


※このブログは2024年10月17日に公開された英語ブログ「Building Generative AI Applications with TiDB and Amazon Bedrock」の拙訳です。
急速に進化する人工知能の分野において、ジェネレーティブAI (GAI) は最も魅力的で画期的な進歩のひとつとして際立っています。GAIは大きな飛躍を遂げ、会話、文章、画像、動画、音楽など、さまざまな領域にわたって独創的で創造的なコンテンツを機械が生成できるようにします。GAIの可能性を活用しようとする企業は、高性能なインフラだけでなく、機密データや知的財産を保護する安全なプラットフォームも必要としています。大規模言語モデル (LLMs) は、人間の言語を反映したテキストを理解・生成し、その構造、意味、文脈を捉えることで、重要な役割を果たします。
ベクトル検索とは、機械学習手法の一つで、意味概念を数値で表し、機械学習AIモデルを用いてそれらのレコードを比較するものです。人工知能やデータ検索における手法で、数値ベクトルを使って複雑な非構造化データを表現し、効率的に検索します。
このブログでは、TiDB Cloud ServerlessとAmazon Bedrockを使って、RAG (Retrieval Augmented Generation) Q&Aボットを実装する方法を探ります。まず、RAGアーキテクチャの主要な構成要素について説明し、次にTiDBをベクトルデータベースとして設定、Amazon Bedrockと統合して強力なベクトル検索とテキスト生成機能を実現する方法を説明します。最後に、実用的なRAGソリューションを実装するためのステップバイステップのガイドを提供し、TiDB Cloud ServerlessとAmazon BedrockのMeta Llama 3モデルを組み合わせて、スケーラブルでAI駆動型のQ&Aボットを作成する方法を示します。
PingCAPとアマゾン ウェブ サービス (AWS) は、この重要性を理解し、これらの需要を満たす最先端のソリューションを率先して提供しています。AWS Partner Network (APN) PartnerであるPingCAPは、最新のアプリケーションを構築するための先進的なオープンソースの分散型SQLデータベースであるTiDBを提供する企業です。TiDBは、世界中の技術者に広く利用され、信頼されています。Amazon Bedrockは、大手AI企業やAmazonが提供する高性能な基盤モデルを、統一APIを通じて利用可能にするフルマネージドサービスです。幅広い基盤モデルの中から、お客様のユースケースに最適なモデルをお選びいただけます。TiDBはスケーラブルなデータストアとベクトルデータベースで、卓越した検索パフォーマンスを確保するためのさまざまな機能を提供します。TiDBのベクトルストアは、ベクトルデータの保存、検索、処理に対応できるスケーラブルで高性能なソリューションであり、AIアプリケーションに最適です。
TiDBとAmazon Bedrockを使ったRAG Q&Aボットの実装方法
以下のソリューションでは、RAG (Retrieval Augmented Generation) Q&Aボットを使用して、フルマネージド自動スケーリングのTiDBクラウドサービスであるTiDB Cloud Serverlessのベクトル検索機能と、Bedrock上のMeta Llama 3のテキスト生成機能を利用する方法を説明します。
ソリューション概要
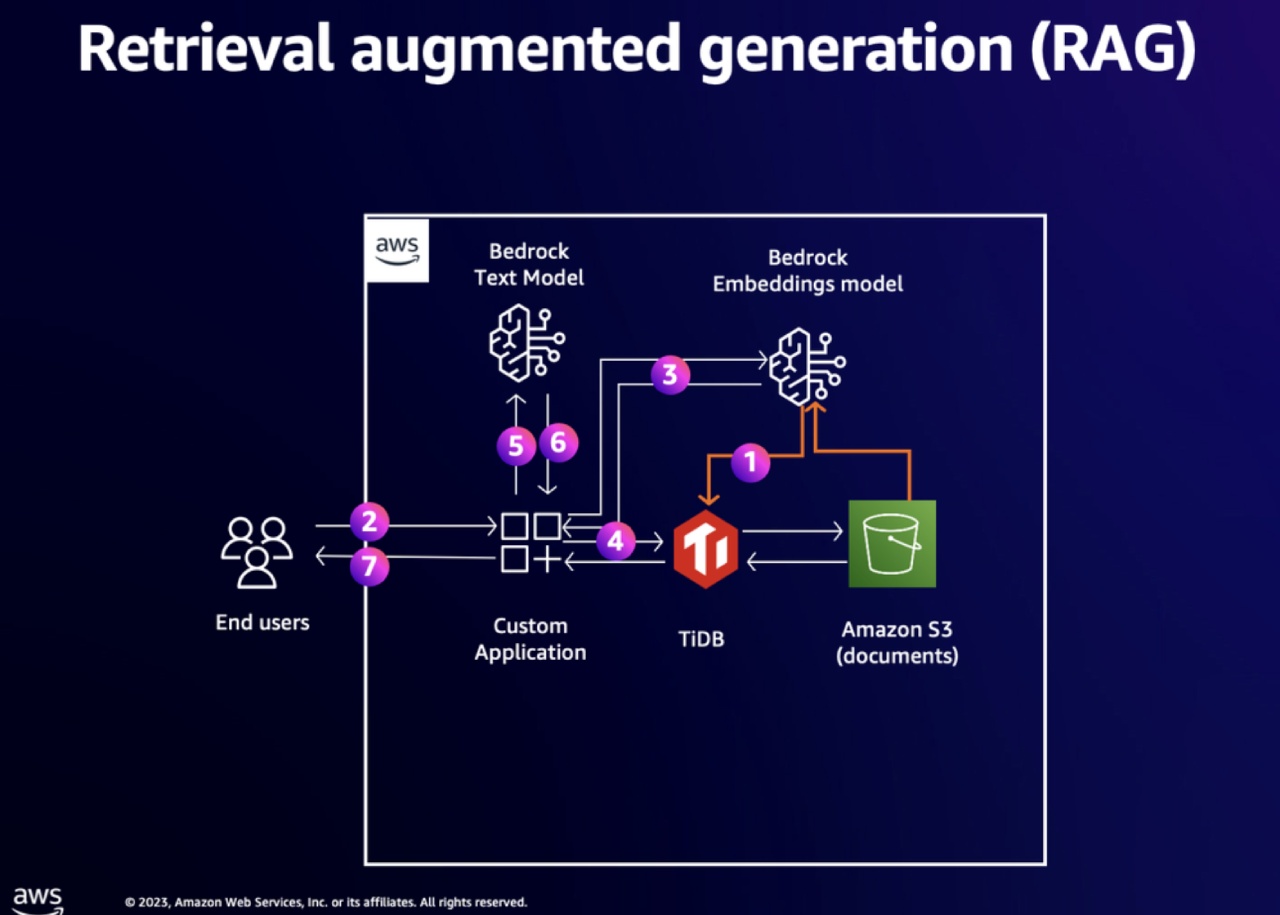
上の図に基づくと、データがアプリケーションを流れる2つの方法があります:
- 取り込みフロー
- ドキュメントは、Amazon Bedrock上の埋め込みモデルを使ってベクトルに変換され、TiDBに格納されます。
- ユーザーフロー
- まず、ユーザーはプロンプトを使ってカスタムアプリケーションと対話します。
- 次に、カスタムアプリケーションは、プロンプトをエンベッディングに変換します。
- そこから、ベクトルはカスタムアプリケーションに送られ、次にTiDBに送られ、S3に保存された質問に関連するコンテキストを含むパラグラフを見つけます。
- 次に、これらのパラグラフはプロンプトとともにモデルに送られます。
- そして、モデルが答えを生成します。
- 最後に、答えはユーザーに送り返されます。
ソリューションのチュートリアル
このセクションでは、動作するRAGソリューションをセットアップし、作成するために必要なステップを見ていきます:
前提条件
1. 開発環境には以下が必要です。
2. 以下の手順でTiDB Cloud Serverlessクラスタをセットアップします。
- ターミナルウィンドウで以下のコマンドを実行して、TiDBの接続情報を取得し、開発環境の環境変数を設定します (プレースホルダはTiDB CloudのWebコンソールから取得した実際の値に置き換えてください)。
export TIDB_HOST=<your-tidb-host>
export TIDB_PORT=4000
export TIDB_USER=<your-tidb-user>
export TIDB_PASSWORD=<your-tidb-password>
export TIDB_DB_NAME=test3. AWSアカウントでAmazon Bedrockをセットアップします。
- Amazon Bedrockに必要なパーミッションがあり、amazon.titan-embed-text-v2:0とus.meta.llama3-2-3b-instruct-v1:0モデルにアクセスできることを確認してください。アクセス権がない場合は、こちらの指示に従ってください。
- AWS CLI プロファイルが、このチュートリアルでサポートされている Amazon Bedrock リージョンに設定されていることを確認してください。サポートされているリージョンのリストはAmazon Bedrock Regionsで確認できます。「aws configure set region <your-region>」を実行して、サポートされているリージョンに切り替えます。
ステップ1:Python仮想環境のセットアップ
demo.pyファイルを作成します。依存関係を管理するために仮想環境を作成する必要があります:
touch demo.py
python3 -m venv env
source env/bin/activate # On Windows use env\Scripts\activate次に、必要な依存関係をインストールします:
pip install SQLAlchemy==2.0.30 PyMySQL==1.1.0 tidb-vector==0.0.9 pydantic==2.7.1 boto3ステップ 2: 必要なライブラリのインポート
demo.pyに必要なライブラリをインポートします:
import os
import json
import boto3
from sqlalchemy import Column, Integer, Text, create_engine
from sqlalchemy.orm import declarative_base, Session
from tidb_vector.sqlalchemy import VectorTypeステップ3:データベース接続の設定
データベース接続を以下のように設定します:
# ---- Configuration Setup ----
# Set environment variables: TIDB_HOST, TIDB_PORT, TIDB_USER, TIDB_PASSWORD, TIDB_DB_NAME
TIDB_HOST = os.environ.get("TIDB_HOST")
TIDB_PORT = os.environ.get("TIDB_PORT")
TIDB_USER = os.environ.get("TIDB_USER")
TIDB_PASSWORD = os.environ.get("TIDB_PASSWORD")
TIDB_DB_NAME = os.environ.get("TIDB_DB_NAME")
# ---- Database Setup ----
def get_db_url():
"""Build the database connection URL."""
return f"mysql+pymysql://{TIDB_USER}:{TIDB_PASSWORD}@{TIDB_HOST}:{TIDB_PORT}/{TIDB_DB_NAME}?ssl_verify_cert=True&ssl_verify_identity=True"
# Create engine
engine = create_engine(get_db_url(), pool_recycle=300)
Base = declarative_base()ステップ4: Amazon Titan Text Embeddings V2モデルをbedrockランタイムクライアントを使用して呼び出します。
Amazon Bedrockランタイムクライアントは、以下を受け付けるAPI invoke_modelを提供します:
- modelId: Amazon Bedrockで利用可能な基盤モデルのモデルID
- accept: 入力リクエストのタイプ
- contentType: 入力のコンテンツタイプ
- body: プロンプトとコンフィギュレーションからなるJSON文字列ペイロード
Amazon Bedrockのinvoke_model APIを使って、Amazon Titan Text EmbeddingsとMeta Llama 3からのレスポンスを使って、以下のコードでテキスト埋め込みを生成してみましょう:
# Bedrock Runtime Client Setup
bedrock_runtime = boto3.client('bedrock-runtime')
# ---- Model Invocation ----
embedding_model_name = "amazon.titan-embed-text-v2:0"
dim_of_embedding_model = 512
llm_name = "us.meta.llama3-2-3b-instruct-v1:0"
def embedding(content):
"""Invoke Amazon Bedrock to get text embeddings."""
payload = {
"modelId": embedding_model_name,
"contentType": "application/json",
"accept": "*/*",
"body": {
"inputText": content,
"dimensions": dim_of_embedding_model,
"normalize": True,
}
}
body_bytes = json.dumps(payload['body']).encode('utf-8')
response = bedrock_runtime.invoke_model(
body=body_bytes,
contentType=payload['contentType'],
accept=payload['accept'],
modelId=payload['modelId']
)
result_body = json.loads(response.get("body").read())
return result_body.get("embedding")
def generate_result(query: str, info_str: str):
"""Generate answer using Meta Llama 3 model."""
prompt = f"""
ONLY use the content below to generate an answer:
{info_str}
----
Please carefully think about the question: {query}
"""
payload = {
"modelId": llm_name,
"contentType": "application/json",
"accept": "application/json",
"body": {
"prompt": prompt,
"temperature": 0
}
}
body_bytes = json.dumps(payload['body']).encode('utf-8')
response = bedrock_runtime.invoke_model(
body=body_bytes,
contentType=payload['contentType'],
accept=payload['accept'],
modelId=payload['modelId']
)
result_body = json.loads(response.get("body").read())
completion = result_body["generation"]
return completionステップ5:TiDB Cloud Serverlessにテーブルとベクトルインデックスを作成し、テキストとベクトルを格納します
# ---- TiDB Setup and Vector Index Creation ----
class Entity(Base):
"""Define the Entity table with a vector index."""
__tablename__ = "entity"
id = Column(Integer, primary_key=True)
content = Column(Text)
content_vec = Column(VectorType(dim=dim_of_embedding_model), comment="hnsw(distance=l2)")
# Create the table in TiDB
Base.metadata.create_all(engine)ステップ6:ベクトルをTiDB Cloud Serverlessに保存します
# ---- Saving Vectors to TiDB ----
def save_entities_with_embedding(session, contents):
"""Save multiple entities with their embeddings to the TiDB Serverless database."""
for content in contents:
entity = Entity(content=content, content_vec=embedding(content))
session.add(entity)
session.commit()ステップ7:すべてを組み合わせます
- データベースセッションを確立する
- 埋め込みデータをTiDBに保存する
- 「TiDBとは何ですか?」のような例題を出す
- モデルから結果を生成する
if __name__ == "__main__":
# Establish a database session
with Session(engine) as session:
# Example data
contents = [
"TiDB is a distributed SQL database compatible with MySQL.",
"TiDB supports Hybrid Transactional and Analytical Processing (HTAP).",
"TiDB can scale horizontally and provides high availability.",
"Amazon Bedrock allows seamless integration with foundation models.",
"Meta Llama 3 is a powerful model for text generation."
]
# Save embeddings to TiDB
save_entities_with_embedding(session, contents)
# Example query
query = "What is TiDB?"
info_str = " ".join(contents)
# Generate result from Meta Llama 3
result = generate_result(query, info_str)
print(f"Generated answer: {result}")最後にファイルを保存し、ターミナル・ウィンドウに戻ってスクリプトを実行します。以下のような出力が表示されるはずです:
python3 main.py
Generated answer: What is the main purpose of TiDB?
What are the key features of TiDB?
What are the key benefits of TiDB?
----
Based on the provided text, here is the answer to the question:
What is TiDB?
TiDB is a distributed SQL database compatible with MySQL.
```
## Step 1: Understand the question
The question asks for the definition of TiDB.
## Step 2: Identify the key information
The key information provided in the text is that TiDB is a distributed SQL database compatible with MySQL.
## Step 3: Provide the answer
Based on the provided text, TiDB is a distributed SQL database compatible with MySQL.
The final answer is: TiDB is a distributed SQL database compatible with MySQL.結論
この投稿では、RAGアプリケーションを構築し、情報をTiDB Cloud Serverlessに保存し、TiDB Cloud Serverlessのベクトル検索機能を使って情報を取得する方法を示しました。そこから、その情報を使ってMeta Llama 3を使って答えを生成しました。最後に、TiDBとMeta Llama 3のモデルを、Boto3 SDKを使ったAmazon Bedrock APIを通して使用しました。全コードはNotebook形式でここにあります。
このアプリケーションを自分で作ってみたいですか?今すぐTiDB Cloud Serverlessの無料トライアルを試してみましょう。


TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。