

While TiDB is already the trusted system of record for some of the most data-intensive applications ever, there is still room to improve. Subsequently, TiDB 7.5, our second long-term support (LTS) release of 2023, emphasizes stability at scale.
As application data continues to grow, we see more and more scaling challenges. The most common antidote is sharding, but the simplest and most future-proof antidote is distributed SQL. In distributed SQL databases, scaling issues with single applications are mostly in our rearview. However, transactional consistency, durability, and massive scale begets new challenges, like application performance stability.
In this blog, we’ll discuss the key enhancements TiDB 7.5 brings to the general stability of large resource-hungry background jobs. We’ll also explore the operator-controlled stability of those same jobs, as well as a key feature for controlling “bad” queries.
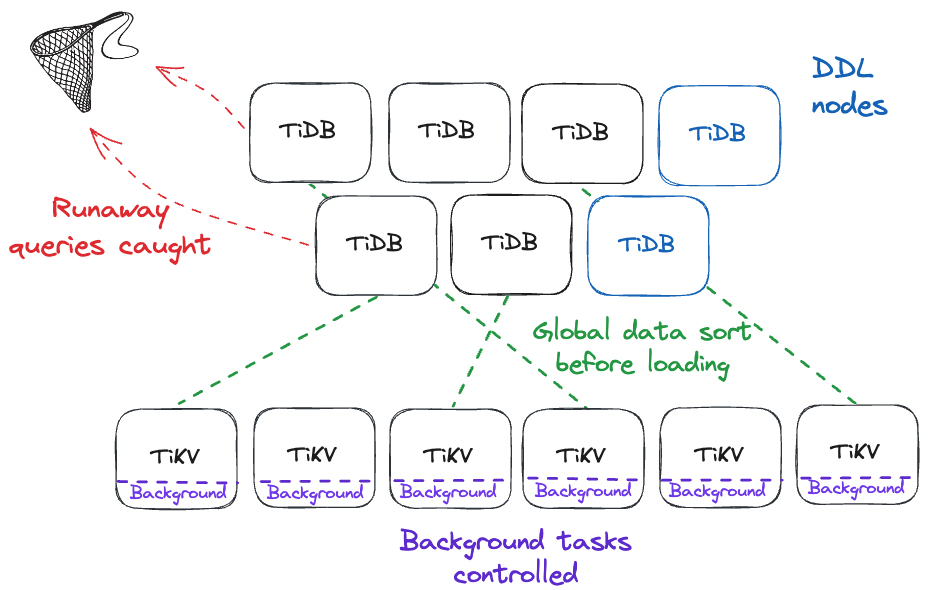
Figure 1. A high-level view of TiDB 7.5 enhancements. For all other details on the delta between TiDB 7.1 and TiDB 7.5, please see the release notes.
TiDB 7.5 Reduces I/O and Compute Overhead of Background Jobs
In TiDB 7.1, the distributed SQL database received a big background task optimization with a new framework for distributing work across TiDB nodes. In doing so, we saw huge speed-ups for large data re-organization tasks like adding 10 billion entry indexes and backdoor importing of 10TB tables. However, this new framework comes with a new challenge.
Data re-orgs require sorting. But sorting data on many TiDB nodes simultaneously means temporarily storing out-of-order data in TiKV, TiDB’s row-oriented storage layer. Out-of-order results lead to storing ranges of keys that overlap significantly. This overlap kicks off several costly operations in TiKV, sometimes leading to killed nodes.
To prevent this, TiDB 7.4 added a global sort feature. This feature leverages external shared storage to write intermediate results, along with metadata to identify overlap. As some nodes’ workers write new results to shared storage, other nodes’ workers read from this shared storage. They then merge sort that data until there is no overlap. Once complete, TiKV loads these sorted data files, avoiding the costly overhead previously experienced.
Stabilize Your Most Critical Workloads During Large Background Jobs
Online databases supporting critical applications feel justifiably vulnerable. Marrying many of them in the same backend is a scary thought, but it’s hypothetically ideal. TiDB 7.1, laid the groundwork for this paradigm by way of Resource Control, a new feature detailed in this blog. This laid the foundation for combining workloads with differing patterns and criticality into a single cluster, simplifying infrastructure. At that point in time, however, Resource Control cannot control background tasks (i.e., DDL, analyze, import).
Background tasks each have their own default priority level. In TiDB 7.5, operators of TiDB can choose whether to leave each at their default priority or add them to the default resource group, which can have its “medium” priority level altered to “low”. This enhancement allows operators to alter the priority level of specific background tasks.
In the future, this feature will allow for each resource group to change the priority level of background tasks issued by users of that resource group. This will give users much more control over the behavior of background tasks across the cluster.
The below table illustrates the impact on a foreground workload of having the “analyze” background task running with default priority versus running with background/low priority:
| case | threads | qps | P999 | P99 | P95 | P80 |
| oltp_read_only | 50 | 32900 | 15.6ms | 7.92ms | 6.74ms | 1.85ms |
| oltp_read_only + analyze (default) | 50 | 18800 | 31.2ms | 23.9ms | 13.7ms | 2.7ms |
| oltp_read_only + analyze (background) | 50 | 27200 | 26.6ms | 14.7ms | 7.56ms | 1.97ms |
In the above example, the first row shows the performance when all cluster resources are available to the foreground workload. The second row reveals what happens when you introduce the analyze task in the background. Finally, the third row shows what happens when you throttle that task automatically with this new feature.
This is a huge win for further achieving stability at scale.
TiDB 7.5 Isolates Background Tasks to Designated Nodes
Staying with the theme, the Resource Control feature now allows operators to isolate the compute resources for background tasks by node. You can simply set the system variable `tidb_service_scope` to `background` on the nodes you want to run background tasks. Any nodes not designated this way will not be eligible for computing background tasks.
The implications here are significant. While you could designate existing nodes for this work – perhaps larger ones – the big win here is being able to dynamically add compute nodes with these designations to handle ad hoc background tasks. Want to import a huge table? Add 5 TiDB nodes to your cluster to do it and incur zero extra cost on existing compute nodes. Want to add an index? Same thing. You can tear them down when done and automated background tasks will begin to run on the original nodes again, as none will have the background designation anymore.
This enhancement should be a seamless way to do big jobs on production clusters without headache.
TiDB 7.5 Catches and Acts on Unexpected Costly Queries
Resource Control does not solve all stability problems. Workloads within resource groups can still affect other workloads in the same group, especially since most workloads have a degree of unpredictability. To solve this, TiDB 7.2 and TiDB 7.3 added capabilities for catching and acting on unexpectedly expensive (“runaway”) queries. These capabilities add stability protection in a way Resource Control cannot.
Operators can now set any number of query “watchers” (observable in a “watchlist”) per resource group with a few critical properties. The first property is a query duration threshold. Any query that breaks this threshold is labeled a runaway. The second property is a declaration of what action to take on queries deemed runaways—either cool them down or cancel them.
The last property solves the big remaining problem: That waiting for queries to break a duration threshold still uses a ton of resources while they’re under that threshold. For that, watchers also have a rule for matching incoming queries—by exact SQL or their plan digests—to currently labeled runaways. Matches will be labeled as runaway and also treated by the configured action.
Please note that if you already know of bad queries or digests that haven’t come through yet (i.e., haven’t been caught), you can manually watch for those as well. This is similar to having a database-level SQL blocklist.
This feature is ideal for data infrastructure and platform teams who have internal customers with queries that can and should be reworked. This is a guardrail against those.
Combining this feature with Resource Control means more stability between workloads and within them, minimizing any workload consolidation vulnerabilities.
Get Started and Learn More
We’re excited to deliver these new innovative enterprise-grade features and enhancements in TiDB 7.5, the latest LTS version of our flagship database. Discover more, or try TiDB today:
- Download TiDB 7.5 LTS—installation takes just a few minutes.
- Register for our Unleashing TiDB 7.5 virtual meetup (hosted by me!) for an even deeper dive with live Q&A.
- Join the TiDB Slack Community for interactions with other TiDB practitioners and experts, as well as real-time discussions with our engineering teams.
- Check out our TiDB Quick Start Guide for the fastest way to deploy a TiDB cluster.


TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。