

※このブログは2023年7月26日に公開された英語ブログ「TiDB Resource Control: Stable Workload Consolidation of Transactional Apps」の拙訳です。
あなたはこのブログのための架空の会社であるSuper Sweet Tech,Inc (SST) のデータインフラストラクチャを所有していると想像してください。現在の会計年度には2つの大きな取り組みがあなたに課せられています。1つ目はコストを削減することです。もう2021年ではありません。テクノロジー経済は財布の紐とともに引き締められています。目標は20%削減です。ワオ!2つ目はデータの整合性に関連するチケットを減らすことです。SSTはTwitterから十分な意見を聞いています。
あなたのグループは問題のある領域の特定に着手し、各々が両方の取り組みに関係していると思われる2つの問題領域を見つけました。1つ目はデータストアの違いです。21種類のデータベースと5,500のインスタンスが複数のAPI、マイクロサービス、顧客向けアプリケーションすべてをまたがって構成されています。下流の分析ストアもあり、2つ目の問題領域につながります。分析パイプラインはコストセンターで、最終的には関連したツールの混乱と適切なQAのための時間を圧迫している莫大な量の技術的負債に起因したデータに関連するチケットが主な原因となっています。
あなたのグループがたどり着いた解決策は、両方の取り組みに影響を与えるものです。そうすれば店舗間の違いが最小限に抑えられ、技術的負債が返済され、CI/CD、ドキュメント、開発者に必要なスキルセットが簡素化されます。最終的にこれらのメリットは積み重なって、この取り組みにとって大きな利益となるでしょう。
ソリューションですか?ワークロードの統合です。もし実現できれば、これはさまざまなアプリケーションからのオンラインデータを結合し、データを1つまたはごく少数のデータストアから提供することを意味します。あなたのグループの誰かが、まさにこの可能性についてブログを持ってきました。
これがそのブログです…
TiDBのリソース制御の紹介
TiDB LTS7.1では、トランザクションワークロードのスケーリングという考え方が大きく進歩しています。非常にスケーラブルな分散SQLデータベースであるTiDBは、スケールした規模での一貫性を保証します。さらに良いことに、TiDB 7.1ではリソース制御と呼ばれる新機能が導入されており、これがストーリーを完成させます。これによりTiDBユーザーは複数のアプリケーションを1つのバックエンドにまとめることができます。
スケール時の一貫性は、大規模なオンラインアプリケーションやデータ集約型アプリケーションに最適です。しかし、これらのアプリケーションを同じストアに統合するにはどうすればよいでしょうか?ちょっと不気味です。
データワークロードを別の場所から取り込むということは、そのCPU、メモリ、ディスクの消費量を元のアプリケーションの消費量に近づけることを意味します。アプリA…アプリBもあります。さあ、うまくやってください!
リソース制御 (このリリース投稿でも参照されています) は、オンラインワークロードの統合に対する懸念に対処します。リソース制御はCPUの計算量とストレージI/Oスループットの観点から行われます (メモリ使用量は別の方法で処理されます)。これらの項目はリソースグループと呼ばれる論理オブジェクトで制御します。リソースグループは優先順位が割り当てられたクラスタリソースの論理バケットです。バケットのサイズと優先度の両方を個別に定義できます。読み進めていくことでさらに詳しく知ることができます。
TiDBのリソース制御の始め方
運用者は簡単なSQLコマンド (後述) を使用してこれらのグループを作成します。これらのグループに割り当てられると、ユーザー (実質的にはアプリケーション)、セッション、さらには単一のSQLステートメントでも同じバケットのリソースを共有できます。グループにワークロードを追加しても、その制約は維持されます。追加しすぎるとそれらのワークロードが制約に達し、速度が低下する可能性があります。そういう仕様です!この機能を使用すると、予測不可能なシナリオにおいて高トラフィッククラスタの安定性をより詳細に制御できるようになります。アプリケーションの要求を満たすようにスケーリングするか、アプリケーションのパフォーマンスが低下したり失敗したりすることを許容するかの選択は、ほとんどの場合明白でしょう。リソース制御はあなたの要求に応じて最も重要なワークロードの安定性を最大化します。

TiDBはコンピューティングとストレージが分離された分散アーキテクチャです (上の図ではTiDBとTiKVがそれにあたります)。リソース制御は両方の場所に適用されます。これを考慮すると、この機能の基礎となるメカニズムはSQLフロー制御とストレージ優先度に基づいたスケジューリングという2つのコア機能を持つものとして概念化する必要があります。フロー制御は各リソースグループのリソースクォータ (後述するRU_PER_SEC) の空き状況に応じて、リクエストをストレージに送信する方法を決定します。スケジューリングとはデータアクセス要求を (キューイングが必要な場合に) キューイングする順序です。これはPRIORITYによって決まります。
この堅牢な安定性をより柔軟にするために、その安定性を維持しながらグループをBURSTABLEとして定義することもできます。これは利用可能な場合に、割り当てられた以上のリソースを使用できることを意味します。最も重要なワークロードをバースト可能にすると、リソース要件が瞬間的かつ予期せず増加した場合でも、より多くのリソースを動的に使用して応答時間をSLA内に維持できることを意味します。
どのように動作するのか
例を使用ながら現実の世界で実際にどのように見えるかを示すことができます。そのためにoltp、batch、hrという3つのリソースグループの作成を示します。oltpワークロードはオンラインおよび顧客向けアプリケーションデータを表します。これは重要かつ予測不可能なワークロードであり、テールレイテンシー (p99) で測定する厳密なレイテンシーSLAがあります。batchワークロードは顧客対応ではない分析パイプラインを表します。これは依然として重要ではありますが、それほど高い重要度ではなく、必要なクラスタも少なくなります。hrワークロードは予測可能なワークロードを表しますが、それに関連付けられたSLAはありません。
これらのグループの作成はSQLインターフェイスで行われ、次のようになります。
CREATE RESOURCE GROUP oltp RU_PER_SEC=4000 BURSTABLE PRIORITY=HIGH;
CREATE RESOURCE GROUP batch RU_PER_SEC=400 BURSTABLE;
CREATE RESOURCE GROUP hr RU_PER_SEC=400;otlpグループはそのメンバーが定期的にトラフィックが増加する重要なアプリケーションとなるため、最大のクォータを取得します。batchグループには必要な量が少なく重要性も低いため、割り当て量が小さくなります。ただし、このグループのアプリケーションにとって時間効率が優れていることが望ましいです。結果としてスペースが許せばアプリケーションが貪欲に動作できるようにバースト可能に設定されます。hrは最も寛容でバーストする能力のない小さな割り当てが与えられます。これにより、予測可能な「邪魔にならない」状態が保たれます。
以下はこれらのグループが現実のシナリオでどのように実行されるかを示す例です。

Otlpワークロードが大量のリソースを必要とする場合、バースト可能で優先度が最も高いためリソースが取得されることに注目してください (上のグラフ)。このワークロードがリソースを消費している間、レイテンシーは低く安定したままです (下のグラフ)。トラフィックが1日を通じて減少すると、他のバースト可能なグループがバーストする可能性があります。これが起こるとbatchワークロードのレイテンシーが変化することに注目してください。hrグループはただ自分たちの仕事をしているだけです。
では、どのように実現しているのでしょうか?
仕組み
フロー制御とスケジューリングを思い出してください。これを理解するにはTiDBが分離されたアーキテクチャであることを思い出してください。コンピューティング (TiDBサーバー)、ストレージ (TiKV)、スケジューリング (Placement Driver) が物理的に分離されていることを意味します。

残りの部分を理解するために、アーキテクチャについて知っておく必要があるのはそれだけです。それを踏まえて、先に述べたこの機能の2つのコア機能、フロー制御と優先度に基づいたスケジューリングに早速入っていきます。
フロー制御
リソース制御の最終目標は、リソースグループの期待された消費率を維持することです。加えて、重要性が異なるワークロードの適切な実行順序を保証することです。最初の目標を達成するために、TiDBはSQLリクエストを作成および実行する”フロー制御”を実装します。リソースグループはフロー制御を使用してストレージ (TiKV) にリクエストを送信するための定義と決定を行います。
トークンバケットアルゴリズムは、データリクエストのフロー制御を処理します。この場合、”トークン”は1秒あたりの要求ユニット (RUs)、つまりRUPS (Request Unit Per Second) です。RUはCPUミリ秒とディスクI / Oを抽象化したもので、詳細についてはここで読むことができます。リソースグループのRUPSは、そのグループ内のリクエストがRUバケットを消費するときに、RUバケットがバックフィルされる速度を制御します。
TiDBは特定のリソースグループに割り当てられたリクエストを処理するため、TiDBとTiKVの両方が各リクエストで使用されるリソース (RUs) に関する情報を報告します。リソースグループの現在利用可能なRUsから、計算された要求に関連するRUsが減算されます。RUPSに見合った速度でバックフィルされます。
優先順位に基づいたスケジューリング
リソース制御の2番目の目標によれば、優先順位に基づいたスケジューリングは2つの重要な理由から存在します。1つ目は、さまざまなビジネス優先度のワークロードの実行順序を明確に強制することです。2つ目は、リソースの制約がある場合でも同じ優先度のワークロードが実行される作業量にできるだけ近づけるようにすることです。フロー制御はこの割合を維持することを目的としていますが、ワークロードの割合がコンピューティング層の制御外に偏る可能性があるため、ストレージノードもこの割合を考慮する必要があります (これについては後で詳しく説明します)。
優先順位に基づいたスケジューリングは、TiKVがTiDBからのデータアクセス要求を実行キューに入れるメカニズムです。このキューは優先順位によってタスクがリンクされたリストで、FIFOです。キューでは同時スレッドのスレッドプールごとに非常に迅速にタスクが処理されます。タスクにはリソースグループからのリクエストの優先度に応じた優先度が設定されます。キューの先頭には高優先度のタスクが含まれ、中間には中優先度のタスクが含まれ、末尾には低優先度のタスクが含まれます。
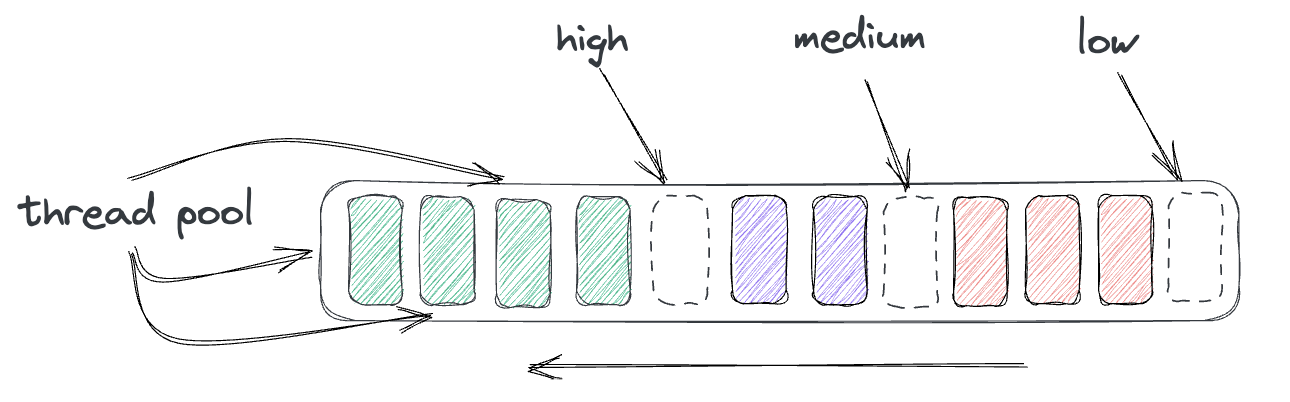
リソース制御ではストレージ層が全体のRU比率に従ってリソースグループを処理していることを保証する必要があるため、TiKVノードはそれぞれすべてのリソースグループのグローバル消費率を認識している必要があります。
グローバル制御
グローバル制御がないと、各ストレージノードで特定のリソースグループのリクエストに優先順位を付けると、比率が歪む可能性があります。これはリソースグループがストレージノードへの不均一なアクセスを必要とし、ノードがグローバルで何が起こっているかを認識していない場合に発生する可能性があります。しかし、良いニュースがあります!
TiDBサーバーのフロー制御は当然、グローバルに認識されたPlacement Driver (そこからRUPSを要求します) を介してこれに対処しますが、TiKVノードも独自の方法でこれに対処します。
ホットスポットシナリオであっても、グループがグローバルに公平な作業分担を継続できるようにするために、TiKVノードはTiDBサーバーのデータ要求への応答の一部としてリソースグループの使用状況をリアルタイムで報告します。これは同じTiDBサーバーノードからリクエストを受信するすべてのノードが認識しており、グローバルな比率を維持するために必要に応じて優先順位を付けたり優先順位を下げたりできることを意味します。
これら2つのメカニズムが連携して動作する例を見ると分かりやすいと思います。目標に合わせた比率を保証するためのグローバルな認識を説明するために、いくつかの異なるシナリオでもう一度想像力を発揮してもらいます。各シナリオにはリソースグループ”rg1”、”rg2”、”rg3”に割り当てられた3つのアプリケーションがあります。わかりやすくするために、各シナリオでは3つのストレージノードを持つクラスタを使用しており、クラスタの理論上の最大QPS (1秒あたりのクエリ数) を知ることができます。注: 最終的な効果を説明するために、RUの抽象化としてQPSを使用しています。
TiDBのリソース制御シナリオ1
グループrg1、rg2、およびrg3はすべて同じ優先度を持ち、クラスタは理論上最大QPS4,000 (ノードあたり1,333) を処理できます。各グループがアプリケーションのSLAを維持するために必要なQPSは1,000 (合計3,000) です。以下の図はリソースグループがアクセスする必要があるデータがノード全体に均等に分散されていると仮定して、リソースグループのワークロードがどのように分散されるかを示しています。優先順位が等しいため、図では省略してあります (この後登場します)。


クラスタで利用可能なQPSはすべてのグループで十分満たされており、グループの優先順位はすべて同じことからワークロード分散は完全かつ均等で比率はすべて1:1:1です。このような公平性により、グループに割り当てられたすべてのアプリケーションはSLAを維持できるようになります。このことは安定したレイテンシーを示しているグラフに現れています。
TiDBのリソース制御シナリオ2
ここで、rg2に1つのワークロードが割り当てられたため、rg2は1,000ではなく3,000QPSが必要になったとします。このことはワークロードに必要な合計QPSがクラスタの最大QPSを超えていることを意味します。予想される比率は1:3:1で、リソースが制限され一部のタスクがキューに入れられます。結果として次のようになります。


リソースの飽和によりノードがタスクをキューに入れる必要があるため、各グループのレイテンシーが増加するはずです。ただしこのシナリオでも公平性は維持され、レイテンシーは依然として互いに同じです。また、各リソースグループによって達成される合計QPSは要件を下回っていますが、必要な比率は1:3:1に維持されていることにも注目してください。
TiDBのリソース制御シナリオ3
次に、PRIORITYを追加します。rg2がPRIORITY = HIGHを取得し、他の2つがMEDIUMを取得したとします。前のシナリオの値を使用すると比率は1:3:1のままですが、rg2の優先順位がそれを上書きします。rg1とrg3のレイテンシーも影響を受ける可能性があります。


このシナリオでは、rg2からTiKVに送信されたすべてのタスクがrg1およびrg3のタスクよりも優先されます。これが新しく1:6:1の比率になる理由です。ここでrg2のQPS要件は満たされていますが、他の2つのグループは満たされていません。さらに、rg2タスクはタスクに割り込みスループットが高いことから、他のグループのタスクはキューイングリソースが利用可能でキューイングが必要ない場合よりも長く待機する必要があります。これは仕様によるものです!
ワークロードの変化に応じてクラスタをリアルタイムでスケールアップできれば理想的ですが、それは無理です。ここで重要なのは、優先順位が高くスループットの高いワークロードが時間通りに作業を完了し、クラスタが余った時間で他のグループで作業を行ったということです。
TiDBのリソース制御シナリオ4
最後に、各TiKVノードがグローバルな”ホットスポット”を認識できるシナリオを紹介します。
例:
再びすべてのグループの優先順位とQPSは同じになりますが、今回は各グループに2,000QPSが必要です。ワークロードの比率は今回も1:1:1ですが、リソースには制約があり、rg2は”ホットスポット”ワークロードになっています。つまり、アクセスに必要なキーが物理的に連続しており同じストレージノード上に配置されています。rg2のデータはすべてTiKV 1にあるため、リクエストの処理にはTiKV 1のみ使用されます。これによりクラスタ全体で比率を維持する際に潜在的な問題が発生します。

この例では、リソース消費率 (4:1:4) が目的の (1:1:1) からずれている”悪い”結果であり、TiKVノードがリソースグループの消費をグローバルに認識していなかったことにより起こっていたであろう結果です。TiKV 1は単に自身のスコープのみを考慮して割合を維持しようとするでしょう。ですが、TiKV 1はrg2が他のノードで作業を行っていないことを認識しているため、それらのリクエストを自身で優先することができます。
その通りです。各グループの優先順位が同じに設定されている場合でも、この特定のノードではグローバルなワークロードの割合を維持するためにrg2の優先順位が高くなります。rg2のワークロードはノードが処理できる量を超えているため、ノードはこのグループのみを処理し、他のノードは他のグループで動作するようになります。最終的にはこのクラスタをスケーリングする必要がありますが、それまでの間は比率は計画どおりに維持されます。リソースの制約によりタスクがキューに入れられている間、このメカニズムによりクラスタ全体で最適な優先順位付けが保証されます。
これらのサンプルシナリオによって、高負荷なクラスタでのパフォーマンスの安定性が優先度ベースのスケジューリングを実装することで実際に向上する理由を十分に示すことができれば幸いです。SQLフロー制御と組み合わせることで、データアクセス要求が適切な優先順位で実行されることを確実に維持しながら個別のワークロードを相互にリソース分離する必要があります。
最後に
これでTiDBのリソース制御機能についての詳細は終わりです。それでは、架空の会社SSTと2つの大きな取り組みはどうなったのでしょうか?
そうですね、非常に優れた分散データベースプロバイダーのこのブログは、偶然にもデータベースのPOCを行わざるを得なくなりました。このリソース制御機能を使用すると、各アプリケーションのリージョンに対して単一のクラスタとしてデプロイでき、すべてのオンラインリージョンのワークロードを処理できるように拡張できることがわかりました。TiDBのリソース制御を使用すると、厳密なSLAを持つ各アプリケーションはSLAを満たすために必要なリソースを使用することができます。同時に、ユーザーは運用アプリケーションを妨げることなく、生のソースデータに対して直接アドホック分析を実行できるようになりました。このことはオンラインでリアルタイムに分析を利用できるという追加の利点になりました。
TiDBのリソース制御は判明している問題の領域を大幅に軽減しました。1つはバックエンドの操作に必要なスキルセットが減ったことです。すぐにではありませんが、バックエンドインフラストラクチャを担当するほとんどのエンジニアはTiDBを理解するだけで済み、アプリケーションにとってはTiDBがMySQLのように見えるため、より簡単になりました。また、CI/CDの複雑さ、開発時間、必要なドキュメントを削減することもでき、エンジニアがデータ品質に集中できる時間を確保し、未解決のバグの優先順位付けを妨げていた技術的負債を取り除くことができました。
TiDBのリソース制御の使用方法の詳細については、ドキュメントを参照してください。
Related Resources

Conference
May 19, 2026
TiDB SCaiLE Europe 2026: Why Engineers Building Agentic AI Should Be in Stockholm on 4 June

Conference
May 12, 2026
TiDB SCaiLE Europe 2026: Speaker Lineup and Session Preview

Product
May 11, 2026
From Preview to Production: TiDB Cloud Dedicated on Microsoft Azure is Now Generally Available
TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。