

※このブログは2026年3月5日に公開された英語ブログ「Multi-Writer Change Data Capture (CDC): Architecture, Challenges, and How TiCDC Solves Them」の拙訳です。
主なポイント
- マルチライター型CDCは、数百万もの独立したリージョンからのイベントをグローバルに順序付けする必要があり、単一のバイナリログ (binlog) を追跡するよりもはるかに困難です。
- TiCDC (TiDB 8.5以降) は、アップストリームアダプター、ログサービス、ダウンストリームアダプタ、およびコーディネーターという、独立してスケーリング可能な4つのコンポーネントを使用します。
- グローバルTSOによる順序付け、多重化されたgRPCストリーム、およびディスクベースのPebbleDBストレージが、スケーリングのボトルネックを根本的に解決します。
- 新しいアーキテクチャは、以前の700MB/秒の天井を取り除き、250TBを超える線形な拡張性を可能にします。
マルチライター型変更データキャプチャ (CDC) とは?
変更データキャプチャ (CDC) は、データの変更をリアルタイムで追跡および伝播するためのパターンであり、ダウンストリームの同期、監査、イベントストリーミング、およびリアルタイム分析などのユースケースを支えています。シングルライター型CDCシステム (例:MySQL binlog、PostgreSQL WALレプリケーション) では、単一のノードがすべての書き込みを処理し、イベントが暗黙的に順序付けされた単一の連続したログを生成します。マルチライター型CDCシステムでは、複数のノードが同時に書き込みを受け付けます。これによりスループットは大幅に向上しますが、同時に読み取る単一のログが存在しないことも意味します。つまり、イベントは多くの独立したソースから収集され、ダウンストリームのコンシューマーに到達する前に、システム全体で一貫した順序にマージされる必要があります。
マルチライター型CDCは、これを可能にするインフラストラクチャレイヤーです。TiDB、CockroachDB、Google Spannerなど、シャードやノード間で同時書き込みをサポートする分散型データベースには不可欠です。専用のマルチライター型CDCソリューションがなければ、チームはメンテナンスが困難でスケーリングも不可能な、脆弱なカスタム同期パイプラインを構築せざるを得なくなります。
シングルライター型モデル:従来のレプリケーションの仕組み
マルチライター型CDCがなぜ難しいのかを理解するために、MySQLやPostgreSQLのようなデータベースが使用している従来のモデルから始めると役立ちます。これらのシステムは数十年にわたり業界で広く利用されてきましたが、現代の分散ワークロードのスケーリングにおいては本質的な限界を抱えています。
- 唯一の信頼できる情報源:単一のノードがすべての書き込みを処理し、明確で曖昧さのない操作順序を保証します。
- 連続したログ:トランザクションは単一のログ (例:MySQL binlogやPostgreSQL WAL) にコミットされ、イベントの順序付けは暗黙的かつ単純です。
- 線形な消費:データは単純なキューのように、一つのプロデューサーから複数のコンシューマーへと流れます。容易に推測できますが、書き込み量が増えるにつれてボトルネックが発生します。
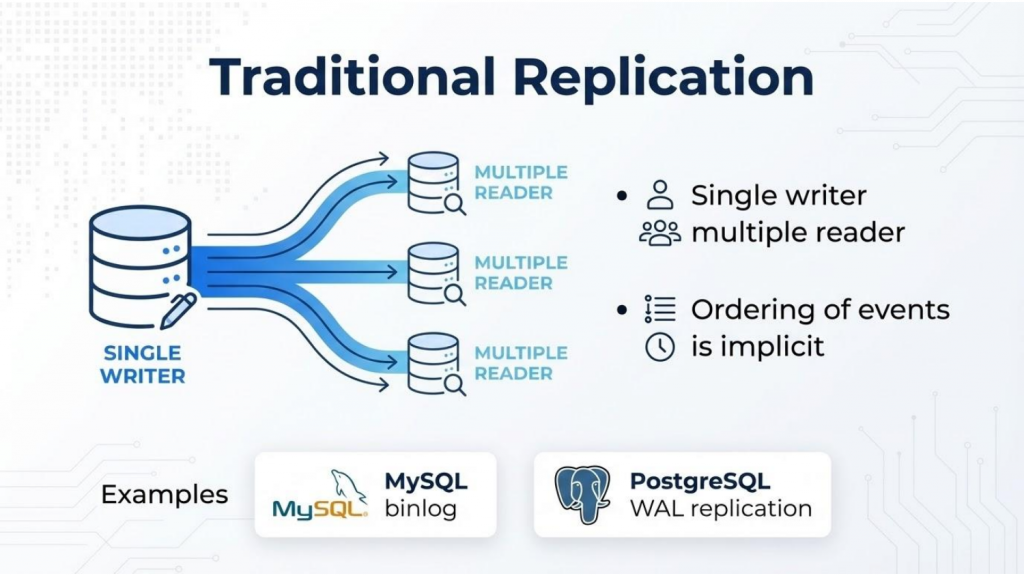
図1:従来のシングルライター型レプリケーションモデル:シングルライター、マルチリーダー、暗黙的なイベント順序付け
TiDBの課題:分散書き込みが新しいアプローチを必要とする理由
TiDBのアーキテクチャは、従来のデータベースとは根本的に異なります。高い一貫性を維持しながら大規模なスケーリングを処理する、分散型クラウドネイティブシステムとしてゼロから設計されました。この設計により、CDCは3つの主要な問題に直面しています。
- マルチライター機能:複数のTiDB SQLノードが同時に書き込みを処理できるため、スループットは大幅に向上しますが、順序付けの複雑さが増します。単一のbinlogが自明な順序付けが可能な従来のシステムとは異なり、TiDBは多くの独立したライター間で調整を行う必要があります。
- 自動シャーディング:データはリージョン (Google Spannerのタブレットに類似) と呼ばれる数百万の小さな単位に分割され、それぞれがRaftコンセンサスグループとして管理されます。これにより耐障害性と拡張性が確保されますが、CDCレイヤーは独立したコンセンサスグループ全体にわたる変更を追跡する必要があります。
- 大規模なスケール:本番環境のTiDBクラスタは、数百万のRaftグループを抱え、250TBを超える規模に容易に達するため、シングルスレッドのレプリケーションモデルでは対応できません。膨大な量の同時変更には、変更データキャプチャへの根本的に異なるアプローチが求められます。
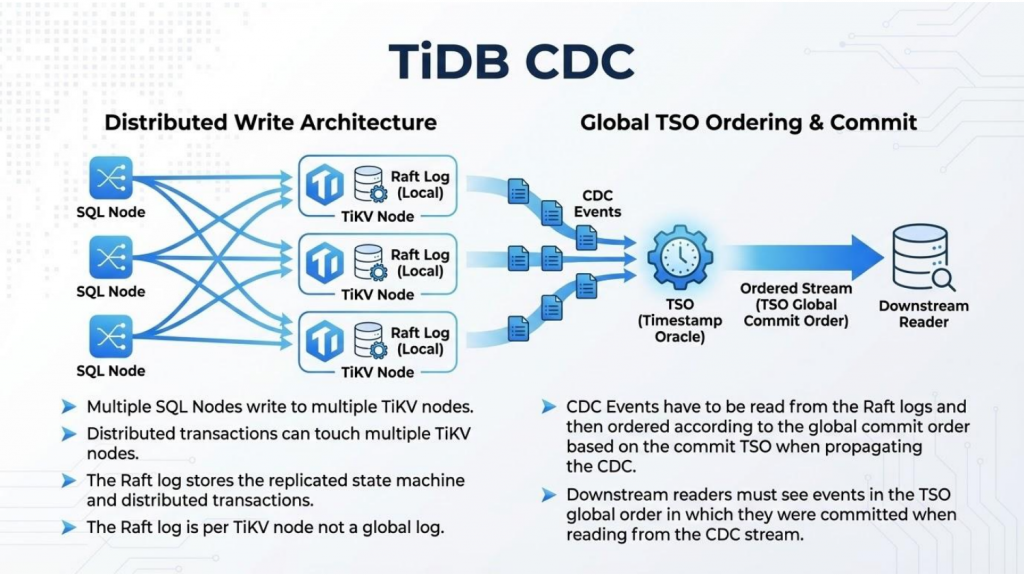
図2:グローバルTSO順序付けを備えたTiDB CDC分散書き込みアーキテクチャ
TiCDCの核心:4つのコンポーネントによる分散アーキテクチャ
この規模に対応するため、TiCDCは中央集権型ノードから、独立して拡張しシームレスに連携するように設計された4つの主要コンポーネントで構成される分散システムへと再設計されました。詳細に入る前に、各コンポーネントの役割を以下の表にまとめました。
| コンポーネント | 役割 | スケーリングモデル |
| アップストリームアダプター | コプロセッサ・オブザーバーパターンを介してTiKVストレージノードから変更を取得します。 | 水平方向 (リージョン分布) |
| ログサービス | ディスク上の永続的なイベントストレージ (PebbleDB)。収集と処理を分離する。 | 独立 (Changefeed間で共有) |
| ダウンストリームアダプタ | Mounter + Dispatcherを介して、データの変換とシンク (Kafka、MySQLなど) への配信を行います。 | シンクごと (本体を変更せずに新しいシンクを追加可能) |
| コーディネーター | クラスタのオーケストレーション、スケジューリング、メタデータ (etcd) のみ。コントロールプレーンのみで、データには触れない。 | 単一インスタンス (データプレーンの負荷なし) |
アップストリームアダプター
アップストリームアダプターは、TiKVストレージノードから直接変更を取得します。コプロセッサ・オブザーバーパターンを使用してRaftStoreに接続し、Raftメッセージに直接割り込むすることなく変更を監視できます。複数のアダプターインスタンスに領域を分散させることで、水平方向にスケーリングします。
ログサービス
ログサービスは、LSMツリーベースのストアであるPebbleDBを使用して、ディスク上に永続的なイベントストレージを提供するステートフルなコンポーネントです。データの収集と処理を分離することで、メモリオーバーフローを起こさずに膨大なスループットを処理できます。複数のChangefeedが単一のログサービスインスタンスを共有できるため、リソース効率が大幅に向上します。
ダウンストリームアダプタ
ダウンストリームアダプタはデータの変換を管理し、Kafka、MySQL、またはその他のサードパーティシンクなどのターゲットにイベントを送信します。これには、スキーマ解決のためのマウンターや、イベントを適切な宛先にルーティングするためのディスパッチャーといった特殊なサブコンポーネントが含まれます。
コーディネーター
コーディネーターはクラスタをオーケストレーションし、スケジューリングを処理し、etcd内のメタデータを管理します。重要な点として、データプレーンの責任を持ちません。Changefeedのライフサイクル管理やワークロードのバランシングといったコントロールプレーンの操作のみを処理し、ボトルネックになるのを防ぎます。
マルチライター型CDCにおけるエンジニアリング上の課題の克服
このスケールでマルチライター型CDCソリューションを構築するには、いくつかの困難な課題を解決する必要があります。それぞれの課題に対して、パフォーマンス、正確性、および運用の単純さのバランスをとる革新的なソリューションが求められました。
TiCDCは数百万のリージョンにわたるイベントの順序付けをどのように処理するのか?
要約:TiCDCは、完全な順序付けを強制するためにグローバルなタイムスタンプオラクル (TSO) を使用し、下流でスキーマ変更が実行される前に、先行するすべてのDMLイベントがレプリケートされることを保証するDDLバリアを設定します。
マルチライターシステムでは、数百万ものリージョンから同時にイベントが到着します。適切な順序付けがなければ、下流のシステムはデータが適用される前にスキーマ変更を検知してしまい、致命的な失敗につながる可能性があります。TiCDCのソリューションは、TSOを使用してすべてのイベントにわたる全順序を確立します。データ定義言語 (DDL) の変更に対して「バリア」を設定し、実行順序が常にDML → DDL → DMLになるように保証します。この保証は、データの整合性を維持し、レプリケーションエラーを防ぐために不可欠です。
図3:DML → DDL → DMLの実行順序により、スキーマの正確性が保証されます
TiCDCは膨大なリージョン数とメモリ負荷をどのように管理するのか?
要約:多重化されたgRPCストリームによりリージョンごとの接続オーバーヘッドを削減し、ディスクベースのPebbleDBストレージにより下流の処理速度が低下した場合でもメモリ不足を解消します。
大規模なスケールでは、リージョンごとのわずかなオーバーヘッドであっても、積み重なれば大きなリソース消費につながります。新しいアーキテクチャは、2つの主要な技術革新によってこの問題に対処します。
- 多重化されたストリーム:TiCDCは、数千のリージョンを処理するためにTiKVノードごとに単一のgRPCストリームを使用し、接続オーバーヘッドを劇的に削減します。この最適化の前は、各リージョンが独自のストリームを必要としていたため、ネットワークの増幅と接続の枯渇を招いていました。
- ディスクベースのストレージ:イベントはメモリではなくPebbleDB (LSMツリーベースのストア) に保存されるため、クラッシュすることなく膨大なスループットを処理できます。メモリからディスクへの移行は、バックプレッシャー管理も可能にします。つまり、下流のシンクの処理速度が低下しても、イベントはメモリ不足エラーを引き起こすことなく、ディスク上に安全に蓄積されます。

図4:3つのTiKVノードにわたる100万リージョンにおけるスケーリングの課題
TiCDCはオンラインスキーマ変更をどのように処理するのか?
要約:マウンターコンポーネントがスキーマのバージョンを追跡し、スキーマが並行して変化している場合でも、コミットタイムスタンプに基づいて各イベントに正しいスキーマスナップショットを適用します。
スキーマ変更がレプリケーションをブロックする可能性のある従来のデータベースとは異なり、TiDBはテーブルをロックせずに実行されるオンラインDDLをサポートしています。これはCDCにとって独自の課題を生み出します。イベントがキャプチャおよび処理されている間に、スキーマが変化する可能性があるのです。TiCDCは、バックグラウンドでスキーマが変化していても、イベントを正しくデコードするためにスキーマのローカルバージョンを維持する必要があります。マウンターコンポーネントは、スキーマバージョンを追跡し、各イベントのコミットタイムスタンプに基づいて正しいスキーマスナップショットを適用することでこれを処理します。
アーキテクチャの進化:中央集権型から分散型へ
TiCDCの従来のアーキテクチャから新しいTiDB 8.5での設計への移行は、大規模環境におけるCDCのあり方を根本的に再考したことを表しています。以下の表は、主な改善点を示しています。
| 指標 | 従来のアーキテクチャ | 新しいアーキテクチャ (TiDB 8.5以降) |
| 最大スループット | 約700MB/秒 (Ownerがボトルネック) | 線形な拡張性 (単一のボトルネックなし) |
| DDLスループット | 約3DDL実行 / 秒 | ミリ秒未満のレイテンシー、イベント駆動型 |
| イベントストレージ | インメモリ (メモリ不足のリスク) | ディスクベース (PebbleDB) |
| 処理モデル | 50msのタイマーベースのポーリング | イベント駆動型で、ポーリングオーバーヘッドなし |
| Changefeedのサポート | メモリによる制限 | クラスタあたり数百件 (ログサービスを共有) |
| 障害処理 | 中央集権的なオーナー = 単一障害点 | コーディネーターはコントロールプレーンのみ。障害中もレプリケーションは継続される |
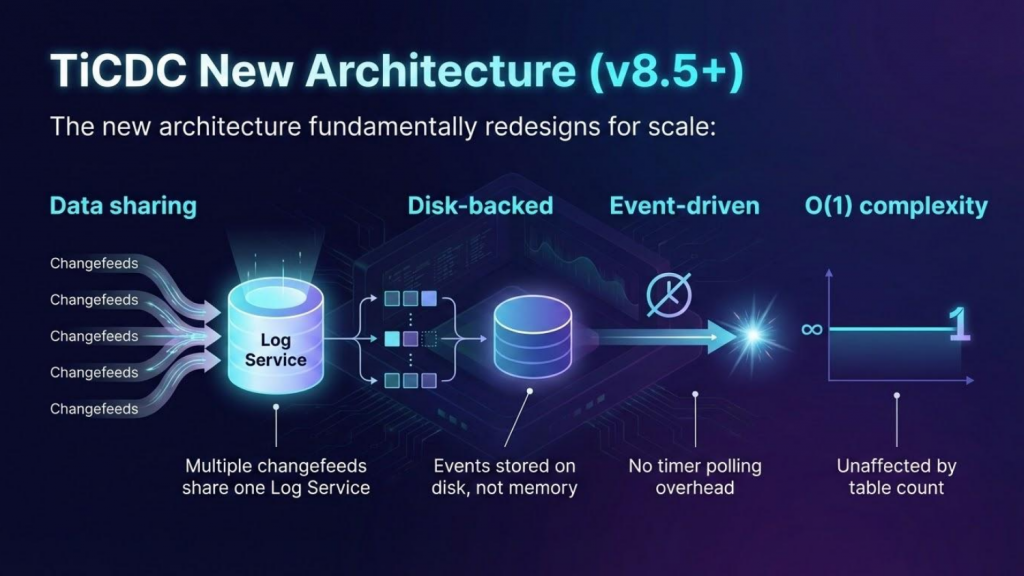
図5:データ共有、ディスクベースのストレージ、およびO(1)の複雑さを備えたTiCDCの新しいアーキテクチャ (TiDB 8.5以降)
新しいTiCDCアーキテクチャのコアとなる設計原則
新しいTiCDCは、3つの主要なアーキテクチャの柱に基づいて構築されています。
分散化
単一障害点は存在しません。サービスはクラスタ全体に分散され、コーディネーターはスケジューリングとメタデータのみを処理します。データそのものには一切触れません。これにより、たとえコーディネーターが故障しても、進行中のレプリケーションは中断されることなく継続されます。
イベント駆動型処理
新しいアーキテクチャは、タイマーベースのポーリングによるオーバーヘッドなしで、高性能な処理を実現します。以前のアーキテクチャの50msタイマーは、DDLスループットにハードルを設けていました。新しいイベント駆動型モデルは、DMLとDDLの両方の変更に対してミリ秒未満のレイテンシーを達成します。
関心の分離
データ収集、ストレージ、および変換の境界を明確にすることで、それぞれが独立してスケーリングできます。ログサービスはダウンストリームアダプタとは独立して拡張でき、コアとなる収集ロジックを変更することなく新しいシンクタイプを追加できます。
TiCDCと他のCDCソリューションの比較
DebeziumやMaxwellなど、最も広く採用されているCDCツールの多くは、シングルライターデータベース向けに設計されています。それらは単一のbinlogまたはWALストリームを消費し、イベントをKafkaや別のメッセージブローカーに転送します。このモデルはMySQLやPostgreSQLではうまく機能しますが、多くのノードで同時に書き込みが発生する分散型データベースを根本的にサポートすることはできません。
TiCDCはいくつかの重要な点で異なります。第一に、単一のログを追跡するのではなく、多くのTiKVノードから並行してイベントを収集します。第二に、グローバルTSOを使用してそれらのストリームをグローバルで一貫した順序にマージします。これは単一ソースのCDCツールでは不要であり、提供できない機能です。第三に、ディスクベースのログサービスと多重化されたgRPCストリームにより、Debeziumコネクタを圧倒してしまうようなリージョン数とスループットレベルを処理できます。すでにTiDBを運用しているチームにとって、TiCDCはネイティブで専用設計のCDCソリューションです。分散型データベースを評価しているチームにとって、そのCDCアーキテクチャは考慮すべき重要な差別化要因となります。
まとめ:リアルタイムデータレプリケーションのクラウドネイティブな未来
TiCDCの歩みは、分散型データベースのためのCDCのスケーリングには、コーディングでの工夫以上のものが必要であることを示しています。それはアーキテクチャの根本的な転換です。分散型、ディスクベース、およびイベント駆動型のモデルに移行することで、TiCDCは現在、線形な拡張性、より高いスループット、そして真のクラウドネイティブな即戦力を提供しています。
これらの改善により、TiCDCは以前は不可能だったワークロードを処理できるようになりました。単一のクラスタで数百のChangefeedをサポートし、数百万のパーティションを持つテーブルをレプリケートし、ネットワークの分断やノード障害が発生している間もトランザクションの整合性を維持します。
参考文献
TiCDCについてさらに深く知りたい方は、以下の追加リソースをご覧ください。
- GitHub上のTiCDC:ソースコード、問題点、およびコントリビューションガイド。
- TiCDCドキュメント:セットアップ、構成、および運用ガイド。
- TiDBアーキテクチャの概要:TiCDCが基盤とする分散型の基礎を理解する。
- TiDBコミュニティ:会話に参加したり、質問したり、フィードバックを共有したりします。
Related Resources

Conference
May 19, 2026
TiDB SCaiLE Europe 2026: Why Engineers Building Agentic AI Should Be in Stockholm on 4 June

Conference
May 12, 2026
TiDB SCaiLE Europe 2026: Speaker Lineup and Session Preview

Product
May 11, 2026
From Preview to Production: TiDB Cloud Dedicated on Microsoft Azure is Now Generally Available
TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。