


複雑なビジネス環境において、リソース分離は安定性、パフォーマンス、そして効率的なリソース利用を確保するために不可欠です。TiDBは、リソース分離を可能にする堅牢な機能を提供し、複数のレベルで効率的なリソース分離を可能しています。
- 物理的な分離:物理的なトポロジーとデータ配置戦略による分離
- ソフトな分離 (フローベースのリソース分離):動的なフロー制御とリソース管理による分離
このブログでは、フローベースのリソース分離のベストプラクティスに焦点を当て、物理的な分離をすることなく、実行時にワークロードを制御し、分離する方法について解説します。
どのようなリソース分離が必要か?
現在のTiDBのリソース制御機能は、ますます高度になっています。データに基づいた分離から、きめ細やかなSQLやバックグラウンドタスクの制御に至るまで、複数のレベルで確実な分離効果を実現できます。
データに基づいたのリソース分離 (物理的分離)
リソース分離と聞いて多くの人がまず思い浮かべるのは、複数のアプリケーションがクラスタを共有する際に、各アプリケーションが使用するリソースをどのように制限するかという点でしょう。
TiDB 6.5で提供される「SQLの配置ルール」機能は、SQLで記述されたルールに基づいたデータ配置戦略です。この戦略により、複数のシステムがTiDBクラスタを共有する場合でも、データレベルでの物理的分離を容易に実現し、物理的分離の要件を満たすことができます。
少数のアプリケーションがクラスタを共有し、リソースを完全に占有する場合
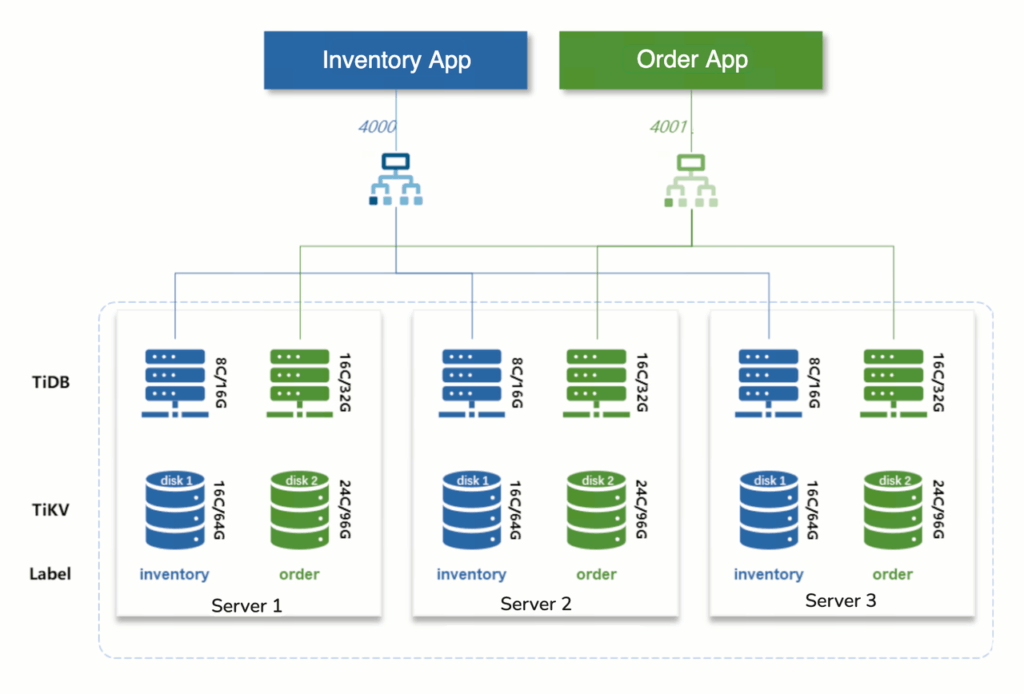
- SQLで記載された配置ルール (定型的な中規模・大規模アプリケーションに適しています)
create placement policy policy_order constraints="[+zone=order]";
create placement policy policy_inv constraints="[+zone=inventory]";
alter database retail_order placement policy policy_order;
alter database retail_inventory placement policy policy_inv;フロー制御ベースのリソース分離 (ソフトな分離)
データ分離スキームは、CPU、メモリ、ディスクなどのリソースを効果的に分離できますが、柔軟性には限りがあります。
- 中規模から大規模なシステムでは、データベースやテーブルを特定のストレージノードに割り当てることでメリットが得られます。
- 設定変更には基盤となるデータの移行が伴う場合があり、完全に適用されるまでに時間がかかります。
- 運用上の複雑さが比較的高くなります。
TiDB 7.1では、分散アーキテクチャにおけるリソース制御の複雑さを簡素化するために、リソース制御機能が提供されています。
- CPU、I/O、ネットワークのリソースをRU (Request Unit) として統一的に抽象化します。
- データベースユーザー、SQLステートメント、バックグラウンドタスクの3つのレベルで分離を提供します。
- データ量の拡張・縮小に対応しており、データ転送なしで数秒で適用され、究極の柔軟性を提供します。
ユーザー (テナント) レベルのリソース制限
小規模なデータベースシステムは一般的にリソース使用率が低い傾向にあります。データベースリソースを決定する際、私たちは直感や標準化された設定に基づいてリソースを選択することが多く、その背後には明確な根拠がない場合があります。さらに、複数のシステムは通常、ピーク負荷時間が異なります。従来のソリューションでは、最大ピークに冗長性を持たせてリソースを割り当てる必要があり、これは必然的に多くの活用されないリソースを生み出していました。
TiDBのリソース制御ソリューションは、より小さな構成で、より効率的なリソース利用を可能にします。複数の小規模データベースシステムをTiDBに統合することで、各システムの実際の負荷ピーク、QPS (Queries Per Second)、その他の要件に基づいて、その割り当てを正確に管理できるようになります。もし、いずれかのシステムが大量のリソースを消費するようなら、専用のTiDBコンピューティングインスタンスを割り当てることができます。

典型的なシナリオ:バッチ処理の負荷分離
システムには、通常、オンライン処理とバッチ処理という2種類の負荷が存在します。たとえば、オンライン処理のピークは日中であり、早朝は基本的にビジネスの閑散期にあたります。この時間帯であれば、システムは大規模なバッチ処理を安全に実行でき、日中のオンラインサービスを妨げることなく、高密度な読み書きタスクを高速に完了させることが可能です。
しかし、バッチ処理が翌日の業務ピーク時までずれ込むケースもあります。この時、バッチ処理を停止させるのは明らかに適切ではありませんし、かといって多くのリソースを消費し続けさせるのも適切ではありません。
従来、データベースには実際には制御手段が不足しており、スケジューリング層やアプリケーション層で限定的な制御を行うしかありませんでした。TiDBのリソース制御機能は、このような状況を簡単に管理できます。
- バッチ処理用に個別のユーザーを作成し、リソースグループに割り当てる。
CREATE USER 'USER_BATCH' IDENTIFIED BY '******';
CREATE RESOURCE GROUP rg_batch RU_PER_SEC = UNLIMITED PRIORITY = HIGH;
alter user 'USER_BATCH' RESOURCE GROUP rg_batch;
-- If the batch task runs overtime into the next day, simply execute the following SQL to immediately limit its rate
ALTER RESOURCE GROUP rg_batch RU_PER_SEC = 100000 PRIORITY = LOW;典型的なシナリオ:SaaS

上記の第3のマルチテナントアーキテクチャパターンで示されているように、複数のテナントが同じテーブルのセットまたはデータベースを共有します。異なるSaaSテナントのデータは、パーティショニングによってテーブルに保存されるか、あるいは単一のテーブルを直接使用し (テーブル内のtenant_idフィールドで区別)、そこに格納されます。
数千ものテナントを抱えるSaaSのシナリオにおいて、TiDBのリソース制御機能は、CPU/メモリ/ノード数を分割することなくリソースを統一的かつ抽象的に扱います。これにより、データベースユーザーレベルでのリソース制御を容易に実現でき、制限の変更も簡単です。その利点は、クラスタの実際の状況に基づいて動的に調整できるため、非常に高い柔軟性を提供することです。

- テナント1が非常に大きなボリュームを持つと仮定した場合、そのために個別のデータベースユーザー (user1) を作成できます。さらに、このユーザーには、高い優先度とリソースの超過使用を許可する独立したリソースグループを作成することが可能です。
CREATE RESOURCE GROUP rg_tenant1 RU_PER_SEC = 1000000 PRIORITY = HIGH BURSTABLE;
alter user 'user1' RESOURCE GROUP rg_tenant1;- 規模が小さい他のテナントは、同じリソースプールを共有します。
CREATE RESOURCE GROUP rg_tenant_default RU_PER_SEC = 500000 PRIORITY = MEDIUM;
alter user 'user_default' RESOURCE GROUP rg_tenant_default;- リソースの拡張
ALTER RESOURCE GROUP rg_tenant_default RU_PER_SEC = 900000 PRIORITY = MEDIUM;SQLステートメントレベルの分離
TiDB 7.2で導入されたリソース制御は、実行に予想以上の時間を要したり、リソースを過剰に消費したりするランナウェイクエリに対する管理機能を提供します。
- QUERY_WATCH (手動処理):発見されたSQLの実行を制限します。
- QUERY_LIMIT (自動処理):予期せぬSQLが発生した場合、データベースがそれを認識し、自己適応的に処理します。
典型的なシナリオ:SQLとサーキットブレーカー (QUERY_WATCH) による実行制限
一部のSQLステートメントでは、不適切な記述や特定のシナリオ (数値の抽出など、大量のデータ問い合わせが必要な場合) によって、実行時に多くのリソースを消費してしまう状況が発生することがあります。実行が遅くなるのは許容できても、あまりに多くのリソースを消費して通常の業務リクエストに影響を与えることは避けたいでしょう。TiDBのリソース制御機能を使えば、そのようなSQLステートメントの実行を簡単に制限できます。
-- When this SQL is executed, it is executed using only the rg1 resource group (rg1 is a resource of 100 RU).
SELECT /*+ RESOURCE_GROUP(rg1) */ * FROM t where is_delete=0 and create_time>='2023-01-01';
-- Lower the priority of this SQL in the default resource group to allow it to execute in a rate-limited manner.
QUERY WATCH ADD RESOURCE GROUP DEFAULT ACTION COOLDOWN SQL TEXT EXACT TO 'select * FROM t where is_delete=0 and create_time>='2023-01-01'加えて、これまでに実行されたことのない大規模なSQLがシステムに突然現れる状況も考えられます。その発生源は不明なため、そのようなSQLは直接ブロックし、実行を阻止したいと考えるでしょう。
-- Intercept and terminate based on the SQL DIGEST dimension.
QUERY WATCH ADD RESOURCE GROUP default ACTION KILL SQL DIGEST 'd08bc323a934c39dc41948b0a073725be3398479b6fa4f6dd1db2a9b115f7f57';
-- Additionally, you can use the SQL TEXT dimension (to individually intercept SQL with a specific condition value).
-- "as well as the PLAN DIGEST dimension (which can intercept the occurrence of a poor plan in SQL)"典型的なシナリオ:予期しないクエリの自己適応管理 (QUERY_LIMIT)
QUERY_WATCHベースの限定的な実行制限とサーキットブレーカーソリューションは、イベント発生中または発生後に手動で処理する方法です。これらの問題の出現と発見から最終的な解決に至るまでには、多くの場合時間がかかります。たとえシステムに精通した経験豊富な管理者であっても、問題を解決するには数分、あるいはそれ以上の時間を要することも珍しくありません。これは、ビジネスが影響を受ける時間もそれに比例して長くなる可能性があることを意味します。
QUERY_LIMITは、より柔軟な自己適応型 (Self-Adaptation) 処理方法を提供し、データベースが例外的な処理を自動的に発見・処理できるようにします。私たちは、例外を定義するだけで済みます。
- 制限を100,000RUとする
rg_auto_cooldownリソースグループを作成します。このリソースグループ内で実行に60秒以上かかるクエリをランナウェイクエリとして定義し、システムが自動的に暴走クエリの優先度を下げ、実行を制限するように設定できます。
CREATE RESOURCE GROUP rg_auto_cooldown RU_PER_SEC = 100000 QUERY_LIMIT=(EXEC_ELAPSED='60s', ACTION=COOLDOWN);- 制限を100,000RUとする
rg_over_10000リソースグループを作成します。このリソースグループ内で、1秒あたり10,000RUを超えるクエリをランナウェイクエリとして定義し、システムが自動的にそれらの優先度を下げ、実行を制限するように設定できます。
CREATE RESOURCE GROUP rg_colldown RU_PER_SEC = 100000 QUERY_LIMIT=(RU=10000, ACTION=COOLDOWN);- 現在のリソースグループ内で大規模なクエリを他のリソースグループに分離することも可能です。例えば、
defaultのリソースグループにおいて100万行を超えるデータを処理するクエリをランナウェイクエリとして定義します。これにより、システムは自動的にそのクエリをrg_bigqueryリソースグループに配置し、現在のリソースグループ内のリクエストとの競合を回避できます。
CREATE RESOURCE GROUP rg_bigquery RU_PER_SEC = 10000 PRIORITY = LOW;
-- Assume the current resource group is default.
ALTER RESOURCE GROUP default QUERY_LIMIT=(PROCESSED_KEYS=1000000, ACTION=SWITCH_GROUP(rg_bigquery));バックグラウンド・タスクレベルの分離
日常的な運用とメンテナンスにおいてインデックスの作成は一般的なタスクです。TiDBではすべてのDDLがオンラインで実行されますが、インデックス作成時のリソース消費リスクを無視することはできません。TiDB 7.4のリソース制御機能は、バックグラウンドタスクの管理を導入しました。
- インデックス作成のDDLタスクを例にすると、DDLをバックグラウンドタスクとして設定し、TiKVノードの総リソースの最大30%に制限できます。この際、システムはこのタスクのリソース使用量を動的に制限し、実行中に他のフォアグラウンドタスクのパフォーマンスへの影響を最小限に抑えます。
ALTER RESOURCE GROUP `default` BACKGROUND=(TASK_TYPES='ddl', UTILIZATION_LIMIT=30);- 現在、TiDBは以下の種類のバックグラウンドタスクをサポートしています:Lightning、br、ddl、そしてstatsです。
まとめ
本ブログを通じて、TiDBのリソース分離機能についてより包括的にご理解いただけたことと思います。今後、皆様がそれぞれのシナリオ要件に応じて適切なリソース分離ソリューションを選択し、システムの安定性を確保しつつ、リソース利用率を継続的に向上させられることを願っております。
| 分離スキーム | 典型的シナリオ | 技術的実装 |
| データに基づく分離スキーム | 中規模システムと大規模システムの分離 | SQLによる配置ルール |
| システム内の異なる負荷分離 (読み書き分離など) | ||
| フロー制御ベースの分離スキーム | データベース・ユーザーの分離 (例:複数の小規模システム、SaaSシナリオ) | リソースコントロール |
| SQLステートメントを手動で分離 (実行制限、サーキットブレーカー) | ||
| リソースグループ内の異常なSQLを自動的に分離する | ||
| バックグラウンド・タスクレベルの分離 (DDL、バックアップ、派生処理など) |
TiDBのリソース分離機能が実際にどのように動作するかは、無料のテストクラスタを起動することで体験できます。また、弊社のデータベース専門家にご相談いただくことも可能です。



TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。