

※このブログは2026年1月22日に公開された英語ブログ「Memory Fragmentation in Linux: What It Is, Why It Hurts, and How to Fix It」の拙訳です。
高性能なデータベース環境におけるメモリ管理は、単に十分なサイズのRAMを確保するだけでなく、そのRAMがどのように構成されているかが重要です。SREやDBAにとって、Linuxカーネルのメモリ管理の微妙な違いを理解することは、システムの安定稼働と予測不能なテールレイテンシが発生するかの分かれ目となります。
このブログでは、Linuxにおけるメモリフラグメンテーションの核となるメカニズムを紐解きます。バディアロケータの内部構造や、その主要な防御策であるページマイグレーションタイプについて深く掘り下げるとともに、Transparent Huge Pages (THP) とhugetlbの間にある、パフォーマンス上の重要なトレードオフを明確にします。最後に、/proc/buddyinfoやftraceを活用した具体的な診断ワークフローを紹介します。これにより、TiDBのような本番環境において、メモリコンパクション がテールレイテンシにどのような影響を与えているかを定量化する手法を解説します。
60秒でわかるメモリフラグメンテーション
Linuxカーネルの文脈において、メモリフラグメンテーションとは物理RAMがどのように割り当てられ、使用されているかを指す概念です。これはディスクのデフラグメンテーションとは異なり、特にRAMとカーネルメモリに特有の問題です。中核となる制約は連続メモリ割り当てにあります。カーネルを効率的に動作させるには、メモリブロックが物理的に隣接している必要があることが多いためです。
これらの連続したブロックが分断されると、たとえ数ギガバイトの「空き」メモリがあったとしても、カーネルは必要とするサイズの単一の連続ブロックを見つけられず、その結果として性能低下を引き起こす可能性があります。
内部フラグメンテーションと外部フラグメンテーション (Linuxにおける現状)
パフォーマンスの問題を診断するためには、まずフラグメンテーションの2つの種類を区別する必要があります:
- 内部フラグメンテーション:これは、カーネルが実際に要求された量よりも多くのメモリを割り当てた場合に発生します。割り当てられたブロックの内部に「無駄な」領域が存在しますが、その領域は他の用途に使用することができません。
- 外部メモリフラグメンテーション:これはシステム性能にとって最も重要な問題です。システム内に空きメモリが存在しているにもかかわらず、それらが小さく非連続な「穴」として分散している状態を指します。その結果、トータルの空きメモリ量は十分であっても、大きな連続ブロックの要求は失敗することになります。
なぜ仮想メモリだけでは不十分なのか (カーネルとDMAの制約)
物理的に連続していないページを連続した仮想アドレス空間にマッピングできる仮想メモリの時代において、なぜフラグメンテーションが問題になるのか疑問に思うかもしれません。仮想的な連続性はアプリケーションにとっては有用ですが、カーネルやハードウェアにはより厳しい要件が存在します:
- カーネルのリニアマッピング:特定のカーネルサブシステムは、性能の観点からリニアマッピングに依存しており、物理的に連続したメモリを必要とします。
- デバイスI / OとDMA:Direct Memory Access (DMA) により、ハードウェアデバイスはCPUを介さずにデータを転送できます。現代のデバイスの中には「スキャッタ・ギャザーDMA」をサポートするものもありますが、多くの旧式デバイスや特殊なデバイスは、依然として物理的に連続した大きなバッファを必要とします。
バディアロケータ:Linuxのページオーダーがどのようにフラグメンテーションを生むのか
Linuxは、物理メモリをバディアロケータを用いて管理しています。これはメモリを「オーダー (Order)」単位で階層化する仕組みで、オーダー0は単一ページ (通常4KB)、オーダー1は2ページ (8KB) というように、オーダーが1上がるごとにサイズが倍増していきます。
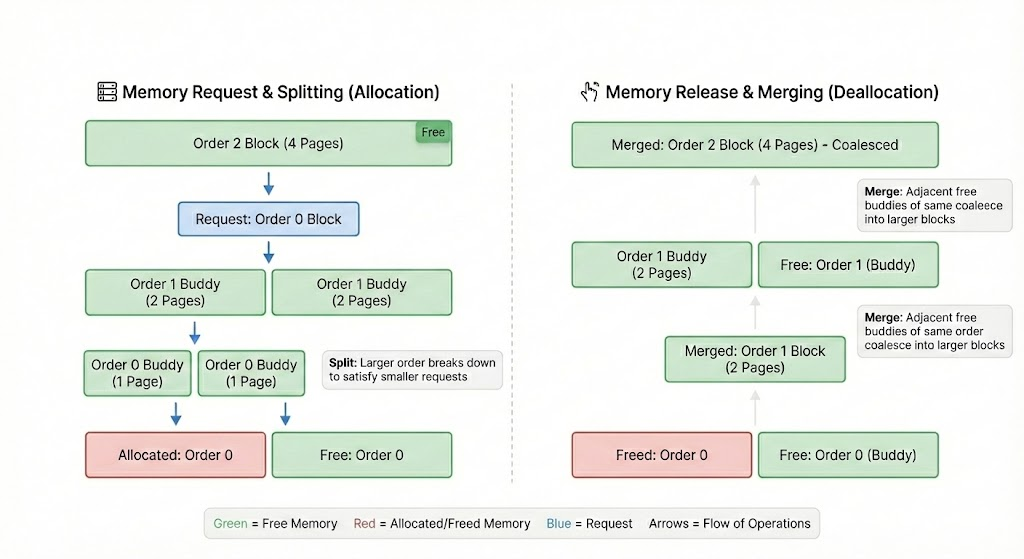
図1. Linuxのバディアロケータにおけるブロックの分割と結合
高いオーダーの割り当て、つまり大きな連続メモリブロックが要求されると、アロケータはより大きなブロックを分割して「バディ(相棒)」を生成します。逆に、メモリが解放されると、それらは再び結合して元の大きなブロックに戻ります。このとき、小さく移動不可能な割り当てがメモリマップ全体に散在していると、高いオーダーのブロックが不足するようになり、バディ同士が結合できなくなります。その結果としてフラグメンテーションが発生します。
スラブアロケータ (SLUB / SLAB) の役割と位置付け
バディアロケータが巨大なページ単位のメモリブロックを管理する一方で、スラブアロケータ (現代のカーネルでは主にSLUBが採用されています) は、タスク記述子やiノードといった小規模なオブジェクトを管理します。スラブアロケータは最終的にバディアロケータからページを消費します。スラブの増加が大きい場合、連続したページブロックへの圧力が高まり、外部フラグメンテーションの原因となることがあります。
ページマイグレーションとマイグレーションタイプ:Linuxにおけるフラグメンテーション対策の第一歩
フラグメンテーションに対抗するため、Linuxカーネルはメモリページをマイグレーションタイプごとに分類してします。「移動不可能なページ」が本来コンパクト化可能なブロックを汚染するのを防いでいます:
- MIGRATE_UNMOVABLE:カーネルによって割り当てられたページなど、移動が不可能なページ。
- MIGRATE_MOVABLE:ユーザ空間のアプリケーションで使用される、移動可能なページ。
- MIGRATE_RECLAIMABLE:ファイルキャッシュのように、破棄して解放することが可能なページ。
カーネルが優先されるマイグレーションタイプから要求を満たせない場合、「フォールバック」割り当てを実行します。このフォールバック動作が頻発している状態は、外部メモリフラグメンテーションが深刻化している明確なシグナルとなります。
Huge Pages, hugetlb, および Transparent Huge Pages (THP):断片化が「コスト」に変わる瞬間
TiDBのような分散SQLデータベースは、ページテーブルの参照オーバーヘッドを削減できるHuge Pagesの恩恵を大きく受けます。しかし、Huge Pagesは広大な連続領域 (2MBや1GBなど) を必要とするため、メモリの断片化 (フラグメンテーション) による影響をより顕著に受けることになります。
| 機能 | Transparent Huge Pages (THP) | hugetlb | 明示的な Huge Pages |
| 割り当て | カーネルによる自動割り当て | 起動時または実行時の事前確保 | 手動管理 |
| 複雑性 | 低 (プラグ&プレイ) | 中 | 高 |
| 予測可能性 | 低 (レイテンシ急増の要因) | 高 | 高 |
| ユースケース | 一般的なワークロード | データベース / 低遅延要求 | 特殊なハイパフォーマンス用途 |
データベースでTHPを無効化すべきタイミング (およびその代替案)
Transparent Huge Pages (THP) はメモリ管理の簡素化を目的としていますが、データベースにおいては深刻なレイテンシのスパイクを引き起こす原因となります。カーネルのバックグラウンドスレッドである「khugepaged」が連続したメモリ領域を見つけられずにいるすると、強引なコンパクションが実行され、結果として処理の停止が発生します。
本番環境のデータベースにおいては、THPを無効化し、代わりに明示的な巨大ページ (hugetlb) を使用するのが標準的な運用のデフォルトです。これにより、起動時にメモリ領域が確実に確保され、予測可能なパフォーマンスが担保されます。詳細については、データベースにおけるTransparent Huge Pages (THP) ガイドを参照してください。
メモリコンパクション:Linuxが連続した空き領域を再構築する仕組み
メモリコンパクションとは、カーネルが移動可能なページを移動させて、より大きな連続した空き領域を作るプロセスのことです。
必須の処理ではありますが、コンパクションは両刃の剣にもなり得ます。 「直接コンパクション」は、プロセスが割り当て要求の際にカーネルによるメモリのデフラグが終わるまで待たされる場合に発生し、大きなレイテンシスパイクやパフォーマンスの急降下を引き起こすことがあります。
メモリフラグメンテーションの検出方法 (重要なコマンド)
フラグメンテーションを診断するには、freeやtopのような基本的なツールだけでは不十分です。
/proc/buddyinfo:各メモリゾーンでのオーダーごとの利用可能ブロック数を表示。オーダー0は多いのにオーダー10が少ない場合、システムは深刻なフラグメント化が発生しいます。/proc/pagetypeinfo:マイグレーションタイプの分布や、フォールバックがどれくらい発生しているかを確認できます。- Fragmentation Index:一部のカーネルでは、/sysを通じてフラグメンテーションの深刻度を定量化できます。
外部フラグメンテーションイベントをftraceで測定 (ステップバイステップ)
リアルタイムでフラグメンテーションイベントを取得するには、ftraceを利用します:
- イベントを有効化:
echo 1 > /sys/kernel/debug/tracing/events/kmem/mm_page_alloc_extfrag/enable - データを収集:
cat /sys/kernel/debug/tracing/trace_pipe > frag_log.txt - 結果の解釈:Look for “fallback” events. An example event line might look like this:
mm_page_alloc_extfrag: page=0x12345 pfn=74565 alloc_order=9 fallback_order=0 - awkで解析:
awk '/fallback_order/ {print $NF}' frag_log.txt | sort | uniq -c - トレースを無効化:
echo 0 > /sys/kernel/debug/tracing/events/kmem/mm_page_alloc_extfrag/enable
本番データベースサーバー向け性能低下の緩和チェックリスト
データベース向けに健全なLinux環境を維持するため、以下を確認しましょう:
- [ ] 高いオーダー依存の抑制:実行時に巨大な連続ブロックを必要とするようなカーネルレベルの設定を避ける。
- [ ] Huge Page戦略の策定:THPとhugetlbのどちらを使用するか意図的に選択する。データベースでは通常、明示的なHuge Pages (hugetlb) が好まれます。
- [ ] パフォーマンス・ベースラインの確立:コンパクションやフォールバックイベントのベースラインを策定し、急激なスパイクを検知・アラートできるようにする。
- [ ] システム挙動のトレース:ftrace などのツールを使用して、本番環境への影響を最小限に抑えつつLinuxシステムの挙動を追跡する。
TiDBのワークロードにおける重要性 (予測可能なテールレイテンシ)
TiDBのような分散データベースでは、一貫したパフォーマンスがサービスレベル目標 (SLO) の達成に不可欠です。 メモリフラグメンテーションがバックグラウンドのコンパクションやダイレクトリクレームを引き起こすと、それはそのままデータベースのテールレイテンシに直結します。 カーネルレベルのボトルネックを理解し対策することで、負荷が高い状況でも予測可能なパフォーマンスを提供できるデプロイ環境を安定して維持できます。
TiDBが高性能ワークロードをどのように処理するか、ご覧になりませんか? 手動でのシャーディングなしでMySQLワークロードをモダナイズしたり、Linuxカーネルのメモリフラグメンテーションについてさらに深く学べる「続き (パートII)」で、より高度な技術的インサイトを得ることができます。
FAQ:Linuxにおけるメモリフラグメンテーション (一問一答)
RAMは断片化されることがありますか?
はい。RAMにはハードディスクのような物理的な駆動部はありませんが、ここでの「フラグメンテーション」とは、Linuxカーネルが特定の操作で必要とする連続した物理メモリ領域が不足している状態を指します。
現代のカーネルでもフラグメンテーションは問題ですか?
はい。現代のカーネルではコンパクションアルゴリズムやマイグレーションタイプが改善が進んでいますが。しかしHuge Pageの利用増加や大容量RAMの普及により、フラグメンテーションの影響はさらに大きくなっています。
コンパクションは常に効果的ですか?
必ずしもそうとは限りません。連続した領域を解放する一方で、ページ移動に伴うCPUオーバーヘッドがパフォーマンス低下を引き起こす可能性があり、特に「ダイレクトコンパクション」時にはその悪影響が利点を上回る場合があります。



TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。