

※このブログは2025年10月31日に公開された英語ブログ「How Distributed ACID Transactions Work in TiDB」の拙訳です。
トランザクション、特に分散型ACIDトランザクションは至る所に存在しています。また、私たちがすぐに気づかなくても、トランザクションを取り巻くプロトコルも同様に至る所に存在しています。
例として、一般的な結婚式を考えてみましょう。これは本質的に、二相コミット (2PC) プロトコルです。式を執り行う司式者がトランザクションコーディネーター (TC) であり、結婚するカップルがアクティブな参加者です。第一段階では、TCは各参加者に対し、「コミットしてもよろしいですか」(つまり、「誓いますか (I do)」) と尋ねます。両者が「コミットしてもよい」(つまり「誓います」) と答えて初めて、司式者は詳細を書き込み、婚姻届にタイムスタンプをコミットできます。これが正式にトランザクションをコミットすることになります (すなわち、第二段階として、カップルを夫婦であると宣言します)。
このブログでは、広く使われているオープンソースの分散型SQLデータベースであるTiDBの視点を通して、分散型ACIDトランザクションをさらに深く掘り下げていきます。具体的にはTiDBが分散システムという文脈でどのように分散型ACIDトランザクションをサポートしているのかを明らかにします。
クラウドネイティブな世界においてACIDトランザクションが依然として重要な理由
データベースの世界 (現実の世界でも) において、あらゆるトランザクションの根底にある基本的な考え方は、4つの「ACID」特性です。
- 原子性:トランザクション内のすべての操作が完了するか、あるいは一つも完了しないかのどちらかです (先の例で言えば、カップルが結婚するか、しないかのどちらかです)。
- 一貫性:システムの状態が、ある一貫性のある状態から、別の一貫性のある状態へと移行します。先の例では、参加者が独身の状態から既婚の状態へと移行します。
- 隔離性:トランザクションが同時に実行された場合でも、それらの実行結果は、あたかも何らかの順序で一つずつ実行されたかのように整理されます。したがって、もし司祭が合同結婚式を執り行う場合、司祭は「誓います」という言葉が混ざって混乱が生じないように保証します。ここで私たちは主にトランザクションの一貫性に関心があります。
- 永続性:トランザクションが一度完了 (コミット) すると、その変更は永続的になります。先の例に戻ると、もし誰かが翌朝目覚めて、それがすべて悪夢だったと主張しても、婚姻届にはコミットの証明が残っています。離婚するには、新しいトランザクションを開始する必要があります。
クラウドネイティブ・アーキテクチャにおいては、これらの保証の確保はより困難になり、そしてより不可欠なものとなります。分散型データベースはリージョンや障害ドメインをまたいで展開され、ノードはいつでも参加、離脱、または故障する可能性があります。耐障害性と高可用性は、リーダーが変更されること、そしてレプリカが状態を破壊することなく追いつくことを意味します。ACIDは、これらすべてを通して安全を確保するレールを提供します。ネットワークが一瞬途切れたり、ノードが消滅したりしても、アプリケーションは正確で順序付けられた結果を目にします。
これは、注文、支払い、在庫、ユーザーセッションといった、多くの小さく同時並行的な更新が同じレコードに集中する高スループットのOLTPシステムで最も重要になります。ACIDがなければ、負荷がかかった際にテールレイテンシーの急増、二重支払い、ファントムリード、古いビューなどが本番環境に紛れ込む可能性があります。一方、楽観的並行性制御、先行書き込みログ、スナップショット読み取り、および慎重な競合解決といった堅牢なトランザクション管理があれば、水平スケールと予測可能な正確性という、両方の利点を享受できます。
要するに、ACIDはレガシーな制約ではありません。それは、クラウドネイティブ・サービスが整合性を犠牲にすることなく、自信を持ってスケールすることを可能にする技術的基盤なのです。
TiDBの分散データベースアーキテクチャの内部
TiDBは、コンピュートとストレージのアーキテクチャが分離された高可用性な分散型データベースであり、シームレスな水平スケーリングを可能にします。このスケーラビリティにより、TiDBクラスター内のストレージノードとコンピュートノードを動的にサイズ変更できます。しかし、この柔軟で分散された構造は、モノリシックなアーキテクチャと比較して、特有の考慮点があります。
TiDBの高可用性 (HA) アーキテクチャは、TiDBデータベースの信頼性と継続的な運用を保証します。TiDBのHAソリューションは堅牢であり、ハードウェア障害やその他の中断に直面した場合でも、継続的な可用性、耐障害性、および復元力を提供するように設計されています。TiDB のHAソリューションの主要な機能には以下が含まれます。
- 自動フェイルオーバー:ノード障害が発生した場合、Raftコンセンサスアルゴリズムが自動的なリーダー選出とフェイルオーバーを促進します。これにより、手動介入なしにシステムがシームレスに機能し続けることが保証されます。
- ロードバランシング:TiDBは、ワークロードをクラスタ全体に均等に分散するためのロードバランシングメカニズムを組み込んでいます。これは、リソースのボトルネックを防ぎ、パフォーマンスを最適化します。
- モニタリングとアラート:TiDBには、管理者がクラスターの健全性とパフォーマンスを追跡するのに役立つ組み込みのモニタリングおよびアラートツールが付属しています。これは、プロアクティブな管理と潜在的な問題への迅速な対応を促進します。
TiDBクラスターの主要コンポーネント
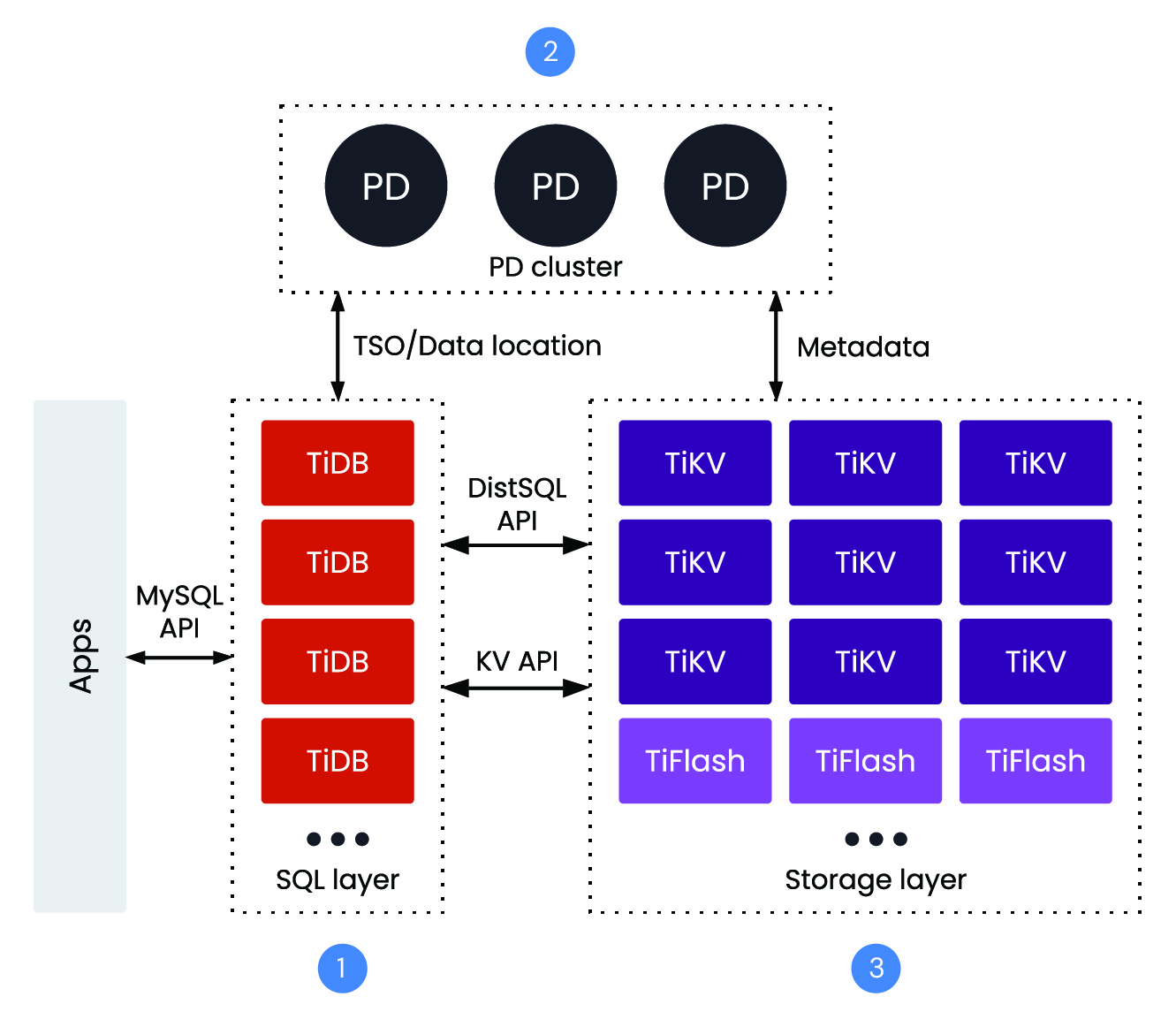
- 1. TiDB Server:ステートレスなSQLレイヤーで、MySQLと互換性があり、コンピュートとストレージを分離することでスケーリングを容易にします。各ノードは読み取りと書き込みの両方を受け付けられます。
- 2. PD (Placement Driver):PDは、メタデータとクラスターのトポロジー管理を担当します。
- 3. TiKV (multi version concurrency controlを備えたストレージ):TiDBが使用する分散トランザクショナル・キーバリューストアです。データレプリケーションのためにRaftコンセンサスアルゴリズムを採用しており、複数のノード間でデータの一貫性と高可用性を保証します。
TiDBクラスタは、ネットワーク経由で通信する多様なサービスで構成されています。上記の図で赤枠で示されている焦点は、TiDBサーバーのエンドポイントです。このエンドポイントは、MySQLプロトコルの処理役を担い、SQLパーサーとオプティマイザーを含んでいます。また、トランザクションコーディネーター (TC) の役割も果たします。
この議論でTiDBクラスタという言葉を用いる場合、私たちは連携して動作するすべてのサービスを指します。簡潔にするため、エンドポイントおよびSQLサービスをTiDBと表記します。
TiDBクラスタは、ステートレスなSQLコンピュート層 (TiDB Server) と、Placement Driver (PD) によって調整される分散ストレージ層 (TiKV) を分離することでスケールします。TiKVはテーブルをRaft経由で複製される小さなリージョン (Region) に分割します (リーダーが書き込みを処理し、フォロワーがレプリケーションを行い、自動フェイルオーバーが実行されます)。また、レプリカの配置場所を制御する配置ルール (Placement Rules) や、オプションのフォロワーリード機能も備えています。水平スケールは弾力的かつオンラインで行われます。リージョンは分割され、PDがノード間でそれらをリバランスします。ダウンタイムなしに、容量/スループットのためにTiKVを追加したり、並行性のためにTiDB Serverを追加したりできます。HTAP (Hybrid Transaction/Analytical Processing) のため、TiFlashはカラム型レプリカを保持するため、オプティマイザーは分析処理をTiFlashにルーティングしつつ、OLTPはTiKVで継続され、ETLなしで耐障害性と安定したテールレイテンシーを提供します。
より詳細な情報は、こちらのドキュメントから確認できます。トランザクションに関して、重要な2つのサービスはPlacement Driver (PD) とTiKVです。
TiDBが大規模環境でACIDトランザクションを保証する方法
TiDBクラスタは、分散ストレージシステムにおけるネットワーク関連の課題に対処するための基盤要素として、Raftコンセンサスプロトコルを活用しています。Raftは、トランザクションモデルに対して堅牢性を提供します。
TiDBクラスタ内のトランザクションは、開始タイムスタンプとコミットタイムスタンプを特徴としています。コミットタイムスタンプは、変更を外部化し、他のトランザクションから可視にするために不可欠です。生成されるタイムスタンプは、グローバルな一意性と単調増加する値という2つの重要な制約を遵守しなければなりません。単一障害点を防ぐため、PD (Placement Driver、すなわちメタデータサーバー) のクラスターが、他の責務に加えてタイムスタンプの生成を処理します。
分散トランザクションのためのパーコレーターアルゴリズム
Googleで開発され、高スループット要件を持つ大規模なスケール向けに設計されたPercolatorアルゴリズムは、TiKVにおける分散トランザクションを実装しています。元々Googleの検索エンジンにおけるウェブクロールや増分ドキュメントインデックス作成のために開発されたPercolatorは、並列性を高めるためにスナップショット分離 (SI) を使用しています。SIの仕組みについては、以下の詳細な説明を参照してください。
TiDBクラスターにおけるPercolatorアルゴリズムの実装は、オンライン・トランザクション処理 (OLTP) 向けに最適化されています。TiDBのトランザクション最適化に関する詳細は、OLTPシナリオ向けに調整された具体的な最適化について説明しています。さらに、TiDBでは、すべてのキーがTiKV上の単一のプリライトでコミットされる一般的なケースでは、1PC (一相コミット) を使用します。
Percolatorの設計の特筆すべき特徴の一つは、トランザクションコーディネーター (TiDB SQL ノード) がステートレスであることです。これにより、ローカルに状態を永続化する必要がなくなります。ただし、最適化として、コミットされていないトランザクションをローカルにバッファリングする場合がありますが、これは前述の1PC最適化のケースで役立ちます。TiKVのクラスターが、ロックとその状態を保存します。プリライトロックは永続化されますが、長期間ではありません。これにより、プリライトロックが残ったままコーディネーターが稀に失敗した場合でも、影響を最小限に抑えることができます。
トランザクションステータスの単一のチェックと、オプションのロック解除 (resolve lock) RPC によって、関連するキーの読み書きの競合が効率的に処理されます。TiDB (TC) ノードでのトランザクション解決状態のキャッシングや、あるリージョンに関連するすべてのトランザクションロックを単一の操作で解決するといった最適化により、オーバーヘッドはさらに削減されます。この遅延クリーンアップ設計は、極めて低いレイテンシ要件のシナリオであっても、OLTPシステムに無視できる程度の影響しか与えません。さらに、トランザクションコンテキストの維持という複雑さを軽減します。
パーコレーターアルゴリズムの実践
Percolatorアルゴリズムは、内部でロックとタイムスタンプを使用して、私たちが求めるトランザクションのACID保証を提供します。オブジェクト (例えば、我々の例におけるノード A、B、C) 上のグローバルな (T2.start) タイムスタンプが、T2のスナップショットを構成します。
MySQL/InnoDBとの互換性を保つため、TiDBはスナップショット分離 (Snapshot Isolation) をリピータブルリード (Repeatable Read) として公称しています。この点には、注意すべき微妙な違いがあります。
Percolatorアルゴリズムをよりよく理解するために、例を通して見ていきましょう。この例では、Bobが自分の口座からAliceの口座へ10ドルを送金したいとします。
ステップ1:アカウントの設定
まず、両方の口座にいくらかの資金を入れた状態で、アカウントをセットアップします。
CREATE TABLE T (ac VARCHAR(20) PRIMARY KEY NOT NULL, balance DECIMAL(8,2));
BEGIN;
INSERT INTO T VALUES("Bob", 110);
INSERT INTO T VALUES("Alice", 90);
COMMIT;以下の数字7と6は、トランザクションの開始タイムスタンプです。「Write」列にある”7: Data@6″は、タイムスタンプ6におけるKeyの「Data」列の値への「ポインター」であることを意味します。これを別の方法で解釈すると、以下のようになります。
Bobの残高 := Bob.Data.find(6); // := 110
| キー | データ | ロック | 書き込み |
| Bob | 7: 6: 110 | 7: 6: | 7: Data@6 6: |
| Alice | 7: 6: 90 | 7: 6: | 7: Data@6 6: |
ステップ2:口座への送金
次に、Bobの口座からAliceの口座へ資金を送金します。
BEGIN;
UPDATE T SET balance = balance - 10 WHERE ac = 'Bob';
UPDATE T SET balance = balance + 10 WHERE ac =' Alice';
COMMIT;トランザクションには2つのフェーズがあります。まず、ロックを獲得するプリライト・フェーズ、そして次にロックが解放され、値が外部化されるコミット・フェーズです。プリライト・フェーズでは、Bobの口座へ一時的な書き込みが行われます。これは「書き込み」列を見ることで確認できます。そこには、最後にコミットされたポインターが依然として古い値 (110) を指していることがわかります。
Percolatorには、プライマリロックとセカンダリロックの概念があります。この概念では、セカンダリロックは、前述と同じポインター構文を使用してプライマリロックを指します。
「プライマリ」ロックは、トランザクションの行セットからランダムに選択された行です。これは、すべてのセカンダリロックが指し示すロックを保持するキーであり、それ以外の特別な意味はありません。
| キー | データ | ロック | 書き込み |
| Bob | 8: 100 7: 6: 110 | 8: primary 7: 6: | 8: 7: Data@6 6: |
| Alice | 7: 6: 90 | 7: 6: | 7: Data@6 6: |
ステップ3:アカウントを更新する
次に、Aliceの口座を更新します。これもまた一時的な書き込みです。今回はセカンダリロックを獲得します。このロックは、同じタイムスタンプ (8) で Bob が保持しているプライマリロックを「指し示して」います。
| キー | データ | ロック | 書き込み |
| Bob | 8: 100 7: 6: 110 | 8: primary 7: 6: | 8: 7: Data@6 6: |
| Alice | 8: 100 7: 6: 90 | 8: primary@Bob 7: 6: | 8: 7: Data@6 6: |
次に、私たちは第二フェーズを実施します。このフェーズでは、データのコミット、ロックの解放、そしてデータの外部化を行います。コミットとロック解放後の両方の残高の新しい状態は、「書き込み」列のポインターに従います。
Bobの残高 := Bob.Data.find(8); // := 100
Aliceの残高 := Alice.Data.find(8); // := 100
| キー | データ | ロック | 書き込み |
| Bob | 9: 8: 100 7: 6: 110 | 9: 8: 7: 6: | 9: Data@8 8: 7: Data@6 6: |
| Alice | 9: 8: 100 7: 6: 90 | 9: 8: 7: 6: | 9: Data@8 8: 7: Data@6 6: |
二相コミットプロトコルの動作
このセクションでは、以下のフロー図に示されているように、TiDBがTiKVリージョンをまたいで二相コミットを実行するプロセスを順を追って説明します。

0) 開始とタイムスタンプ:TiDBサーバーはトランザクションを開始し、PDから単調増加するstart_ts (開始タイムスタンプ) を取得します。これにより、スナップショット分離と一貫性のある読み取りビューが確立されます。
1) プライマリキーの選択:このトランザクションによって変更されるすべてのキーの中から、TiDBは一つをプライマリとして指定し、残りをセカンダリとします。このプライマリの運命が、クライアントに返される最終的な結果を決定します。
2) フェーズ1 — プリライト:TiDBは、関連するすべてのTiKVリージョンに対してプリライトRPCを並行して発行します。各リージョンは (MVCCバージョンに基づいて) 競合を検証し、競合が見つからない場合は、今後の書き込みのためにロックを配置します。いずれかのプリライトが失敗した場合、TiDBはトランザクションを中断し、ロールバックします。
3) フェーズ2 — コミット (プライマリ優先):すべてのプリライトが成功した場合、TiDBはPDにcommit_ts (コミットタイムスタンプ) を要求し、その後にプライマリキーをコミットします。プライマリが「コミット済み」として承認されると、そのトランザクションはクライアントの視点からコミットされたと見なされます。セカンダリはその後コミットされます。
4) セカンダリコミットとロッククリーンアップ:TiDB (またはバックグラウンドワーカー) はセカンダリキーをコミットし、プリライトロックをクリアします。TiKVはコミット中にロックを検証および削除し、リーダー/ライターがそれ以上ロックを見ないように保証します。
トランザクション安全のためのスナップショット分離
Percolatorの詳細な仕組みに入る前に、スナップショット分離、その保証内容、そしてアノマリーを理解しておくと有益です。包括的な説明については、このドキュメント (およびその参考文献) [1] を参照してください。データベースのトランザクションとその分離レベルに関心がある方にとって、これは価値ある読み物となるでしょう。
3つのノードA、B、Cを持つ連結リストを使って、スナップショット分離を説明することができます。

ここにT1とT2という2つのトランザクションがあるとしましょう。
- T1はノードCを更新したいと考え、T2はノードAを更新したいと考えます。
- T1は上記のリストを辿り、ノードA=1とノードB=2を読み取ります。その後、ノードCの値を100に設定します。
- T2はノードAの内容を100に変更します。
T1とT2による変更は、T1とT2の間で読み書きの競合を引き起こします。通常、トランザクションのどちらか一方がアボートされます。スナップショット分離のケースでは、T1はノードAの値自体には関心がなく、Cに到達するために辿る際に読み取っただけです。T2をT1の前に、またはT1をT2の前に並べ替えても、最終的な結果は同じになります。この状況を理解する一つの方法は、T1が開始する前に連結リストのスナップショットを取得していると考えることです。
Serializable分離レベルとMVCC
対照的に、Serializable分離レベルでは、2PLプロトコルに従い、T1は自身が辿るすべてのノード (AとB) に対して少なくとも共有ロックを取得します。T1のこれらの読み取りロックは、T2によるノードAの更新をブロックしたはずです。PostgreSQLは、Serialized Snapshot Isolation (SSI) [2] と呼ばれるバリエーションを使用しています。SSIは共有ロックを取得しますが、これらの共有ロックは他のトランザクションをブロックしません。その代わりに、トランザクションのロックは、直列化可能性の違反がないかコミット時にチェックされます。違反がある場合、コミット段階でロールバックが発生します。その結果、SSIはロック競合が発生すると深刻なパフォーマンス問題に悩まされやすい傾向があります。
Serializableはスナップショット分離よりも強力であり、スナップショット分離では防げない書き込みスキューを防ぎます。書き込みスキューの例外は、2つの同時実行トランザクションが関連する異なるレコードを読み取る場合に発生します。そこから、各トランザクションが読み取ったデータを更新し、最終的にトランザクションをコミットします。これらの関連レコード間に、複数のトランザクションによって同時に変更されてはならない制約がある場合、最終結果はその制約に違反することになります。
スナップショット分離は、より多くの並列性を許容するため、パフォーマンスに優れています。MySQL/InnoDBのリピータブルリードと同様に、SELECT FOR UPDATE構文を使用することで、書き込みスキューを防ぐことができます。
並列トランザクションが同じデータを変更しない限り、トランザクション間に競合は発生しません。これらのルールを次のように要約できます。
- トランザクションが開始されるとき、それぞれがデータベースのスナップショットを取得します。
- 分離された更新は並行して継続できます。
- 並行して実行されている別のトランザクション (T2) が、あるトランザクション (T1) がスナップショットとして取得した値を変更しコミットした場合、影響を受けるトランザクション (T1) は自身の変更をコミットできません。
最後に、TiDBはMVCC (Multi-Version Concurrency Control) を使用して、すべてのトランザクションにデータベースの安定したタイムスタンプ付きスナップショットを提供します。実際には、これはロックなしで一貫した読み取りが可能であることを意味します。読み取り側が書き込み側をブロックすることはなく、書き込み側も読み取り側をブロックしません。スナップショットはPDからのグローバルに単調増加するstart_tsによって定義されるため、他のトランザクションがクラスター内の別の場所でデータを更新している場合でも、クエリは一貫したビューを参照します。
分散トランザクションにおける競合処理
競合はLock列をチェックすることで識別されます。ある行はデータの複数のバージョンを持ち得ますが、任意の時点では最大で一つのロックしか持つことができません。書き込み操作中、プリライト・フェーズにおいて、影響を受けるすべての行に対してロックの獲得が試みられます。もしロックの獲得に一つでも失敗した場合、トランザクションはロールバックされます。楽観的ロックアルゴリズムを使用している時、競合が頻繁に発生するシナリオでは、Percolatorのトランザクション書き込みがパフォーマンスの低下に遭遇することが時々あります。
TiDBは、楽観的コミットモデルと悲観的コミットモデルの両方をサポートしています。悲観的コミットモデルは、MySQLのバックグラウンドを持つ方々にとってはお馴染みのものです。楽観的コミットは、単一ステートメントのオートコミットに使用されます。
自動再試行とロック解決
競合やリージョンエラーが発生した場合、TiDBは可能な限り手動介入なしにトランザクションを完了させるために、指数バックオフと自動リトライを使用します。典型的な一時的な問題には以下が含まれます。
- 他のトランザクションのロックに遭遇した場合。
- リージョンリーダーの転送。
- 一時的なネットワーク障害。
TiDBのロックリゾルバーは、以下の動作を行います。
- ロックのTTLを確認します。
- 期限切れのロックをプッシュ/解決しようと試みます。
- プリライトまたはコミットを再試行します。競合しているトランザクションがまだ進行中の場合、待機側は一時的にブロックされる可能性があります。そうでない場合、TiDBは古いロックをクリーンアップして処理を進めます。これにより、読み取り処理はロックフリーに保たれ (MVCC スナップショット経由)、書き込み競合は連鎖的な障害なしに回復可能になります。
フォールトトレランスとパーティション
内部では、TiKVリージョンはクォーラムプロトコルを用いて複製されています。これにより、ノード障害やネットワーク分断に対する耐性が提供されます。
- ノードに障害が発生した場合、クォーラムが利用可能になり次第、別のレプリカがリーダーシップを引き継ぎ、リクエストの処理を続行できます。
- ネットワーク分断が発生した場合、クォーラムを持つ多数派側のみが書き込みを受け付けられます。少数派側は書き込みを拒否するか停滞させ、これはクライアントに対して再試行可能なエラーとして現れます。TiDBは、健全なリーダーに到達可能になり次第、バックオフし、自動的に再試行します。
- コミットにはクォーラムが必要なため、クラスターの一部が到達不能な場合でも、TiDBは原子性と一貫性を維持します。
最終的な結果として、競合はMVCCロックと構造化された再試行によって処理されます。障害や分断は、クォーラム複製とリーダーフェイルオーバーによって吸収されます。そして、システムは健全な多数派での進行を優先しつつ、正しさを保証します。
設計による高可用性と耐障害性
TiDBは、レジリエンスを念頭に構築されたクラウドネイティブ・データベースです。このシステムは、コンピュートとストレージを分離し、データを複数の障害ドメインをまたいで複製し、ノードやゾーンの停止から手動介入なしに自動的に復旧します。
自動フェイルオーバー
- リーダー選出:TiKVはクォーラムコンセンサスを使用しているため、現在のリーダーに障害が発生した場合、リージョンのリーダーは自動的に再選出されます。トラフィックは最小限の中断で新しいリーダーに切り替わります。
- ステートレスなSQLレイヤー:TiDBサーバーはステートレスです。TiDBインスタンスに障害が発生した場合、クライアント接続はロードバランサーの背後にある健全なサーバーにリバランスされます。
- 配置を考慮したスケジューリング:PDは健全性を監視し、障害のあるノードやゾーンからリーダーシップを移動させることで、書き込みの可用性を維持します。
アベイラビリティゾーン間でのレプリケーション
- クォーラム複製:各TiKVリージョンは、異なるアベイラビリティゾーンに配置された複数のレプリカに格納されます。書き込みは過半数の実施で成功するため、一部のレプリカが到達不能になった場合でもクラスターの可用性が維持されます。
- 障害ドメインの分離:レプリカの配置ポリシーにより、同じゾーンで過半数が決まらないようにしています。これにより、局所的なインシデント発生時の影響範囲が限定されます。
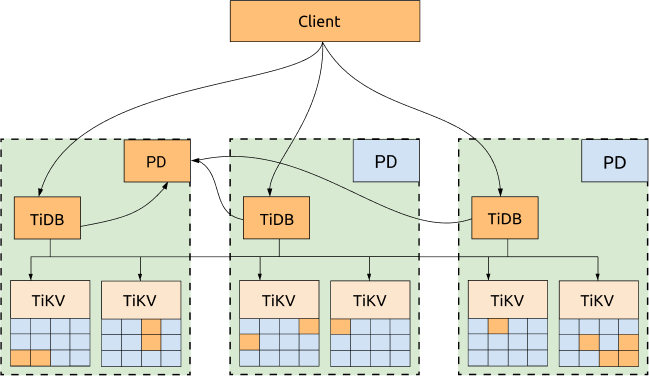
上記の図では、すべてのレプリカが3つのアベイラビリティゾーン (AZ) 間に分散配置されており、高可用性とディザスタリカバリの機能を提供します。
迅速な回復
- 自己修復型ストレージ:ノードが復帰した際や、代替ノードが追加された際に、複製が自動的にリバランスされ、不足しているレプリカが再構築されることで、設定されたレプリカ数が復元されます。
- オンライン運用:ダウンタイムなしでTiDBノードまたはTiKVノードを追加することでスケールアウトが可能です。システムはトラフィックを処理しながら、リージョンとリーダーシップを移行します。
- ノンブロッキング読み取り:MVCCが一貫したスナップショットを提供するため、クラスターが再構成を行っている間、多くの障害が読み取り側からは隠蔽されます。
TiDBのアーキテクチャは、最新のクラウドの基本要素に適合しています。信頼性の低いネットワークや一時的なノードを想定し、クォーラム複製、リーダー選出、および配置を考慮したスケジューリングを利用することで、障害が発生してもデータベースの可用性と正確性を維持します。
TiDB vs. その他の分散データベース
TiDBの設計は、実用的なバランスを目指しています。つまり、必要な箇所での強い一貫性、弾力的な拡張性、そして高可用性を、シャーディングを超えたACID保証を犠牲にすることなく実現します。ここでは、いくつかのよく知られたシステムとの比較を示します。
| システム | アーキテクチャ | 一貫性モデル | シャードをまたいだトランザクション | 強み | 典型的なトレードオフ |
|---|---|---|---|---|---|
| TiDB | シャード間でリソースを共有しないSQLレイヤーをTiDBサーバー上に持ち、ストレージはRaft上のTiKVで、PDが配置とタイムスタンプを担当する。 | 書き込みには強い一貫性を持ち、MVCCスナップショットによりロックフリーな読み取りを実現する。 | 可能。2相コミットによりリージョンをまたいでACIDを維持する。 | MySQL互換性、SQLとストレージの両方をスケールアウト可能、自動フェイルオーバー。 | リージョン間レイテンシが書き込みパスに影響を与える、慎重な配置設計が推奨される。 |
| Vitess | MySQLインスタンス群の上にシャーディングミドルウェアを構築している。 | シャード内ではInnoDBの一貫性を持つ。クロスシャードのフローはアプリケーションとオーケストレーションに依存する。 | 限定的。クロスシャードトランザクションは可能だが、複雑性が増し、一般的な経路ではない。 | MySQLでの実績ある水平スケーリング、より多くのルーティングロジック、クロスシャードACIDのための運用上の複雑さ。 | アプリケーションがシャードを認識する必要がある、クロスシャードACIDのためのより多くのルーティングロジックと運用上の複雑さ。 |
| Google Spanner | TrueTimeと同期レプリケーションによるグローバル分散ストレージ。 | 厳密な順序付けを伴う外部一貫性。 | 可能。強い保証を持つグローバルトランザクション。 | グローバルな一貫性、成熟したマネージドサービス。 | グローバルな書き込みにおいて、クラウドロックイン、より高いレイテンシとコストプロファイル。 |
| CockroachDB | 分散型KV上のモノリシックなSQLレイヤーを持ち、レンジごとのRaftを使用する。 | デフォルトでSerializable Isolationを提供する。 | 可能。2相コミットによりオーバーレンジでコミットする。 | PostgreSQL互換性、シンプルなスケールアウト、強い一貫性。 | リージョン間レイテンシがトポロジーやゾーン構成に影響を与える可能性があるため、慎重な設定が必要。 |
もし、シャーディングをまたいだACIDを備えたMySQL互換性、強力でありながら実用的な一貫性、そしてアプリケーションを再設計することなくノードを追加できる能力が必要であれば、TiDBはシャーディングミドルウェアのアプローチと、厳密に管理されたグローバル一貫性サービスとの間に位置する、バランスの取れた道筋を提供します。
TiDBにおけるACIDトランザクションの実用事例
TiDBのACIDトランザクション、MVCCスナップショット、そしてRaftに裏打ちされた複製の組み合わせは、正確性や稼働時間を妥協できないシステムに強力に適合します。
金融サービス:フォールトトレランスとの整合性
- 決済と台帳。2相コミットが複数行、複数シャードにわたる書き込みを調整することで、残高や振替の原子性を維持します。書き込みが進行している間も、MVCCは監査証跡やリスクチェックのための一貫した読み取りを提供します。
- 規制上の耐久性。アベイラビリティゾーンをまたいだRaft複製は、ノード障害やネットワーク分断が発生しても、コミットされたデータを保持します。自動的なリーダー選出とロック解決により、システムは健全な多数派で処理を継続します。
- 運用継続性。悲観的トランザクションは、べき等な借方・貸方ワークフローのようなホットパスを直列化できますが、ほとんどのクエリはロックフリーのまま維持されます。
ゲームプラットフォーム:高可用性と水平スケーラビリティ
- マッチメイキングとインベントリ。ACIDトランザクションは、トラフィックが急増した際でも、アイテムの付与、ゲーム内通貨の更新、セッション状態を保護します。
- シームレスなスケールアウト。TiDBはコンピュートとストレージを独立してスケールします。プレイヤー人口が変動するにつれてリージョンが分割・リバランスされるため、ダウンタイムなしにホットスポットが解消されます。
- 常時稼働のプレイ。クォーラム複製と自動フェイルオーバーにより、ノードやゾーンがダウンした際でも書き込みが維持され、その間も読み取り側は一貫したスナップショットを利用します。
SaaSプラットフォーム:クラウドネイティブ・トランザクション管理
- マルチテナントの正確性。シャーディングをまたいだACIDが、請求、プロビジョニング、エンタイトルメントなどのサービスを横断するテナントスコープの更新が原子性を維持することを保証します。
- オンラインスキーマと成長。ステートレスなSQLレイヤーとオンラインDDLにより、メンテナンスウィンドウなしに機能のロールアウトが可能になります。ストレージはTiKVノードを追加することで成長します。
- プラットフォームの回復力。配置を考慮したスケジューリングとリージョンごとの複製により、障害を局所化します。TiCDCは、コミットされた変更をOLTPに影響を与えることなく、分析や検索システムにデータをストリームします。
まとめ:TiDBによるクラウドネイティブACIDトランザクション
このブログでは、TiDBを通して分散トランザクションの効率性と信頼性を探ります。TiDBはPercolatorプロトコルを活用することで、分散環境でACID保証を実現しています。
Percolatorはスナップショット分離モデルを使用しています。これにより、トランザクションは開始時にデータベースのスナップショットを取得し、並列更新を促進し、分散ノード間での一貫性を確保できます。
Serializabilityのような従来の分離レベルとの比較は、パフォーマンスと制約の強制における微妙なトレードオフを明らかにします。スナップショット分離プロトコルとMySQL/InnoDBのリピータブルリードとの互換性が強調されています。
分散システムにおいて堅牢なACID保証を提供するPercolatorの役割は、パフォーマンスとトランザクションの整合性のバランスをとるための説得力のあるソリューションを提供します。
TiDBは、コンピュートとストレージの両方を独立してスケーリングすること、グローバルな分散をサポートすること、および多様なデータ環境向けに操作を最適化することに優れています。トランザクションのACID保証を堅牢にサポートするそのモダンな分散データベース設計は、進化するワークロードとスケーリング要件のシームレスな処理を可能にします。これにより、要求の厳しいシナリオにおいても一貫した安定したパフォーマンスが保証されます。
関連リソース
詳細については、以下の資料をご確認ください。
- ホワイトペーパー:SaaSの成長を加速する
- オンデマンド:TiDB入門
- ブログ:スケールするACID:MySQLが分散SQLの代替を必要とする理由
- ドキュメント:単一リージョン内でのマルチアベイラビリティゾーン展開
- ドキュメント:TiKVのMVCCインメモリエンジン
参考文献



TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。