

※このブログは2025年10月16日に公開された英語ブログ「Database Sharding Explained: Strategies for Scalable SQL Performance」の拙訳です。
データベースシャーディングとは、データをチャンクに分割し、そのチャンクを複数のデータベースサーバー (またはデータベースインスタンス) に「インテリジェントに」分散させることで、データベースのパフォーマンスを向上させるデータアーキテクチャ戦略です。これらのデータのチャンクは「シャード」と呼ばれ、各シャードはデータ全体の一部を含んでいます。すべてのシャードを合わせるとデータ全体を表し、個々のデータ行は一つのシャードにのみ存在します。
シャーディングは、作業がより多くのマシンによって処理されるため、データベースがより多くのトランザクションを処理し、より多くのデータを保存することを可能にします。データベースシャーディングは、スケーラビリティが求められる大規模な分散環境において非常に効果的です。
データベースシャードは、シェアード・ナッシングアーキテクチャの一例です。シャードは独立したデータベースサーバーであり、他のシャードとコンピューティングリソースを共有することはありません。改めて確認すると、シャードはデータベースデータの一部を表し、すべてのシャードがデータ全体を表します。
以下の図は、単一のコンピューター上にあるテーブル (「Origin Table (元のテーブル)」とラベル付けされています) を示しています。

元のテーブルが非常に巨大で、クエリに時間がかかると想像してみてください。シャーディングされたアーキテクチャに変更すれば、クエリパフォーマンスを向上させることができます。図の右側がこれを示しています。テーブルは現在シャード化されています。データの一部はデータベースサーバーDB1に存在し、残りのデータはデータベースサーバーDB2に存在します。これがシャーディング、つまりデータを分割し、複数のサーバーに分散させることです。
データベースシャーディングを設定する際、データをどのように分割するかという選択が、高速なデータベースになるか、非常に遅いデータベースになるかを決定づけることになります。このトピックについては、後のセクションで改めて取り上げます。
このブログでは、この一般的なアーキテクチャパターンを定義するデータベースシャーディングの背後にある概念を深く掘り下げ、そのあらゆる詳細を探求します。
データベースシャーディングとは何ですか?
データベースシャーディングとは、一つの大きな論理データセットを、より小さく独立した断片 (シャードと呼ばれる) に分割し、複数のサーバーに分散させる手法です。この最大の利点は、データベースの水平スケーリングが可能になることです。負荷やデータが増加しても、これまでのように巨大なマシンを購入し続けるのではなく、シャードノードを追加することで対応できます。ほとんどのシャーディングシステムはシェアード・ナッシングアーキテクチャを採用しており、各シャードが自身のデータとリソースを所有するため、競合が最小限に抑えられ、シャードが独立してスケールしたり、障害が発生したりしても影響が及びにくくなります。
なぜ従来のデータベースはSQLのスケーラビリティに苦戦するのか
従来のデータベースは、通常、単一のマシン上で動作します。こうしたマシンは、サーバー、仮想マシン (VM)、あるいはノードなどと呼ばれるのを聞いたことがあるかもしれません。呼び方がどうであれ、それらには性能の上限があります。
この性能の限界は、いずれデータベースをより高性能なマシンに移行する必要があることを意味します。コンピューターが「より高性能」だと聞いたら、すぐに「はるかに高価」だと考えるべきです。急成長しているデータベースでは、通常、データベースが成長する余地を持てるように、必要以上の計算能力に対価を支払うことになります。データベースが現在のマシンの容量を超えると、さらに大きく、さらに高価なマシンに移行するというプロセスを繰り返すことになります。
この状況に対処する別の方法があります。ただし、それは費用がかかり、複雑です。環境に新しいデータベースマシンを追加するのです。しかし、これにはデータを複数のマシンに効率的に分散させる何らかの方法が必要です。これは、複数のデータベースサーバーの上にソフトウェア層を追加するか、この機能をアプリケーションに追加することで実現できます。この手法は非常に一般的であるため、データベースシャーディングという名前がついています。
データパーティショニングとシャーディング:主な違いを解説
これまでデータベースシャーディングを、一つの大きなデータセットを複数のマシンに分割し、それぞれの断片 (シャード) が独立したサーバー上に存在して、トラフィックの一部を処理するものと定義してきました。次に、これをパーティショニングと比較してみましょう。パーティショニングは、一つの大きなテーブルを同じマシン上でチャンクに分割し、それぞれの断片 (パーティション) を単一のデータベースサーバーが管理します。
パーティショニングでは、分割は単一のデータベースサーバー内で行われます。データはパーティションと呼ばれるセグメントに分割されますが、一つのデータベースシステムの下に留まります。これは、商品を複数の倉庫 (シャード) に分散させるシャーディングとは異なり、一つの倉庫内に異なるセクションを整理するようなものです。各パーティションは、シャードと同様にデータセット全体の一部を保持しますが、シャーディングとは異なり、すべてが同じデータベースサーバー内に存在します。このアプローチは、大規模なテーブルを管理するのに特に有益であり、負荷を複数のサーバーに分散させることなくクエリのパフォーマンスを向上させることができます。
以下の図は、前の図と似ています。主な違いは、元のテーブルがチャンクに分割され、それが単一のデータベースサーバー上に存在するのに対し、シャード化されたデータは複数のデータベースサーバー上に存在することです。

データベースシャーディングが、スケーラビリティのためにデータを分割し、異なるデータベースに分散させるのに対し、パーティショニングは、効率的な管理とアクセスのために単一のデータベース内でデータを整理します。どちらもパフォーマンスの向上を目的としていますが、その方法は異なります。
ここでは深く掘り下げませんが、単一のデータベースアーキテクチャ内でパーティショニングとシャーディングを組み合わせることは非常に一般的です。したがって、パーティショニングとシャーディングは二者択一の取引ではないことを覚えておいてください。これらの手法は組み合わせて利用することができます。
データベースのシャーディングを使用すべき時 (および使用すべきでない時)
データベースをシャーディングするかどうか、そしていつシャーディングするかを決めるのは、事業を拡大する適切なタイミングを選ぶのに似ています。それはすべて、タイミングと必要性にかかっています。データベースシャーディングは、万能な解決策ではありません。それ自体に複雑さが伴います。
シャーディングがSQLパフォーマンスを向上させる場合
- 高トラフィックと大容量データ:データベースが数百万のユーザーからの負荷やテラバイト級のデータ処理に苦慮している場合、データベースのシャーディングを検討する時期。
- スケーラビリティの必要性:ビジネスが急成長しており、データとユーザーベースの継続的な増加が見込まれる場合。
- パフォーマンスの低下:クエリのレスポンスが遅くなっていることに気づき、分析結果がデータベースレベルでボトルネックを示している場合。
シャーディングが不要な複雑さを加えるとき
- 小規模から中規模のデータベースサイズ:ストレージまたは処理能力の上限に達していないデータベースの場合。
- シンプルなワークロード:データベースが複雑なクエリや高いトランザクションレートを経験していない場合。
- 限られた技術リソース:シャーディングの実装と管理には、かなりの専門知識が必要です。もしチームがその複雑さに対処する準備ができていない場合は、見送りを推奨 (または、よりシンプルな解決策を探すべきです)。
重要な点として、データベースシャーディングは強力なツールですが、常に最初に使用すべき手段ではありません。慎重に検討し、それがあなたのデータベースのニーズと課題に適合していることを確認してください。
シャーディング戦略:適切なアプローチの選択
データベースシャーディングについて理解できたところで、次にその実装方法を理解する必要があります。これには多くの方法がありますが、幸いにも、すべての方法は同じ概念に基づいています。それは、シャーディングキーを使ってデータを複数のシャード全体に分散させることです。
これらのアーキテクチャはそれぞれに長所と短所を持っており、どの方法を選択するかは、対象となるデータベースの特定の要件や特性に大きく依存します。重要なのは、あなたの特定の状況に最適なシャーディング戦略を選ぶことです。
キーベース (ハッシュ) シャーディング
キーベースシャーディングでは、ユーザーIDやタイムスタンプなどの特定の値をシャーディングキーとして利用します。
これは以下の図で確認できます。このアプローチでは、データ行がどのシャードに格納されるかを決定するために、キーを選択する必要があります。この図では、シャーディングキーとして「Column 1 (列1)」を選択しています。次に、データ項目にハッシュ関数を適用します。このハッシュキーによって、データがどのシャードに送られるかが決まります。
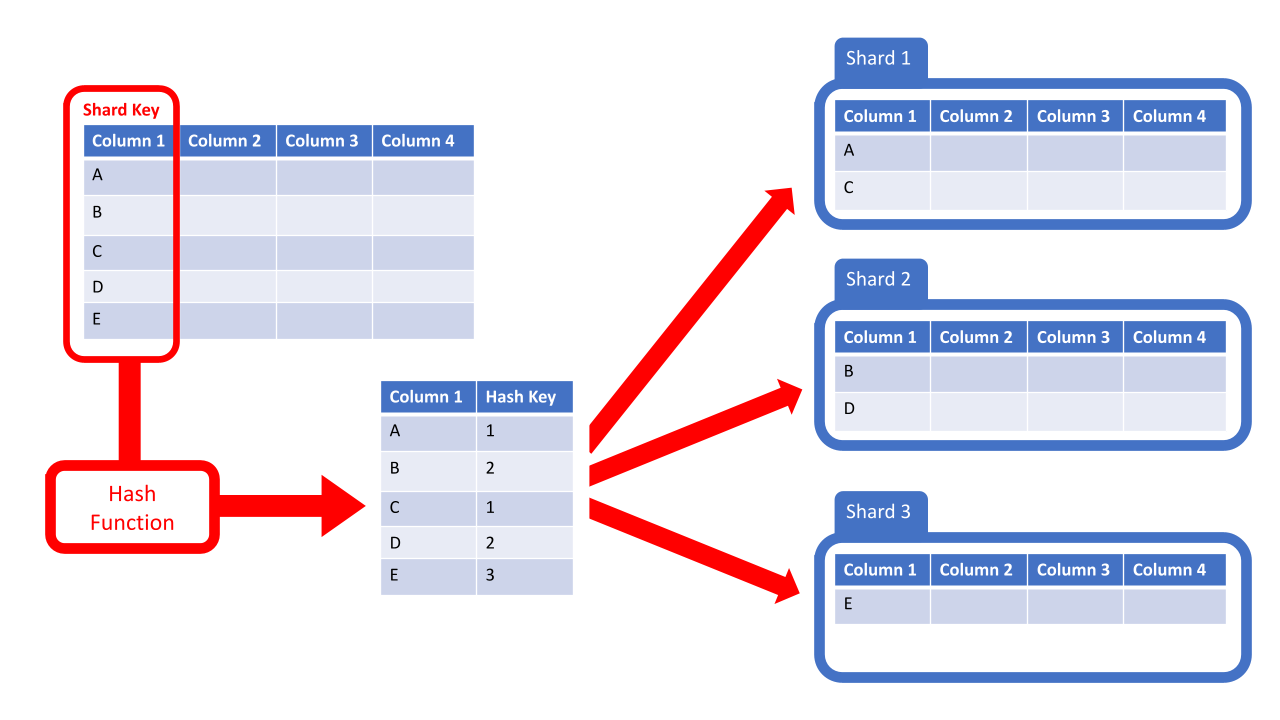
キーベースシャーディングは、データが均等に分散している場合に理想的ですが、データが増加するにつれて調整が複雑になることがあります。
このシャーディング手法は、特定のキー (ユーザーIDなど) にハッシュ関数を使用してデータをシャードに割り当てます。これは、データの均一な分散を保証するのに優れています。しかし、既存のデータの再配置が必要となるため、シャードを追加または削除する際に複雑になる可能性があります。
レンジベース (水平) シャーディング
レンジベースシャーディングでは、日付の範囲や地理的な場所など、値の範囲に基づいてデータが分割されます。
以下の図では、「Paint Color (ペイントの色)」の列に基づいてシャーディングすることを選択しています。ペイントの色は数値コードです。データベースはこのコードを受け取り、シャードに設定された範囲を使って、データがどこに配置されるべきかを決定します。

レンジベースシャーディングは、明確で連続的な区分を持つデータに有効ですが、不均一なデータ分散を引き起こす可能性があります。
このアプローチは、アルファベット順や日付の範囲など、レンジに基づいてデータを分割します。これは分かりやすく、時系列データには理想的ですが、特定のレンジに他のレンジよりも多くのデータが含まれる場合、不均一なデータ分散 (すなわちホットスポット) につながる可能性があります。
バーティカルシャーディング
バーティカルシャーディング (垂直シャーディング) は、テーブルの列に基づいてデータを分割し、異なる列をさまざまなシャードに分散します。このパターンは、幅の広いテーブル (ワイドテーブル) を複数のテーブルに分割するために使用されます。その結果、一方のテーブルは他方よりも列数が少なくなります (ナローテーブル)。このナローテーブルには、最も頻繁にクエリされるデータが格納されます。まれに分割された二番目のテーブルからデータが必要になった場合は、二番目のテーブルを最初のテーブルと結合することができます。

バーティカルシャーディング (垂直シャーディング) は、利用されていない大きな列を持つテーブルに適しており、頻繁にアクセスされるデータを分離することでパフォーマンスを向上させます。
この戦略は、アナリティクスが導入されている環境で有用です。アナリティクスワークロードでは、非常に列の多いテーブルにアクセスすることが一般的に必要とされます。ただし、複数のシャードに同時にアクセスする必要があるクエリを複雑にしてしまう可能性があります。
ディレクトリベースシャーディング
ディレクトリーベースシャーディングは、テーブルの列に基づいてデータを分割し、異なる列をさまざまなシャードに分散させます。
以下の図では、以前に使用した「Paint Color (ペイントの色)」の列を再び取り上げます。この例では、データを特定のシャードに配置するために、ディクショナリ (ルックアップテーブルとも呼ばれます) を使用しています。

ディレクトリーベースシャーディングは、利用されていない大きな列を持つテーブルに適しており、頻繁にアクセスされるデータを分離することでパフォーマンスを向上させます。
このシャーディング手法では、どのデータがどのシャードにあるかを追跡するためにルックアップディレクトリを介します。これは非常に大きな柔軟性を提供し、不均一な分散にも適切に対処できる一方で、そのルックアップディレクトリが単一障害点になるというリスクをもたらします。また、ディレクトリの維持管理と一貫性の確保も重要な考慮事項となります。
手動シャーディングと自動シャーディング:どちらの道を選ぶべきか?
ここまで、シャーディング戦略について議論しましたが、最も重要な詳細、つまり「誰がシャーディングを担うのか?」についてはまだ議論していません。別の言い方をすれば、データベースを手動でシャーディングすることも、あるいは、データを効果的に自動でシャーディングするために設計されたミドルウェア層やデータベースを使用することもできます。
手動シャーディングされたデータベース、または自動シャーディングされたデータベースを実装するために使用できる具体的な方法を見ていきましょう。
分散型SQLデータベースによる自動シャーディング
分散型SQLデータベースは、ネイティブで自動シャーディングをサポートしており、スケーラビリティとメンテナンスを簡素化します。
- 長所:シャーディング機能が組み込まれていること、スケーラビリティ、メンテナンスの軽減により、真の高可用性データベースを提供します。データを自動的にシャーディングするためにゼロから設計されています。
- 短所:既存のシステムからの移行や、新しい運用ノウハウが必要になる場合があります。公平に見て、すべてのシャーディングソリューションには環境変更と新しいスキルの習得が求められます。自動シャーディングのために設計されたデータベースを利用することが、最善の長期的な解決策となります。
ミドルウェアソリューションによる自動シャーディング
MySQLデータベースには、ProxySQLやVitessのようなミドルウェアを使用します。これらのツールは、アプリケーションとデータベースの間に位置し、シャーディングロジックを透過的に処理します。
- 長所:シャーディングプロセスを簡素化し、アプリケーションに対して透過的です。
- 短所:管理すべき層が一つ増え、習得に時間がかかる可能性があります。これにより、ソフトウェア、ハードウェア、および管理コストが増加する可能性があります。
組み込みシャーディング機能
MySQL ClusterやMariaDBのようなデータベースには、よりMySQLネイティブなシャーディングソリューションとして、組み込みのシャーディング機能が含まれています。
- 長所:MySQLエコシステムとのネイティブな統合。
- 短所:シャーディング機能が後付けで追加されたため、他の分散型SQLデータベースと比較して柔軟性に欠ける可能性があります。これに対し、分散型SQLデータベースは当初から自動シャーディングをサポートするように設計されています。
アプリケーション層シャーディング
アプリケーションのロジックを変更し、データを複数のデータベースインスタンスに分散させます。このアプローチは制御性が高い反面、かなりの開発作業を必要とします。
- 長所:シャーディングロジックに対して高い制御性を持ちます。
- 短所:大幅な開発とメンテナンスの労力が必要です。スケールアウトには綿密な計画が必要であり、実行時には通常ダウンタイムが発生します。このアプローチを実装すると、アプリケーションが続く限り繰り返されるコンサルティングプロジェクトになってしまいます。痛手です!
要約すると、データベースシャーディングは多大な作業となる可能性があります。以下に、この種のプロジェクトが実際にはどのようなものになるか、非常に大まかな概要を示します。
シャーディング実装のための主要プロジェクト手順
- シャーディングの必要性を特定する:シャーディングの必要性を理解するために、データベースを評価します。データ量、トランザクションレート、パフォーマンスの問題といった要因を考慮します。
- コンピューティングリソースとストレージの必要量を決定する:これはプロセスの中でも最も重要なステップの一つです。オンプレミスのデータベースをシャーディングする場合、ハードウェアを購入する必要があるかもしれません。このステップでハードウェアを選定します。クラウド環境で実行している場合は、必要な仮想マシンとストレージのコストを見積もるようにします。また、ソフトウェアを忘れないでください。追加のライセンスや製品が必要になる場合があります。オープンソースソフトウェアを使用している場合 (賢明な選択です)、サポート契約を増強する必要があるかもしれません。
- テスト環境を作成する:テスト環境は、多くの状況でプロセスを簡素化します。手間はかかりますが、テスト環境での失敗は、本番システムを破壊するほど悪くはありません。サイジング文書に戻り、テスト環境の分を追加することを忘れないでください。
- コンピューティングリソースとストレージリソースを調達する:ハードウェアの発注と、必要なソフトウェアのライセンス取得を忘れないでください。
- シャーディング戦略を選択する:キーベース、レンジベース、バーティカル、またはディレクトリーベースのシャーディングから選択します。選択は、データ構造と利用パターンに合致している必要があります。
- シャーディングキーを選択する:このキーが、データをシャード間でどのように分散するかを決定します。データの分散が均等になり、複雑なシャードをまたがったクエリが最小限に抑えられるキーを選択します。
- シャーディングロジックを実装する:これは、アプリケーションレベルでも実行できます。データベースサーバーの上にシャーディング層を追加するか、自動シャーディングをサポートするデータベース管理システムを使用します。
- 徹底的にテストする:稼働を開始する前に、シャード化されたデータベースを厳密にテストし、データの整合性とパフォーマンスを確保します。
- 監視と調整を行う:実装後も、シャード化されたデータベースのパフォーマンスを継続的に監視し、必要に応じてシャードの再バランスを行います。
分散SQLデータベースがシャーディングを簡素化する理由
これまで実証してきたように、適切なデータベースシャーディング戦略を選択することは困難を伴う場合があります。しかし、お客様の組織と共に進化できる、より優れた選択肢があります。
PingCAPが提供するTiDBは、自動シャーディング機能を内蔵した、先進的なオープンソースの分散型SQLデータベースです。伸縮自在なスケーリング、リアルタイム分析、およびデータへの継続的なアクセスにより、データ集約型アプリケーションを支えることができます。スケールアウトするRDBMSやインターネットスケールのOLTPワークロードにTiDBを利用する企業は、以下の特徴を持つ分散型データベースの恩恵を受けることができます。
- MySQL互換:MySQL 8.0とワイヤープロトコル互換性があります。これにより、開発者はデータベースの豊富なツールとフレームワークのエコシステムを引き続き活用できます。
- 水平スケーラブル:手動によるシャーディングなしに、データワークロードに対する完全な透過性を提供します。データベースのアーキテクチャはコンピューティングとストレージを分離しており、必要に応じてデータワークロードを即座にスケールアウトまたはスケールインできます。
- 高可用性:システム障害やネットワーク障害発生時でもデータへの継続的なアクセスを保証するために、自動フェイルオーバーと自己修復を実現します。
- 強力な一貫性:データをグローバルに分散する際にもACIDトランザクションを維持します。
- 複合ワークロード対応 (Mixed workload capable):合理化された技術スタックにより、リアルタイム分析の生成が容易になります。TiDBのインテリジェントなクエリーオプティマイザーは、一連のオペレーターから構成される最も効率的なクエリ実行計画を選択します。
- ハイブリッドおよびマルチクラウド対応:ITチームはパブリック、プライベート、ハイブリッドクラウド環境のVM、コンテナ、またはベアメタル上で、データベースクラスタを世界中のどこにでもデプロイできます。
- オープンソース:Apache 2.0ライセンスの下で100%オープンソースである分散型データベースにより、ビジネスのイノベーションを解き放ちます。
- セキュア:転送中および保存中のデータの両方で、エンタープライズグレードの暗号化によりデータを保護します。
TiDBの設計はGoogleのSpannerおよびF1データベースから着想を得ています。ただし、TiDB はグローバルに分散されたファイルシステムを必要とせずに、同様の機能を提供することを目指しています。
まとめと今後の取り組み
シャーディングは、データをノード間で分割することでリレーショナルデータベースのスケーリングを促進し、スループットを向上させ、成長に伴うパフォーマンスの安定を保ちます。しかし、従来の手動シャーディングには、アプリケーションの書き換え、複数のシャード結合、運用上の苦労、厄介なフェイルオーバーといったトレードオフが伴います。
分散型SQLデータベースは、シャーディングのような水平スケーラビリティを提供しつつも、単一の論理データベースとしてのシンプルさを維持します。これにより、自分でシャーディングフレームワークを構築することなく、SQL、トランザクション、および運用の平穏を保つことができます。
TiDBの分散型SQLアーキテクチャについてさらに学ぶか、無料のTiDB Cloudトライアルを開始して、あなたのワークロードでその違いを実感してください。



TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。