
※このブログは2022年06月29日に公開された英語ブログ「Analytics on TiDB Cloud with Databricks」の拙訳です。
著者 : Qiang Wu (PingCAP TiDB Cloudエンジニア)
編集者 : Calvin Weng, Tom Dewan
TiDB Cloud は、オープンソースの分散SQLデータベースであるTiDBのフルマネージドのDatabase-as-a-Service (DBaaS) です。
Databricks は、Sparkと连携するWebベースのデータ分析プラトムォォです。データウェahaウsuとデータreikをreikawasuuaーキテクチャに组み合わせるには最适です。
Databricksに組み込まれているJDBCドライバーを使用すると、TiDB CloudとDatabricksを数分で接続することができ、TiDBのデータをDatabricksで分析できるようになります。この記事では、TiDB CloudのDeveloper Tierのクラスタ (※Developer Tierは2022年11月1日よりServerless Tierに変わりました) を作成し、TiDBとDatabricksを接続し、Databricksを使用してTiDBのデータを処理する方法について説明します。
TiDB CloudでDeveloper Tierクラスタをセットアップする
TiDB Cloudを開始するには次の手順を実行します:
- TiDB Cloudアカウントにサインアップしてログインします。
- Create Cluster > Developer Tierで1 year Free Trialを選択します。
- クラスタ名を設定し、クラスタのリージョンを選択します。
- Createをクリックします。TiDB Cloudのクラスタは約1〜3分で作成されます。
- OverviewパネルでConnectをクリックし、トラフィックフィルターを作成します。ここでは、0.0.0.0/0のIPアドレスを追加して、他のIPからのアクセスを許可します。
- 後程Databricksの設定で使用するJDBC URLをメモします。
サンプルデータをTiDB Cloudにインポートする
クラスタを作成したら、 サンプルデータをTiDB Cloudに投入します 。デモンストレーションとして自転車シェアリングプラットフォームであるCapital Bikeshareのサンプルシステムデータセットを使用します。サンプルデータは、Capital Bikeshareデータライセンス契約に基づいてリリースされています。
- クラスタ情報ページでimportをクリックします。Data Import Taskページが表示されます。
- インポートタスクを次のように設定します:
- データソースの種類 :
Amazon S3 - バケットURL :
s3://tidbcloud-samples/data-ingestion/ - データ形式 :
TiDB Dumpling - ロール ARN :
arn:aws:iam::385595570414:role/import-sample-access
- データソースの種類 :
- Target DatabaseでTiDBクラスタのUsernameとPasswordを入力します。
- サンプルデータのインポートを開始するにはimportをクリックします。このプロセスには約3分かかります。
- 概要パネルに戻り、ConnectをクリックしてMyCLI URLを取得します。
- MyCLIクライアントを使用してサンプルデータのインポートを確認します。
$ mycli -u root -h tidb.xxxxxx.aws.tidbcloud.com -P 4000(none)> SELECT COUNT(*) FROM bikeshare.trips;+----------+| COUNT(*) |+----------+| 816090 |+----------+1 row in setTime: 0.786s
DatabricksからTiDB Cloudに接続する
続行する前にご自身のアカウントでDatabricksのワークスペースにログインしていることを確認してください。Databricksアカウントをお持ちでない場合は、こちらから無料のアカウントにサインアップしてください。もしDatabricksの経験が豊富でノートブックを直接インポートしたい場合は、(オプション) TiDB CloudのサンプルノートブックをDatabricksにインポートするに進むことができます。
このセクションではDatabricksに新しいノートブックを作成し、それをSparkクラスタにアタッチしてから、JDBC URLを使用してTiDB Cloudに接続します。
- Databricksワークスペースで、次に示すようにSparkクラスタを作成してアタッチします:

- DatabricksのノートブックでJDBCを設定します。TiDBはDatabricksのデフォルトのJDBCドライバーを使用できるため、ドライバーパラメーターを設定する必要はありません。
%scala val url = "jdbc:mysql://tidb.xxxx.prod.aws.tidbcloud.com:4000" val table = "bikeshare.trips" val user = "root" val password = "xxxxxxxxxx"ここでは
url: TiDB Cloudへの接続に使用されるJDBC URL
table: ${データベース}.${テーブル}のようにテーブルを指定
user: TiDB Cloudに接続するためのユーザー名
password: ユーザーのパスワードを設定します。 - TiDB Cloudへの接続を確認します:
%scala import java.sql.DriverManager val connection = DriverManager.getConnection(url, user, password) connection.isClosed() res2: Boolean = false
Databricksでデータを分析する
接続が確立されたらTiDBのデータをSparkデータフレームとしてロードし、Databricksでデータを分析できます。
- Sparkのデータフレームを作成してTiDBのデータをロードします。ここでは前の手順で定義した変数を参照します:
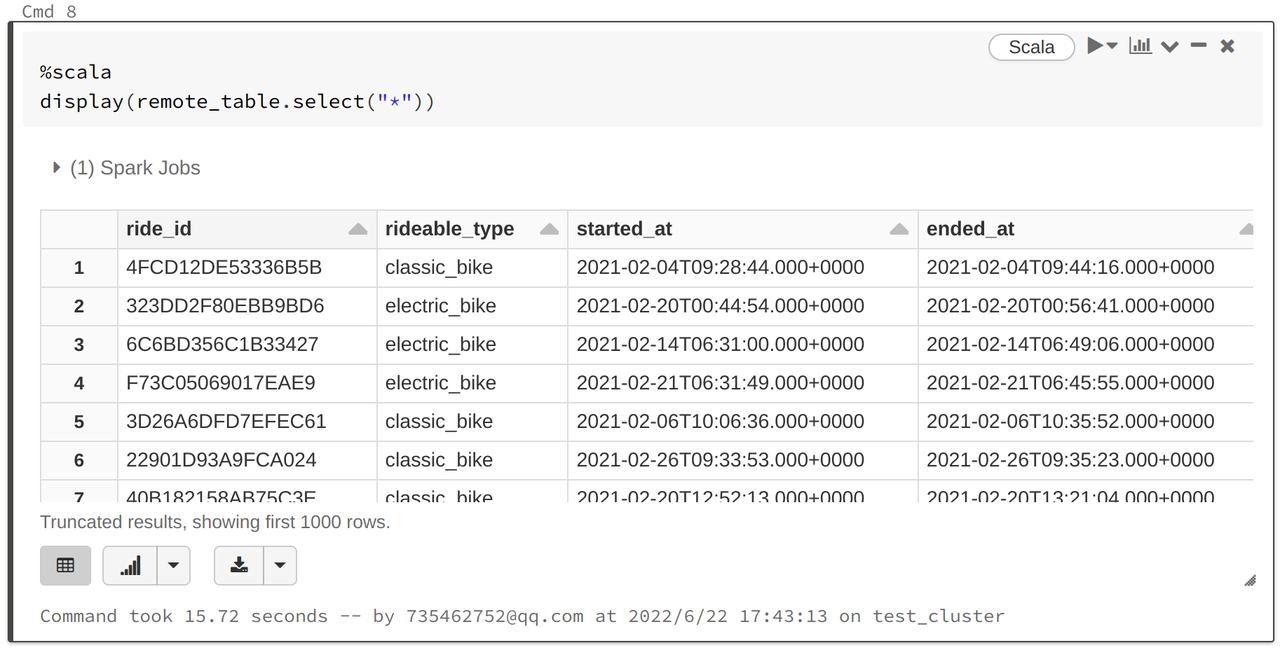
%scala val remote_table = spark.read.format("jdbc") .option("url", url) .option("dbtable", table) .option("user", user) .option("password", password) .load() - データに対してクエリします。Databricksには必要なグラフの種類をカスタマイズする強力なグラフ表示関数が用意されています:
%scala display(remote_table.select("*"))
- データフレームのビューまたはテーブルを作成します。この例では”trips”という名前の一時ビューを作成します:
%scala remote_table.createOrReplaceTempView("trips") - SQLステートメントを使用してクエリします。次のステートメントはタイプごとの自転車の数を照会します:
%sql SELECT rideable_type, COUNT(*) count FROM trips GROUP BY
rideable_type ORDER BY count DESC - 分析結果をTiDB Cloudに書き込みま:
%scala spark.table("type_count") .withColumnRenamed("type", "count") .write .format("jdbc") .option("url", url) .option("dbtable", "bikeshare.type_count") .option("user", user) .option("password", password) .option("isolationLevel", "NONE") .mode(SaveMode.Append) .save()
(オプション) TiDB CloudのサンプルノートブックをDatabricksにインポートする
ここでは DatabricksからTiDB Cloudに接続する 手順と DatabricksDatabricksでTiDBデータを分析する. 手順を含むTiDB Cloudサンプルノートブックを紹介します。こちらを直接インポートすることで分析作業に集中することができます。
- DatabricksワークステーションでCreate > Importをクリックして TiDB CloudのサンプルURLを貼り付け、ノートブックをDatabricksワークスペースにダウンロードします。
- このノートブックをSparkクラスタにアタッチします。
- この例のJDBC構成を独自のTiDB Cloudクラスタに置き換えます。
- ノートブックの手順に従いDatabricksを使用してTiDB Cloudを試してください。
おわりに
この記事ではDatabricksでTiDB Cloudを使用する方法を紹介しました。 こちらをクリックすることで、わずか数分で今すぐTiDB Cloudを試すことができます。私達は現在、TiDB / TiKV上でApache Sparkを実行するために構築された薄いクエリレイヤーであるTiSparkを介してDatabricksからTiDBに接続する方法に関する別のチュートリアル記事の作成に取り組んでいます。私たちのブログを是非購読して下さい。
Want to explore TiDB without installing any software? Go to TiDB Playground



TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。