
※このブログは2022年9月25日に公開された英語ブログ「Using Streaming, Pipelining,and Parallelization to Build High Throughput Apps (Part II)」の拙訳です。
著者 : Cong Liu (PingCAP TiDB Cloudエンジニア)、Phoebe He (デベロッパーリレーションズマネージャー)
編集者:Fendy Feng、Tom Dewan、Rick Golba
インターネットの利用は、パンデミックによって加速しています。インターネット上のこれらの活動はすべて、最終的にサーバー、アプリケーション、システムに対するリクエストやワークロードとなります。スケーラビリティが課題になっています。前回は、ストリーミング、パイプライン化、並列化によって、アプリケーションがリソースを最大限に活用する方法について紹介しました。今回は、高スループットのアプリケーションを実装するための戦略や考慮事項について説明します。
ストリーミングの実装
タスクを分解してデータの整合性を確保する
ストリーミングは、大きなタスクを小さなチャンクに分割し、順番に処理します。その際、データの一貫性を確保すること、つまりアトミック性を確保することは、いくつかの意味があります。
第一に、元のタスクのアトミック性を意味します。タスクを分解しても、小さなスライスを元に戻したときにタスクが変わることはありません。例えば、「1TBのファイルをコピー・ペーストする」タスクを3,300万の小さなタスクに分割すると、各タスクは32KBのファイルをコピー・ペーストし、別々に処理します。処理後、3,300万のタスクは1TBのファイルに統合されます。
第二に、それぞれの小さなタスクのアトミック性を意味します。完全に正常にコミットするか、完全に失敗するかのどちらかしかありません。それぞれの小さなタスクのアトミック性をどのように実現するかについては、後のセクションで説明します。現時点では、小さなタスクはすでにアトミックであると仮定します。
大きなタスクをいくつもの小さなタスクに分解することができれば、全ての小さなタスクが終われば、大きなタスクも完了します。これは最高の状態です。元のタスクとまったく同じ、完璧な分解ができるのです。
残念ながら、それぞれの小さなタスクを一度だけ確実に実行するのは容易ではありません。最もよくある状況は「偽の失敗」です。小さなタスクが終了したにもかかわらず、成功したことを記録したり、他のタスクに伝えたりすることができません。そのため、このタスクは誤って “失敗した “とみなされます。偽の失敗は、ジョブが複雑な環境で実行されている場合に特に大きな問題となります。このような失敗には、マシン障害、ネットワーク障害、プロセス障害などがあります。
大きなタスクを分解し、均等に分割された小さなタスクのリストを得るための最良の方法は、「複数の成功 」を許容することです。どの小さなタスクも、複数回終了しても同じ結果になる可能性があります。これを表す言葉がある: “冪等 (べきとう) “です。例えば、「数字を2にする」というタスクであれば、そのタスクは常に同じ結果を返すのでべき等です。小さなタスクが「数値を1増やす」なら、そのタスクは前の値に基づいて変化する結果を返すので、冪等ではありません。
冪等設計では、「すべてのアトミック・タスクが少なくとも一度はコミットされる 」という当初の目標を緩和することができます。この設計は実装がはるかに簡単で、Kafkaのようにすでに多くの成功した実装例があります。べき等によって、物事を分解しながらも一貫性を保つことができます。これが最初のステップで非常に重要な点です。
アトミック・タスクを構築する設計
小さなタスクをアトミックにするためには、タスクの内部からの視点と、タスクの外部 (タスクのステータスと返す結果) からの視点の2つが必要です。タスク内部の視点から見ると、タスクは通常複数のステップを含み、先に説明したように、タスクは必然的に各ステップの失敗の可能性に直面します。デフォルトでは、小さなタスクはアトミックではありません。しかし、タスクの外部から見れば、タスクの状態と結果をチェックするために、アトミックである必要があります。そのためには、最も重要なステップ、つまり最後のステップの結果だけを追跡すればいいのです。その 「フラグ・ステップ 」が成功すれば、そのタスクは成功したと判断します。そうでなければ失敗と判断します。
フラグ・ステップのアプローチは単純ですが繊細でもあります。タスクは、フラグ・ステップが完了したときにのみ、完了したと主張し、結果を提供します。したがって、タスクの外部からはアトミックです。タスクの内部では、すべてのステップを保持し、いくつの失敗も許容できるので、実装は簡単です。唯一気をつけなければならないのは、タスクが再び呼び出される可能性があるかどうかです。以前に呼び出されたステップから何かが残っているかもしれないので、これを処理する最も簡単な方法は、すべての 「残骸 」を捨てることです。
前回紹介したOvercookedの例で言えば、マッシュルームを客に提供するには、切る、調理する、料理を提供するという3つのステップが必要です。料理を提供するのはフラッグ・ステップです。料理人がトイレに行ったり戻ったりしたとか、あるステップが失敗したとか、そういうことが起きたら、料理が提供されたかどうかを判断してステータスをチェックします。そうでない場合は、前のステップをチェックします。マッシュルームが切られているかどうかをチェックし、次に火が通っているかどうかをチェックします。もし火が通りすぎていたら、マッシュルームを片付けて調理し直す必要がある。お客さまに料理を提供できて初めて、この作業は成功したことになります。
このゲームのロジックをデータ処理に応用すれば、実行に失敗した残骸を捨てることができます。これは通常、マシンの再起動時に処理されます。
アトミック・タスクの粒度を慎重に決める
前に、1TBのファイルをコピーすることを例にデータの一貫性を保ちながら、大きなタスクをいくつもの小さなタスクに分解する方法について説明しました。このタスクは、32KBのデータブロックのコピーに分解できます。しかし、なぜ32KBなのか?小さなタスクの大きさはどのように決めればいいのでしょうか?検討すべき視点はいくつかあります。
タスクを小さなタスクに分解するにはリソースを必要とします。粒度が小さければ小さいほど、アトミックなタスクが多くなります。サイズに関係なく、タスクの実行には固定コストがかかります。従って、粒度の大きなアトミック・タスクの方がタスク分解オーバヘッドは小さく、通常は高いスループットを達成できます。さらに、並列化を使用する場合、より多くのタスクは、性能を損なうよりも、より高い競合状態を作り出す可能性が高いです。
一方、粒度が小さいと、タスクごとに占有されるリソースが小さくなるため、全体のリソース使用量のピーク値はずっと低くなります。さらに、障害コストもずっと低くなります。ストリーミングとパイプライン化を組み合わせると、最初のアトミック・タスクの最初のステップと最後のアトミック・タスクの最後のステップは、1つのリソースしか消費しません。そのため、タスクが十分に大きければ、リソースの無駄が生じます。この場合、粒度が大きいほど無駄が多くなります。
| より小さな粒度 | より大きな粒度 | |
| タスク分解オーバヘッド | より大きい | より小さい |
| アトミック・タスクごとのリソース | より少ない | より大きい |
| 失敗のコスト | より低い | より高い |
| 最初と最後のアトミック・タスクのアイドルリソースのコスト | より低い | より高い |
| スループット | より低い | より高い |
つまり、タスクが大きすぎても小さすぎてもコストがかかります。バランスをとる技術が必要で、アトミック・タスクの粒度を慎重に決める必要があります。それは、アプリケーションが使用するハードウェアとソフトウェアを総合的に考慮したものでなければなりません。2つのシナリオで説明しましょう。
シナリオ1では、7200RPMのハードディスク・ドライブにファイルをコピーします。平均シーク時間は3~6ミリ秒、最大ランダムR/W QPSは400~800、R/W帯域幅は100MB/秒です。各アトミック・タスクが100KBより小さい場合、パフォーマンスが低下する可能性が高くなります。
task size = 100 KB = (R/W bandwidth)/(maximum random QPS) = 100 MB/800シナリオ2では、アプリケーションは並列コーディングのためにデータを小さなチャンクに分解します。リソースの占有を通信するためにミューテックス (相互排他オブジェクト) を適用します。これまでの経験から、このレース条件では、ミューテックスの QPS は約100KB/s です。アプリケーション全体のスループットは、このタスクの場合、100KB* スライスサイズ以下となります。つまり、各チャンクが約4KBの場合、このアプリケーションの全体的なスループットは400MB/s未満になります。
throughput = 400 MB/s = size of slice * mutex QPS = 4 KB * 100 KB/sパイプライン化の実装
パイプライン化は、1つのアトミック・タスクで異なるリソースの異なる処理速度に合わせてリソースを割り当てます。パイプライン化の鍵は、1つのアトミック・タスクを、消費されるリソースに基づいて複数のステップに分解することです。そして、各ステップを別々に処理するために、複数のライン (ラインの数はステップ数に対応する) を使用します。ライン-1は全アトミック・タスクのステップ-1に対応し、ライン-2はステップ-2に対応する、といった具合です。そこから、より多くのハードウェアを使用し、処理時間を短縮し、はるかに優れたパフォーマンスを得ることができます。
ブロッキング・キューによるプロセスラインの実装
各プロセスラインはタスクプールです。ライン-1がタスク-1のステップ-1を終了すると、タスク-1はライン-2のプールに入れられます。そして、ライン-1がタスク-2のステップ-1を処理すると、ライン-2はタスク-1のステップ-2を処理します。
各ラインのタスクプールは、前のラインをプロデューサー、現在のラインをコンシューマとするFIFOキューです。
もしキューが満杯にもかかわらず、あるプロデューサーがそこにアイテムを追加しようとしたらどうなるでしょうか?逆に、キューが空で、コンシューマがそこから要素を取り出したい場合はどうなるでしょうか?ブロッキング・キューでは、もしキューが満杯であれば、私たちはプロデューサーをブロックし、空きがある場合にのみそれらを呼び出します。もしキューが空なら、コンシューマーをブロックし、キューにアイテムがあるときだけそれらを呼び出します。パイプラインの各ステップごとに、1つのブロッキング・キューが必要です。
Overcookedの例に戻ると、タスク-1はオーダー1で、切ると調理するという2つのステップを含んでいます。ライン-1が切るタスク (プロデューサー) で、ライン-2が調理タスク (コンシューマー) です。鍋は2つしかないので、キューのサイズは2つです。切り終わったら、材料を鍋に移さなければなりません。鍋がない場合、「移動」アクションはブロックされます。まな板用のブロック・キューと調理台用のブロック・キューが1つずつ必要です。
ブロッキング・キューは複数の言語で実装されています。JavaとScalaはBlockingQueueインターフェイスを提供しています。Goはchannel/chanを使用しています。C++では、std::queueとstd::mutexを組み合わせてブロッキング・キューを実装できます。ネットワーク実装では、select / epoll、またはtcp.send + tcp.receive + waitがすべてブロッキング・キューとみなされます。
いくつかの留意点
ブロッキング・キューを使用する際には、以下の点に留意してください。
一つ目は、1つのキューがブロックされた場合、すべてのキューがブロックされなければなりません。そうしないと、より高速な回線によってリソースが制御不能に消費されてしまいます。各ブロッキング・キューの最大サイズを設定することで、自動ブロッキングを確実に行うことができます。言い換えれば、各ブロッキング・キューの最大サイズを設定することで、処理速度を自動的に設定することができます。
二つ目は、実行中ブロッキング・キューは満杯か空かのどちらかでしかありません。満杯とは、上流のステップの速度が速く、下流を待ち続けることを意味します。空とは、下流のステップの速度が早く、すべてのフローが速やかに下流に流されることを意味します。これらの満杯と空の動作は、ステップのキューサイズとリソース容量を決定するのに役立ちます。キューサイズは、リソースを占有はするものの、完全に利用するわけではないので、大きな数字にする必要はありません。このサイズは、タスクのキュー内時間を短縮し、処理の待ち時間を短縮するために、できるだけ小さくする必要があります。しかし、キューは十分な大きさが必要で、タスク処理時間が安定した数値でなければ、タスク不足のために処理ラインが一時停止することはありません。実際には、このサイズはベンチマーク・テストに由来するもので、最初は小さな数字で設定されるべきです。
三つ目は、ブロッキング・キューは、一時停止と再開のアクションを駆動するために、リアルタイムのシグナルを使うべきだということです。悪い例は、キュー内のタスク数を定期的に検査することです。これは、”should action “から “do action “までの差分時間を持っており、おそらくリソースが制御不能になり、余分な処理時間がかかるという問題を引き起こすでしょう。
四つ目は、非同期であったり、境界を越えていたりするため、エラー処理が厄介な場合があることです。良いやり方は、エラーメッセージを含む各タスクのステータスメッセージを用意することです。ラインごとにエラーメッセージをチェックしましょう。
並列化の実装
ストリーミングとパイプライン化の後、プロセス中のさまざまなタイプのリソースが、別々のラインによって消費されます。ボトルネックとなるリソース (例えばI/Oリソース) は通常、タイトなループの中で1つのラインによって消費されます。これにより、システムのパフォーマンスが大幅に向上します。しかし、ボトルネック・リソースを完全に利用するには複数のラインが必要になるため、ここで並列化が行われます。
スレッド数を慎重に決める
並列化を実装するには、いくつかのヘルパーが必要です。例えば、複数のプロセスや複数のスレッド、複数のコルーチンや複数のファイバー、複数のネットワーク接続などです。より良いパフォーマンスを得るためには、同時実行スレッド数を慎重に決める必要があります。
同時スレッド数を増やせばQPSが向上するとは限りません。場合によっては、アプリケーションのパフォーマンスが低下することもあります。同時並行性が高くなると競合状態が多くなり、その結果QPSが低下することがあります。また、コンテキスト・スイッチングにもコストがかかります。次の図では、2スレッドのQPSは8スレッドのQPSの約4倍であることがわかります。
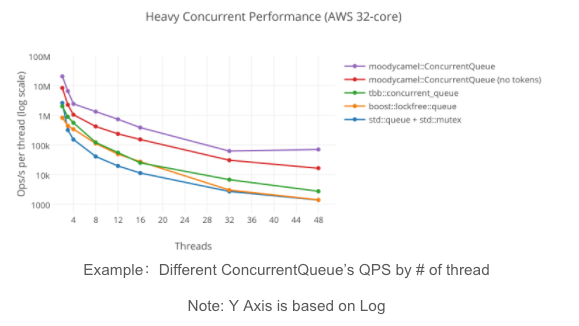
並行処理性能の高さ (AWS 32コア)
ソース: C++用高速汎用ロックフリーキュー
Overcookedゲームでは、人数が多ければ多いほど多くの料理を簡単に出せるというわけではありません。お互いの足元を踏まないように、始める前によく話し合って戦略を立てる必要があります。そうしないと、同じリソースを奪い合うことになりかねません。例えば、みんなが食器を使っているのに、誰も使った食器を洗おうとしません。あるいは、私は調理だけを担当しているので、食材を切るのを待つ必要があるのですが、上流の人が効率的にやってくれません。これではリソースを最大限に活用できず、待ち時間が無駄になってしまいます。
ボトルネックとなるリソースの最大消費量に達することができる限り、同時実行スレッド数を最小限に抑える必要があります。また、隠れた競合条件にも注意する必要があります。例えば、1GBのテーブルに対してハッシュ結合中にフルテーブルスキャンを実行し、各アトミックタスクが1MBの場合、隠れた競合状態が存在します。すべてのタスクはスキャン中に同じグローバル・ハッシュマップにアクセスする必要があります。ハッシュマップにアクセスする粒度は非常に小さいため、大きなQPSを必要とし、システムが競合する可能性が高くなります。実行時にパフォーマンスのボトルネックになることは間違いありません。
設計段階で並列化戦略を決める
Overcookedでプレーボタンをクリックする前に戦略を明確に伝える必要があるように、アプリの設計段階でも並列化の戦略が必要です。私たちは、高スループット・アプリケーションのための確固たる設計を形成するのに役立つレシピを提供します。
並列化戦略の設計には2つの原則があります:
- 競合条件を減らす
- ボトルネックになっているリソースをフルに活用する
並列化には多くの戦略があります。一般的なものは3つ挙げられます:
- グローバル並列化のみ
- グローバル並列化とローカル並列化
- ローカルパイプライン化によるグローバル並列化
次の表は、それぞれの戦略を示したものです。
| グローバル並列化のみ | グローバル並列化+各スレッド内でのパイプライン化 | パイプライン化が主なプロセス+パイプライン上の各ステップでの並列化 |
 |  |
最も一般的な方法:グローバル並列化のみ
最も一般的な戦略は、グローバル並列化のみです。例えば、8つのスレッドが同時に実行されている場合、1つのスレッドがタスクの1/8を担当し、それを単独で処理します。スレッドの実行内部でストリーミングやパイプラインが行われるとは限りません。Overcookedのゲームで言えば、4人の異なるプレーヤーが最初から最後まで1つのオーダーに取り組み、互いに助け合わないようなものです。
グローバル並列化は、実装が最も簡単なので、最も一般的なアプローチです。パフォーマンス要件がそれほど高くない場合は、この方法で実行しても問題ないかもしれません。しかし、ほとんどの場合、高スループットアプリケーションには適した戦略ではありません。これは主に、時間によるリソース消費を正確に制御できないためで、スレッド間でリソース使用量に関して連携する方法がないためです。リソースを完全に使用することはできません。ある瞬間には、あるスレッドでリソースがピークに使用されている一方で、別のスレッドではアイドル状態になっている可能性があります。スレッドは互いの状態を知りません。
グローバル並列化なしのパイプライン化
2つ目の戦略は、グローバル並列化を行い、各スレッド内でパイプライン処理を適用するものです。Overcookedの例で言うと、プレイヤーAとBが協力して材料を切り、プレイヤーCとDが協力して調理を行うようなものです。
この実装の一例が、オンライン分析処理 (OLAP) カラム型データベースのClickHouseにあります。ディスクにアクセスするために、ClickHouseは全体の処理をいくつかのスレッドに分解し、並列計算とディスク読み込みを行っています。各スレッドは特定のデータ範囲で動作します。ディスク読み取りステップではパイプライン処理が適用されます。読み込みが低速ディスクの場合、I/Oがボトルネックリソースとなります。高速ディスクの場合は、CPUがボトルネックリソースとなります。どちらの状況でも、パイプライン化が適用されるため、タイトなボトルネックはリソース消費をフラットにすることができます。これは並列化に適した設計です。
グローバル並列化を行わないパイプライン処理
もう1つよく使われる戦略は、グローバル並列化を行わずにパイプライン化をメインプロセスとして使い、パイプライン上のすべてのステップで並列化を適用するものです。(実際にはこれは必要ありません。最も遅いステップに並列化を適用すればよい場合もあります)。Overcookedゲームでは、調理にほとんどの時間がかかるため、プレイヤーA、B、Cはすべて調理に取り組み、プレイヤーDは残りの作業、例えばみじん切りや皿洗いを一人でやるという戦略が相当します。
これはトランザクションの観点からは理にかなっています。なぜなら、システム内のすべてのリソースを一度に使って1つのステップを処理する際に、グローバルなデータコンテキストを提供できるからです。また、ローカリティが向上し、キャッシュをより有効に活用できます。
最後になりますが、ニーズに応じて戦略を組み合わせることができます。説明したように、多くのことがパフォーマンスに影響する可能性があります。必ずベンチマークを実行して、システムのパフォーマンスに影響する要因を特定してください。
パーティショニング:特殊な並列化
パーティショニングは一種の特殊な並列化です。異なるパーティションはタスクを共有しないため、グローバル並列化のみを使用してパーティショニングを検討することができます。パーティショニングにより、競合条件の副作用なしに、より多くのスレッド数を実際に達成することができました。
しかし、パーティショニングには限界があります。各パーティションが互いに依存し合わなければなりません。そして、速いパーティションは遅い部分の終了を待つ必要があります。つまり、タスクの全体的な完了時間は、最も遅いシャードの作業終了に依存します。シャードを待つことによる損失は、予想以上になる可能性があります。パーティションの数が多ければ多いほど、アイドル・リソースに伴う損失が大きくなります。
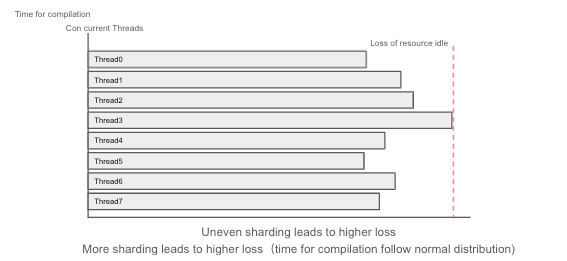
不均一なシャーディングは損失増につながります。
シャーディングが多いほど損失が大きくなります。 完了までの時間は正規分布に従います。
まとめ
デジタルトランスフォーメーションのトレンドは作業負荷が増加し、システム設計の課題を露呈させます。処理システムにリソースを追加するとコストが増えます。パフォーマンスは最適化ではなく、設計の結果であるべきです。ストリーミング、パイプライン化、並列化を利用して、より良いスケジューリングができるようにアプリケーションを設計し、ボトルネックとなるリソースをフル活用することができます。これにより、各ノードでより高いスループットを達成し、システム全体のスループットを向上させることができます。
アプリ開発について詳しく知りたい場合は、ぜひご意見をお聞かせください。TwitterやSlackチャンネルからお気軽にお問い合わせください。また、データ集約型アプリケーションのスーパーチャージに関するソリューションについては、当社のウェブサイトをご確認ください。
こちらも併せてお読みください:
ストリーミング、パイプライン、並列化を使って高スループットのアプリケーションを構築する (前編)
Spring BootとTiDBによるWebアプリケーションの構築
RetoolとTiDB Cloudを使って、30分でリアルタイムカンバンを作る
Related Resources

Product
June 29, 2026
TiDB Completes Independent Security Assessment by NCC Group

Thought Leadership
June 2, 2026
Beyond Context Windows: Memory is the Runtime for Production Agents

Product
May 11, 2026
From Preview to Production: TiDB Cloud Dedicated on Microsoft Azure is Now Generally Available
TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。