

※このブログは2026年02月18日に公開された英語ブログ「Raft Region Size:The Invisible Lever for Distributed Database Performance」の拙訳です。
分散データベースをチューニングしたことがある人なら、CPU、メモリ、レプリケーション係数、同時実行数といった分かりやすいパラメータを調整した経験があるでしょう。しかし、あまり注目されないにもかかわらず、性能・信頼性・運用のしやすさに大きな影響を与える設定があります。それがRaftのリージョンサイズです (訳注:「リージョン」はTiDB独自の概念。本ブログではRaftプロトコル本来の用語ではなく、TiDBの実装上のデータ分割単位としてこの表現を使用しています)。
TiDBでは、TiKVを通じて扱われるリージョンサイズは、クラウドのリージョン (例:us-west-1) ではなく、データの分割単位のサイズを指します。
これは、データの分割・複製・移動・復旧の方法を決定し、ホットスポットの挙動から障害時の影響範囲まで、あらゆるものに影響を与えます。にもかかわらず、しばしば単なる「シャードサイズ」と誤解されがちです。しかし実際はそれ以上のものです。
リージョンサイズは、グローバルな物流ネットワークにおけるコンテナの大きさに近いものです。小さすぎると調整コストに押し潰され、大きすぎるとすべての移動が遅く、リスクが高く、高コストになります。適切なサイズはなんとなく決まるものではなく、物理法則・ネットワーク・人間の運用が複雑に絡み合った結果として決まります。
では、詳しく見ていきましょう。
TiKVのリージョンとは?連続したキー範囲の理解
TiKVにおけるリージョンとは、次のようなものです:
- 連続したキーの範囲 (行・テーブル・ファイル単位ではない)
- 1つのRaftグループとして管理
- 通常は3つのレプリカで同期的に複製
- スケジューリング、負荷分散、フェイルオーバー、スナップショット転送の最小単位
1つの論理テーブルは通常、複数のリージョンに分割されます。これはテーブルデータにもインデックスにも同様に適用されます (ただし概要を理解するこの段階では両者の区別は重要ではありません)。
もしTiKVをアメリカ合衆国を例にするなら:
- リージョンは州
- Raftグループは州政府
- PDは中央計画機関
- Leaderは州知事
Raftのリージョンサイズは固定ではない
まず重要なポイントです。「リージョンサイズ」とは固定値ではなく、目標値です。
TiKVでは:
- データ書き込みに伴ってリージョンは自然に成長する
- 閾値を超えると分割される
- 小さすぎる隣接リージョンはマージされる
つまりリージョンサイズとは:箱をどれくらいの大きさにしたいかであって、すべての箱は必ずこのサイズでなければならないというものではありません。
この違いは重要で、極端な値を設定してもTiKVが拒否しない理由や、誤った設定でシステムが破綻する理由を説明しています。
Raft Region Sizeがバランスをとる必要がある3つの力
リージョンサイズの決定は、以下3つの力のトレードオフです。
1. 並列性
リージョンが小さいほど:
- Raftグループが増える
- Leaderが増える
- 負荷分散の機会が増える
これはスーパーのレジをたくさん用意するようなものです。人員と調整が破綻しない限り、並列処理能力は上がります。
2. オーバーヘッド
各リージョンには以下のコストがあります:
- Raftハートビートは、RaftグループからPD (Placement Driver) へ送られる定期的なレポートです。これは単なる生存確認メッセージに留まらず、リージョンのサイズ、リーダーやピアの情報、そしてスケジューリングに関する統計データなどが含まれています。
- ログレプリケーション
- メタデータ管理
- スケジューリング
- Leader選出
リージョンが多すぎると、全チームが毎週役員会議をする会社のようになり、調整ばかりになります。
3. 復旧と移動
リージョンは以下の単位でもあります:
- フェイルオーバー
- 再配置
- スナップショット転送
大きなリージョンは重い貨物列車のようなものです。強力ですが、脱線が発生した際に経路変更するのは遅くなります。
OLTP vs OLAP:同じリージョンでも異なる負荷
これらの要素は、データの利用方法によって異なる影響を受けます。TiKVにおけるトランザクション実行とTiFlashにおける分析実行は、同じリージョン分割方式に対してまったく異なる負荷を与えます。
分析の観点:TiFlashにおける考慮事項
リージョンサイズがTiFlashに与える影響はTiKVとは異なります。
TiKVは主にリカバリ、リバランス、障害ドメインに関心があります。一方でTiFlashは主にスキャンの並列性とデータの取り込み効率に関心があります。
TiFlashはリージョン単位で分析スキャンを実行します。これは、リージョンサイズがOLAPの並列性の形を直接制御することを意味します。
リージョンが小さすぎる場合:
- スキャンの並列性が増加する
- レプリケーションのファンアウトが増加する
- データ取り込みおよびコンパクションに伴う書き換え負荷が増加する
- 過剰なタスク調整により実行オーバーヘッドが増大する
この場合、TiFlashはデータ分析よりもリージョン管理に多くの時間を費やすようになります。リージョンが大きすぎる場合:
- 同時スキャンタスク数が減少する
- 分析クエリ中のCPU使用率が低下する
- 作業を均等に分散できないためテイルが増加する
- 書き込みスパイクや障害発生後におけるレプリカのキャッチアップは、データ取り込みの単位がリージョンサイズであるため、低速化する
クラスタの状態が正常であっても、TiFlashの稼働率が低く、動作が鈍いように見えることがあります。TiFlashにおいて、リージョンサイズは障害の境界を定義するものではありません。これは分析処理の粒度を定義するものです。粒度が細かすぎると、データ取り込みの負荷が高まります。逆に粒度が粗すぎると、並列処理の効果が制限されます。
小さすぎるリージョンの罠 (なぜ1MBは悪いのか)
理論上、小さなリージョンは魅力的に見えます:
- 細粒度の負荷分散
- 優れたホットスポット分離
- 高速な個別処理
しかし実際には以下が発生します。
システムの挙動
- リージョンが絶えず分割されてしまいます
- リージョン数が数十万〜数百万に爆発的に増加します
- PDが膨大なメタデータを追跡します
- Raftグループ数が制御不能に増殖します
最初に壊れるもの
- PDのCPUとメモリ
- Raftのハートビートトラフィック
- Leader選出選挙の嵐
- スケジューラのスラッシング
これは、貨物船の艦隊を数百万のドローンに置き換え、それぞれに航空管制が必要になる状況に似ています。システムは正しさではなく、調整能力によって破綻します。
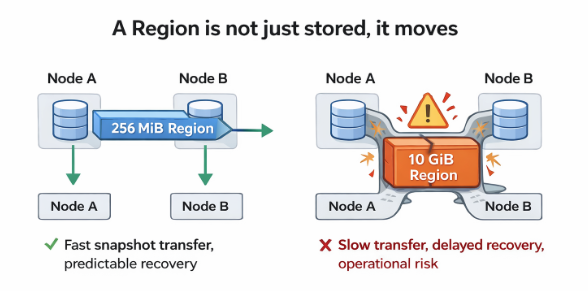
大きすぎるリージョンの罠 (なぜ1PBはさらに悪いのか)
今度は逆方向に振ってみます。リージョンサイズを極端に大きくすると、リージョンは分割されなくなります。
システムの挙動
- 少数の巨大なリージョンに集約されます
- 各リージョンが巨大な障害ドメインになります
最初に破綻するもの
- スナップショット転送が現実的でなくなります
- リバランスが停止します
- ホットスポットを分離できなくなります
- フェイルオーバー時間が大幅に増加します
これは、地域ごとではなく都市全体の人口を一度に移動させて避難させる状況を想像すると分かりやすいです。単に遅いだけではありません。実行不可能です。
大きなリージョンは、派手に障害として現れるわけではありません。リカバリを非現実的にすることで、静かに破綻します。
Raftリージョンサイズバケット:中間の選択肢
これらの落とし穴を両方見てくると、そのジレンマは明らかです:
- 小さなリージョンでは並列処理が可能になりますが、オーバーヘッドが膨大になります
- 大きなリージョンではオーバーヘッドは減りますが、リカバリやスキャンが著しく遅くなります
そこで登場するのがリージョンバケットです。バケットは、リージョン内部を細分化してクエリの並列実行を可能にします。これは、新しい高速道路を作るのではなく、既存の高速道路に車線を追加するイメージです。その特徴は以下の通りです:
- 新しいリージョンは作成されません
- 新しいRaftグループは生成されません
- レプリケーション、スケジューリング、フェイルオーバーの境界には影響しません
運用上、これにより安定したリカバリ動作は維持されつつ、必要な部分でより細かい実行単位を活用できます。
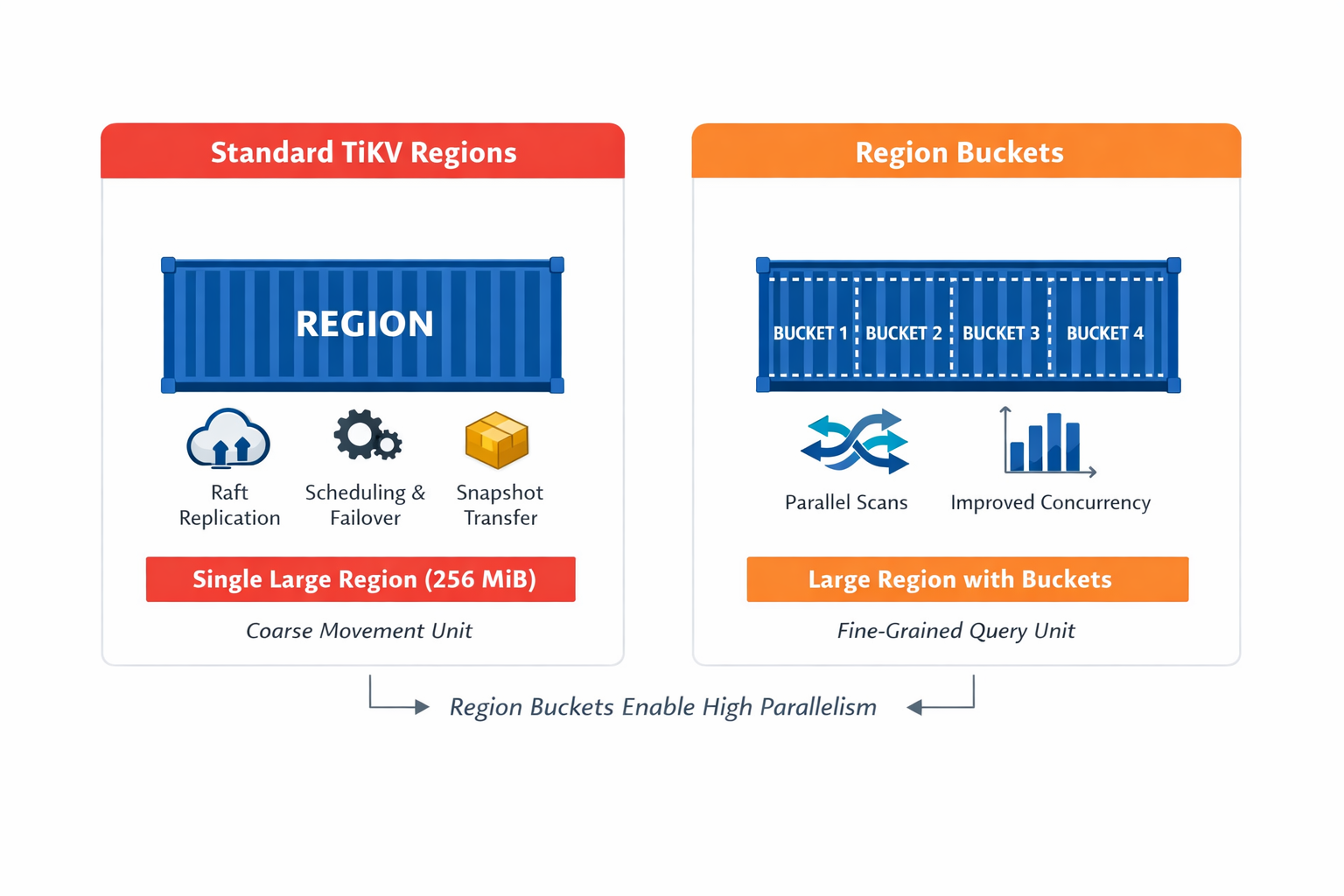
重要な注意点:リージョンバケットは現時点で実験的な機能であり、対象を絞ったスキャン重視のワークロード向けであって、広範囲な本番利用を想定したものではありません。
Raftリージョンサイズ:なぜTiDBは256MBを採用したのか
分散システムにおけるデフォルト値は、過去の戦いの傷跡です。
TiDBのデフォルトリージョンサイズは、バージョン8.4.0までに96MBから256MBに進化しました。現在の推奨運用範囲はおおよそ48MBから256MBで、256MBが最新のデフォルトとして選ばれています。
ハードウェアの進化 (NVMeストレージ、高速CPU、25/100 GbEネットワーク) に伴い、多くの小さいリージョンを管理するコーディネーションのオーバーヘッドが、256MBスナップショットを移動するコストよりも大きなボトルネックになったためです。
256MBのメリット:
- 迅速な移動、安定したリカバリ、被害範囲の制限が可能な十分な小ささ
- リージョン数の爆発を避け、Raftのオーバーヘッドを削減し、PDの安定性を維持できる十分な大きさ
TiDBの標準的な輸送コンテナと考えることができます:
- 船、トラック、クレーン、港湾、労働力に最適化
- すべての貨物に完璧というわけではない
- ほとんどの貨物には十分対応可能
実務でのリージョンサイズ設定方法
リージョンサイズは、以下の設定で制御されます:
coprocessor.region-split-size |
この設定は、TiKVがリージョンをいつ十分に大きいと判断して分割するかを決定します。
設定値を調整する際には、いくつか重要な制約があります:
- TiFlashやDumplingを使用する場合、リージョンサイズは1GBを超えてはいけません
- リージョンサイズを大きくした場合、Dumplingの並列度を下げる必要があります。さもないとTiDBがメモリ不足になる可能性があります
これはリージョンサイズ設計の重要なテーマを再確認させます:大きなリージョンはコーディネーションのオーバーヘッドを減らす一方で、リージョン全体に関わる操作のコストは増えるということです。
ドキュメント化されたガードレール (厳密な制限ではない)w
TiDBは意図的に厳密な上限を設けていません。その代わり、安全に運用できる範囲をドキュメント化しています:
推奨:約 48 MB 〜 256 MB
一般的な値: 96 MB, 128 MB, 256 MB
強い警告: 1 GB 以上
明確な危険ゾーン: 10 GB 以上
その運用方針はシンプルです:
「オペレーターを信頼する。ただし、システムが危険に達する境界点は明示する。」リージョンサイズ設定の失敗:症状と原因
| 症状 | 考えられる原因 | 発生理由 |
| PDのCPU/メモリ使用率が高く「ハートビートストーム」が発生 | 小さいリージョンの罠 (例:1MB以下) | PDが膨大なメタデータを追跡し、数百万もの個別Raftグループを調整する必要があるため |
| 頻繁なリーダー切り替えとスケジューラの処理過多 | 小さいリージョンの罠 | 小さな「プロヴィンス (地域)」が多すぎると、生産的な作業よりも調整オーバーヘッドが増大します |
| スナップショット転送が不可能またはタイムアウトする | 大きいリージョンの罠 (例:10GBより大きい) | 巨大なリージョンを移動するのは、都市全体の人口を一度に移動させるようなもので、パイプが耐えられません |
| 分割や移動できない局所的ホットスポットが発生 | 大きいリージョンの罠 | リージョンはスケジューリングの最小単位であるため「巨大」リージョンは細分化できず負荷を分散できません |
| ノード障害時のフェイルオーバー時間が膨張 | 大きいリージョンの罠 | フェイルオーバー単位が大きすぎるため、リカバリの再ルーティングや再構築が現実的でなくなります |
| TiFlashの取り込みによる書き換え負荷 (データ更新処理の繰り返し) や実行オーバーヘッドが過剰 | 小さいリージョンの罠 | 小さいリージョンはレプリケーションのファンアウトを増加させ、TiFlashがデータ管理に多くの時間を費やします |
| スキャン時のTiFlash CPU利用率が低くOLAPクエリのテールレイテンシが高い | 大きいリージョンの罠 | リージョン数が少なく、1リージョンあたりが大きすぎるため、並列化が効率的に行えません |
リージョンサイズを変更せずにオーバーヘッドを減らす
リージョンサイズを大きくすることだけが手段ではありません。以下は、オーバーヘッドを軽減する追加の方法です。
リージョンのマージ
隣接する小さなリージョンをマージすることで、リージョンの総数とスケジューリングオーバーヘッドを減らすことができます。
リージョンのハイバネート (休止)
ハイバネートリージョンは、非アクティブなリージョンをスリープ状態にする機能です。リージョンが読み書きを受けていない場合:
- Raftのハートビートを抑制
- リーダーの活動を減少
これにより、小さいリージョンの罠が巨大でアクセスの少ないデータセットに対しても致命的になりにくくなります。特に「ロングテール」のデータを扱うユーザーに価値があります。イメージとしては、建物を壊すのではなく、空いているオフィスの電気を消すようなものです。
Active PD FollowerによるPDのスケーリング
リージョン数が多いとPDにも負荷がかかります。
Active PD Followerは以下の方法でこの負荷を緩和します:
- フォロワーでリージョンメタデータを同期
- TiDBノードがフォロワーに直接問い合わせ可能にする
- PDノード間でメタデータリクエストをロードバランス
これにより、リージョンの意味論や一貫性保証を変えることなく、スケーラビリティを向上できます。
なぜTiKVは危険な操作を止めないのか
厳格な制限を設けない理由は、リージョンサイズがハードウェア依存、ネットワーク依存、ワークロード依存だからです。例えば、100GbEのベアメタルクラスタは、共有ストレージ上のクラウドクラスタとは挙動が大きく異なります。
TiKVは禁止よりポリシーを選択します。危険な操作を止めることはありませんが、その代償が明確に分かるようにします。
永遠に覚えておくべきメンタルモデル
もし一つだけ覚えるとしたら、次のことです:リージョンサイズはストレージの話ではなく、データの移動の話です。
データがどれだけ速く動けるか:
- ノード間で
- 障害発生時に
- リバランス中に
- 成長時に
最適なリージョンサイズとは、問題が発生する速度に合わせてデータが最も速く動けるサイズのことです。
最終的なまとめ:ゴルディロックス (ちょうどよい) ゾーン
Raftリージョンサイズは、分散システム全体を静かに制御するガバナーのような存在です。スループット、リカバリ速度、運用の安定性の間で重要なバランスを設定します。
- 小さいリージョンの罠 (小さすぎる):数百万のハートビートのノイズに溺れます。調整オーバーヘッドがシステムを崩壊させ、実際の作業を始める前に止まってしまいます。
- 大きいリージョンの罠 (大きすぎる):自分のデータの重さに麻痺します。危機時にコンテナが重すぎて移動できず、リカバリが現実的でなくなります。
- 256MBの現代のデフォルト:これはTiDBの「標準的な輸送コンテナ」です。PDの「連邦プランナー」を安定させるには十分大きく、かつ「脱線」が発生したときに迅速に移動できるほど小さいサイズです。
分散システムにおいて、退屈であることは最大の褒め言葉です。適切なリージョンサイズを選ぶことで、データベースを劇的に壊れやすくするのではなく、予測可能で堅牢な状態に保つことができます。
データベースの安定性を偶然に任せないでください。現在のリージョン分布を監査し、現代的な256 MBデフォルトを安全に適用するには、リージョンパフォーマンスの調整をご覧ください。
TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。