

※このブログは2025年12月16日に公開された英語ブログ 「The Making of TiDB X: Origins, Architecture, and What’s to Come」 の拙訳です。
先日開催された年次イベントTiDB SCaiLEにおいて、TiDB Cloudの新しいコアエンジンであるTiDB Xを発表したところ、反響は即座に、そして非常に大きなものとなりました。発表後、多くの方々から、TiDB Xはどのようにして生まれたのか、なぜ開発することにしたのか、そしてそれがTiDB Cloudの将来とどのようにつながっているのかについて、技術的な質問から技術以外の質問まで、さまざまな問い合わせが寄せられました。すべての方に個別に返信する代わりに、私たちはこのストーリーを書き残すことにしました。新しいエンジンのアーキテクチャだけでなく、その背景にある考え方、途中での試行錯誤、そしてこのエンジンに至るまでの長年にわたる進化の過程についても含めてお伝えします。
TiDB Xは突然生まれたわけではありません。
それは、TiDB Cloudの構築を何年も重ね、限界に直面し、長年の常識に挑戦し、最終的に、これまでの延長線上にあるアプローチでは、進むべき未来には到達できないと判断した結果として生まれたものです。多くの点で、TiDB Xは原点に立ち返る試みと言えます。すなわち、なぜ私たちはTiDBを作ったのか、顧客が本当に価値を置いているものは何か、そしてAIやクラウドネイティブ開発によって変化した世界において、スケーラビリティとは本当は何を意味するのか、という問いに立ち返ることです。
最も重要な問いに立ち返る:なぜ人々はTiDBを選ぶのか?
長年にわたり、私たちが社内で直面してきた大きな課題の一つは、TiDB Cloud Starter とTiDB Cloud Dedicatedの間に存在するアーキテクチャの分断でした。両者はTiDBという名前を共有していましたが、技術、チーム、進化の方向性において大きく異なっていました。私たちは統合を何度も試みましたが、いずれも成功しませんでした。
最終的に私たちの方向性を再び揃えるきっかけとなったのは、非常にシンプルな問いでした。「なぜユーザーはTiDBを選ぶのか?」数えきれないほどの会話を通じて、その答えは常にたった一つの言葉に集約されました — スケーラビリティです。
それは単にデータ量やスループットの話ではなく、実運用においてデータベースが限界に達するあらゆる次元におけるスケーラビリティを意味しています。インデックス、テナント、テーブル、コネクション、メタデータ、運用の複雑性などです。システムは最も強い部分で失敗するのではなく、最も弱い部分で限界に達します。TiDBはこれらすべての要素において、他に類を見ないバランスの良さを示してきました。
一例としてAtlassianの事例があります。Atlassianでは、単一のデータベース内で数百万のテーブルをサポートする必要がありました。データサイズ自体はそれほど大きくありませんでしたが、メタデータに対する要求は非常に高いものでした。競合するシステムは数千テーブル規模で限界を迎えましたが、TiDBはほぼ1,000万テーブルまでスケールし、この導入を勝ち取りました。この事例は、私たちが繰り返し目にしてきた核心的な事実を改めて裏付けています。スケーラビリティこそがTiDBの得意分野であり、しかもそれは決して固定的なものではないということです。
10倍または100倍のスケールでは何が起きるのか?
私たちは従来のTiDBアーキテクチャを、かつて考えていた以上に拡張しました。快適に運用できる100TBクラスタから、安定した1PB超クラスタまでです。しかし次に自然に浮かぶ問いはこうです。10PB以上のスケールでは何が起きるのでしょうか?
率直に言うと、従来のシェアード・ナッシングアーキテクチャ (ローカルストレージ上に構築されたもの) では、そのスケールに必要な柔軟性、コスト構造、運用上の動的な対応を提供することはできません。
今後10年間のワークロード、特にAIエージェントによって生成される個別SQL、爆発的に増えるロングテールのユースケース、大量の動的アプリケーションに対応するためには、データベースは次の2つのクラウド原則を完全に受け入れる必要があります。
- 弾力的なリソース:真の従量制コンピュート
- オブジェクトストレージ:安価で耐久性があり、大規模並列処理が可能なストレージ
もし今日のワークロードが手に負える範囲に思えても、歴史は私たちが未来を過小評価しがちであることを教えてくれます。ムーアの法則はそれを痛感させてくれます。私たちの想像力はめったに技術的現実に追いつきません。そして過去6か月のAIの進展だけでも、それは一層明らかになっています。
アプリケーションを数分で作成でき、データ収集が容易で、各ユーザーにAIエージェントが生成する個別ワークロードがある場合、SQLパターン、テーブル構造、クエリ経路の組み合わせはデータベースシステムのあらゆる部分に負荷をかけます。
そこで問いはこうなります。高速なイノベーションを維持しつつ、長期的な安定性と安全性を保証するデータベースをどう設計するか?
この問いこそが、TiDB Xの真の始まりを示しています。
TiDB Xの起源:初期の技術的構想
TiDB Xの方向性の最初の兆しは、私が2021年4月にCCFのカンファレンスで行った講演にまでさかのぼりますが、このアイデア自体ははるか以前から形成されていました。2017年ごろ、PingCAPの共同創業者兼CEOのMax Liuは、トランザクションの最適化を探求し、SQLレイヤーのテストを加速するための小規模な社内プロジェクトを立ち上げました。同時に、私たちはWiscKey論文 (FAST ’16) やDgraphのGo実装であるBadgerDBから影響を受けました。これらはLSMツリーにおいてキーと値を分離することで書き込み増幅を削減することを追求していました。
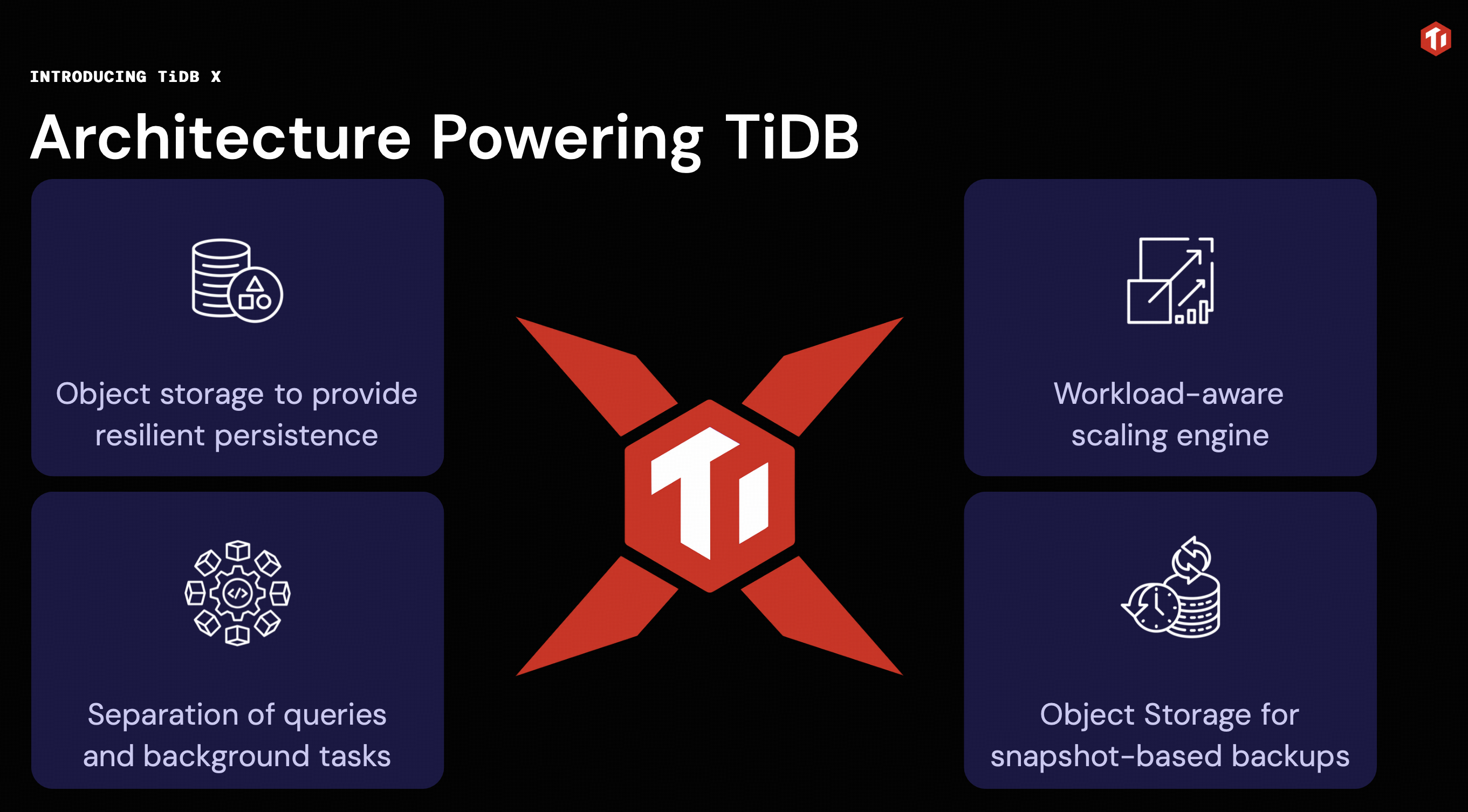
図1:TiDB Xがオブジェクトストレージ、ワークロードに応じたスケーリング、タスク分離をどのように組み合わせているか
Go愛好者として、私たちはBadgerDB上に構築したTiKV互換の分散キーバリューストアを試作しました。軽量で柔軟性があると感じましたが、その楽観的な考えが誤りであることは後に痛い目で学びました — TiDB Xは最終的にRustで書き直されました。それでも、このプロトタイプは重要なアイデアを生み出しました:ストレージに関する懸念をより積極的に分離できるということです。
同時に、Snowflakeのコンピュートとストレージの分離は、クラウドネイティブデータシステムに対する期待を再形成していました。SnowflakeはOLAPを対象としていましたが、私たちにOLTP向けの挑発的な問いを投げかけました:SSTファイルをS3上に置き、キャッシュとRaftログだけをローカルに保持することは可能か?RockSetやRocksDBチームのような他のプロジェクトも同様の方向性を探っていましたが、既存の制約の中での試みでした。私たちはさらに一歩進み、完全にサーバーレスでクラウドネイティブなOLTPデータベースを構築したいと考えました。
転換点:2022年と段階的な手法を捨てた決断
2022年までに、私たちはクラウドネイティブエンジンプロジェクトを再開し、具体的かつ挑戦的な目標を掲げました。それらは大胆すぎて、段階的な手法では実現できるものではありませんでした:
- 世界中の開発者向けに無料のTiDB Cloudサービスを提供。
- 新しいクラスタを数秒で作成し、完全セルフサービスに。
- 0から1億QPS/TPSまで自動でスケールし、同じ速度で0まで縮小することを可能に。
- データセットのサイズをキロバイトからペタバイトまでサポート。
- 標準的なクラウドAPIのみを使用し、特殊なハードウェアや特殊な構成に依存しないこと。
当時、最小規模のTiDBクラスタでさえ月に数百ドルかかりました。クラスタの立ち上げには数分かかり、大規模クラスタのスケーリングは、ワークロードをノード間でゆっくり再バランスする必要があったため数日かかることもありました。これらの制約は、私たちが描いていた未来には適合しませんでした。
1,000倍の改善を達成するには、段階的な手法を完全に捨てる必要がありました。
わかりやすい例えとしてニューラルネットワークの歴史があります。バックプロパゲーションは何十年も存在していましたが、十分な計算資源がなければその潜在能力を発揮できませんでした。2012年にAlexNetがGPUを利用して初めてAIブームが起こったのです — GPU自体は何年も前から存在していたにもかかわらずです。2022年、私たちはTiDBにも独自の「GPUの転換点」が必要だと気付きました。シェアード・ナッシングアーキテクチャはここまで私たちを支えてきましたが、それ以上の進化は難しくなっていました。
そこで私たちは、すべてを根本から作り直すことを選んだのです。
TiDB Xを支える5つのアーキテクチャ原則
何度も試行を重ねた結果、TiDB Xを形作った主要な原則は以下の通りまとめられます。
1. データベースではなくサービスを構築する
これは最も重要な転換です。TiDB Xはユーザーが導入するパッケージ型のデータベースではありません。オンラインのクラウドネイティブサービスであり、その製品としてSQLデータベース (この場合はTiDB Cloud) が提供されるという形です。この違いはすべてに影響します:チーム構成、デプロイ、監視、マルチテナンシー、スケーリング、アップグレード、そしてコンピュートとストレージの役割まで。
このマインドセットが、次の原則へと直接つながっています。
2. 真のSOA (サービス指向アーキテクチャ) を採用する
サービス指向アーキテクチャ (SOA) により、私たちは以下を実現できました:
- きめ細やかななスケーラビリティ
- 高密度なマルチテナンシー
- コスト管理
- 障害ドメインの分離
- コンポーネントの独立した進化
実際のところ、私たちの最大のアーキテクチャ的飛躍の多くは、分散システムのアルゴリズムによるものではなく、システム全体にこのSOAを徹底的に適用したことから生まれました。
3. 物理インスタンスではなく仮想クラスタを採用する
無料で世界中からアクセス可能なデータベースを提供したい場合、ユーザーごとに物理インスタンスを割り当てることはできません。最小構成でさえ同様です。ほとんどのユーザーは「コールド」であり、1時間に数回のリクエストしか送信しません。彼らは重要ですが、専用ハードウェアを割り当てることは不可能です。
TiDB Xでは仮想クラスタを導入しています。仮想クラスタはコンピュートとストレージを共有しながら、メタデータとルーティングによって分離を維持する論理的なクラスタです。仮想クラスタにより、数百万のテナントに効率的にサービスを提供することが可能になります。これは、サーバーレスデータベースの一部ベンダーが行っているように、Postgresのストレージ層をS3に置き換えるだけでは不十分である理由でもあります。完全な垂直分解とサービス指向設計がなければ、「サーバーレス」は表面的なものにとどまります。
4. 「ログがデータベースである」という原則を受け入れる
Auroraがこの考え方を広め、私たちはこれを現代データベース設計における最も根本的なな貢献の一つと考えています。ログが真実の情報源である場合、その他のすべては再構築可能になります:
- NVMeやメモリは高速な読み取りキャッシュを提供します。
- SSDは追記専用の書き込みに優れています。
- レプリケーションにより可用性と耐久性が確保されます。
- ローカルで状態を失っても問題にはなりません、再構築が可能なためです。
これにより、データ構造や正確性保証が簡素化され、カーネル開発者の負荷も軽減されます。
5. TiDBの強みを最大限に活かす:シャーディング戦略
TiDBの既存アーキテクチャは、私たちにいくつかの利点をもたらしました:
- SQLレイヤー (tidb-server) はステートレスで動作していました。
- 当初シームレスなオンラインアップグレードをサポートしていたtidb-proxyは、自然なゲートウェイサービスとなりました。
- TiKVの動的レンジベースシャーディングはすでに存在していました;以前の制約は、シャード移動に物理データの移動が必要でした。
TiDB Xでは、TiKVはステートレスになりますが、シャードの抽象は維持されます。シャードは論理化され、スナップショットストレージはS3に移行します。これにより、非常に大きな利点が生まれます:
- 数百〜数千のTiKVノードを瞬時に起動し、それぞれがシャードを並行してロードが可能。
- ルーティングを更新し、ノードを即座にシャットダウンすることで縮小が可能。
- 数時間に及ぶデータ移行作業を回避。
- シャードごとにRaftログを分割し、シングルライタのボトルネックを排除。
- マルチテナンシーの場合は、単にキーの先頭にtenantID_を追加するだけで、各テナントのフットプリント小さくかつ独立して動作します。
この組み合わせ — 論理シャード + S3スナップショット + ステートレスコンピュート — により、私たちが目指していた突破的な弾力性が実現されます。
TiDB Xで可能になること
TiDB Xは、AIエージェント、動的なワークロード、爆発的に増えるロングテールアプリケーションによって形作られる次世代ソフトウェア時代のために設計されています。SQLがユーザーごと、リクエストごと、コンテキストごとに生成される場合、データベースは数%単位でスケールするのではなく、桁違いに上下にスケールする必要があります。
TiDB Xはまさにそれを可能にします:
- クラスタを数秒で起動
- 数百万の軽量テナントにサービスを提供
- オブジェクトストレージを用いてペタバイト規模までスケール
- 巨大なトラフィックの急増に対応
- 「コールド」ワークロードのコストを最小化
- ユーザーに支持されるSQLという抽象化を維持
- 長期的な正確性と耐久性を確保
- クラウドの動態に応じた弾力性を提供
TiDBは常にアプリケーションの柔軟性を尊重するデータベースとして設計されてきました。TiDB Xは、シェアード・ナッシングアーキテクチャの限界を超えてさらにスケールする道を与えることで、その使命を強化します。
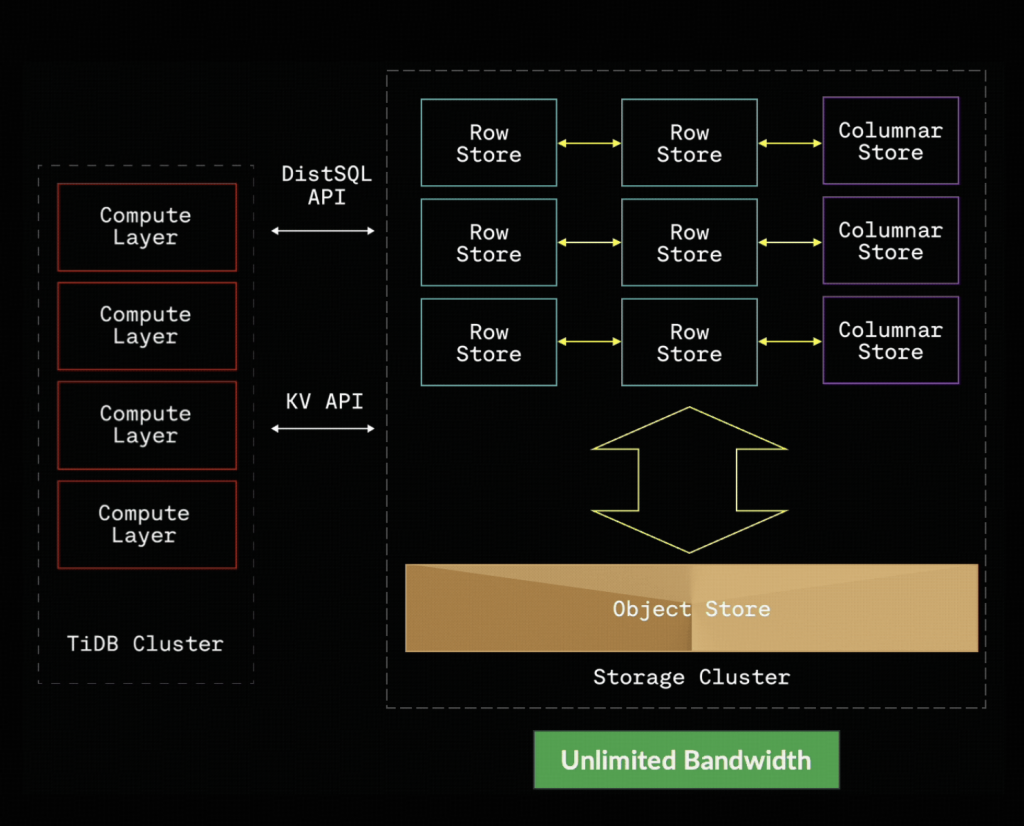
図2:TiDB Xがコンピュートとストレージを分離し、独立してスケールできる仕組み
今後の展望
今後のブログ投稿では、TiDB Xのクラウド管理レイヤーについてさらに深く掘り下げます。このレイヤーは、仮想クラスタのオーケストレーション、ワークロード対応オートスケーリング、マルチテナンシー、共有リソースプールを担当するシステムです。このレイヤーがあることで、TiDB Xは従来のようにユーザーがプロビジョニングして運用するデータベースではなく、現実の需要に応じて常に適応するクラウドサービスのように振る舞います。
また、チームが今日TiDB Xをどのように体験できるかを明確にすることも重要です。TiDB XはTiDB Cloudのコアエンジンであり、オブジェクトストレージベースのアーキテクチャとワークロード対応スケーリングにより、最初から真のサーバーレス弾力性を提供します。ほとんどのユーザーにとって、TiDB Cloud EssentialはTiDB Xを始めるための基本かつ推奨される方法であり、MySQL互換性、エンタープライズ級の信頼性、利用量ベースの課金を提供しつつ、インフラ管理、容量計画、スケーリングの判断を行う必要がありません。
TiDB X自体は独立した製品でもデプロイの選択肢でもありません。TiDB Xは、運用の簡素化、総所有コストの低減、モダンなワークロードにおける長期的スケーラビリティのサポートを可能にする基盤アーキテクチャを提供します。TiDB Cloudが進化するにつれ、TiDB Xはこれらの能力を提供する共通のアーキテクチャ的基盤としてますます重要になります。一方で、TiDB Cloudはチームが迅速に構築し、効率的に運用し、自信を持ってスケールできる最もアクセスしやすい方法であり続けます。
このブログ投稿は、TiDB Xに関するより広範なシリーズの始まりと考えてください — その起源、仕組み、チームが今日どのように活用できるか、そしてTiDB Cloudの未来にどのように影響するかについてです。
このアーキテクチャが実際にどのように機能するか気になりますか?
Manus 1.5がTiDB Xを活用し、AIエージェントが大規模にフルスタックアプリケーションを生成、分岐、進化させる仕組みをご覧ください — 本番環境での事例です。
参照:How Manus 1.5 Uses TiDB X to Let Agents Ship Full-Stack Apps at Scale
Related Resources

Conference
May 19, 2026
TiDB SCaiLE Europe 2026: Why Engineers Building Agentic AI Should Be in Stockholm on 4 June

Conference
May 12, 2026
TiDB SCaiLE Europe 2026: Speaker Lineup and Session Preview

Product
May 11, 2026
From Preview to Production: TiDB Cloud Dedicated on Microsoft Azure is Now Generally Available
TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。