

※このブログは2025年11月07日に公開された英語ブログ「Supercharging Real-Time Applications with TiDB and DragonflyDB」の拙訳です。
データ集約型のアプリケーションには、スケーラビリティ、低レイテンシ、そしてレジリエンスが求められます。しかし、従来のデータベースは、トランザクションの一貫性と高速なインメモリキャッシングの両方を大規模に処理に課題を抱えています。そこで、TiDBとDragonflyDBの組み合わせが真価を発揮します。
- TiDB:大規模なスケーラビリティと複合的なワークロード処理のために設計された、分散型でMySQL互換のデータベースです。
- DragonflyDB:Redis互換のモダンなインメモリデータストアで、Redisよりも遥かに優れた効率性でミリ秒未満のキャッシングとキューイングのパフォーマンスを提供します。
このチュートリアルでは、TiDB + Dragonflyスタックのセットアップ手順を説明し、両者がどのように補完し合うかを示し、リアルタイムなリーダーボードシステムの実践的なハンズオン例を構築します。
TiDBは、分散SQLデータベースとしてのスケールと一貫性を提供し、DragonflyDBは超高速なRedis互換キャッシングを提供します。両者が連携することで、リーダーボード、決済、フィードのようなリアルタイムのユースケースを強化します。
TiDBをエンジンとして、DragonflyDBをターボチャージャーとして考えてみてください。
なぜTiDBとDragonflyDBなのか?
TiDB (MySQLと同様) とDragonflyDBは、どちらも設計上マルチスレッドであり、これはデータ集約型のワークロードにとって非常に重要です。
TiDBのアーキテクチャは、並列実行のためにクエリとトランザクションを複数のノードとスレッドに分散します。
- TiDBの強み:水平スケーラビリティ、強い一貫性、複合ワークロード処理を備えます。
一方、DragonflyDBは、デフォルトでシングルスレッドであるRedisとは異なり、マルチコアCPUを最大限に活用できます。これにより、DragonflyDBは同じハードウェアで遥かに高いスループットを処理できます。
- DragonflyDBの強み:超高速なキャッシュ、Redisをそのまま置き換え可能、マルチスレッドによるスケーラビリティ。また、DragonflyDBはマルチノードクラスタリングソリューションであるDragonfly Swarmにより、水平スケーラビリティも備えています。
両者が連携することで、TiDBが永続的な真実のソースとしての役割を果たし、DragonflyDBが読み取り、キュー、一時的なデータ取得を高速化します。
DragonflyDB:そのまま置き換え可能なRedis代替
DragonflyDBは、100% Redis互換です。Redisからの移行は、通常、アプリケーションコード内のエンドポイントを変更するだけで済み、書き換えは必要ありません。例として、次のようになります。
# Before: using Redis
r = redis.Redis(host="redis-host", port=6379)
# After: using Dragonfly
r = redis.Redis(host="dragonfly-host", port=6379)これだけです。あなたのRedisコマンドはそのまま動作しますが、著しく向上したパフォーマンスと効率で実行されます。
次に、TiDBとDragonflyDBをDockerで一緒に実行する方法をご紹介します。
ステップ1. Colimaによる設定:Colima + Docker CLIのインストール
brew install colima docker docker-compose
colima start --cpu 4 --memory 8 --disk 20
docker context use colimaステップ2. TiDBを実行する
TiDBクラスタをまだお持ちでない場合は、TiDB Cloud Starterが最も簡単な方法です。
Dockerを使ってローカルで実行することも可能です。
docker run -d --name tidb -p 4000:4000 pingcap/tidb:latestステップ3. DragonflyDBを実行する
DragonflyDBはDocker上でも簡単に実行できます。
docker run -d --name dragonfly -p 6379:6379 docker.dragonflydb.io/dragonflydb/dragonflyこれで、ポート6379でRedis互換のキャッシュが利用可能になりました。
この時点で、TiDBとDragonflyの両方がColima内で実行されているはずです。確認してみましょう。
docker ps
次に、TiDBとDragonflyDBの両方に接続可能かを確認します。
mysql -h 127.0.0.1 -P 4000 -uroot -e "SELECT VERSION();"
redis-cli -h 127.0.0.1 -p 6379 PING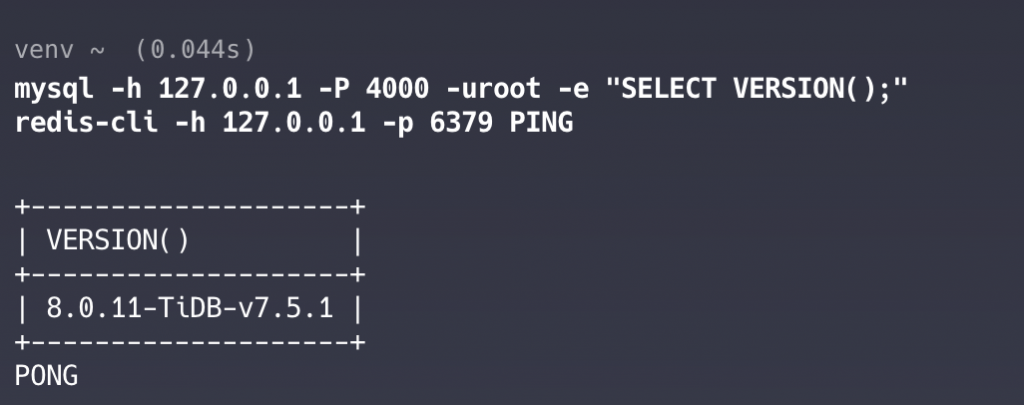
ステップ4. TiDBでスキーマを作成する
それでは、TiDB内に永続的なリーダーボードテーブルを作成しましょう。
CREATE DATABASE game;
USE game;
CREATE TABLE leaderboard (
user_id BIGINT PRIMARY KEY,
username VARCHAR(50),
score INT,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);ステップ5. Pythonによる読み通しリーダーボードの構築 (例)
仮想環境 (PEP 668 に準拠) をセットアップする必要があります。macOSやLinuxでは、Pythonライブラリをグローバルにインストールしないでください。代わりに、以下のようにします。
python3 -m venv venv
source venv/bin/activateシェルプロンプトに (venv) と表示されます。次に、依存関係にあるライブラリをインストール
pip install mysql-connector-python redisPythonデモコード (Read-Through Cache)
ここに、デモの核となる部分、すなわちPythonでのリードスルーキャッシュパターンを示します。
これをleaderboard_demo.pyとして保存してください。
# leaderboard_demo.py
import mysql.connector
import redis
from datetime import datetime, timedelta
# --- Connections ---
db = mysql.connector.connect(
host="127.0.0.1", port=4000, user="root", password="", database="game"
)
cursor = db.cursor(dictionary=True) # dict rows for convenience
r = redis.Redis(host="127.0.0.1", port=6379)
CACHE_TTL_SECONDS = 300 # 5m; tune for your app
def _lb_key(period: str | None = None) -> str:
# Examples: leaderboard:alltime, leaderboard:2025-09
if period in (None, "alltime"):
return "leaderboard:alltime"
return f"leaderboard:{period}"
def add_score(user_id: int, username: str, score: int):
# Write-through: TiDB first (source of truth)
cursor.execute(
"INSERT INTO leaderboard (user_id, username, score) VALUES (%s,%s,%s) "
"ON DUPLICATE KEY UPDATE username=VALUES(username), score=VALUES(score)",
(user_id, username, score),
)
db.commit()
# Then update Dragonfly cache(s). For simplicity we update all-time only here.
r.zadd(_lb_key("alltime"), {username: score})
r.expire(_lb_key("alltime"), CACHE_TTL_SECONDS)
def get_top_players(n: int = 10, period: str | None = "alltime"):
"""
Read-through: try Dragonfly; on miss, query TiDB, rehydrate Dragonfly, return data.
period:
- "alltime" (default)
- "YYYY-MM" for monthly boards (e.g., "2025-09")
"""
key = _lb_key(period)
results = r.zrevrange(key, 0, n - 1, withscores=True)
if results: # cache hit
return results
# --- Cache miss: rebuild from TiDB ---
if period in (None, "alltime"):
sql = (
"SELECT username, score FROM leaderboard "
"ORDER BY score DESC LIMIT %s"
)
params = (n,)
else:
# Monthly board using updated_at; adjust to your business rule
start = datetime.strptime(period, "%Y-%m")
end = (start.replace(day=28) + timedelta(days=4)).replace(day=1)
sql = (
"SELECT username, score FROM leaderboard "
"WHERE updated_at >= %s AND updated_at < %s "
"ORDER BY score DESC LIMIT %s"
)
params = (start, end, n)
cursor.execute(sql, params)
rows = cursor.fetchall()
# Rehydrate Dragonfly (pipeline for speed)
pipe = r.pipeline()
pipe.delete(key)
for row in rows:
pipe.zadd(key, {row["username"]: int(row["score"])})
pipe.expire(key, CACHE_TTL_SECONDS)
pipe.execute()
# Return in the same shape as ZREVRANGE ... WITHSCORES
return [(row["username"].encode("utf-8"), float(row["score"])) for row in rows]
# --- demo ---
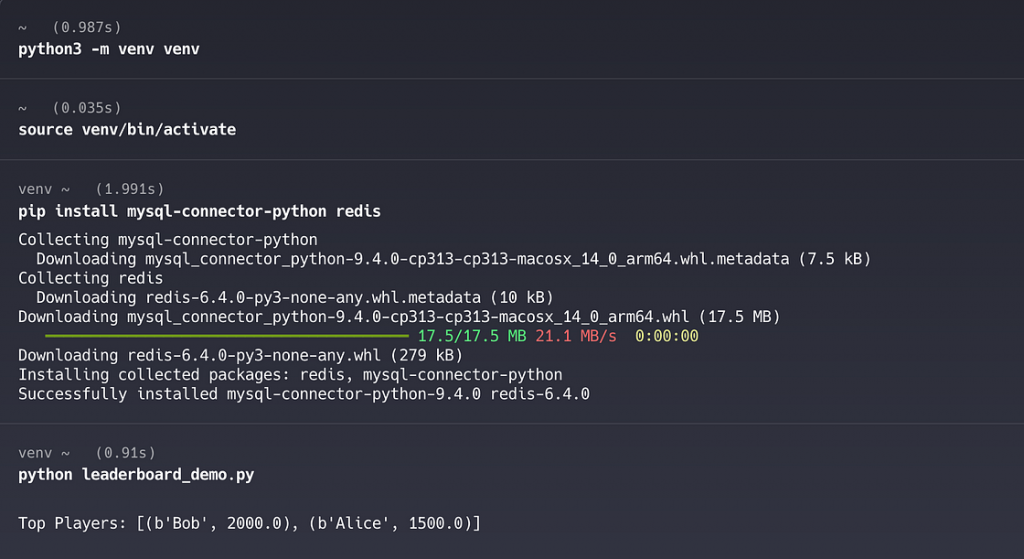
if __name__ == "__main__":
add_score(1, "Alice", 1500)
add_score(2, "Bob", 2000)
print("Top Players (all-time):", get_top_players())- get_top_players() はリードスルーキャッシュを実装しています。これはZREVRANGEコマンドを呼び出し、リストが空の場合 (キーがない、または期限切れの場合) にTiDBにクエリを実行し、ZADDでDragonflyDBにデータを再投入し、短いTTLを設定して結果を返します。
- 重要な点:これは、TiDBが書き込みパスと読み取りパスの両方に関与していることを示しつつ、頻繁な読み取りをDragonflyDBからミリ秒未満に抑えることを可能にします。
月間リーダーボード (期間ベースのクエリ)
updated_atカラムを使用して、月ごとのリーダーボードを取得するには、period=”YYYY-MM”を使います。例:
python -c 'from leaderboard_demo import get_top_players; print(get_top_players(10, period="2025-09"))'この関数は月単位で計算し、キャッシュミスが発生した場合にキャッシュを再構築します。
ステップ6. キャッシュミスと再投入のテスト
次に、キャッシュキーを削除してクリーンな状態から開始します。
redis-cli -h 127.0.0.1 -p 6379 DEL leaderboard:2025-09
redis-cli -h 127.0.0.1 -p 6379 CONFIG RESETSTAT初回読み込みはキャッシュミスし、TiDBから読み込む (更新日時月単位ウィンドウでフィルタリング)
python -c 'from leaderboard_demo import get_top_players; print(get_top_players(10, period="2025-09"))'ステータスを確認 (ミスを予想)
redis-cli -h 127.0.0.1 -p 6379 INFO stats | egrep "keyspace_hits|keyspace_misses"2番目の読み込みはキャッシュヒット
python -c 'from leaderboard_demo import get_top_players; print(get_top_players(10, period="2025-09"))'再度ステータスを確認します (hitが増加するはずです)
redis-cli -h 127.0.0.1 -p 6379 INFO stats | egrep "keyspace_hits|keyspace_misses"月別キーの内容を確認します
redis-cli -h 127.0.0.1 -p 6379 ZREVRANGE leaderboard:2025-09 0 9 WITHSCORES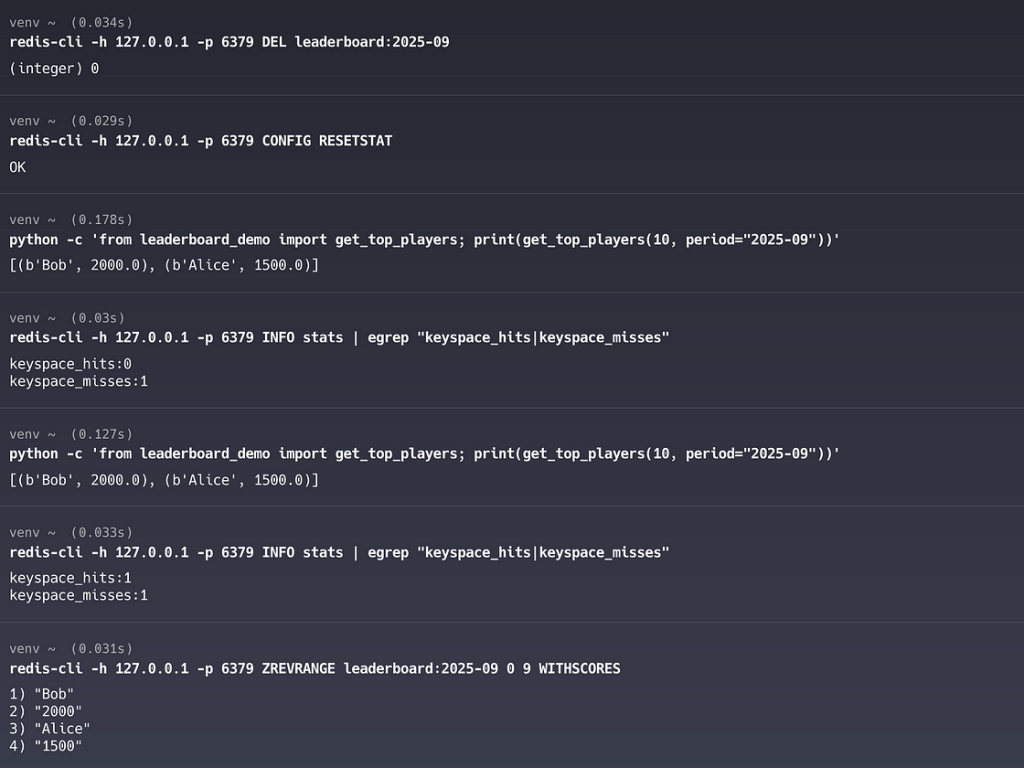
注意点
- TTLと鮮度:ワークロードごとにCACHE_TTL_SECONDSを調整し、同時に起きるキャッシュミスによるアクセスを避けるためにジッター (±20%のばらつき) を加えます。
- キャッシュ切れ制御:軽量なロック (SETNX / SET lock:key token NX EX 10) を使用して、有効期限切れ時に一つのプロセスのみが再構築するようにします。
- インデックス:月次リーダーボードを頻繁にクエリする場合、TiDBにINDEX(updated_at) を追加します。
まとめ
TiDBの分散型マルチスレッドアーキテクチャと、Redisをそのまま置き換え可能なDragonflyDB、およびマルチスレッドのキャッシングエンジンを組み合わせることで、両方の利点を得ることができます。
- TiDBによる、強力な耐久性、MySQL互換性、そしてスケーラブルな分析。
- DragonflyDBによる、超高速なキャッシュ、キュー、リーダーボードを、Redisコードを書き換えることなく実現。
このアーキテクチャは、スピードと信頼性の両方が等しく重要となるゲーム、フィンテック、アドテック、ソーシャルアプリに完全に適合します。
妥協せずにスケールする必要があるアプリケーションを構築しているなら、TiDBとDragonflyDBを組み合わせてみてください。それは、あなたのデータベースにロケット燃料を与えるようなものです。
さらに多くの無料の実践的なチュートリアルについては、TiDB Labsにアクセスして確認できます。
Related Resources

Conference
May 19, 2026
TiDB SCaiLE Europe 2026: Why Engineers Building Agentic AI Should Be in Stockholm on 4 June

Conference
May 12, 2026
TiDB SCaiLE Europe 2026: Speaker Lineup and Session Preview

Product
May 11, 2026
From Preview to Production: TiDB Cloud Dedicated on Microsoft Azure is Now Generally Available
TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。