

※このブログは2026年4月9日に公開された英語ブログ「S3 is the New Network: Rethinking Data Architecture for AI Agents」の拙訳です。
編集者注:この記事はもともと『The New Stack』に掲載されたもので、許可を得て転載しています。原文はこちらでご覧いただけます。
重要なポイント
- Amazon S3の耐久性とグローバルな可用性により、データとコンピュートを同じ場所に配置する必要がなくなります。
- 分離されたストレージにより、エフェメラルなクラスタ、イベント駆動ワークフロー、自動ティアリングが可能になります。
- TiDB Xは共有バックエンドとしてS3を使用し、独立したスケーリングと高速なリカバリを実現しています。
- オブジェクトストレージファーストのアーキテクチャは、AIエージェントの弾力的かつオンデマンドな要件に適合します。
数十年にわたり、データベース設計者は「ストレージはコンピュートの近くに配置されなければならない」という前提のもとで分散データベースを構築してきました。
データがネットワーク上を移動する距離が長くなるほど遅延の可能性が高まる、というのが従来の考え方です。そのため、ローカルRAID (ディスクの冗長構成)、NAS (ネットワーク接続型ストレージ)、クラスタファイルシステムなどが用いられ、データをコンピュートの近くに配置することで、迅速かつ容易にアクセスできるようにしてきました。
しかし分散システムにおいては、データストア全体をコンピュートの近くに維持することは、スケーリングを遅くし、煩雑にし、コストも高くします。ノードやクラスタを複製するたびに、そのノードに紐づくデータも同時に複製しなければならないためです。
理想的な状況ではありませんでしたが、最近まで現実的な代替手段は存在しませんでした。データベースはスケールする必要があり、チームはサービスレベルアグリーメント (SLA) を満たさなければなりませんでした。さらに、広域ネットワークは大規模な高性能データベースを支えるほど十分に信頼性が高いものではありませんでした。そのためデータベース設計者は、調整、整合性、およびレプリケーションロジックといった課題の解決に多くの労力を費やしてきました。
しかし、もし状況が違っていたとしたらどうでしょうか。ネットワークやデータの配置場所、あるいはデータをA地点からB地点へどのように移動させるかを一切気にする必要がなかったとしたら、その場合データベースはどのように設計されるでしょうか。
この興味深い問いを投げかけたのが、Amazon S3、Google Cloud Storage、Microsoft Azure Blob Storageといったクラウドオブジェクトストレージサービスの登場です。
クラウドオブジェクトストレージとは
クラウドオブジェクトストレージの構造はこれ以上ないほどシンプルです。本質的には、API経由でキー / バリューの対応付けによってアクセスされる、巨大なデータの集合体です。
その無制限に近いストレージ容量と「どこからでもアクセス可能」という特性が、これらを革命的な存在にしています。画像、ログ、学習データなど、あらゆる種類のデータを数十億件規模で保持でき、さらに重要なのは、それらのレコードすべてを、世界中のどこにあるコンピュートからでも、どれほど負荷がかかっても利用可能にできる点です。
Amazon S3は極めて高い信頼性を持っています。AWSはS3を11ナイン(99.999999999%) のデータ耐久性と99.99%の可用性を前提として設計しており、データはAmazonのリージョン施設全体にわたって自動的に複製されます。これにより、物理ディスクの管理やレプリケーションを意識することなく、データの安全性と高可用性が確保されます。
さらにAmazon S3は、シームレスにスケールします。固定されたボリュームという概念はなく、キャパシティプランニングも不要です。事実上無制限のデータを保存でき、性能は単一サーバーのボトルネックではなく並列アクセスによってスケールします。これらの保証により、アーキテクトは低レイヤーのストレージ障害、容量制約、整合性に関するエッジケースの検討から解放されます。
要するに、クラウドオブジェクトストレージは、高い耐久性を持ち、常時稼働し、強整合性を備えた単一の信頼できるデータソースを提供します。ローカルストレージほど高速ではありませんが、その必要はありません。Amazon S3のようなサービスは純粋な速度では劣るものの、その分、信頼性と運用の容易さで大きく優れています。シャーディング、セグメンテーション、ソフトウェア定義ネットワークといった複雑性を気にする代わりに、データベースはデータが妥当な時間内に確実に取得できるという前提のもとで、シンプルにデータを参照できるようになります。
つまり、次世代の分散データベースにおいては、クラウドオブジェクトストレージが実質的にネットワークそのものとして機能することになります。
オブジェクトストレージを中心にした新しいアーキテクチャパターン
クラウドオブジェクトストレージの上に構築することで、これまで実現が難しかったいくつかのアーキテクチャパターンが可能になります。
- エフェメラルコンピュートクラスタ:オブジェクトストレージをコンピュートから分離することで、特定のジョブのために一時的なクラスタを簡単に起動し、処理後に破棄することが容易になります。これは、タスク達成のために一時的なデータベースを構築することが多いAIエージェントにとって特に有用です。データ複製のオーバーヘッドなしに、必要なときにコンピュートを自由に起動できます。
- イベント駆動ワークフロー:Amazon S3に新しいオブジェクトが到着したことをトリガーとして、AWS Lambda関数の実行、トレーニングジョブの開始、あるいは下流のコンシューマへの通知などを行うことができます。このようなワークフローは、データが高度にレプリケーションされたシステムでは実現が困難ですが、単一のストレージに集約されている場合は容易に実装できます。
- AIおよび機械学習パイプライン:多くの分散機械学習ワークフローは、中央集約されたオブジェクトストレージデータストアの恩恵を受けます。学習データセット、特徴量ストア、モデルのチェックポイント、実験ログなどは、一般的にすべてオブジェクトストレージ上に保存されます。TensorFlow、PyTorch、Amazon SageMakerといったフレームワークは、オブジェクトストレージから直接データをストリーミングする設計になっています。
- 大規模ストレージのティアリング:データベースは通常、データを高頻度で利用される「ホットデータ」と、ほとんどアクセスされない「コールドデータ」に分類します。ホットデータは高速なフラッシュストレージに保存され、コールドデータはコスト効率の高いハードディスクドライブに保存されます。従来、このホット・コールドストレージのプロビジョニングには手動対応や慎重なキャパシティプランニングが必要でした。しかしクラウドオブジェクトストレージを利用することで、データベースはアクセス需要に応じて、オブジェクトストアと高速キャッシュ間でデータを自動的に移動させるティアリングを実現できます。Amazon S3のようなオブジェクトストアは高い可用性と事実上無限の容量を備えているため、事前の計画そのものが不要になります。
例:TiDB X
それでは、これらの機能が実際の設計にどのように反映されるかを見てみましょう。PingCAPは、クラウドオブジェクトストレージを基盤としてTiDB Xを構築しています。これは、人気オープンソース分散SQLデータベースTiDBの最新バージョンです。
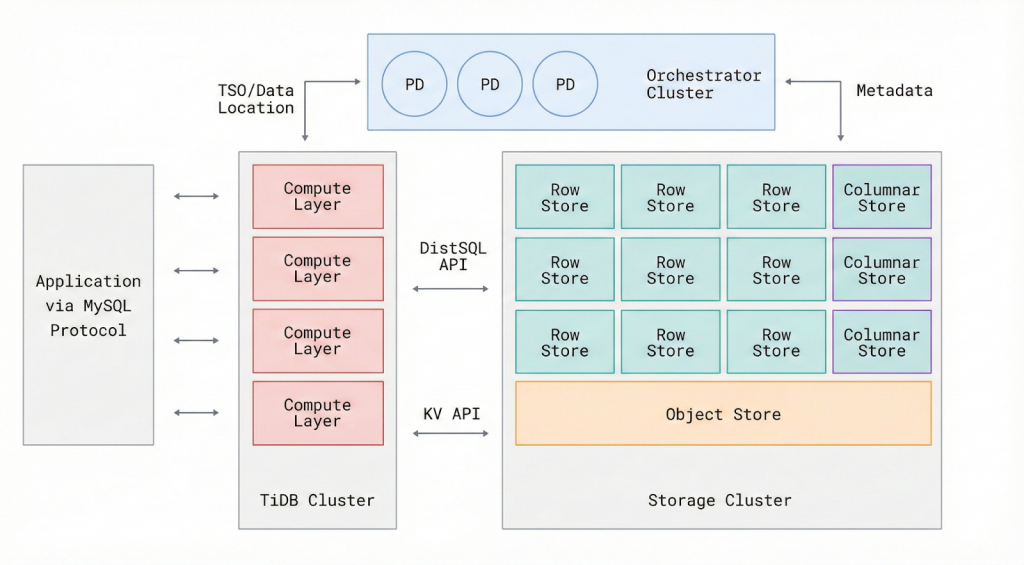
図1:オブジェクトストレージを組み込んだTiDB Xのアーキテクチャ
上図に示すように、TiDB Xはコンピュートとストレージを完全に分離し、Amazon S3を共有バックエンドとして利用しています。コンピュートノードは独立してスケールアップおよびスケールダウンが可能です。高速なローカルキャッシュとRaftにより、ホットデータに対して低レイテンシかつ一貫性のあるアクセスが保証されます。データストア全体をコンピュートの近くに保持するのではなく、TiDB Xは最もアクティブなデータのみをコンピュート近くに配置します。またTiDB Xは、クエリパターン、レイテンシ目標、データ特性を継続的に監視し、それに応じてシステム構成を動的に再編成します。
そのオブジェクトストレージベースのアーキテクチャにより、バックアップおよびリカバリ処理が大幅に簡素化されます。プライマリデータの永続化にAmazon S3を利用することで、従来のバックアップ運用に伴うオーバーヘッドが削減され、バックアップ処理の完了時間も大幅に短縮されます。
またこの設計はノード障害の影響も軽減します。ローカルの状態は主に耐久性のあるレプリケート済みストレージへのキャッシュとして機能するため、障害が発生したインスタンスは、必要な状態をオブジェクトストレージから直接取得することで迅速に置き換えられ、処理を再開できます。運用の観点から見ると、クラウドオブジェクトストレージの活用により、TiDB Xは高い適応性と優れたコスト効率を同時に実現しています。オートスケーラーは、単なる事前設定されたインフラの閾値に反応するのではなく、クエリパターン、レイテンシ目標、データタイプといったコンテキストに基づくシグナルをもとに動作します。これによりシステムは、リアルタイムにリソース構成を再編成し、異なるワークロードやタスクに柔軟に対応することが可能になります。
要するに、Amazon S3のような高性能なクラウドオブジェクトデータストアの上に構築することで、TiDB Xは、一貫性やスケールを犠牲にすることなく、エラスティシティ、パフォーマンス、シンプルさを同時に実現できるクラウドデータベースのあり方を示しています。
Amazon S3を共通基盤として活用する
大規模なリレーショナルデータストアをコンピュートリソースの近くに配置し続けることは、常にトレードオフを伴ってきました。それは、従来のネットワークの制約によって生じた問題に対する、コストのかかる解決策でした。
TiDBのようなアーキテクチャを見ると、Amazon S3のようなサービスが持つ圧倒的な性能とスケールによって、従来の回避策は不要になりつつあることが分かります。これらは従来のアーキテクチャを徐々に時代遅れなものにしつつあります。さらに重要なのは、それ以上の変化をもたらしている点です。すなわち、ユーザーが人間ではなくAIエージェントである可能性が高い世界に適した、エフェメラルコンピュートのような新しい運用手法を実現していることです。
AIがビジネス組織やベストプラクティスを再構築するにつれて、データベースそのものの形も変化しています。その変化を可能にしている大きな要因が、Amazon S3のようなサービスです。データを場所に依存しないものとし、ユビキタスかつ容易にアクセス可能にすることで、クラウドオブジェクトストレージは、かつてデータベース設計を支えていた前提を覆しています。その結果として生まれるのは、より柔軟でレジリエントなデータベースです。運用がよりシンプルになり、ほぼ自動的にスケールできるようなシステムへと進化していきます。
TiDB Xは、クラウドオブジェクトストレージを前提としてゼロから設計されています。そのアーキテクチャの仕組みを詳しく確認するか、TiDB Cloudを無料で試して、その動作を実際に体験してみてください。
Related Resources

Conference
May 19, 2026
TiDB SCaiLE Europe 2026: Why Engineers Building Agentic AI Should Be in Stockholm on 4 June

Conference
May 12, 2026
TiDB SCaiLE Europe 2026: Speaker Lineup and Session Preview

Product
May 11, 2026
From Preview to Production: TiDB Cloud Dedicated on Microsoft Azure is Now Generally Available
TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。