
この記事は、Shawn MaがTiDB DevCon 2020で行った講演をもとに作成したものです。
TiDBは、ハイブリッドトランザクション/分析処理(HTAP)ワークロードに対応したオープンソースの分散型NewSQLデータベースです。TiDB 4.0は、2020年5月に一般提供が開始された真のHTAPデータベースです。
この記事では、まず、HTAPとは何なのかを説明し、次いでTiDBではHTAPアーキテクチャがどのようにフル活用されているのかを説明します。
HTAPとは
従来型データベースには2種類あります。オンライントランザクション処理(OLTP)データベースとオンライン分析処理(OLAP)データベースです。一方、HTAPデータベースは、両方のワークロードを同時に処理するハイブリッドデータベースです。
従来型データプラットフォームアーキテクチャ
一般的に言えば、OLTPデータベースは行ベースのストレージエンジンを利用しています。現在のデータを保存し、それをリアルタイムで更新します。高水準の同時実行処理と厳密な整合性を実現できます。各リクエストによって変更されるデータは、数行のみです。一方、OLAPデータベースは多くの場合、カラム型(列指向型)データベースです。OLAPデータベースは、ヒストリカルデータのバッチ処理を行います。つまり、同時実行性は高くありませんが、各リクエストは多数の行にタッチします。
以上説明したとおり、OLTPリクエストとOLAPリクエストの要件は異なるので、必要となるテクノロジーもそれぞれ異なります。こうした理由から、OLTPリクエストとOLAPリクエストは多くの場合、切り離されたデータベース内で処理されます。従来型のデータ処理システムは以下のようになります。
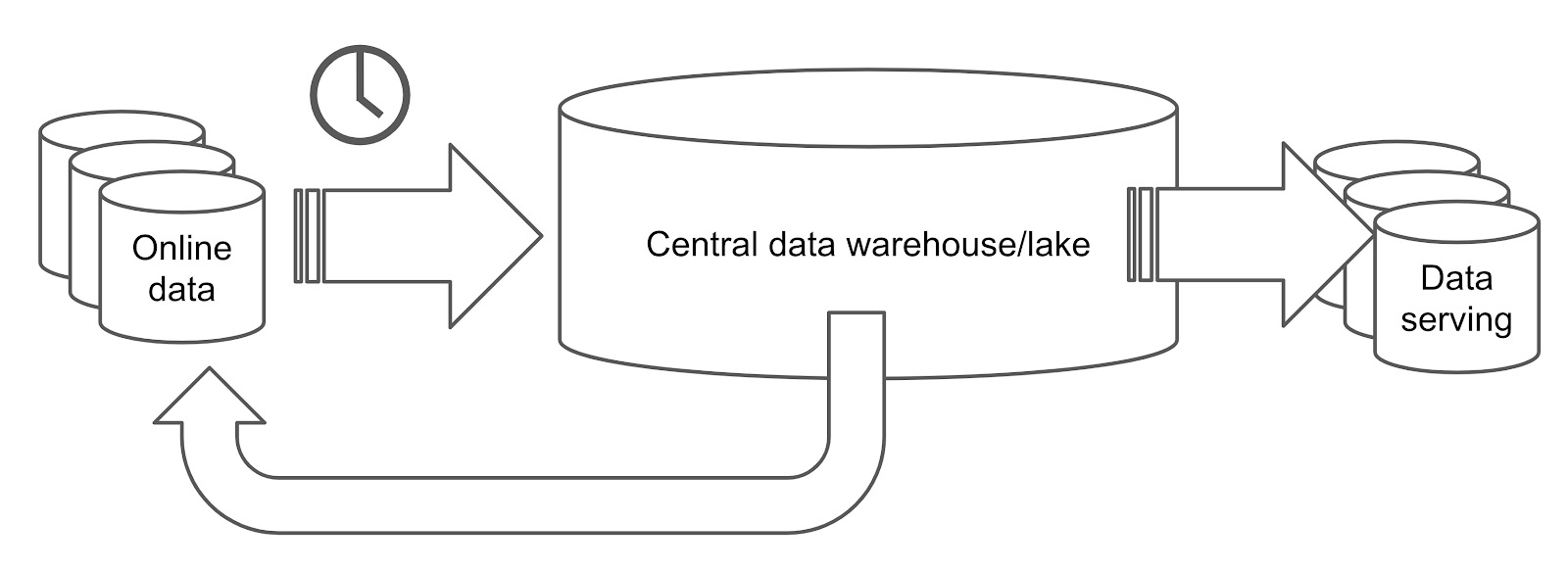
従来型データプラットフォーム
上図のアーキテクチャでは、オンラインデータはオンラインデータベースに保存され、そこでトランザクションワークロードが処理されます。データは、オンラインデータベースから一定の間隔(例えば1日1回)で抽出されます。その後、抽出されたデータは、リレーショナルデータウェアハウスやHadoopデータレイクなどの分析処理データベースに読み込まれます。読み込まれたデータは、データウェアハウスまたはデータレイクで処理され、レポートとしてエクスポートされた後、データ提供データベースに読み込まれるか、またはオンラインデータベースに送り返されます。
このプロセスは、処理に時間がかかり、しかも複雑です。データ処理工程が増えるほど、遅延が増加します。
なぜHTAPが重要なのか
では、データプラットフォームが上図のような複雑な構造になるのは致し方ないことなのでしょうか。もちろん、そんなことはありません。HTAPデータベースを利用すれば、システムを効率化し、リアルタイムパフォーマンスを実現できます。以下説明していきます。
HTAPデータベースとは、OLTPワークロードとOLAPワークロードの両方を処理するデータベースを言います。HTAPデータベースを利用すれば、トランザクションと分析をそれぞれ別のデータベースで実行する必要がなく、両方を1つのデータベースで実行することができます。HTAPデータベースは、行ストアとカラムストアを組み合わせることによって、両方の長所を備えており、単に2つのフォーマットを結びつけた以上の能力を発揮します。
ところで、そもそもなぜHTAPデータベースが必要なのでしょうか。古いデータプラットフォームは複雑で、動作が遅いかもしれませんが、それでも各アプリケーションを実行させることはできます。
HTAPが必要である理由は、トランザクションワークロードと分析ワークロード間の境界があいまいになってきているからです。
- OLAPのユースケースで、トランザクション処理が必要になってきています。レポートを作成するとき、場合によっては、同時実行性の高いショートクエリを実行し、ヒストリカルデータに対してはスモールレンジのクエリを実行しなければなりません。
- OLTPのユースケースで、分析処理が必要になってきています。トランザクションを実行するとき、場合によっては、大規模な分析を行う必要があります。オンライン動作を改善するため、オンラインデータベースにフィードバックを送ったり、アプリケーションデータに対してリアルタイム分析を行ったり、複数のアプリケーション間でクエリを実行したりする必要が生じる可能性もあります。
下図をご覧ください。一般的なセールスプラットフォームのデータベースでさえ、さまざまな動的要件に対応する必要があります。左の円はOLTP的なワークロードで、右の円はOLAP的なワークロードです。2つの円の共通部分は、OLTP機能とOLAP機能の両方、すなわちHTAP機能が必要となるワークロードです。それぞれのワークロードには、拡張性、粒度の細かいインデックス作成、カラム型ストレージ、リアルタイム更新、高水準の同時実行処理などのデータベース機能に対するさまざまな要件があります。

シンプルなセールスプラットフォームにでさえ、さまざまな要件がある
これらの要件を満たすためには、HTAPデータベースは行ストアとカラムストアの両方を備えている必要があります。しかし、両方のストアを一緒にするだけではうまく機能しません。両方のストアをオーガニックな統一体として統合する必要があります。つまり、行ストアとカラムストア間で自由なコミュニケーションを確立させることに加え、データのリアルタイム性と整合性も確保する必要があります。
TiDBのHTAP実装方法
当初、TiDBはOLTPデータベースとして設計されました。現在、TiDBの中でも最大級のものは、単一データベースとして何兆行ものデータを持っており、実稼働環境では1秒間に何千万件ものクエリを処理しています。しかし、意外にも、ユーザーは4.0よりも前のバージョンのTiDBを、うまく機能するデータハブまたはデータウェアハウスとしてすでにデプロイしていました。当時でも、TiDBはOLTPワークロードとOLAPワークロードの両方に対応していました。
では、TiDB 4.0になって何が新しくなったのでしょうか。端的に言うと、TiDB 4.0では、リアルタイムのカラム型ストレージエンジンであるTiFlashを導入することによってHTAPエクスペリエンスを改善しました。TiFlashは、キーと値の分散型トランザクションストアであるTiKVのカラム型拡張機能です。TiFlashは、TiKVからのデータをRaftコンセンサスアルゴリズムに従って非同期的に複製し、Raftインデックスとマルチバージョン同時実行制御(MVCC)を検証することによって、スナップショット分離レベルの整合性を保証します。
下図に示すとおり、TiKVとTiFlashを組み合わせると、TiDBのアーキテクチャは、行ストアとカラムストアが統合されたスケーラブルなものになります。

TiDB 4.0のHTAPアーキテクチャ
このアーキテクチャを以下に説明します。
- TiKVとTiFlashは、それぞれが別々のストレージノードを利用するため、完全な分離性が確保されています。
- カラムの複製内にあるデータは、リアルタイムであり、整合性を確保しています。
- TiKVとTiFlashの間に中間レイヤーが存在しないため、データの複製作業は高速かつシンプルなものになります。
- 行ストアインデックスとカラムストアのポイント取得、スモールレンジスキャン、大規模バッチスキャンがサポートされています。コストモデルを利用しているオプティマイザーは、実際のワークロードに基づいてカラムストアまたは行ストアを選択します。
スケーラブルかつリアルタイムの更新
TiDBのHTAPアーキテクチャの行ストアとカラムストアは、リアルタイムでスケーリングしたり更新したりすることができます。
TiKVと同様に、TiFlashもマルチRaftグループの複製メカニズムを実装しています。唯一の違いは、TiFlashは、行ストアからカラムストアにデータを複製する点です。データを複製または保存する基本単位をRegionと呼んでいます。
また、データ複製プロセスには中間レイヤーは存在しません。他のデータ複製プロセスでは、データはKafka等のメッセージキューシステムなどの分散パイプラインを通過しなくてはならないため、遅延が増加します。しかし、TiDBの場合は、TiKVとTiFlash間の複製はピアツーピアで行われます。中間レイヤーがないため、データの複製はリアルタイムで行われます。
HTAPアーキテクチャでは、複製の拡張性とストレージの拡張性のバランスが維持されます。また、複製メカニズムとシャーディングメカニズムは、以前のOLTPアーキテクチャと同じです。したがって、これまでどおり、HTAPアーキテクチャにスケジューリングポリシーを適用することができるとともに、クラスタも水平方向にスケールアウトまたはスケールインさせることができます。さらに、カラムストアと行ストアをそれぞれ別々にスケーリングし、アプリケーションニーズを満たすことができます。
以下のシングルコマンドを実行するだけで、TiFlash複製を有効化できます。
# To create 2 columnar replicas for orders table
mysql> ALTER TABLE orders SET TIFLASH REPLICA 2;
リアルタイムかつ整合性のある読み取りが可能な非同期複製
TiFlashでは、データ複製は非同期的です。この設計には2つの利点があります。
- カラムストアの複製作業は、トランザクション処理をブロックしない。
- カラムの複製がダウンしても、行ストアは機能する。
複製が非同期的とはいえ、Raftコンセンサスアルゴリズムが導入されているため、アプリケーションが読み取るデータは常に最新のものになります。

Raftラーナーメカニズム
アプリケーションがTiFlashのラーナー複製からデータを読み取ると、アプリケーションは読み取り検証をTiKVのLeader複製に送信し、その後、複製の進捗状況に関する情報を受信します。複製作業が完了しなかった場合は、最新のデータはラーナーレプリカにレプリケート(レプリケーション)されない、ラーナー複製は最新のデータを取得するまで待機します。システムの使用率がピークに達していなければ、全体の待機時間はわずか数10ミリ秒から数100ミリ秒です。
オプティマイザーによるインテリジェントな選択
また、留意しておくべき点として、カラムストアと行ストアは2つの独立したシステムではなく、1つのオーガニックな統一体であるということが挙げられます。では、これら2つのストアはどのように連携をとっているのでしょうか。その秘密は、当社のオプティマイザーです。
オプティマイザーは、クエリ実行プランを選択するとき、カラムストアを特別なインデックスとして扱います。オプティマイザーは統計とコストベース最適化(CBO)に基づき、すべての行ストアインデックスと専用のカラムストアインデックスの中から最速のインデックスを選択します。このような方法で、カラムストアと行ストアの両方が考慮されます。オプティマイザーがユーザーの代わりに最適な選択を行ってくれるので、ユーザーは複雑なクエリに使用するストレージエンジンを選択する必要がありません。
ただし、ユーザーがカラムストアと行ストアを完全に分離したい場合は、2つのストレージエンジンのうち1つをクエリが使用するよう、手作業で指定することができます。以下の図表は、ClickHouseが行ったオンタイムベンチマークテストの結果であり、単一ワイドテーブルでのTiFlash、MariaDB、Spark、Greenplumそれぞれのパフォーマンスが示されています。データベースは4種類ですが、同じ10種類のクエリの実行時間は、それぞれのデータベースによって異なります。ご覧のとおり、このアーキテクチャでは、TiFlash上のTiDBの方が他のデータベースよりもパフォーマンスが優れていることがわかります。

TiFlash、MariaDB、Spark、Greenplumのベンチマークテスト
Apache SparkがTiSparkと連携
TiDBのHTAPアーキテクチャは、TiSparkの助けを借りることで、Apache Sparkとシームレスに連携することができます。TiSparkは、TiKVやTiFlash上でSparkを実行するために構築された薄い計算レイヤーであり、AIコンピューティングやデータサイエンス向けツールボックスの提供やビジネスインテリジェンス(BI)との統合などの複雑なOLAPクエリに応答するためのものです。TiDBはSparkエコシステムに接続されているため、これらの複雑なシナリオで利用することができます。
TiSparkをHadoopデータレイクと組み合わせて利用することができます。これにより、分散型コンピューティングによって複雑な高負荷クエリを処理するための非常に優れた手段としてTiDBを利用できます。TiSparkとGreenplumについてTPC-Hベンチマークテストを行ったところ、TiSpark + TiFlashとGreenplumの勝負は引き分けといったところでした。以下に示すとおり、Greenplumの方が速いケースもあれば、TiSpark + TiFlashの方が速いケースもありました。

TiSpark+TiFlashとGreenplumのベンチマークテスト
HTAPシナリオでTiDBを活用
前述したとおり、HTAPシナリオでは、ユーザーはTiDBを利用してアーキテクチャをシンプル化することができます。その結果、メンテナンスの複雑さが低減し、各アプリケーションにリアルタイムデータが提供され、ビジネスアジリティが改善されます。
リアルタイムデータウェアハウジング
下図に示してあるのは、一般的なTiDBのユースであるリアルタイムデータウェアハウジングです。TiDBは常時更新をサポートしているため、他のOLTPデータベースのデータとの同期を簡単にとることができます。このアーキテクチャでは、TiDBが複数のアプリケーションからデータを収集し、そのデータをリアルタイムで集約します。

TiDBをリアルタイムデータウェアハウスとして利用
TiDBは、データを収集した後、レポートとリアルタイムチャートの作成や、当然ながらAIへのデータ供給などのリアルタイムクエリを作成することができます。
トランザクション処理と分析処理のワンストップデータベース
TiDBをHTAPシナリオで活用するもう1つの方法は、トランザクション処理と分析処理両方に対応できるワンストップデータベースを構築することです。ユーザーはこれまで、MySQLをオンラインデータベースとして利用し、データをMySQLから分析用データベースやHadoopに翌日で複製してきました。この場合、MySQLがオンラインアプリケーションに関する処理を行い、分析用データベースやHadoopに接続されたBIツールがデータ分析を実行します。

OLTPとOLAPのためのワンストップデータベース
しかし、TiDBクラスタのみでも、このシナリオに対応できます。オンラインアプリケーションをTiDBの行ストアに接続し、BIサーバーをカラムストアに接続します。このアーキテクチャによって、アーキテクチャの複雑さを緩和できることに加え、パフォーマンス全体を引き上げることができます。
TiDBと既存データウェアハウスの統合
しかし、利用可能なデータウェアハウジングシステムをすでに保有していて、そのシステムを完全に捨てて、すべてをTiDBに移行させるわけにもいかない、と考える人もいるかもしれません。
実際、すでにHadoopやデータウェアハウスを利用している場合、以前のユースケースがシステムに適合しない可能性があります。しかし、TiDBは柔軟性と拡張性に優れているため、下図のように、ユーザーはTiDBを既存のデータウェアハウジングシステムに統合することができます。

TiDBとデータウェアハウスの統合
各アプリケーションは、データをTiDBに集約します。この場合のTiDBは、リアルタイムクエリや外部へのデータ提供のためのリアルタイムレイヤーとして機能します。このリアルタイムレイヤーを通じ、TiSparkはデータをオフラインのHadoopレイヤーに送信することができます。Hadoopレイヤーでは、Hadoopがデータのモデル化とクリーニングを行い、その後そのデータをTiDBにエクスポートします。これにより、TiDBはデータをより効率的に処理することができます。
通常、Hadoopは高速のリアルタイムクエリに対応していないので、そのAPIを外部サービスに直接公開することはできません。TiDBでは、既存システムの能力を高めることによって、リアルタイムでのデータ処理が実現されています。
結論
カラム型ストレージエンジンを導入したTiDB 4.0 HTAPは、そのGAリリースからわずか数か月で、20件以上の実稼働ユースケースで採用されました。ユーザーは、リアルタイムレポーティング、不正検知、CRM、データマート、リアルタイムキャンペーンモニタリングを構築するため、TiDBを活用しています。
TiDBを体験するには、無料サインアップよりTiDB Serverlessをお試しください。日本語ドキュメントのTiDBクイックスタートガイド、または無料オンライントレーニングのご利用をお勧めします。ご不明な点などございましたら、お問い合わせフォームよりご連絡ください。 また、GitHubにて問題を報告することもできます。



TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。