
※このブログは2021年11月12日に公開された英語ブログ「How to Troubleshoot RocksDB Write Stalls in TiKV」の拙訳です。
著者:Mike Barlow(PingCAPソリューションアーキテクト)
編集者:Jose Espinoza, Tina Yang, Tom Dewan
オープンソースの分散NewSQLデータベースであるTiDBでは、いくつかの理由で書き込みパフォーマンスが低下する可能性があります。このトラブルシューティングガイドでは、RocksDBに内在している書き込み性能低下に関連したTiDBの書き込みパフォーマンスの低下について説明します。RocksDBはオープンソースで成熟した高性能のキーバリューストアです。フラッシュドライブや高速ディスクドライブなどの高速で低遅延のストレージ向けに最適化されています。
また、この問題をTiKVで解決する方法についても説明します。TiKVは、RocksDBをストレージエンジンとして使用しており、拡張性が高く、待ち時間が短く、使いやすいキーバリューデータベースです。
RocksDBはデータをすぐにフラッシュして圧縮できない場合、「ストール」と呼ばれる機能を使用して、エンジンに入るデータの書き込みを遅くしようとします。書き込みストールが発生すると、すべての書き込みの一時停止や書き込み処理数の制限が発生します。
GitHubからの引用
RocksDBには、フラッシュまたはコンパクションが書き込み速度に追いつかない場合に書き込みを遅くするための全体的な仕組みがあります。このような仕組みが無い場合、ユーザーがハードウェアの処理能力を超えて書き込みを続けると、データベースは次のようになります。
この仕組みは、書き込み処理をデータベースが処理できる速度まで遅くすることです。ただし、データベースが一時的な書き込みバーストに敏感すぎたり、ハードウェアが処理できるものを過小評価したりすることがあるため、予期しない速度低下やクエリタイムアウトが発生する可能性があります。
- 容量の増幅を招きます。これにより、ディスク容量が不足する可能性があります。
- 読み取りが増幅し、読み取りパフォーマンスを大幅に低下させます。
TiKVには、RocksDBの2つのインスタンス(RaftDBとKVDB)があります。RaftDBには列ファミリーが1つしかありません。KVDBには3つの列ファミリー(デフォルト、書き込み、およびロック)があります。
書き込みストールのユーザー影響
TiKVはRocksDBに依存しているため、アプリケーションまたはプロセスが大量の書き込みを行うと、TiDBの応答時間(レイテンシー)が大幅に低下する可能性があります。この待ち時間は、特定のテーブルへの書き込みだけでなく、すべての書き込みに影響を与えるようです。
RocksDBの書き込みストールが原因であり、追加の調査が必要かどうかを特定するのに役立つGrafanaグラフがいくつかあります。
下記のセクションにある次のGrafanaチャートを使用できます。
[Cluster name] / TiKV-Details / [RocksDB - raft | RocksDB -kv]
以下のグラフでは、書き込みストールが11:30頃に大幅に急増したことがわかります。11:30以前と12:15以降は書き込みストールは発生していません。正常なシステムでは、書き込みストールは発生しません。
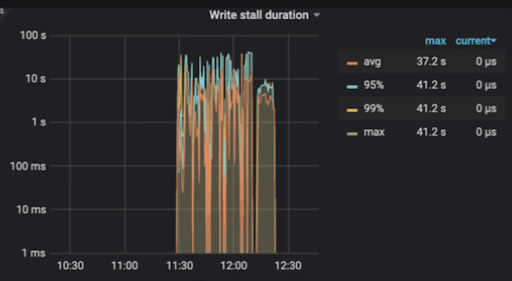
書き込みストールの期間
これらの知識があれば、書き込みストールをより深く掘り下げることができます。
RocksDB下記の指標について数が大きくなった場合に書き込みストールを発生させます。
これらの指標は、以下の”Write Stall Reason”の図に直接関連付けされています。
以下の各メトリクスは、”slowdown”または”stop”に関連付けられています。”slowdown”は、RocksDBがメトリクスに固有の書き込み数を制限していることを示します。“stop”は、RocksDBがメトリクスに関連する書き込みを停止したことを示します。
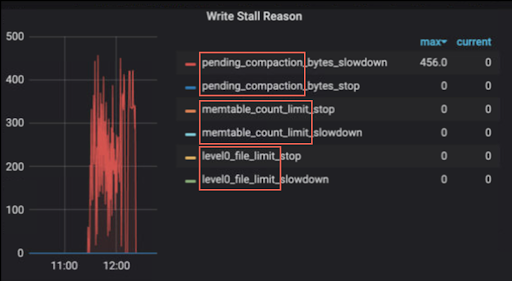
書き込みストールの原因
RocksDBが書き込みストールを引き起こす理由
大量のmemtable
大量のmemtableが作成されると、メモリ不足(OOM)例外が発生する可能性が高くなります。したがって、RocksDBは作成されるmemtableの数とサイズを制限します。
各列ファミリー(デフォルト、書き込み、ロック、およびRaft)について、RocksDBは最初にディスク上の先行書き込みログ(WAL)にレコードを書き込みます。(これは、書き込みストールでは重要ではありません)次に、データをmemtable(書き込みバッファー)に挿入します。memtableが write-buffer-size の制限に達すると、memtableは読み取り専用になり、新しい書き込み操作を受け取るために新しいmemtableが作成されます。CF(列ファミリー)書き込みのデフォルトの write-buffer-size 制限は128MBで、ロックの場合は32MBです。作成できるmemtableには最大数があります。デフォルトは5です。これは max-write-buffer-number によって設定されます。制限に達すると、RocksDBはそれ以上のmemtableを作成せず、memtableの数が max-write-buffer-number の制限を下回るまで、すべての新しい書き込み操作を停止します。
ディスクへのmemtableのフラッシュとSSTファイルの圧縮を特に担当するバックグラウンドタスク(ジョブ)があります。デフォルトでは、max-background-jobs は8またはCPUコア-1のいずれか小さい方に設定されています。
memtableは大量に作成される可能性があります。TiDBには、列ファミリー(デフォルト、書き込み、ロック、Raft)ごとに少なくとも1つのmemtableがあることに注意してください。前述のように、memtableが write-buffer-size lの制限に達すると、読み取り専用になり、SSTファイルとしてディスクにフラッシュするようにフラグが立てられます。memtableをディスクにフラッシュするタスクの数には制限があり、max-background-flushes の制限で確認できます。デフォルトは2またはmax-background-jobs / 4のいずれか大きい方です。
補足:
TiKV v4.0.9より前では、max-background-flushes は使用できず、バックグラウンドフラッシュタスクの数は max-background-jobs / 4に設定されています。
memtableの数が列ファミリーの max-write-buffer-number に達すると、RocksDBはそのインスタンス上のその列ファミリーのすべての書き込みを停止します。
設定パラメータ:
[rocksdb|raftdb].[defaultcf|writecf|lockcf].write-buffer-sizeデフォルトは128MBです。このパラメータを大きくすると、OOMの可能性も高まります。[rocksdb|raftdb].[defaultcf|writecf|lockcf]max-write-buffer-numberデフォルトは5です。このパラメーターを増やすと、OOMの可能性も高まります。[rocksdb|raftdb].max-background-jobsTiDB 5.0の場合、デフォルトは8です。[rocksdb|raftdb].max-background-flushesデフォルト値は2またはmax_background_jobs/ 4の大きい方に設定されています。
Grafanaのグラフ:
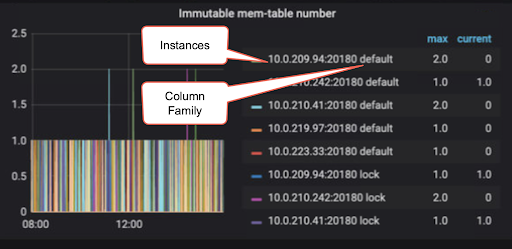
不変なmemtableの数
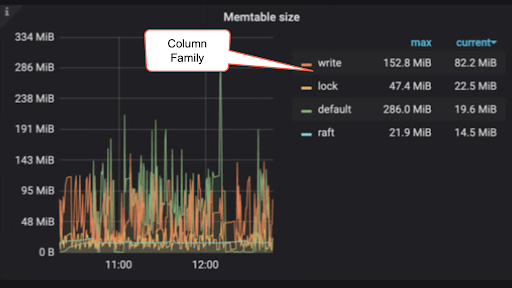
memtableのサイズ
大量のレベル0 SSTファイル
レベル0のSSTファイルのサイズと数は、クエリの読み取りパフォーマンスに直接影響を与える可能性があります。したがって、RocksDBはレベル0のSSTファイルの数を制限しようとします。
一般に、SSTファイルは列ファミリー(デフォルト、書き込み、ロック、Raft)ごとに存在します。RocksDBのレベル0 SSTファイルは、他のレベルとは異なります。memtableは、レベル0のSSTファイルとしてディスクにフラッシュされます。レベル0のSSTファイル内のデータは、memtableとして生成順に配置され、同じリージョンのデータを異なるファイルに分散させることができます。また、同じキーを持つデータは、複数のSSTファイルに存在する可能性があります。したがって、読み取りが発生すると、レベル0の各SSTファイルを順番に読み取る必要があります。レベル0のSSTファイルが多いほど、クエリ読み取りのパフォーマンスが低下する可能性が高くなります。レベル0のファイルが大量に作成された場合、書き込みストールが引き起こされます。
補足:
レベル0およびレベル1のSSTファイルが圧縮されないのは正常です。これは、SSTファイルを圧縮する他のレベルとは対照的です。
デフォルトでは、レベル0のSSTファイルの数が20に達すると、RocksDBはデータベース全体の書き込みを遅くします。レベル0のSSTファイルの数が36に達すると、RocksDBはデータベース全体の書き込みを停止します。
列ファミリーのレベル0 SSTファイルの数が4に達すると、圧縮がトリガーされます。ただし、圧縮が行われない場合があります。異なる列ファミリーでの並列圧縮は同時に発生する可能性があります。
設定パラメータ:
[rocksdb|raftdb].[defaultcf|writecf|lockcf].level0-file-num-compaction-triggerデフォルトは4です。[rocksdb|raftdb].[defaultcf|writecf|lockcf].level0-slowdown-writes-triggerデフォルトは20です。[rocksdb|raftdb].[defaultcf|writecf|lockcf].level0-stop-writes-triggerデフォルトは36です。
Grafanaのグラフ:
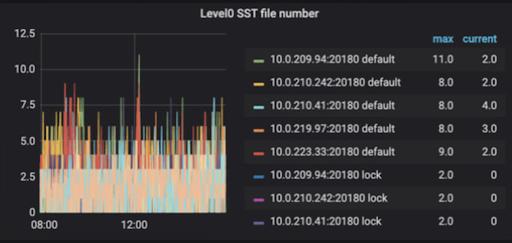
レベル0のSSTファイルの数
大量の保留中の圧縮バイト数
Log-Structured Merge-Tree(LSM)は、複数のレベルで構成されています。各レベルには、0個以上のSSTファイルを含めることができます。レベル0は「上位レベル」として識別され、各増分レベル(レベル1、レベル2など)は下位レベルとして識別されます。(下図参照)
レベル0は下位レベルとは異なる方法で処理されるため、レベル0は保留中の圧縮バイトには適用されませんが、レベルのより完全な図を提供するために下の図に含まれています。
RocksDBは、レベル1以下にレベル圧縮を使用します。既定では、レベル1は、書き込みおよび既定の列ファミリー(CF)に対して512MBのターゲットサイズの圧縮を持ち、ロックCFの既定のサイズは128MBです。それぞれの下位レベルには、前の上位レベルの10倍のターゲットサイズがあります。たとえば、レベル1のターゲットサイズが512MBの場合、レベル2のターゲットサイズは5GB、レベル3のターゲットサイズは50GBなどです。
レベルが目標サイズを超えると、超過分は保留中の圧縮バイトと呼ばれます。レベル1以下の保留中の圧縮バイトが集計され、保留中の圧縮バイトの合計が計算されます。保留中の圧縮バイトの合計がsoft-pending-compaction-bytes-limitまたはhard-pending-compaction-bytes-limitを超えると、書き込みストールが引き起こされます。
たとえば次の図では、保留中の圧縮の合計は72GBです。soft-pending-compaction-bytes-limitが64GB (デフォルト) に設定されている場合、書き込みストールが発生します。
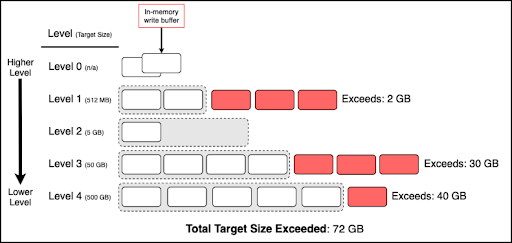
保留中の圧縮バイト数の合計
設定パラメータ:
[rocksdb|raftdb].soft-pending-compaction-bytes-limitデフォルトは64GBです。[rocksdb|raftdb].hard-pending-compaction-bytes-limitデフォルトは256GBです。Grafanaのグラフ:
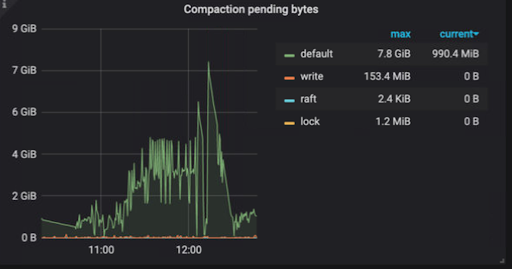
保留中の圧縮バイト数
考えられる根本原因
RocksDBの書き込みストールの発生にはいくつかの理由があります。簡単にまとめると、最も一般的な原因は次の通りです。
- ホットスポット
- アプリケーションのワークロードに変化があり、さらに多くの書き込みが発生
- インフラストラクチャストレージのIOPsが適切でない
- memtableがいっぱいになる、レベル0のSSTファイルが多すぎる、または保留中の圧縮バイトが多すぎるという連鎖効果
- 十分な圧縮スレッドが無い
まとめ
非常に高い書き込みパフォーマンスが必要なシステムでは、RocksDBの書き込みストールが問題になる可能性があります。特定のシナリオの下でのみ、書き込み、読み取り、および容量構成のバランスを取ることができます。パフォーマンスの問題を解決し、TiDBを最大限に活用するには、RocksDBのさまざまな側面と、チューニングに使用できる設定オプションを理解することが重要です。



TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。