
※このブログは2026年2月17日に公開された英語ブログ「The Hidden Cost of Database Over-Provisioning」の拙訳です。
2025 Kubernetes Cost Benchmark Reportによると、Kubernetesクラスタ全体の平均CPU利用率は約10パーセントです。多くのチームが疑問を抱いています:なぜデータベースのCPU利用率はこれほど低いのでしょうか?
その答えは不十分なエンジニアリングではありません。それは構造的なものです。
最新のクラウドネイティブなデータベースのスケーリングモデルは、ピークに合わせたキャパシティプランニングを中心に構築されています。可用性を保つために、平均的な需要をはるかに上回るインフラストラクチャが確保されます。その結果、データベースのオーバープロビジョニングが常態化し、実際の使用状況とは乖離したままKubernetesのデータベースコストが上昇し続けます。
特にAIやイベントベースのシステムによって、ワークロードの負荷変動が激しくになるにつれて、プロビジョニングされたキャパシティと実際のワークロードの間のギャップは広がり続けています。
利用率のギャップ
ほとんどの本番環境では、プロビジョニングされたキャパシティはで高い位置に引かれた直線のように見えます。これは設計上、最悪のケースに対処するためのものです。
実際のワークロードの挙動は大きく異なります。急激に変動し、短時間スパイクし、そのほとんどの時間で確保された上限をはるかに下回っています。
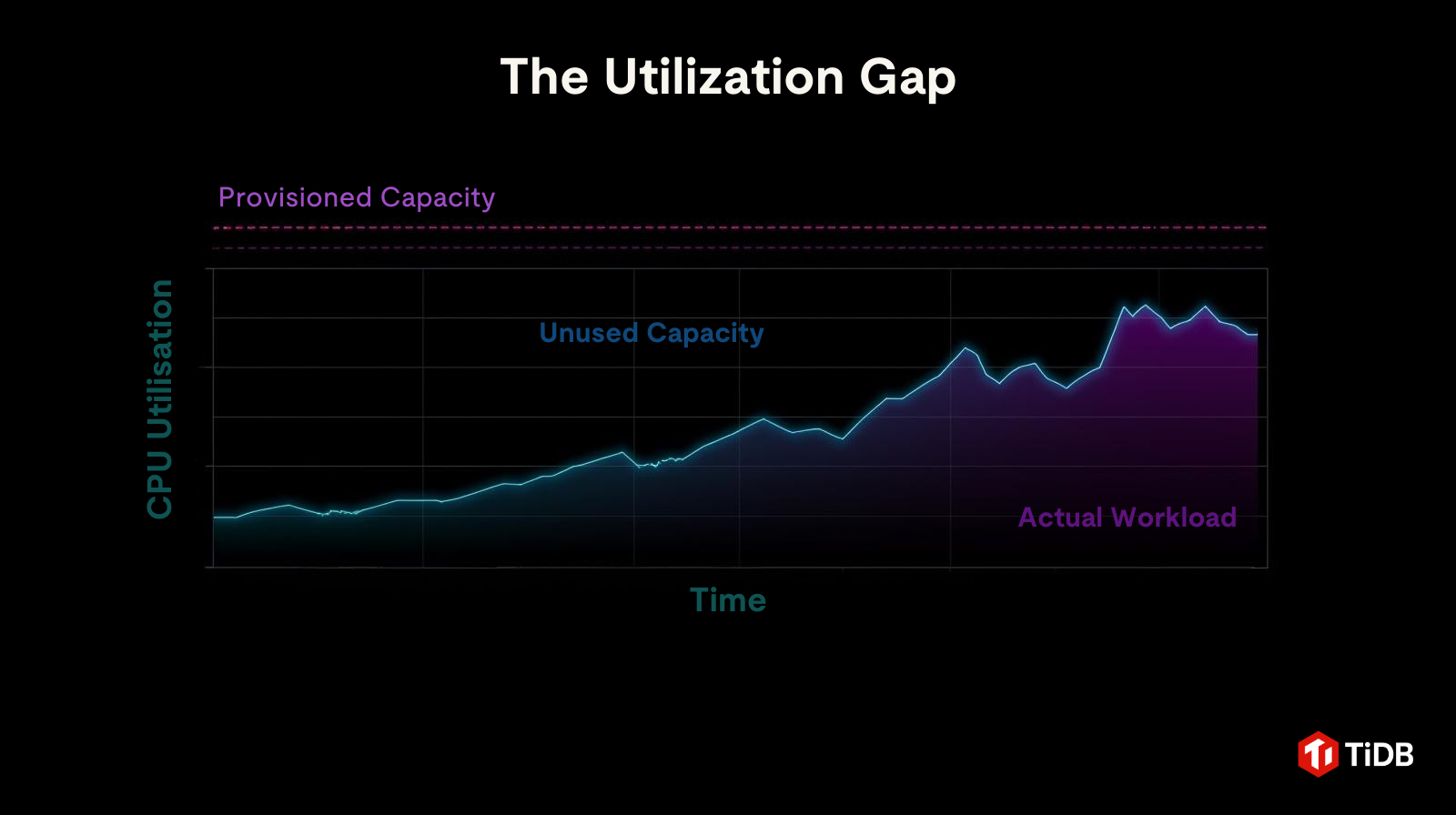
図1:データベースオーバープロビジョニングの利用率のギャップ
これら2本の線の間の余白は、持続的なアイドルコストを表しています。
このギャップは、成長するにつれて広がります。
シャーディングされたMySQLと保守的な容量プランニングのコスト
このモデルのコストは、マーケティングキャンペーンや製品発表などのイベントが計画された際により顕著になります。大幅なトラフィックの増加が予想される場合、事前に不足分のキャパシティをプロビジョニングする必要があります。実際には、これは以下のような作業を意味します。
- 新しいインスタンスの追加
- ノード間でのデータの再分布
- 需要が顕在化するかなり前に安全策のバッファを導入すること
シャーディングされたMySQLまたはPostgreSQL上に構築されたシステムでは、このプロセスは特に複雑になる可能性があります。リシャーディングは単なるインフラストラクチャの懸念事項ではありません。多くの場合、アプリケーションレベルの調整、慎重な手続き、そして重大な運用リスクを伴います。マネージドクラウドデータベースでは運用オーバーヘッドは削減されますが、依然として保守的な事前のキャパシティプランニングが必要です。
このため、チームは実際の使用量ではなく、予測に基づいてリソースの料金を支払うことになります。キャパシティは早期に確保され、利用率は低いままであり、最終的に需要が期待通りになるかどうかにかかわらず、金銭的なコストが発生します。
なぜクラウドネイティブシステムではデータベースの利用率がこれほど低いのか?
クラウドネイティブシステムにおけるデータベース利用率の低さは、単なる非効率と誤解されがちです。実際には、それはAIパイプライン、バックグラウンドジョブ、イベント駆動型のワークロードにおけるバーストトラフィックを予測することの難しさを反映しています。
アプリケーション内に組み込まれたAIサポートエージェントを例に挙げてみましょう。
午後2時に、クエリの急増が発生します。各リクエストは以下の処理を実行します:
- ベクトル類似性検索
- 複数のデータセットにわたるコンテキスト検索
- 並行トランザクション更新
15分間、データベースは何千もの短時間の並行操作を処理します。
キャパシティプランニング重視のモデルでは、そのピークを処理するためにインフラストラクチャをプロビジョニングする必要があります。しかし、その日の残りの23時間45分間、需要はピークの数分の一にとどまります。
バッファは恒久的なものになります。このような処理の急増は一時的なものです。
変動性が高まるにつれて、キャパシティプランニングは最適化からリスク回避へとシフトします。より大きなバッファがより長い期間確保されます。ピーク利用率と平均利用率の間のギャップは広がり続けています。
需要が予測を上回る場合
慎重な予測であっても、不確実性を排除することはできません。
通常の10倍のトラフィックを生成すると予想されたキャンペーンが、それをはるかに上回る可能性があります。予測を超えた場合、通常2つの選択肢しかありません。
- プレッシャーの下でリソースを追加し、コストと運用リスクを増大させる。
- データベースレイヤーを保護するために、アプリケーションのトラフィックを制限します。
これらの結果は、現場のやり方に問題があったからではありません。事前にキャパシティを決定する必要があるシステムの根本的な限界を反映しています。この経験は保守的な行動を助長します。将来の計画には、より大きなバッファ、より早期のプロビジョニング、およびピーク利用率と平均利用率の差をさらに拡大することなどが挙げられます。
クラウドネイティブデータベースのスケーリングとスケールインのリスク
トラフィックが通常のレベルに戻っても、効率を回復させることは決して簡単ではありません。
なぜスケールインは難しいのか
データベースクラスタを縮小することは、拡張することよりも本質的にリスクが高くなります。
- データの整合性のリスク:正確性を維持し、損失を防ぐために、データをサーバー間で慎重に移行する必要があります。
- 段階的な廃止:サーバーを単に停止することはできません。システムを不安定にすることなく、対象サーバーへの接続を行わないようにし、廃止する必要があります。
- 運用上の遅れ:クリーンアップの取り組みは、次の成長イニシアチブに遅れをとることがよくあります。
このリスクがあるため、チームは慎重に動く傾向があります。オーバープロビジョニングされたキャパシティは、元のスパイクが収まった後も長期間維持されることがよくあります。クリーンアップが完了する頃には、すでに新しい成長イニシアチブが進行しています。
これらのリスクは、予測可能なパターンを作り出します。
- キャパシティは急速に増加する。
- 利用率はゆっくりと低下する。
- クリーンアップは需要に追いつかない。
時間が経つにつれて、余剰容量は常態化し、事実上恒久的なものになります。
目に見えにくいコスト:インセンティブの不一致
インフラストラクチャの支出以外にも、過剰なプロビジョニングによって、より捉えにくい課題が生じます。
システムの規模が過大だと、非効率性がすぐに問題になることは稀です。クエリ速度が遅く、アクセスパターンが最適ではない場合でも、十分な余裕があるため、パフォーマンスは許容可能です。
エンジニアが積極的に最適化を行っても、インフラストラクチャのフットプリントは変わらないことがよくあります。クラスタが自動的に縮小することはないため、コストは低下しません。
時間が経つにつれて、エンジニアリングの努力をおこなっても財務的な結果にはつながりにくくなります。
キャパシティプランニングモデルにおけるインセンティブの分岐
| アクション | 従来のデータベースの結果 | TiDB Cloudの結果 |
| 遅いクエリを最適化する | キャパシティは事前確保されているため、コストは変わりません。 | 消費されるリクエストユニットを減らして、請求額を直接削減します。 |
| トラフィックが50%低下 | プロビジョニングされたサーバーのコストは固定のままです。 | 使用量に応じてコストが自動的にスケールダウンされます。 |
| 冗長なバックグラウンドジョブを排除する | パフォーマンスは向上しますが、インフラストラクチャの支出は変わりません。 | ワークロードの削減が、測定可能なリクエストユニットの節約につながります。 |
パフォーマンスの向上が支出の削減につながらない場合、最適化は知的な満足感は得られますが、財務的には目に見えないものになります
構造的な経済問題
これらのパターンは、個人の決定やチームの行動によって引き起こされるものではありません。キャパシティが前払いされ、パフォーマンスの向上が支出を削減せず、トラフィックの変動が柔軟性ではなくリスクをもたらすというコストモデルから生じています。
データベースが主に事前に確保されたキャパシティによって価格設定されている限り、オーバープロビジョニングは依然として最も安全な選択肢です。慎重さが合理的になり、実験には暗黙のコストが伴います。
キャパシティ管理から持続可能なイノベーションへ
過剰なプロビジョニングは、しばしば最善の選択肢であるかのように見えます。しかし、その長期的な影響はインフラストラクチャの支出をはるかに超えています。それはチームの計画方法、実験のスピード、そして不確実性に対する許容範囲を形成します。余剰キャパシティがデフォルトになると、慎重さが好奇心に取って代わり、イノベーションは目立たないながらも着実に停滞します。
最新のワークロードは、不変ではなく、より変動しやすくなっています。チームに未来を予測することを要求するデータベースは、現在のチームが試みられることをますます制約しています。本当の問題は、もはや「どのようにキャパシティをより効率的にプロビジョニングするか」ではなく、「そもそもキャパシティプランニングが主要な制御メカニズムであり続けるべきかどうか」です。
データベースは、組織に安定性と野心のどちらかを選択させるべきではありません。オーバープロビジョニングは運用の失敗ではありません。それは、データベースの経済性がもはや現代のワークロードに適合していないというシグナルなのです。
従量課金制のデータベース価格設定とキャパシティ予約モデル
従量課金制のデータベース価格設定は、クラウドネイティブなインフラストラクチャの経済構造を変えます。予約されたキャパシティに対して支払う代わりに、チームはデータベースによって実行された実際のワークロードに対して支払います。このモデルは、従来のKubernetesデータベースコストの背後にあるコストの前提に直接挑戦するものです。
TiDB Cloudは、ワークロードとコストの経済的関係を変えることで、この課題に取り組んでいます。ワークロードが減少するとコンピュートリソースをスケールダウンできるため、低稼働期間中のコストを削減できます。アイドル状態のキャパシティは、もはや恒久的な費用ではありません。
重要なのは、この弾力性が単なる事後対応のスケーリングではないということです。利用率のしきい値を待ってからキャパシティを追加する方法では、依然として遅延とリスクが生じます。TiDB Cloudは、変動性をファーストクラスの挙動として吸収するように設計されており、価格設定とアーキテクチャが、キャパシティ固定モデルの上に重ねられるのではなく、その前提に合わせられています。
さらに、TiDB Cloudはリクエストユニットを通じて使用量を測定します。これはデータベースによって実行された実際の負荷を反映したものです。クエリの実行は測定可能なリソースを消費し、効率の向上はリクエストユニット消費量を直接削減します。最適化は、コスト指標に即座に反映されます。
1日約20ドルから始められる本番環境
過剰プロビジョニングから脱却するために、アーキテクチャを大幅に見直す必要はありません。
TiDB Cloud Essentialを使用すると、多くの小規模な本番ワークロードを1日約20ドルで運用できます。
この料金には以下が含まれます。
- マルチゾーン保護が組み込まれた、99.99%の可用性
- デフォルトで有効な30日間のポイントインタイムリカバリ
- 最大10万リクエストユニットまでの使用量に基づいた自動スケーリング
- 転送中および保存時の暗号化
これは限定的な試用版ではありません。実際のトラフィックの変動を処理するように設計された、フルマネージドの本番グレードのデータベースです。
最悪のシナリオに備えてプロビジョニングする代わりに、実際のワークロードをデプロイし、実際の使用量に合わせてコストをスケールさせることができます。需要が減少すれば支出も減少します。エンジニアは最適化を通じて消費量をさらに削減できます。同時に、システムはトラフィックの急増に対応するために自動的にスケールします。
まずは1つの本番ワークロードから始めてください。運用上の影響を測定し、コストを比較してください。その上で、固定キャパシティの経済性が依然として貴社の環境に適しているかどうかを判断してください。
TiDB Cloudにサインアップして、オーバープロビジョニングなしで次の本番ワークロードを運用しましょう。



TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。