

※このブログは2025年10月16日に公開された英語ブログ 「Change Data Capture (CDC): A Complete Guide for Modern Data Teams」 の拙訳です。
データ管理やリアルタイム分析の領域において、Change Data Capture (CDC) は欠かすことのできないツールとなっています。
CDCは、ソースデータベース内の変更を監視・記録するためのソフトウェア機能であり、そこから記録した変更をターゲットデータベースに適用することができます。
これらの変更には、新規レコード、更新、既存データの削除といった操作が含まれます。CDCは、ソースデータベースで新たな変更が発生するたびにデータを継続的に移動・処理し、ターゲットデータベースが常に同期された状態を維持できるようにします。
このブログ記事では、CDCの基本について解説します。また、主要なメリットやパターンを紹介し、導入を始めるためのソリューションも提供します。.
Change Data Captureとは何か、そしてなぜ重要なのか
CDCは、データベースおよびデータ統合の分野で利用される技術です。バッチ型のETLプロセスとは異なり、データベース内で行われた変更を取得・追跡するよう設計されています。CDCは、ソースデータベース内で発生する個々の変更 (例:INSERT、UPDATE、DELETEさらにはDDLによる変更まで) を識別して取り込み、システムがそれらの変更履歴を継続的に把握できるようにします。
CDCは、データレプリケーション、データウェアハウス、リアルタイム分析など、変更を効率的かつ正確に検出し、複数のシステム間で伝播させることが重要となるシナリオで特に有用です。データベース全体やテーブル全体をスキャンして変更を検出するのではなく、CDCはソースデータベース内で更新されたデータや増分の変更をピンポイントで取得するため、ワークロードや処理のオーバーヘッドを削減できます。
Change Data Captureはどのように機能するのか:データベースログからリアルタイムデータストリーミングまで
このプロセスをイメージするために、CDCがソースデータベース内の変更を処理し、それらの変更をシームレスにターゲットデータベースへ適用していく様子を思い浮かべてみましょう。
以下は、CDCがどのように動作するかのシンプルな例です:
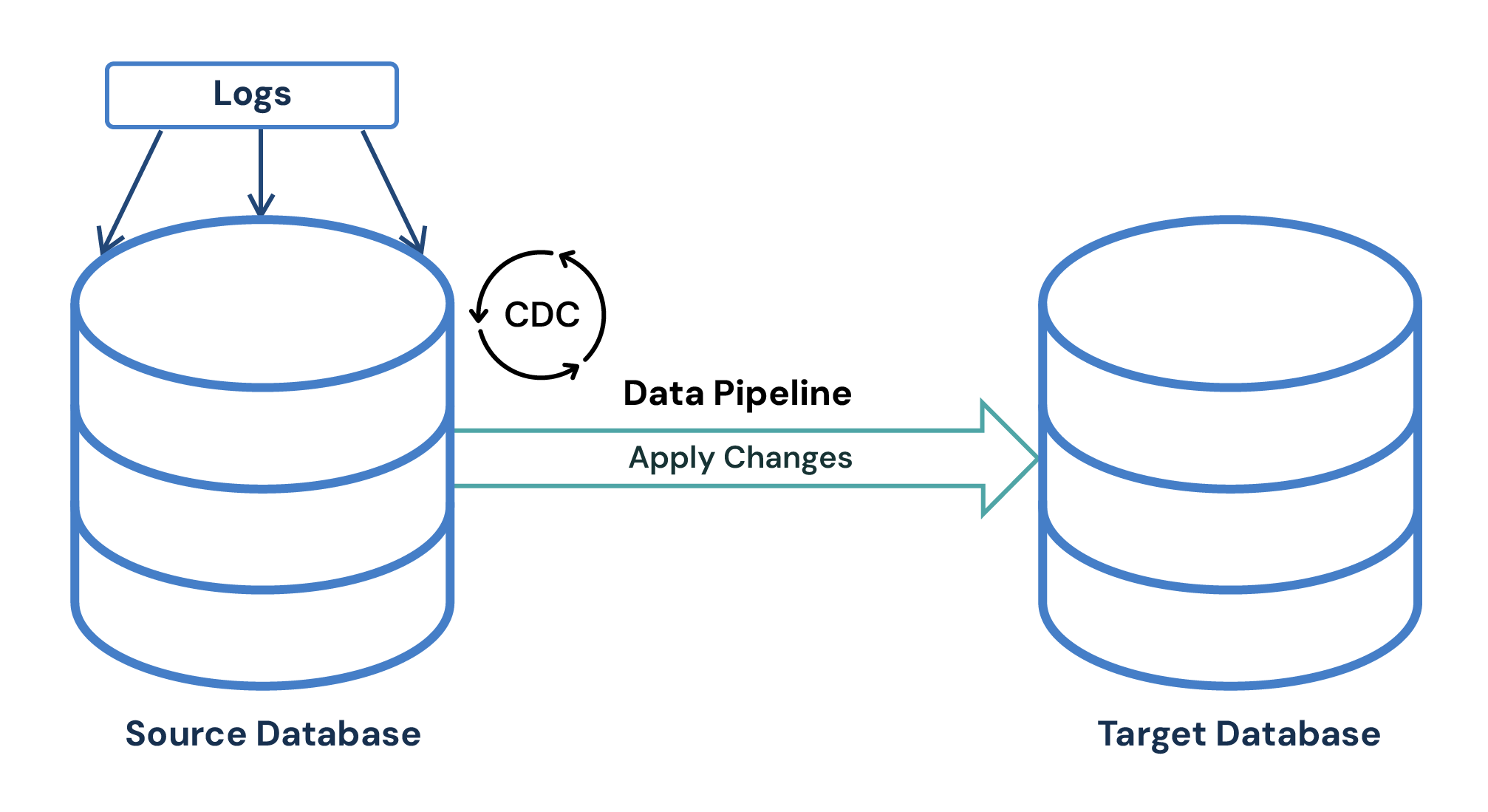
- ソースデータベースに変更が加えられる。
- CDCプロセスが、データベースシステムのログから発生順に生成された変更を取得・解析する。
- CDCプロセスが、取得した変更を順番どおりにターゲットデータベースへ適用する。
- ターゲットデータベースはソースデータベースと同期された状態になる。
注:これらのステップは、CDCレプリケーションが動作し続ける限り、継続的に繰り返されます。
なぜ企業にCDCが必要なのか:リアルタイムデータパイプラインとクラウドデータベース同期
CDCは、同種または異種のデータプラットフォーム間でデータ整合性を維持するうえで重要な役割を果たします。また、データ同期を容易にし、リアルタイム分析を可能にし、データウェアハウスの取り組みを支援し、アプリケーションが常に最新の情報へアクセスできるようにします。これらをすべて、ターゲット側のデータプラットフォームでデータを最新状態に保つための煩雑な手作業なしに実現できます。
CDCを利用する主なメリットはいくつかあります:
- リアルタイムデータ更新:CDCは変更が発生したタイミングでそれをキャプチャし、ターゲットシステムへ即座に伝播します。これにより、遅延のないリアルタイムデータへのアクセスが可能になります。リアルタイム情報が必要なアプリケーションにとって非常に重要です。
- レポーティング負荷のオフロード:リソース負荷の高いクエリをソースデータベースに直接実行する代わりに、CDCは変更をキャプチャして別のレポート用または分析用データベースへレプリケーションします。これにより、レポートツールや分析処理は最新データへアクセスしつつ、ソースデータベースのパフォーマンスや安定性に影響を与えません。
- 事業継続性の向上:CDCは、ディザスタリカバリ (DR) 戦略において重要な役割を果たします。プライマリシステムでデータ損失やシステム障害が発生した際に、迅速な復旧を可能にします。CDCは遠隔地にあるシステム間でのデータレプリケーションと同期を実現し、災害発生時でもデータのコピーが利用可能な状態を確保します。
- 負荷の低減: 初期同期後に変更されたデータのみを取得するため、ソースシステムへの負荷を軽減し、データ転送時のネットワーク帯域の利用を最適化します。
- データ同期の自動化:CDCは、異なるシステムやデータベース間でのシームレスなデータ同期を実現します。これにより、すべてのデータコピーが手動作業なしで最新状態に保たれます。
総合すると、Change Data Captureはデータ管理を大きく強化し、システム間の効率的なデータ統合を可能にし、組織が正確で最新の情報を扱えるようにします。その結果、より良い意思決定と業務効率の向上につながります。
Change Data Captureの手法:トリガー方式vs.ログベースレプリケーション
CDCを実装する方法としては、一般的に次の2つのアプローチがあります:
トリガー方式CDC (メリット&デメリット)
この方法では、ソーステーブルに対して行われる変更を取得するためにデータベーストリガーを使用します。指定したソーステーブルに対してINSERT、UPDATE、DELETE操作が実行されるたびに、トリガーが起動し、関連する変更がCDC用のテーブルまたはログに記録されます。しかし、トリガー方式のCDCはデータベースのパフォーマンスに影響を与える傾向があります。 各INSERT、UPDATE、DELETE行に対して複数の書き込み操作が必要となるため、追加のオーバーヘッドを生みます。
ログベースCDC:スケーラブルなCDCアーキテクチャ
この方法では、データベース管理システムが生成するトランザクションログ (またはredoログ) をCDCが利用します。パフォーマンスへの影響はごくわずかです。
これらのログには、データベースに対して行われたすべての変更が記録されています。CDCツールやCDCプロセスは、これらのログを読み取り、変更内容を解釈し、他のシステムへレプリケートしたり、追加の分析のために保存したりします。
ログベースCDCは、ソースデータベースの変更を取得するための主流となる手法です。
主要なCDCのユースケース:分析基盤からKafka連携まで
CDCは、さまざまな業界やアプリケーションで利用されています。以下は代表的なユースケースの一覧です:
- リアルタイム分析&BI:CDCはデータをリアルタイムで分析基盤やデータウェアハウスへレプリケートし、運用システムへ負荷をかけることなく、最新データに基づく分析を可能にします。
- クラウドデータベース移行:TiDBへの移行時やクラウド間移行のカットオーバーにおいて、ソースとターゲットを同期し続けることで、ダウンタイムとリスクを最小化します。
- イベント駆動型マイクロサービス:行レベルの変更をイベントとして公開し、通知、不正検知、在庫更新など、下流のサービスが即座に反応できるようにします。
- Kafka連携によるストリーミングパイプライン:CDCの出力をApache Kafkaに送ることで、Flink / Spark / ksqlDBなど、多数のコンシューマーへのスケーラブルなファンアウトを実現します。
- ハイブリッドクラウド&データレイクパイプライン:変更データをS3 / GCS / HDFSなどのデータレイクに継続的に取り込み、ML特徴量生成、アーカイブ、クロスリージョンの分析を支えます。
- データウェアハウス&ビジネスインテリジェンス:CDCは、運用データベースからトランザクションデータを抽出してデータウェアハウスへ取り込み、レポーティング、分析、意思決定を支援します。
- 高可用性のためのレプリケーション:CDCにより、システム障害や災害発生時でもダウンタイムを最小化できるよう、ほぼリアルタイムで冗長なコピーを作成します。
- データ移行とシステムアップグレード:システム移行やアップグレード時に、旧システムで発生した変更を新システムへ継続的にレプリケートし、データ整合性と最小限のダウンタイムを確保します。
- 分散システム間の同期:地理的に分散した複数システムやデータベース間のデータを同期し、すべてのシステムが一貫性のある最新状態を維持できるようにします。
- コンプライアンス&監査:CDCは重要データに対するすべての変更を追跡・記録し、法規制や内部ポリシー遵守のための詳細な監査証跡を提供します。
これらのユースケースは、CDCがリアルタイムまたはニアリアルタイムで変更を取得・伝播・適用することが、データ管理、分析、システム運用においていかに重要であり、多用途であるかを示しています。
TiDBによるChange Data Capture:データレプリケーションのために設計された分散SQL
多くの企業は、データ同期を実現するためにCDCレプリケーションに依存しています。しかし、ほとんどのデータベース製品はCDCを標準アーキテクチャとして提供していないため、企業はサードパーティ製のソリューションを購入し、統合する必要があります。
PingCAPでは、TiDBと完全に統合された、コスト効率の高いCDCレプリケーションツールを開発しました。当社の高度なオープンソース分散SQLデータベースは、リレーショナルデータベースに対するオールインワンのソリューションを提供するために設計されています。特に大規模データセットを扱う場合に、高可用性・スケーラビリティ・強整合性を要求する多様なシナリオに対応できます。すでに世界中で3,000 社以上に採用されている信頼性の高いデータベースプラットフォームです。
TiCDC:TiDBネイティブのChange Data Captureソリューション
TiCDC (TiDB Change Data Capture) は、TiDB専用に設計されたCDCソリューションです。
TiCDCは、TiDBに対して行われたリアルタイムの変更をキャプチャし、レプリケートするツールです。INSERT、UPDATE、DELETEといったDML (データ操作言語) による変更だけでなく、CREATE、DROP、ALTERといったDDL (データ定義言語) による変更も追跡・適用できます。ソースTiDBデータベースはこれらの変更をキャプチャし、1つまたは複数のターゲットデータベースにレプリケートします。
TiCDCとは何か
TiCDCは、ソースTiDBクラスタで発生したDMLおよびDDLによる変更をキャプチャし、それらを低レイテンシでターゲットシステムへ効率的にレプリケートします。ターゲットシステムには、データウェアハウス、分析データベース、MySQL互換データベース、Kafkaクラスタ、さらには別のTiDBクラスタなどが含まれます。
TiCDCがKafkaおよびクラウドデータベースと連携する仕組み
以下は、TiCDCの動作概要です:
- 変更のキャプチャ:TiCDCはTiDBクラスタ内の変更を継続的に監視します。これは、TiDBが生成するredo log (トランザクションログ) を利用することで実現され、データベースに対するすべての変更を取得します。
- 変更の処理:キャプチャした変更は、TiCDCによって処理され、レプリケーションに適した形式へ整理されます。TiCDCはデータ整合性を確保し、変更の順序を正確に維持します。
- レプリケーション:処理された変更は、各ターゲットシステムへさまざまなコネクタを通じてレプリケートされます。TiCDCはTiDB、MySQL、およびMySQL互換データベースに対応したシンクコネクタをサポートし、多様なデータプラットフォームとの統合を可能にします。
- データの整合性:TiCDCは、異なるレプリカやデータシンク間で強力なデータの整合性を維持します。同一のデータ順序を維持し、正しいシーケンスで適用します。ソースとターゲット間のネットワークレイテンシは100ミリ秒以下であることが推奨され、ほぼリアルタイムのレプリケーション整合性を実現します。注:TiCDCノードは、増加したレプリケーション負荷に応じてスケールアウトできます。
- フォールトトレランス:TiCDCは高可用性と耐障害性を重視して設計されており、障害発生時でもデータ損失なしでレプリケーションを継続できます。TiCDCはRPO (目標復旧ポイント) を数秒、RTO (目標復旧時間) を数分で提供します。
- テーブルのレプリケーション設定:TiCDCは、特定のデータベース・テーブル・DML・DDLをフィルタリングし、レプリケート対象を細かく制御できます。
- クラスタ管理: OpenAPIを使用することで、タスクステータスの取得、タスク設定の動的な変更、タスクの作成・削除が可能です。
TiDBのセルフマネージドクラスタにおいて、TiCDCは変更されたデータをさまざまなターゲットシステムへレプリケートすることが可能です。以下の表に示します:
| ソース | ターゲット | レプリケーションタイプ |
| TiDB | TiDB | 一方向 / 双方向 |
| TiDB | MySQL互換データベース | 一方向 |
| TiDB | Kafka (Avro / JSONフォーマット) | 一方向 |
| TiDB | AWS S3 オブジェクトストレージ | 一方向 |
| TiDB | AWS Google Cloud Storage | 一方向 |
| TiDB | Azure Blob Storage | 一方向 |
| TiDB | NFS | 一方向 |
リアルタイムデータパイプラインのためのTiCDCアーキテクチャ
以下の図は、TiCDCのアーキテクチャの動作イメージです:

上図の左側示されているTiDBクラスタがソースシステムです。データはソースから以下のように伝達されます:
- データに変更が発生すると、TiDBクラスタは新しい変更ログをTiCDCクラスタに送信します。
- TiCDCクラスタはログから変更内容を解析します。
- 最後に、設定されたターゲットプラットフォームが解析済みの変更をプッシュして適用します。これらの変更は、TiDBクラスタ、MySQL互換データベース、Kafka、あるいはストレージオブジェクトなどに適用可能です。
TiCDCのユースケース:マルチリージョン同期、データレイク、ストリーミング
TiCDCはさまざまなシナリオで利用可能です。
- ディザスタリカバリ:TiCDCは、多くの顧客によってリアルタイムレプリケーションの構築に広く利用されています。このレプリケーションは、プライマリのTiDBプロダクションクラスタからリモートのTiDBクラスタやMySQL互換データベースへ行われます。この構成により、アクティブ-パッシブのセットアップが実現し、データ整合性を維持しつつ、信頼性の高い災害復旧ソリューションを提供します。さらに、ターゲットデータベースでリアルタイムレポートを実行できるため、プライマリデータベースへのレポート負荷を効果的に軽減できます。
- リアルタイム分析レポーティング:TiCDCはターゲットの分析データベースへリアルタイムデータを供給できます。これにより、データアナリストは常に更新されるデータセット上でリアルタイム分析を行うことが可能です。
- データウェアハウス:TiCDCは、プロダクションデータベースで発生した最新の変更をデータウェアハウスに反映し、常に最新の状態に保ちます。
さらに、TiCDCはKafkaのような複数の異種ターゲットをサポートします。Kafkaはリアルタイム分析の標準プラットフォームとして広く利用されています。また、TiCDCはレプリケーション負荷に応じて水平スケーリングできる点も特徴です。これは技術的な詳細ですが、分散システム向けツールとしてTiCDCが選ばれる理由の一つとなっています。
では、TiCDCレプリケーションを使用する際に、ソースデータベースとターゲットデータベースが同期しているかをどのように確認すればよいでしょうか?ターゲットがTiDBクラスタまたはMySQLインスタンスの場合は、sync-diff-inspectorを使用してデータ整合性を比較することが推奨されます。sync-diff-inspectorは、MySQLプロトコルを用いて保存されたデータを比較するTiDBのツールです。
結論と次のステップ:TiDBでCDCを始めるには
CDCは、モダンなデータ管理や分析において重要な役割を果たす強力な技術です。TiDB専用に設計されたTiCDCは、分散かつ高可用なデータベースで変更をキャプチャしレプリケートする堅牢なソリューションを提供します。リアルタイム分析、データウェアハウス、データ統合のいずれであっても、TiCDCはデータの同期と最新状態の維持をサポートし、常に最新かつ正確な情報に基づいて作業できる環境を提供します。
TiCDCが役立ちそうだと感じましたか?詳細や導入方法については、公式ドキュメントページをご参照ください。
TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。