

※このブログは2026年03月04日に公開された英語ブログ「How to Build an AI App That Simulates Life Decisions」の拙訳です。
重要ポイント
- AIを活用したライフシミュレーターアプリを構築し、6つの生活領域 (財務、感情、キャリア、健康、人間関係、全体) にわたる6〜24か月の現実的な結果を生成します。
- 1つの意思決定につき6つのエンベディングを用いることで、曖昧で誰にでも当てはまるような結果ではなく、特定の生活領域に対するターゲット化されたセマンティック検索を可能にします。
- TiDBはベクトル検索とSQL結合を単一クエリで組み合わせ、シナリオを分離して探索するためのデータベースレベルのブランチを提供します。
- プロンプトは楽観的な見通しではなく、感情的な正直さを求めます。現実的なリスクや実体験が、AIによる意思決定の予測を実用的にします。
2025年のほとんどの期間、私は疲弊したループに陥っていました。数日に一度、ChatGPT、Claude、Geminiを開き、ほぼ同じ質問を少しずつ異なる形で投げかけていました。「家を買うべきか、それとも賃貸を続けるべきか?」
表面上、数字はシンプルに見えました。私の家賃は月額2,000ドルです。住宅ローンは約3,500ドルです。結論は出ましたね?賃貸を続けて1,500ドルの差額を手元に残すべきです。
しかし、実際の大きな人生の意思決定はそんなに単純ではありません。
資産形成はどうでしょうか?税制上のメリットは?1,500ドルの差額をインデックスファンドに投資する機会コストはどうでしょうか?そして何より、非金銭的な要素はどうでしょうか?所有による心理的安定感、賃貸の柔軟性、メンテナンスのストレスなどです。
私は財務情報をChatGPTにコピーペーストし、変数を1つ変更して再度質問しました。それからClaudeを別の切り口で試し、次にGemini、また前提条件を更新してChatGPTに戻りました。各AIは妥当な答えを返してくれましたが、結局私はほぼ同じシミュレーションを手動で何百回も行っていました。
3か月間この疲弊するサイクルを繰り返した後、私はひらめきました。自分が手動でやっていたことは、AI搭載アプリなら自動でできることだと気づきました。
そこで私はParallel Livesを開発することにしました。これはAIを活用したライフシミュレーションツールで、可能性のある未来の分岐したタイムラインを生成します。20年先の幻想的な予測ではなく、計画に現実的に活用できる6か月、12か月、24か月のシナリオを提供します。
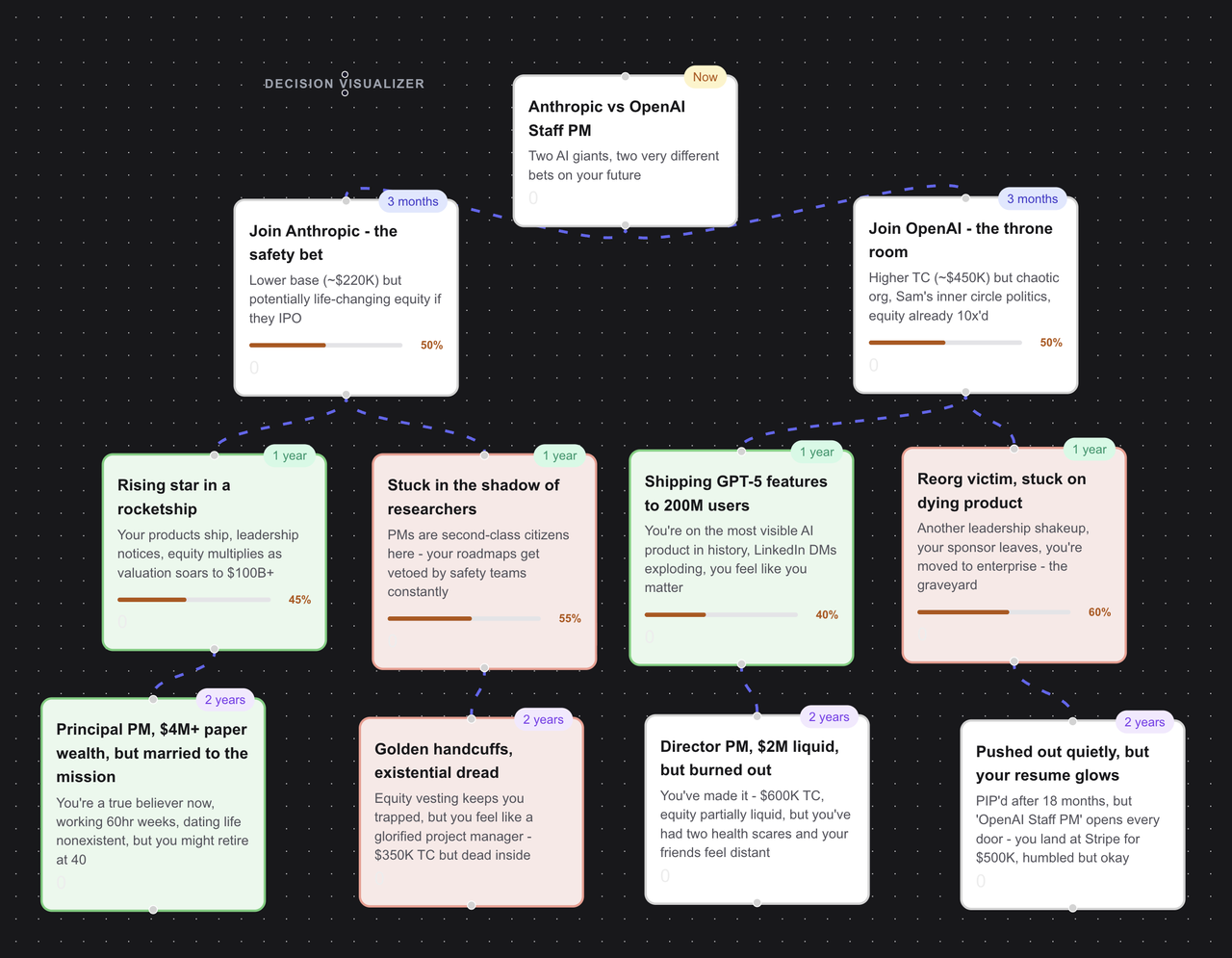
Parallel Livesの仕組み:AI駆動のライフシミュレーター
Parallel Livesは、人生におけるあらゆる重要な意思決定を入力すると、異なる選択がどのように展開していくかを複数の側面から示します。金銭面だけでなく、感情面、キャリア面、そして個人としての側面も含まれます。
コアとなるワークフロー:
- 意思決定を入力します (購入するか賃貸にするか、転職するか現職に留まるか、引っ越すか現状維持か)。
- AIが現実的な結果を伴う2つの初期パスを生成します。
- 任意のパスをクリックして、より深い結果を探索します。
- 任意の意思決定ポイントで別の分岐を作成します。
- 過去のすべての意思決定をセマンティックに検索します。
- パス同士を並べて比較し、AIによる分析を行います。
これは、大規模言語モデルによって駆動される意思決定ツリーの可視化ツールのようなものであり、各ノードは単なる結果ではなく、6つの人生の側面における状態の推移を表します。
テクノロジースタック:なぜこれらのツールを選んだのか
AIによる意思決定シミュレーションアプリの構築には、複数の機能のバランスが求められます。自然言語理解、ベクトル類似検索、リレーショナルデータ管理、そしてリアルタイムストリーミングです。単一のツールですべてを完璧にこなすことはできないため、レイヤーごとに特化したソリューションを選択しました。
TiDB Cloud Starter:すべての基盤となるデータベース
私は以下に対応できるデータベースを必要としていました:
- リレーショナルデータ (意思決定ツリー、ユーザーセッション、分岐パス)
- ベクトルエンベディング (各ノードあたり1,536次元)
- 多次元データに対するセマンティック検索
- ベクトルとリレーションを結合したリアルタイムクエリ
- 予測不可能なトラフィックに対応するコスト効率の高いスケーリング
TiDB Cloud Starterは、これらすべてを1つのMySQL互換システムで提供します。Postgres + Pinecone + Redisを個別に管理する代わりに、単一のSQLクエリでリレーショナルテーブルの結合とベクトル類似検索を同時に実行できます。TiDB Cloud Starterはアイドル時にゼロまでスケールするため、ユーザーが意思決定を行っていない間にコストが発生し続けることはありません。
Claude Opus 4.5:主要なシナリオ生成エンジン
OpusはParallel Livesの中核です。意思決定を入力すると、Opusは現実的な感情のニュアンスを伴った分岐シナリオを生成します。これは単なる検索タスクや単純な予測ではありません。文脈を理解し、二次的な影響を予測し、デメリットについても正直に示す必要があります。
最初にGPT-4とGemini 1.5 Proを試しました。どちらもそれらしいシナリオを生成しましたが、一貫して楽観的すぎる傾向がありました。Opusは人生の意思決定における複雑な現実を捉えます。人間関係に負担をかける昇進、失敗に終わるもののかけがえのない教訓をもたらすスタートアップ、資産形成にはつながる一方でキャリアの柔軟性を制限する住宅などです。
Claude Sonnet 4:次元抽出と構造化データ
意思決定ノードを保存する前に、6つの人生の側面 (財務、感情、人間関係、キャリア、健康、全体) にわたる要約を抽出する必要があります。Sonnet 4はこの構造化抽出タスクに優れており、ニュアンスよりも一貫性が重要なケースでは、Opusよりも高速かつ低コストです。
GPT-4o mini:パス比較分析
ユーザーが2つの分岐を並べて比較したい場合、GPT-4o miniがトレードオフ分析を生成します。高速でコスト効率が高く、競合する優先事項を分かりやすい形で整理することに特に優れています。
OpenAI Embeddings (text-embedding-3-small):セマンティック検索の基盤
各次元の要約はすべて1,536次元のベクトルに変換されます。これにより、「ワークライフバランスに影響を与えた意思決定を表示する」といった検索を、正確なキーワード一致に依存せずに実現できます。
データアーキテクチャ:多次元意思決定モデリング
ここがParallel Livesが一般的なAIアプリケーションと異なるポイントです。多くのアプリはドキュメントごとに1つのエンベディングを作成しますが、私は意思決定ノードごとに6つのエンベディングを作成することにしました。
なぜ人生の意思決定に6つの次元が重要なのか
人生における大きな選択は、1つの領域だけに影響するわけではありません。新しい仕事に就くことは、以下のような影響を与えます:
- 財務:給与、福利厚生、通勤コスト、引っ越し費用
- 感情:ストレスレベル、充実感、不安、期待感
- 人間関係:家族や友人との時間、恋愛関係の健全性、職業上のネットワーク
- キャリア:スキル開発、評価、将来の機会、キャリアの方向性
- 健康:身体的な健康、メンタルヘルス、エネルギー、燃え尽きリスク
- 全体:すべての要素を統合した全体像
誰かが「人間関係に影響を与えた意思決定を表示してほしい」と求めたとき、財務的な内容で薄められた結果は望んでいません。対象を絞った次元ごとの検索は、汎用的なエンベディング検索よりも優れています。
多次元意思決定のためのデータベーススキーマ
コアとなるデータモデルは、3つのテーブルで構成されています。
-- Stores complete decision trees
CREATE TABLE trees (
id VARCHAR(36) PRIMARY KEY,
decision TEXT NOT NULL,
tree_data JSON NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
INDEX idx_created (created_at)
);
-- Tracks user's exploration path through decisions
CREATE TABLE decision_history (
id VARCHAR(36) PRIMARY KEY,
session_id VARCHAR(36) NOT NULL,
parent_id VARCHAR(36),
decision TEXT NOT NULL,
choice_made TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
INDEX idx_session (session_id),
INDEX idx_parent (parent_id)
);
-- Stores six embeddings per decision node
CREATE TABLE decision_embeddings (
id VARCHAR(36) PRIMARY KEY,
decision_id VARCHAR(36) NOT NULL,
node_id VARCHAR(255) NOT NULL,
dimension ENUM('financial', 'emotional', 'relationship',
'career', 'health', 'overall'),
summary TEXT NOT NULL,
embedding VECTOR(1536),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
INDEX idx_decision (decision_id),
INDEX idx_dimension (dimension),
VECTOR INDEX idx_embedding (embedding) USING HNSW
); tree_dataのJSONカラムには、完全なブランチ構造が格納されており、各ノードにはシナリオの説明、時間軸、感情スコア、そしてさらなる探索のための子ノードが含まれています。
システムにおけるデータの流れ
[ユーザーが人生の意思決定を入力]
↓
[Claudeが2年間の結果を伴う2つの初期パスを生成]
↓
[ユーザーがパスをクリックしてさらに探索]
↓
[Claudeが次の意思決定ポイントとその結果を生成]
↓
[ユーザーは分岐可能:「もし別の選択をしていたら?」]
↓
[[各ノードから6次元の要約を抽出]
↓
[エンベディングを生成し、TiDBに保存]
↓
[過去のすべての意思決定に対するセマンティック検索]AI駆動のライフシミュレーター:なぜTiDB Cloud Starterを選ぶのか
ほとんどのベクトルデータベースでは、ベクトル検索とリレーショナルクエリのどちらかを選ばざるを得ません。TiDB Cloud Starterは両方を独自に組み合わせており、意思決定モデリングに不可欠な3つの機能を実現しています。
多次元ベクトルインデックス
各意思決定ノードには、6つのライフ次元ごとに個別のベクトルインデックスが必要です。Pineconeを使う場合、6つのネームスペースまたは6つの個別インデックスが必要になります。「健康と人間関係に影響を与えた意思決定」を検索するには、6回のAPIコールを行い、その結果をアプリケーションコードでマージする必要があります。
TiDB Cloud Starterでは、これが1つのSQLクエリで済みます。
SELECT * FROM decision_embeddings
WHERE dimension IN ('emotional', 'health')
AND VEC_COSINE_DISTANCE(embedding, ?) < 0.5
ORDER BY distance ASC;データベースは多次元フィルタリングをネイティブに処理します。クライアント側での結果マージは不要です。
ベクトルとリレーショナルデータの結合
「人間関係に影響を与えた意思決定」を検索する場合、以下を行う必要があります。
- 係の次元で一致人間関するエンベディングを検索
- 元の意思決定テキストのためにdecision_history (決定の履歴) と結合
- 全体の文脈と分岐パスのためにtreesと結合
分離型アーキテクチャ (Pinecone + Postgres) の場合、まずベクトル検索を行い、その後手動で結合し、結果をマージする必要があります。しかし、TiDB Cloud Starterでは、これが1つのクエリで実現できます:
SELECT
de.summary,
d.decision,
t.tree_data
FROM decision_embeddings de
JOIN decision_history d ON de.decision_id = d.id
JOIN trees t ON d.session_id = t.id
-- 人間関係 (relationship) カテゴリに限定
WHERE de.dimension = 'relationship'
-- ベクトル的に類似度が高いものだけ取得
AND VEC_COSINE_DISTANCE(de.embedding, ?) < 0.5
-- 類似度が高い順 (距離が小さい順) に並べる
ORDER BY distance ASC;ベクトル類似検索とリレーショナル結合が同時に実行されるため、文脈を保持したままのセマンティック検索が可能です。
シナリオ探索のためのデータベースレベルのブランチ
この機能によって、TiDB Cloud Starterが意思決定モデリングアプリケーション向けに設計されていることを実感しました。
Parallel Livesの基本は、別の現実を探索することです。「もしあの仕事を選んでいたら?」と「もし今のままだったら?」の比較です。それぞれのパスはさらに別のパスに分岐します。ユーザーはクリックして探索し、戻ったり、異なるシナリオを試したりできます。
TiDB Cloud Starterの分岐APIは、ミリ秒単位で分離されたデータベースコピーを作成します。
const response = await fetch(
`https://serverless.tidbapi.com/v1beta1/clusters/${clusterId}/branches`,
{
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({
displayName: `scenario-${scenarioId}`,
parentId: clusterId
})
}
);各ブランチは完全なデータベースコピーです。ユーザーは意思決定のパスを探索し、新しいノードを生成し、エンベディングを保存できます。もしリセットしたり別の前提で試したりしたい場合でも、元のブランチは変更されません。真の分離と、真のロールバック機能です。
この機能は、Manus.aiがエージェントに数千の解決パスを同時に探索させるために使用しているものと同じです。Parallel Livesでは、ユーザーが意思決定ツリーをUIレベルだけでなく、データベースレベルで分岐させることが可能になります。
ボーナス:スケール・トゥ・ゼロの経済性
意思決定は利用が集中するタイミング (大きな選択に直面したとき) があり、その後は数週間利用がないこともあります。従来のデータベース課金モデルでは、このようなパターンは常時稼働コストによって不利になります。
TiDB Cloud Starterはスケール・トゥ・ゼロに対応しています。アイドル期間中は費用がかかりません。ユーザーが意思決定ツリーを探索すると、キャパシティは瞬時に立ち上がります。トラフィックが予測できないサイドプロジェクトでは、これにより持続可能な運用と、従来のモデルでの高額すぎるコストとの差が生まれます。
AI駆動のライフシミュレーター:感情的に正直な予測の実現
最初にシナリオ生成を試したときは、全く使い物になりませんでした。Claudeに「可能な結果を生成して」と指示したところ、出てきたのは完全な空想でした。どのシナリオも完璧にうまくいき、ストレスも、人間関係の摩擦も、隠れたコストもありませんでした。実際の意思決定にはまったく役に立たない結果です。
突破口は、プロンプトを「楽観的であるよりも感情的に正直であること」を要求する形に書き換えたことでした。
すべてを変えたシステムプロンプト
const SYSTEM_PROMPT = `あなたは、人生における重大な意思決定について、起こり得る複数の未来をシミュレーションします。`
重要なルール:
1. 感情に正直でいましょう。曖昧なリスク表現は避けましょう。
- 悪い例:「いくつかの課題に直面するかもしれません」
- GOOD:良い例:「最初の6ヶ月は孤独を感じることになるでしょう。ほとんどの人がそうなります」
2. 結果だけでなく、実際の生活の様子を示しましょう。
- 悪い例:「年収は15万ドルに上がります」
- 良い例:「年収は150万ドルですが、週60時間働いており、この四半期ですでに家族のイベントを3回逃しています」
3. ユーザーの入力にある具体的な事実はそのまま残しましょう。
- もし「120k万ドルのオファー」と言っているなら、「良い給与」ではなくそのまま「12万ドルのオファー」と書きましょう
4. 異なる時間軸では、繰り返しではなく変化を示しましょう。
- 6ヶ月:直近の適応期間です
- 1年:パターンが見え始めます
- 2年:新しい日常が定着します
5. すべての良いことには代償があります。すべての悪いことにも良い面があります。
- 昇進 → サイドプロジェクトに使える時間が減ります
- スタートアップの失敗 → しかし、素早く形にする力が身につきます
その違いは劇的でした。
以前は:「あなたは成功し、充実感を感じる。」
今は:「資金調達ラウンドは成立したが、共同創業者とは緊張関係にある。2か月間運動もしていない。株式は帳簿上は価値があるが、このストレスが本当に見合うのか疑問に思っている。」
このような微妙なニュアンスを含む予測こそ、単なるモチベーション的な空想ではなく、実際に役立つ意思決定ツールを特徴づけるものです。
意思決定の種類ごとのドメイン固有ガイダンス
仕事のオファーに関する意思決定は、住宅や転居に関する意思決定とは異なる考慮事項が必要です。最初のバージョンでは、すべてに対して汎用的なプロンプトを使用していました。その結果、出力は平凡で似通ったものになっていました。
現在は、意思決定の種類に応じた専門的指針を組み入れています。
function getScenarioGuidance(decision: string): string {
const lower = decision.toLowerCase();
if (lower.includes('job offer') || lower.includes('salary')) {
return `JOB OFFER GUIDANCE:
- Total comp matters more than base salary (equity, bonus, benefits)
- Consider: commute impact on daily energy, team culture fit, growth ceiling
- Hidden costs: relocation, lifestyle inflation, golden handcuffs`;
}
if (lower.includes('house') || lower.includes('mortgage') ||
lower.includes('rent')) {
return `HOUSING GUIDANCE:
- True cost = mortgage + property tax + insurance + maintenance
(budget 1-2% of home value/year)
- Renting isn't "throwing money away" - run the actual numbers
- Location lock-in: how does this affect job flexibility?`;
}
if (lower.includes('move') || lower.includes('relocate') ||
lower.includes('city')) {
return `RELOCATION GUIDANCE:
- Cost of living differences can erase salary gains
- Social network rebuild takes 1-2 years minimum
- Consider: weather impact on mental health, proximity to family`;
}
return ''; // Generic decision, no special guidance
}この文脈に基づくプロンプトにより、出力の品質は劇的に向上しました。住宅の意思決定では、維持費の積立や機会費用が反映されるようになりました。仕事のオファーでは、企業文化との相性や通勤の影響が含まれます。人々がつい考慮し忘れるような細かい点まで考慮されるようになりました。
より良いUXのためのストリーミングレスポンス
Claude Opusでツリーを生成するには10~15秒かかります。フィードバックなしに読み込み中のアイコンを見続けるには長すぎます。
そこで、AIの応答をストリーミングし、ユーザーが意思決定ツリーがリアルタイムで構築されていく様子を確認できるようにしています:
export async function POST(request: NextRequest) {
const { decision, mode } = await request.json();
const stream = await anthropic.messages.stream({
model: "claude-opus-4-5-20250514",
max_tokens: 4000,
system: SYSTEM_PROMPT + getScenarioGuidance(decision),
messages: [{ role: "user", content: buildPrompt(decision, mode) }]
});
return new Response(
new ReadableStream({
async start(controller) {
for await (const chunk of stream) {
if (chunk.type === 'content_block_delta') {
controller.enqueue(
new TextEncoder().encode(chunk.delta.text)
);
}
}
controller.close();
}
}),
{ headers: { 'Content-Type': 'text/plain; charset=utf-8' } }
);
}フロントエンドはストリームを順番に処理し、ノードが生成されるたびにレンダリングします。ユーザーはツリーが成長していく様子をリアルタイムで確認できるため、生成にかかる時間は同じでも、処理が速く進んでいる印象を受けます。
過去の意思決定に対するセマンティック検索
それぞれの意思決定を6次元のエンベディングで探索した後は、強力な検索機能が利用可能になります:
export async function POST(request: NextRequest) {
const { query, dimensions = ['overall'], limit = 10 } = await request.json();
const queryEmbedding = await generateEmbedding(query);
const [rows] = await pool.execute(`
SELECT
de.decision_id,
de.node_id,
de.dimension,
de.summary,
d.decision as original_decision,
VEC_COSINE_DISTANCE(de.embedding, ?) as distance
FROM decision_embeddings de
JOIN decision_history d ON de.decision_id = d.id
WHERE de.dimension IN (${dimensions.map(() => '?').join(',')})
AND VEC_COSINE_DISTANCE(de.embedding, ?) < 0.5
ORDER BY distance ASC
LIMIT ?
`, [queryEmbedding, ...dimensions, queryEmbedding, limit]);
const grouped = groupByDecision(rows);
return NextResponse.json({ results: grouped });
}ユーザーが行える検索例:
- 「どの意思決定が人間関係に影響を与えたか?」
- 「健康よりキャリアを優先した選択を見せて」
- 「どのシナリオで経済的なストレスがあったか?」
- 「リスクを取ったときに何が起きたか?」
システムは過去のすべての意思決定ノードから該当する次元を検索し、文脈に沿った結果を返します。意思決定の履歴と会話しているような感覚です。
異なる選択肢の結果を比較
時には、さらなる探索は必要なく、特定の2つのパスの違いを明確に知りたい場合があります。「自分の場合、購入と賃貸の違いは実際どこにあるのか?」
比較機能では、構造化された出力を生成するためにGPT-4o miniを使用します:
const response = await openai.chat.completions.create({
model: "gpt-4o-mini",
response_format: { type: "json_object" },
messages: [{
role: "system",
content: `Compare these two life paths. Return JSON with:
- recommendation: "A" | "B" | "depends"
- path_a_strengths: string[]
- path_a_weaknesses: string[]
- path_b_strengths: string[]
- path_b_weaknesses: string[]
- future_voice: "A message from your future self about this choice"
- key_questions: "Questions to ask yourself before deciding"`
}, {
role: "user",
content: `Path A: ${pathA.description}\n\nPath B: ${pathB.description}`
}]
});future_voiceフィールドは、その選択をした仮想の未来の自分からの一人称メッセージを生成します。少し陳腐に聞こえるかもしれませんが、ユーザーは一貫してこれをお気に入り機能として挙げています。「2年後の自分だよ。スタートアップの仕事を選んだ。株式は結局形にならなかったけど、18か月で得た学びは、大企業での5年間よりも大きかった。後悔はない。」と読むと、何か強いメッセージを感じます。
AI駆動のライフシミュレーター:継続的な改善と既知の制約
完璧なソフトウェアは存在せず、Parallel Livesにも現在取り組んでいるいくつかの洗練されていない部分があります:
キャリブレーションの課題:楽観主義と現実主義
予測はどの程度悲観的であるべきでしょうか?楽観的すぎるとツールは役に立ちません。悲観的すぎると意思決定が麻痺してしまいます。
現状では、多くの人のメンタルモデルが楽観的すぎるため、現実的なデメリットを重視する傾向にあります。しかし、一部のユーザーからは、アプリが楽しいと感じていた意思決定に対して不安を与えたとの報告もあります。このフィードバックにより、バランスを再検討しています。
事実保持の問題
ユーザーが「15万ドルのオファーで0.5%の株式」と言った場合、その具体的な数字はツリー全体で一貫して保持される必要があります。Claudeは時々簡略化してしまったり (だいたい15万ドル)、言い換えたり (強力な株式パッケージ) します。明示的に保持するように指示を追加しましたが、まだ100%信頼できる状態ではありません。
タイムラインの標準化
現在、すべてのシナリオは固定の期間 (6か月、1年、2年) を使用しています。しかし、「2年」の意味は意思決定によって異なります。スタートアップなら2年間で3回方針転換するかもしれません。住宅ローンは30年間のコミットメントです。
私は、意思決定の自然なリズムに合わせて調整される、シナリオごとのタイムライン生成に取り組んでいます。
不確実性への対応
一部の意思決定には、実際に予測不可能な変数があります (スタートアップは資金を獲得できるか?住宅市場は暴落するか?)。現状では、アプリは複数のシナリオを表示しますが、確率は数値化していません。確率モデルを追加すれば役立ちますが、あたかも確実な数字に見えるリスクがあります。
このAI駆動ライフシミュレーターがAI意思決定ツールについて教えてくれたこと
Parallel Livesを構築する中で、意思決定においてAIが有用なものと、そうでないものの違いが明確になりました。
有用なこと:
- 楽観主義よりも感情の正直さ
- 単一軸思考ではなく多次元分析
- 長期の空想より短期シナリオ (6〜24か月)
- ドメイン固有の文脈 (住宅、仕事、転居など)
- 思考プロセスを可視化するストリーミングUX
- 過去の意思決定から学べるセマンティック検索
有用でないこと:
- すべてに同じプロンプトを使うこと
- 生きた体験を伴わない純粋な数値分析
- 3年以上の長期予測
- 意思決定ごとの単一エンベディング
- デメリットを無視した楽観的バイアス
核心的な洞察:意思決定はスプレッドシートではありません。意思決定は物語です。優れた意思決定ツールは、単に表のセルを見せるのではなく、実際に生きた体験を示すべきです。
AI駆動ライフシミュレーター:Parallel Livesを体験しよう
Parallel Livesは、以下の理由でTiDB Cloud Starter上に構築されています:
- データベースレベルの分離を備えた分岐型意思決定ツリー
- 多次元ベクトルエンベディング (ノードごとに6つ)
- 過去のすべての意思決定に対するセマンティック検索
- ベクトル類似度検索とリレーショナル結合の統合
- 予測不可能な利用パターンにも対応するスケール・トゥ・ゼロの経済性
これらすべてを、1つのMySQL互換データベースで実現しています。
次のステップ
Related Resources

Conference
May 19, 2026
TiDB SCaiLE Europe 2026: Why Engineers Building Agentic AI Should Be in Stockholm on 4 June

Conference
May 12, 2026
TiDB SCaiLE Europe 2026: Speaker Lineup and Session Preview

Product
May 11, 2026
From Preview to Production: TiDB Cloud Dedicated on Microsoft Azure is Now Generally Available
TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。