The Database for Agentic Workloads
Agents don’t query—they explore, branch, and multiply. TiDB unifies vectors, transactions, and analytics to handle this, letting you provision databases instantly, operate at scale, and keep costs under control.

Traditional databases were designed for predictable, human-driven workloads. Agentic systems operate fundamentally differently.
Leading AI innovators are solving scaling challenges with TiDB.

“TiDB’s elastic architecture enabled us to migrate in two weeks, supporting users and massive ‘Context Engineering’ workloads for viral success.”
“We consolidated our entire AI backend into TiDB—letting our engineers focus on building agent features instead of managing database complexity.”

“TiDB’s unified architecture enabled AI agents to access complete, real-time user context for autonomous marketing decisions.”

“Unified HTAP + Vector engine enabled hybrid queries combining semantic understanding with SQL precision for real-time conversational analytics.”

“Real-time architecture enabled storing and aggregating survey data on the fly, eliminating processing overhead.”

Create AI assistants that understand context and meaning, not just keywords, using vector embeddings and retrieval-augmented generation.
class Chunk(TableModel):
__tablename__ = "chunks"
id: int = Field(primary_key=True)
text: str = Field()
text_vec: list[float] = text_embed.VectorField(
source_field="text",
)
meta: dict = Field(sa_type=JSON)
table = db.create_table(schema=Chunk, if_exists="overwrite")
results = (
table.search(query_text)
.debug(True)
.filter({"meta.language": language})
.distance_threshold(distance_threshold)
.limit(query_limit)
.to_list()
)

Enable multimodal search experiences where users can find images using text descriptions or discover similar visual content effortlessly.
class Pet(TableModel):
__tablename__ = "pets"
id: int = Field(primary_key=True)
breed: str = Field()
image_uri: str = Field()
image_name: str = Field()
image_vec: Optional[List[float]] = embed_fn.VectorField(
distance_metric=DistanceMetric.L2,
source_field="image_uri",
source_type="image",
)
results = (
table.search(query="fluffy orange cat")
.distance_metric(DistanceMetric.L2)
.limit(limit)
.to_list()
)

Get the best of both worlds by merging traditional full-text search with modern vector similarity for comprehensive, accurate results.
# Define table schema
class Document(TableModel):
__tablename__ = "documents"
id: int = Field(primary_key=True)
text: str = FullTextField()
text_vec: list[float] = embed_fn.VectorField(
source_field="text",
)
meta: dict = Field(sa_type=JSON)
query = (
table.search(query_text, search_type="hybrid")
.distance_threshold(0.8)
.fusion(method="rrf")
.limit(limit)
)

Transform your text, images, and documents into searchable vectors without manual preprocessing or complex embedding pipeline setup.
# Define embedding function
embed_func = EmbeddingFunction(
model_name="tidbcloud_free/amazon/titan-embed-text-v2"
# No API key required for TiDB Cloud free models
)
class Chunk(TableModel):
__tablename__ = "chunks"
id: int = Field(primary_key=True)
text: str = Field(sa_type=TEXT)
text_vec: list[float] = embed_func.VectorField(source_field="text")
table = db.create_table(schema=Chunk, if_exists="overwrite")
# Insert sample data - embeddings generated automatically
table.bulk_insert([
Chunk(text="TiDB is a distributed database that supports OLTP, OLAP, HTAP and AI workloads."),
Chunk(text="PyTiDB is a Python library for developers to connect to TiDB."),
Chunk(text="LlamaIndex is a Python library for building AI-powered applications."),
])

Automatically embed product data and deliver personalized recommendations that update in real-time as your inventory changes, without complex pipelines.
class Product(TableModel):
__tablename__ = "products"
id: int = Field(primary_key=True)
name: str = Field(sa_type=TEXT)
description: str = Field(sa_type=TEXT)
description_vec: list[float] = embed_func.VectorField(
source_field="description"
)
category: str = Field(sa_type=TEXT)
price: float = Field()
table = db.create_table(schema=Product, if_exists="overwrite")
# App-1 is inserting strings and vectors are auto-generated in real-time
table.insert(Product(
name="Professional Basketball",
description="High-quality basketball for professional and amateur players",
category="Sports",
price=29.99
))
# App-2 is searching at once using semantic similarity with user preferences
recommendations = (
table.search(user_profile)
.distance_threshold(distance_threshold)
.limit(5)
.to_list()
)
Create AI assistants that understand context and meaning, not just keywords, using vector embeddings and retrieval-augmented generation.
class Chunk(TableModel):
__tablename__ = "chunks"
id: int = Field(primary_key=True)
text: str = Field()
text_vec: list[float] = text_embed.VectorField(
source_field="text",
)
meta: dict = Field(sa_type=JSON)
table = db.create_table(schema=Chunk, if_exists="overwrite")
results = (
table.search(query_text)
.debug(True)
.filter({"meta.language": language})
.distance_threshold(distance_threshold)
.limit(query_limit)
.to_list()
)
Enable multimodal search experiences where users can find images using text descriptions or discover similar visual content effortlessly.
class Pet(TableModel):
__tablename__ = "pets"
id: int = Field(primary_key=True)
breed: str = Field()
image_uri: str = Field()
image_name: str = Field()
image_vec: Optional[List[float]] = embed_fn.VectorField(
distance_metric=DistanceMetric.L2,
source_field="image_uri",
source_type="image",
)
results = (
table.search(query="fluffy orange cat")
.distance_metric(DistanceMetric.L2)
.limit(limit)
.to_list()
)
Get the best of both worlds by merging traditional full-text search with modern vector similarity for comprehensive, accurate results.
# Define table schema
class Document(TableModel):
__tablename__ = "documents"
id: int = Field(primary_key=True)
text: str = FullTextField()
text_vec: list[float] = embed_fn.VectorField(
source_field="text",
)
meta: dict = Field(sa_type=JSON)
query = (
table.search(query_text, search_type="hybrid")
.distance_threshold(0.8)
.fusion(method="rrf")
.limit(limit)
)
Transform your text, images, and documents into searchable vectors without manual preprocessing or complex embedding pipeline setup.
# Define embedding function
embed_func = EmbeddingFunction(
model_name="tidbcloud_free/amazon/titan-embed-text-v2"
# No API key required for TiDB Cloud free models
)
class Chunk(TableModel):
__tablename__ = "chunks"
id: int = Field(primary_key=True)
text: str = Field(sa_type=TEXT)
text_vec: list[float] = embed_func.VectorField(source_field="text")
table = db.create_table(schema=Chunk, if_exists="overwrite")
# Insert sample data - embeddings generated automatically
table.bulk_insert([
Chunk(text="TiDB is a distributed database that supports OLTP, OLAP, HTAP and AI workloads."),
Chunk(text="PyTiDB is a Python library for developers to connect to TiDB."),
Chunk(text="LlamaIndex is a Python library for building AI-powered applications."),
])
Automatically embed product data and deliver personalized recommendations that update in real-time as your inventory changes, without complex pipelines.
class Product(TableModel):
__tablename__ = "products"
id: int = Field(primary_key=True)
name: str = Field(sa_type=TEXT)
description: str = Field(sa_type=TEXT)
description_vec: list[float] = embed_func.VectorField(
source_field="description"
)
category: str = Field(sa_type=TEXT)
price: float = Field()
table = db.create_table(schema=Product, if_exists="overwrite")
# App-1 is inserting strings and vectors are auto-generated in real-time
table.insert(Product(
name="Professional Basketball",
description="High-quality basketball for professional and amateur players",
category="Sports",
price=29.99
))
# App-2 is searching at once using semantic similarity with user preferences
recommendations = (
table.search(user_profile)
.distance_threshold(distance_threshold)
.limit(5)
.to_list()
)
Get hands-on with TiDB through our curated sandbox projects. Deploy complete applications in minutes and explore AI-powered database capabilities.

Learn to build AI apps with vector embeddings, RAG, hybrid search, and GraphRAG using TiDB Cloud Starter in 60 minutes.
Build intelligent apps that retrieve information and translate natural language to SQL using OpenAI models and TiDB Cloud Starter.
Create advanced AI agents with graph-enhanced retrieval and tool calling capabilities using OpenAI and TiDB Cloud Starter integration.
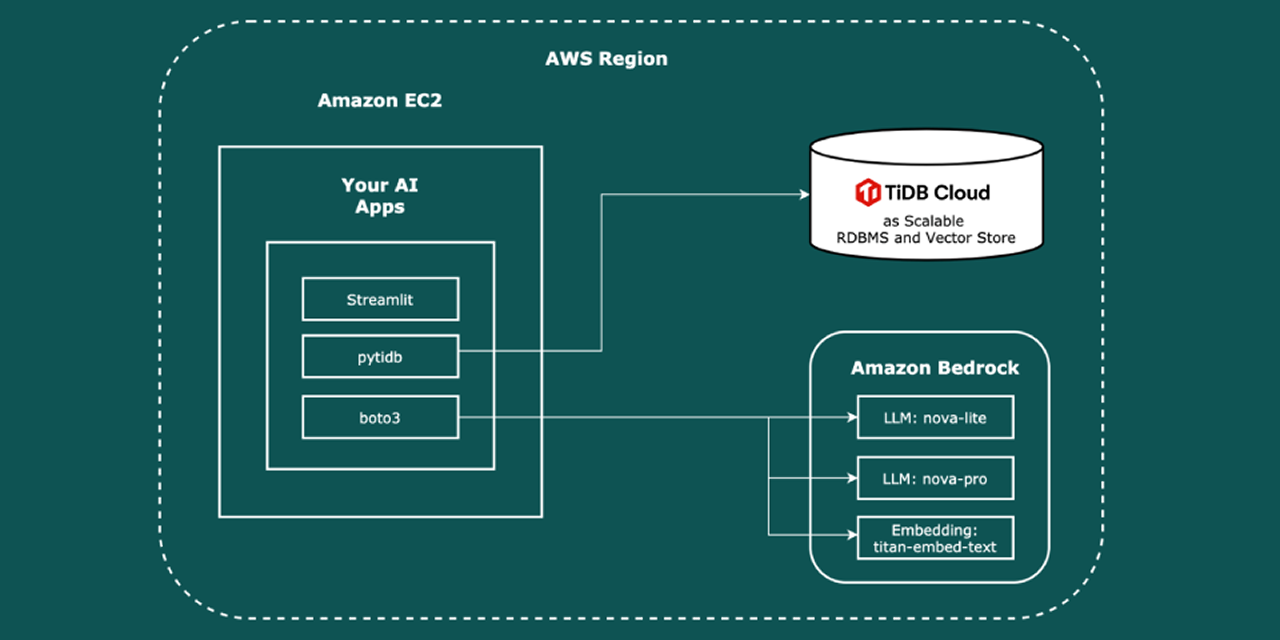
Develop AI applications with Amazon Bedrock models for retrieval-augmented generation and natural language query translation capabilities.
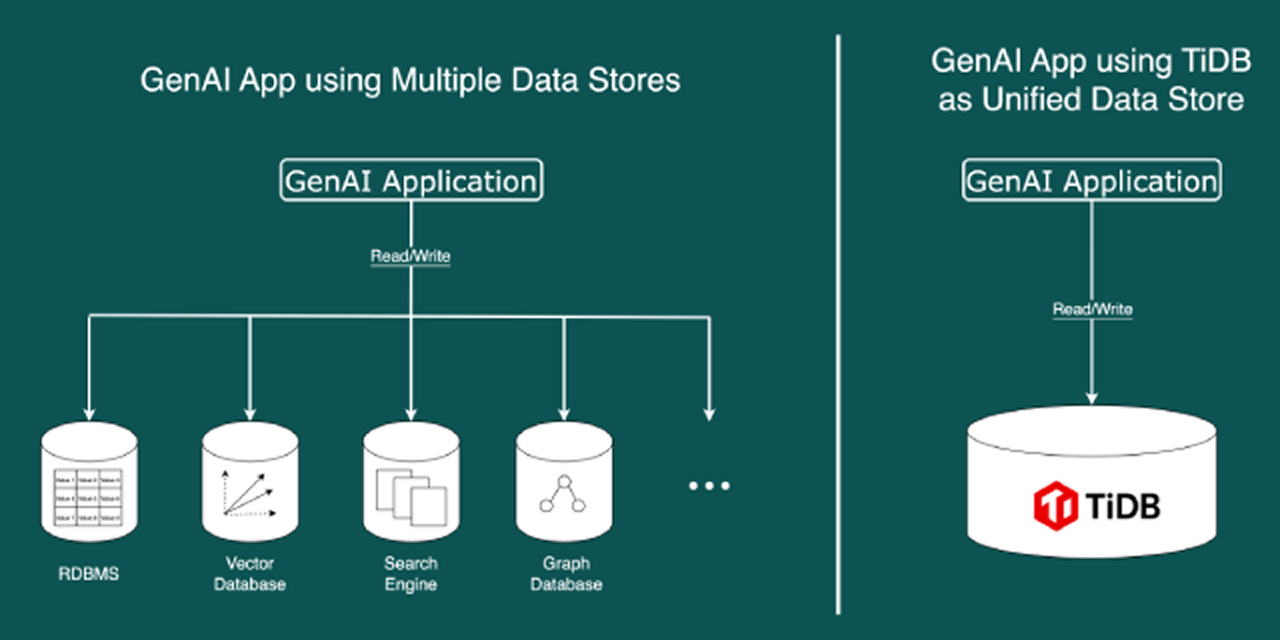
Experience the simplicity of using TiDB as single storage solution versus managing multiple databases for GenAI applications.
Compare multi-database complexity with TiDB’s unified approach for GenAI applications using OpenAI models and simplified development workflows.
Discover amazing projects built by our community. From developer tools to production applications, see what’s possible with TiDB’s AI-powered capabilities.
Web App
AI-powered RAG for healthcare management. Uses TiDB to organize documents, create smart schedules, and power family health chat.
DevOps
Serverless incident response system using TiDB vector search to ingest logs, triage incidents, and generate explainable reports.
Web App
Event-driven agentic system that automates workflows by finding similar past cases with TiDB vector search and generating appeal letters.
Web App
Agentic customer support platform using a custom .NET SDK for TiDB Vector Search to power intelligent ticket routing and real-time chat.
Web App
AI clinical decision support that analyzes medical images and uses TiDB for vector similarity search on cases to provide diagnostic guidance.
Connect with developers building the future with TiDB.

GitHub stars

Community Members
Contributors

Projects
Production-ready integrations for every stage of your AI pipeline.
Quick start: copy paste your Connection String into listed integrations.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()



Talk to Our AI Infrastructure Experts



