

※このブログは2022年10月19日に公開された英語ブログ「Disaster Recovery for Databases: How It Evolves over the Years」の拙訳です。
ディザスタリカバリ (DR) は、エンタープライズレベルのデータベースの中心となる機能です。データベースベンダーは常にDRの改善を目指しており、過去10年間で大きな革新を遂げてきました。
この記事では、クラウドベースの分散データベースにおけるDRと高可用性 (HA) の革新に重点を置いて、データベースのDRの簡単な歴史を紹介します。
>> IDC InfoBriefのダウンロード:デジタルファースト経済における競争 <<
HAおよびDRの測定
HAとDRの目標はシステムを運用レベルで稼働させ続けることです。どちらもシステム内の単一障害点を排除し、フェイルオーバーまたはリカバリプロセスを自動化しようとします。
高可用性は通常、システムが年間のうち稼働している時間の割合によって測定されます。ディザスタリカバリは、障害後に最小限のデータ損失でシステムをサービスに戻すことに重点を置いています。これは、復旧にかかる時間または目標復旧時間 (RTO) と、データボリュームの損失、または目標復旧時点 (RPO) の2つの指標によって測定されます。RPOとRTOは可能な限り短縮する必要があります。

HA/DRとその測定値
各障害はそれぞれ異なるため、フォールトトレランスターゲット (FTT) は、システムが存続できる障害の最大範囲を示します。一般的に使用されるFTTは地域レベルであり、障害の際には州や都市などの地理的領域に影響があることになります。
DRの簡単な歴史
データベースのDRテクノロジーは、バックアップと復元、アクティブ/パッシブ、マルチアクティブの3つの段階を経てきました。
バックアップと復元
初期のディザスタリカバリのでは、データベースはデータブロックとトランザクションログを利用して、完全データと増分データのバックアップを作成していました。障害が発生した場合、データベースはバックアップログとアプリケーショントランザクションログから復元されていました。
近年では、パブリッククラウドデータベースサービスは、ストレージレプリケーションと従来のデータベースバックアップテクノロジーを組み合わせ、スナップショットに基づくリージョン間の自動リカバリバックアップを提供しています。この方法ではソースリージョンのデータベースからスナップショットを定期的に生成し、スナップショットファイルをレプリケート先リージョンにレプリケートします。ソースリージョンがクラッシュした場合、データベースはレプリケート先リージョンから復旧され、サービスは続行されます。このソリューションのRTOとRPOは数時間にも及ぶ可能性があるため、厳しい可用性要件がないアプリケーションに最適です。

バックアップと復元のDRアプローチ
アクティブ-パッシブDR
データベースクラスタの開発は第2段階へと進みます。クラスタの場合、マスターノードはデータの読み取りと書き込みを行います。1つ以上のバックアップノードがトランザクションログを受信して適用し、ある程度の遅延を伴って読み取り機能を提供します。

アクティブ-パッシブDR
このソリューションにはクラスタの概念が含まれますが、それでもモノリシックデータベースに基づいています。スケーラビリティは読み取り操作に限定されます。書き込みをスケーリングすることはできません。もちろん、先程の構成と比較して、RTOは数分に短縮されRPOは数秒に短縮されます。
クロスリージョンリードレプリカで論理レプリケーションを使用するAmazon Auroraは、このテクノロジーに基づいて構築された初期のクラウドデータベースサービスの1つです。

クロスリージョンリードレプリカを使用したAurora論理レプリケーション
近年、Auroraはこの設計に基づいて構築され、グローバルデータベースサービスを提供しています。このサービスでは、ストレージレプリケーションテクノロジを使用して、ソースリージョンからターゲットリージョンにデータを非同期的にレプリケートします。ソースリージョンがダウンした場合、サービスはすぐにバックアップクラスタにフェールオーバーできます。RTOは数分に短縮でき、RPOは1秒未満です。
マルチアクティブディザスタリカバリ
マルチアクティブディザスタリカバリでは、データベースは同じデータを持っている読み取りおよび書き込み可能なサービスノードを少なくとも3つ提供し、データベースはワークロードに基づいてスケールアウトまたはスケールインできます。これは、データベースのパフォーマンスの向上、待機時間の短縮、可用性の向上、弾力性のあるスケーラビリティ、および弾力性を必要とする、広範なインターネット規模のアプリケーションに要求される機能です。
マルチアクティブ性は、1つまたは複数の列に基づいてデータを共有する従来のシャーディングデータベースによって形作られました。シャーディングソリューションは、トランザクションログのレプリケーションによってDRを実現します。たとえば、Googleはかつて非常に大規模なMySQLシャーディングシステムを維持していました。このソリューションはある程度のスケーラビリティを提供しますが、シャードが増加してもディザスタリカバリ機能を向上させることはできません。性能が大幅に低下し、メンテナンスコストが高騰します。したがって、シャーディングはマルチアクティブ性のための過渡的なソリューションと言えます。
近年、RaftまたはPaxosコンセンサスプロトコルに基づくシェアードナッシングデータベースが急速に開発されました。それらは上記のスケーラビリティと可用性の課題を解決しました。マルチアクティブ時代のキープレーヤーには、TiDBとCockroachDBが含まれます。これらのデータベースは、DRテクノロジーとともに、レガシーデータベースとリレーショナルデータベースサービス (RDS) のほとんどを時代遅れにしています。
分散データベースを使用したマルチアクティブDR
分散データベースに適用されるマルチアクティブDRを見てみましょう。たとえば、TiDBはオープンソースで可用性の高い分散データベースです。各テーブルまたはパーティションをより小さなTiDBリージョンに分割し、TiDBリージョンのデータの複数のコピーを異なるTiKVノードに保存します。これはデータの冗長性と呼ばれます。TiDBはRaftコンセンサスプロトコルを採用しているため、データが変更されると、トランザクションログがデータコピーの過半数に同期された場合にのみトランザクションコミットが返されます。これによりデータベースのRPOが大幅に改善されます。実際、ほとんどの場合でRPOは0です。これによりデータの一貫性が確保されます。さらにTiDBのアーキテクチャは、ストレージエンジンとコンピューティングエンジンを分離しています。これにより、ユーザーはワークロードの変化に応じてTiDBノードとTiKVストレージノードをスケールインまたはスケールアウトできます。

TiDBのストレージアーキテクチャ
典型的なマルチリージョンDRソリューション
次の図は、TiDBが一般的なマルチリージョンのディザスタリカバリソリューションをどのように提供するかを示しています。

TiDBのマルチリージョンディザスタリカバリソリューション
これらはTiDB DRアーキテクチャの重要な用語です。
- TiDBリージョン:TiDBのスケジューリングおよびストレージユニット
- リージョン:2つのサイトまたは都市
- アベイラビリティーゾーン (AZ):独立したHAゾーン。ほとんどの場合AZはリージョン内で互いに近い2つのデータセンターまたは都市です。
- L: Raftグループのリーダーレプリカ
- F: Raftグループのフォロワーレプリカ
上の図では、各リージョンにデータのレプリカが1つ含まれています。これらは異なるAZに配置され、クラスタ全体が2つのリージョンにまたがっています。リージョン1は通常、読み取り要求と書き込み要求を処理します。リージョン2は、リージョン1で障害が発生した後のフェールオーバーに使用され、レイテンシーの影響を受けない読み取り負荷を処理することもできます。リージョン3は、リージョン1がダウンしている場合でもコンセンサスに達することができることを保証するレプリカです。一般的にこの構成は ”2-2-1” アーキテクチャと呼ばれます。このアーキテクチャはディザスタリカバリを保証するだけでなく、ビジネスにマルチアクティブ機能を提供します。このアーキテクチャでは、次のようになります。
- 最大のフォールトトレランスターゲットをリージョンレベルにすることが可能
- 書き込み性能が拡張可能
- RPOは0
- RTOは1分以下に設定可能
このアーキテクチャは多くの分散データベースベンダーから、ディザスタリカバリソリューションとしてユーザーによく推奨されています。たとえばCockroachDBは、リージョンレベルのディザスタリカバリを実現するために3-3-3構成を推奨しています。Spannerはマルチリージョン展開用の2-2-1構成を提供します。ただしこのソリューションでは、リージョン1と2が同時に使用できない場合の高可用性は保証されません。リージョン1が完全にダウンした後、リージョン2のいずれかのストレージ・ノードに問題があると、システムのパフォーマンスが低下し、データが失われる可能性があります。マルチリージョンレベルのFTT、または厳密なシステム応答時間が必要な場合でも、このソリューションをトランザクションログレプリケーションテクノロジーと組み合わせる必要があります。
更新データキャプチャによる強化されたマルチリージョンDR
TiCDCはTiDB用の増分データレプリケーションツールです。TiKVノード上のデータ更新を取得し、それらをダウンストリームシステムと同期します。TiCDCは、トランザクションログレプリケーションシステムと類似したアーキテクチャを備えていますが、よりスケーラブルであり、ディザスタリカバリシナリオでTiDBとうまく連携させることができます。
次の構成には2つのTiDBクラスタが含まれています。5レプリカのクラスタ1はリージョン1とリージョン2から構成されています。リージョン1には読み取りおよび書き込み操作を提供するための2つのレプリカが含まれ、リージョン2にはリージョン1で障害が発生した場合に迅速なフェイルオーバーを行うための2つのレプリカが含まれています。リージョン3には、Raftグループ内のクォーラムに到達するためのレプリカが1つ含まれています。リージョン3のクラスタ2はディザスタリカバリクラスタとして機能します。これには、リージョン1とリージョン2の両方で障害が発生した場合に迅速なフェイルオーバーを提供するために、3つのレプリカが含まれています。TiCDCは2つのクラスタ間のデータ変更の同期を行います。この拡張アーキテクチャは、2-2-1:1と呼ばれています。
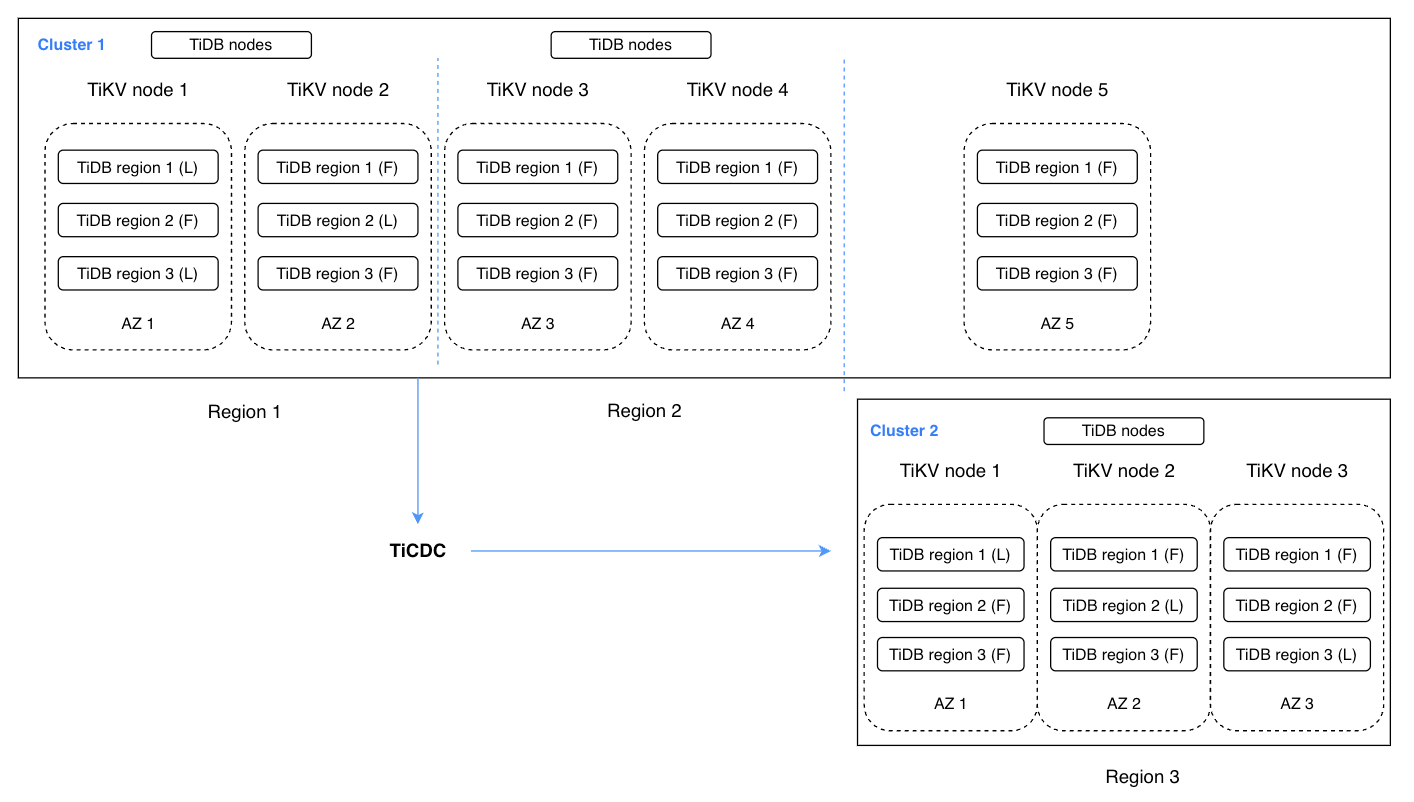
TiCDCを使用したTiDBマルチリージョンDR
この一見複雑な構成は、実際には高可用性を備えています。マルチリージョンレベルで最大のフォールトトレランス目標を達成でき、RPOは秒単位、RTOは分単位です。1つのリージョンの場合、完全に利用できない場合のRPOは0です。このソリューションは、分散データベースの利点と従来のデータベースのディザスタリカバリの経験を組み合わせたものです。そして、CockroahDBまたはSpannerによるマルチレプリカベースのディザスタリカバリソリューションと比較して、このソリューションはより実用的と言えます。
DRソリューションの比較
次の表はこの記事に記載されているDRソリューションの比較です。
| TCO | FTT | RPO | RTO | |
| Auroraによるスナップショットベースのクロスリージョンデータのバックアップと復元 | 低 | リージョン | 数時間 | 数時間 |
| クロスリージョンリードレプリカを使用したAurora論理レプリケーション | 中 | リージョン | 数秒 | 数分 |
| Auroraグローバルデータベース | 中 | リージョン | 1秒以下 | 数分 |
| TiDB (2-2-1) | 高 | リージョン | 1秒以下 | 数分 |
| TiDB (2-2-1:1) | 高 | マルチリージョン | 数秒 | 数分 |
| Cockroach DB (3-3-3) | より高い | リージョン | 1秒以下 | 数分 |
| Cockroach DB (3-3-3-3-3) | とても高い | マルチリージョン | 1秒以下 | 数分 |
まとめ
30年以上に渡り様々な開発段階を経てDRテクノロジーはマルチアクティブフェーズに突入しました。
TiDBのような分散データベースのシェアードナッシングアーキテクチャを使用することで、マルチレプリカテクノロジーとログレプリケーションツールが融合され、データベースDRをマルチリージョン時代に移行することができます。
データベースのディザスタリカバリについて詳しく知りたい場合は、ぜひご意見をお聞かせください。TwitterやSlackチャンネルからお気軽にお問い合わせください。
こちらも併せてお読みください。
Technical Paths to HTAP: GreenPlum and TiDB as Examples
HTAPシステムとしてのTiDBの実力は?HATtrickベンチマーク
クラウドストレージサービスでデータベースの地理的冗長性バックアップを簡素化する
編集者:Calvin Weng, Fendy Feng, Lijia Xu, Tom Dewan
Related Resources

Conference
May 19, 2026
TiDB SCaiLE Europe 2026: Why Engineers Building Agentic AI Should Be in Stockholm on 4 June

Conference
May 12, 2026
TiDB SCaiLE Europe 2026: Speaker Lineup and Session Preview

Product
May 11, 2026
From Preview to Production: TiDB Cloud Dedicated on Microsoft Azure is Now Generally Available
TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。