

著者: Jinpeng Zhang (TiDB Cloud エンジニア)
編集者: Calvin Weng, Tom Dewan
私はTiDBというHTAP (Hybrid Transactional and Analytical) データベースの開発者の一人です。最近、SIGMOD ‘22の論文「How Good is My HTAP System」を読みましたが、この論文ではTiDBを研究対象の1つとしています。著者の仕事ぶり、特にHTAPの性能を観察し、ベンチマークするために作成した方法論とツールにとても感謝しています。例えば、HATtrickベンチマークツールは、オンライントランザクション処理 (OLTP) とオンライン分析処理 (OLAP) のワークロードを同時に生成するだけでなく、HTAPシステム上のOLAPクエリの鮮度を評価することができます。
この論文では、TiDB上で実行される分析クエリは常に最新のデータを読み込むと結論付けています。これは、最新の情報に基づいて意思決定を行いたい企業にとって必須の機能です。
しかし、TiDBの性能テストの結果は、私たちの基準に達していませんでした。もっと詳しく知るために、私はHATtrickのテストを再現し、ここで考察してみました。この情報により、HTAP全般とTiDBについて、より深い洞察を得ることができたらと思います。
HATtrickの仕組み
著者のベンチマークツールであるHATtrickは、分析ワークロード用のStar Schema Benchmark (SSB) と、トランザクションワークロード用のTPCCベンチマークを組み合わせています。この設計により、HATtrickはトランザクションクエリと分析クエリを同時にデータベースに送信し、2つのワークロード間の性能分離を測定することができます。また、この論文では、トランザクションスループットと分析スループットを1つの図で示す「スループットフロンティア」という概念も紹介しています。スループットフロンティアは、トランザクション処理 (TP) と分析処理 (AP) 間の性能分離を追跡する直感的な方法です。
例えば、以下のフロンティア図では、赤い点線は”バウンディングボックス”、青い点線は”比例線”で表しています。緑の実線は、APクエリとTPクエリを同時に実行した場合のシステムの能力を示しています。緑の実線がバウンディングボックスに近いほど、TPとAPの性能分離が良好であることを示しています。

フロンティアで示される性能分離
HTAPの「鮮度」とは?
本論文では、HTAPシステムの「鮮度」についても定義しました。
HTAPシステムは、すべての分析クエリが最新バージョンの運用データに対して実行される場合、鮮度の高い分析を提供します。そうでない場合は、古い分析結果を提供することになります。
HATtrickベンチマークには、処理されたトランザクションクエリのバージョンを記録する鮮度テーブルが含まれています。ベンチマークはこのテーブルを使用して、分析クエリによって取得されたバージョンをチェックします。分析クエリが常に最新バージョンのデータを取得する場合、鮮度スコアは0sとなります。次のフロンティア・チャートでは、鮮度スコアは1.5sです。つまり、分析クエリは1.5秒前の古いデータしか取得できないことになります。

フロンティアチャートの鮮度スコア
TiDB上でHATtrickを再実行する
TiDBは分散型HTAPデータベースです。専用の行指向エンジンであるTiKVと、専用の列指向エンジンであるTiFlashを持っています。TiDBオプティマイザは、トランザクションクエリをTiKVに、分析クエリをTiFlashに自動的にルーティングします。理論的には、TiDB、TiKV、TiFlashの間でリソースの競合がなければ、2種類のクエリの間で良好な性能分離が行われます。
また、TiDBはストレージとコンピューティングを分離する分散アーキテクチャを採用しています。これにより、ユーザーは必要に応じてTiDBインスタンスを追加または削除することで、APまたはTPのスループットをスケーリングすることができます。

TiDBのアーキテクチャ
HATtrickを使った再テストでは、以下の点に注目しました。
- HTAPにおけるTPとAPの性能分離
- TPとAPのスケーラビリティ
TPとAPの性能分離をベンチマークする
HATtrickのスケールファクター100のテストを、より新しいTiDB構成で再実行しました:
- ソフトウェアのバージョン:TiDB 6.1
- CPU:2.4Ghz Intel® Xeon® Silver 4214R CPU、物理コア数24
- メモリ:128GB RAM
- ハードドライブ:500GBソリッドステートドライブ(SSD)
- クラスタ:TiDBノード×1、TiFlashノード×1、TiKVノード×3
- データセット:59GB
この構成をTiDB 1xと呼ぶことにしました。
次のフロンティアチャートは、私たちの結果を示しています。TP/APのスループットを示す緑の実線は、バウンディングボックスにかなり近い値になっています。これは、2種類のクエリ間の干渉がほとんどなく、すべての分析クエリが最新のトランザクションデータを取得できることを意味します。この結果は、TiDBのデュアルエンジン設計にマッチしています。TiDBは、トランザクションクエリと分析クエリ間の性能分離が優れていると結論付けることができます。

TiDB性能分離のHATtrickベンチマーク結果
TiDBの水平スケーラビリティをベンチマークする
このテストでは、TiDB-1xの構成を更新しています。新しいTiDBサーバと新しいTiFlashサーバを追加し、既存のTiKVサーバにさらに3つのTiKVインスタンスをデプロイしています。この構成をTiDB-2xと呼びました。

水平スケーラビリティテストに向けたTiDBのスケーリング
ホットスポットの問題を緩和する
分散システムにはしばしばホットスポットが存在し、これがパフォーマンスを低下させることがあります。最適なパフォーマンスを得るためには、本番環境でもテストでも、この問題を緩和することが常に必要です。このベンチマークを最初に実行したとき、ホットスポット問題に遭遇しました。オリジナルのHATtrickベンチマークとは異なり、ホットスポットを軽減するためにいくつかの変更を加えました。このベンチマークではテーブル行のホットスポットを回避するために
shard_row_id_bitsを使用しました。unique key + tidb_shardで、プライマリーキーの代わりにインデックスにホットスポットが発生しないようにしました。
ホットスポットを修正した後は、以下のヒートマップに示すように、書き込みが均等に行われるようになりました。

TiDB上で緩和されたホットスポット (TiDB Dashboardで生成)
フロンティアでTiDBのスケーラビリティを検証する
スケーラビリティを示すために、TiDB-1xとTiDB-2x構成の結果を同じフロンティアチャートで比較しました。このチャートでは、TiDB-2xの最大トランザクションQPSと最大分析QPSの両方が、TiDB-1xの2倍であることが示されています。このベンチマークでは、AP、TPともに必要に応じてノードを追加することでTiDBの性能が水平方向にスケーリングされることがわかります。比較として、同じ構成でPostgreSQLのHATtrickベンチマークテストも実施しました。
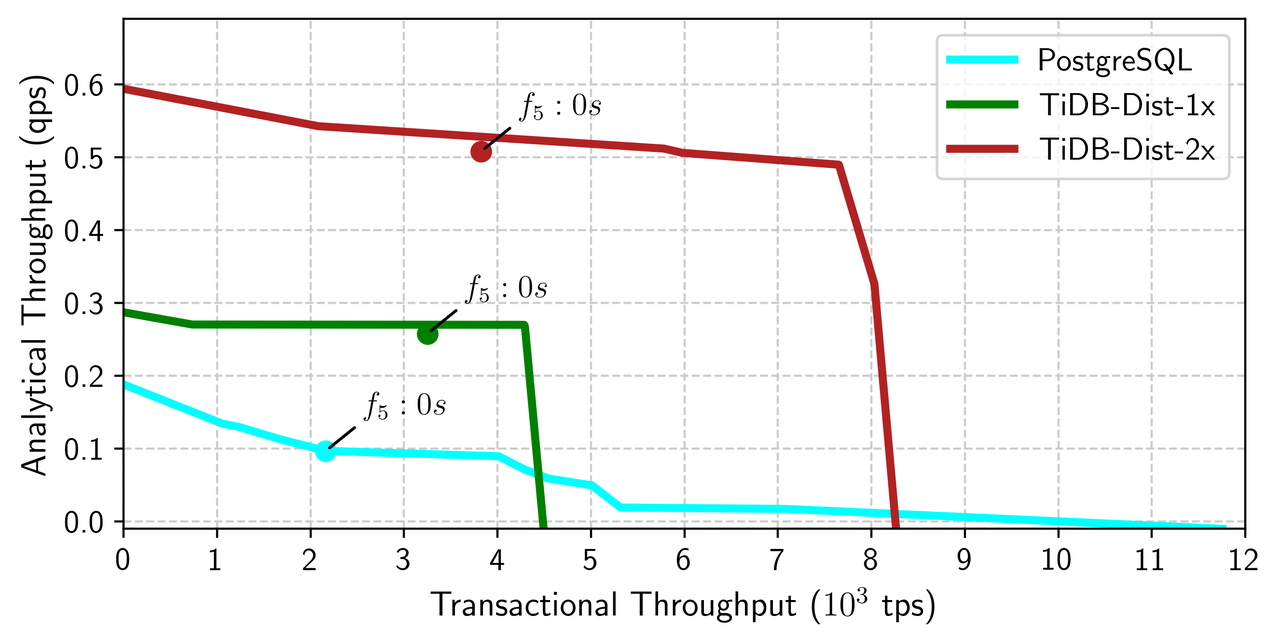
TiDBの性能は水平方向のスケーラビリティに優れている
まとめ
HATtrickを用いたSF100ベンチマークにより、HTAPデータベースとしてのTiDBの能力が検証されました。
- 分析クエリは、常にTiDBの最新データを読み込むことができます。
- TiDBのデュアルストレージエンジンアーキテクチャにより、分析クエリとトランザクションクエリ間の性能分離が非常に優れています。
- TiDBは、ストレージとコンピューティングのアーキテクチャが分離されているため、分析ワークロードとトランザクションワークロードの両方のスループットを水平方向にスケーリングすることが可能です。
また、我々のテストプロセスと結果は、HATtrickが学界とビジネスの両方に適用可能な実用的なベンチマーク手法であることを立証しています。この論文の著者に感謝するとともに、彼らが今後行うHTAP関連の研究に期待したいと思います。一方、HATtrickを使ってTiDBデータベースのベンチマークを行った方は、ぜひその結果を私たちと共有してください。また、私たちのSlackやTiDB Internalsに参加して議論することも可能です。
Related Resources

Conference
May 19, 2026
TiDB SCaiLE Europe 2026: Why Engineers Building Agentic AI Should Be in Stockholm on 4 June

Conference
May 12, 2026
TiDB SCaiLE Europe 2026: Speaker Lineup and Session Preview

Thought Leadership
May 7, 2026
What is a Context Platform? A New Pattern for AI Agents in Production
TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。