
This is the speech Edward Huang gave at Percona Live – Open Source Database Conference 2017.
The slides are here.
- Speaker introduction
- What would you do when…
- TiDB Project – Goal
- Architecture
- Storage Stack
- Safe Split
- Scale Out
- ACID Transaction
- Distributed SQL
- TiDB SQL Layer Overview
- What Happens behind a query
- Distributed Join (HashJoin)
- Tools Matter
- Use Cases
- Sysbench
- Roadmap
Speaker introduction
As one of the three co-founders of PingCAP, I feel honored that PingCAP was once again invited to the Percona Live Conference.
Last year, our CEO Max Liu has introduced TiDB and TiKV to the public. He mainly focused on how we build TiDB and also formulated a future plan of our projects. This time, I’ll draw a detailed picture of TiDB to help you understand how it works.
First of all, I’d like to introduce myself. My name is Edward Huang, an infrastructure software engineer and the CTO of PingCAP.
Up to now, I have worked on three projects, Codis, a proxy-based redis cluster solution which is very popular in China , TiDB and TiKV, a NewSQL database, our topic today. All of them are open source and many people benefit from them, especially in China. And I prefer languages such as Golang, Python, and Rust. By the way, we are using Golang and Rust in our projects (TiDB is written in Go and TiKV uses Rust).
What would you do when…
And first of all I want to ask a question: what would you do when your RDBMS is becoming the bottleneck of your application? Maybe most of you guys may have experienced the following situations. In the old days, all you can do is to either refactor your application or use database middleware, something like mysql proxy. But once you decide to use the sharding solution, you will never get rid of sharding key and say goodbye to complex query as it’s a one-way path.
So how to scale your relational database is a pain point of the entire industry.
TiDB goal
And there comes TiDB, when we were designing TiDB, we want to achieve the following goals:
-
Make sharding and data movement transparent to users so that developers can focus on application development.
-
100% OLTP and 80% OLAP support. TiDB aims to be a hybrid database that supports both OLTP and OLAP. This is feasible because TiDB supports transactions and has our own full featured distributed SQL engine (including parser, optimizer and query executor).
-
TiDB has to be compatible with the MySQL protocol, by implementing MySQL grammars and the network protocol. In this way, our users can reuse many MySQL tools and greatly reduce the migration costs.
-
Twenty-four/Seven availability, even in case of datacenter outages. Thanks to the Raft consensus algorithm, TiDB can ensure the data consistency and availability all the time.
-
Open source, of course.
During the first section, I’ll talk about the technical overview of TiDB and TiKV project, including the storage layer, a brief walk through our distributed sql engine, and some tools for community users to migrate from MySQL to TiDB and vice versa. Secondly, I’ll introduce some real world cases and benchmarks. We got several users in China, which have already used TiDB in production for over 3 months. And in the end, I’ll do a quick demo of setting up a TiDB-cluster and have some queries on it.
Architecture
Below shows the TiDB architecture.
In this diagram, there are three components: the SQL layer, which is TiDB; the distributed storage layer, which is TiKV; and Placement Driver, aka PD.
These three components communicate with each other through gRPC.
-
TiDB server is stateless. It doesn’t store data and it is for computing only. It translates user’s SQL statement and generates the query plan, which presents as the rpc calls of TiKV.
-
TiKV is a distributed key value database, acting as the underlying storage layer of TiDB and it’s the place where data is actually stored. This layer uses Raft consensus algorithm to replicate data and guarantee data safety. And TiKV also implements a distributed computing mechanism so that the sql layer would be able to do something like predicate push down or aggregate push down.
-
Placement Driver is the managing component of the entire cluster and it stores the metadata, handles timestamp allocation request for ACID transaction, just like the TrueTime for Spanner, but we don’t have the hardware. What’s more, it’s controlling the data movement for dynamic workload balance and failover.
Storage stack
Let’s dive deep into the storage stack of TiKV.
As mentioned earlier, TiKV is the underlying storage layer where data is actually stored. More specifically, data is stored in RocksDB locally, which is the bottom layer of the TiKV architecture as you can see from this diagram. On top of RocksDB, we build a Raft layer.
So what is Raft? Raft is a consensus algorithm that equals to Multi-Paxos in fault-tolerance and performance. It has several key features such as leader election, auto failover and membership changes. And Raft ensures that data is safely replicated. We have exposed the Raw Key Value API at this layer. If you want a scalable, highly available kv database, and don’t care about cross-row ACID transaction, you can use the Raw Key Value API for higher performance.
The middle layer is MVCC, Multiversion concurrency control. The top two layers are transaction and grpc API. The API here is the transactional KV API.
TiKV is written in Rust and the reason is that the storage layer is performance-critical and stability is first-class citizen of course. We only got c/c++ in the past, and now we have rust. Rust is great for infrastructure system software like database, operation system… Without any extra cost for GC, runtime and high performance. Another great thing is that Rust does a lot of innovation works to prevent memory leaks and data race, which means a lot to us.
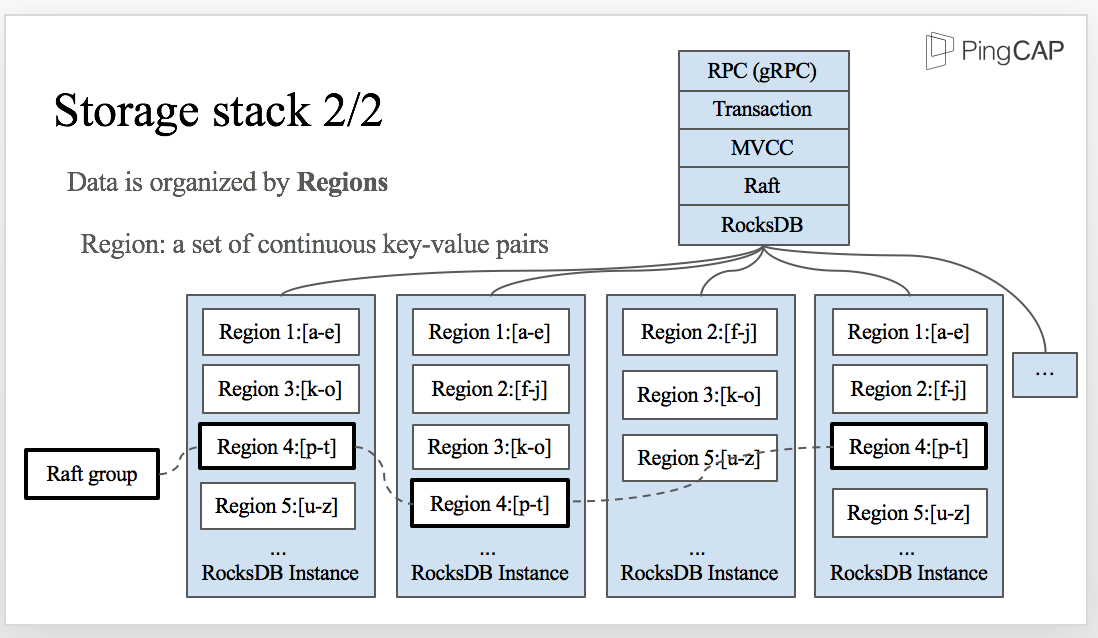
Now we know that the actual data is stored in RocksDB. But how exactly is data organized inside of the RocksDB instances? The answer is by Regions.
Region is a set of continuous key-value pairs in byte-order.
Safe split
Let’s take a look at the diagram here: The data is split into a set of continuous key-value pairs which we name them from a to z. Region 1 stores “a” to “e”, Region 2 “f” to “j”, Region 3 “k” to “o”, etc. As region is a logical concept, all the regions in a physical node share the same rocksdb instance.
In each RocksDB instance, as I just mentioned, there are several regions and each region is replicated to other instances by Raft. The replicas of the same Region, Region 4 for example, make a Raft group.
The metadata of the raft groups is stored in Placement Driver, and of course, placement driver is a cluster, replicates the metadata by Raft, too.
In TiKV, we adopt a multi-raft model. What’s multi-raft? It’s a way to split and merge regions dynamically, and of course, safely. We name this approach “safe split/merge”.
For example, Region 1 from “a” to “e” is safely split into Region 1.1 “a” to “c” and Region 1.2 “d” to “e”, we need to guarantee no data is lost during the split.
This explains how one Region is split, but how about its replicas on other nodes? Let me show you the process.
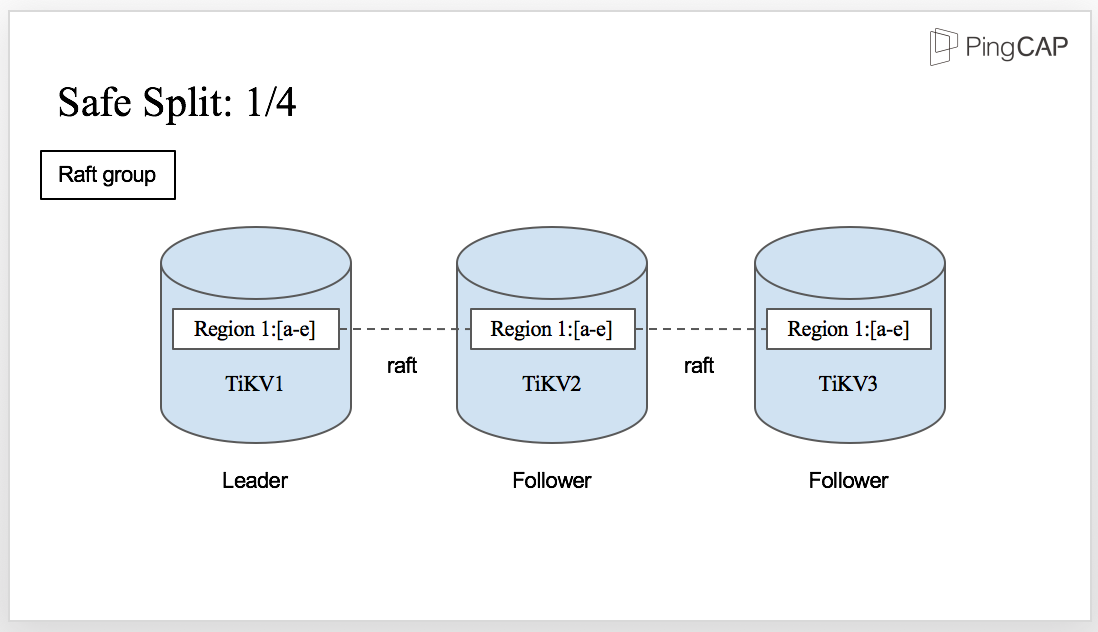
This is the initial state for Region 1. You can see there is a Raft group with three TiKV nodes. Region 1 on TiKV1 is the Leader and the other two replicas are the followers.
However, there comes a situation that there are too much data in Region 1 and it needs to be split.
It’s easy if there is only one Region 1, but in this case, we have three replicas. How can all the replicas be split safely? The answer is also Raft. Let’s see how it works.
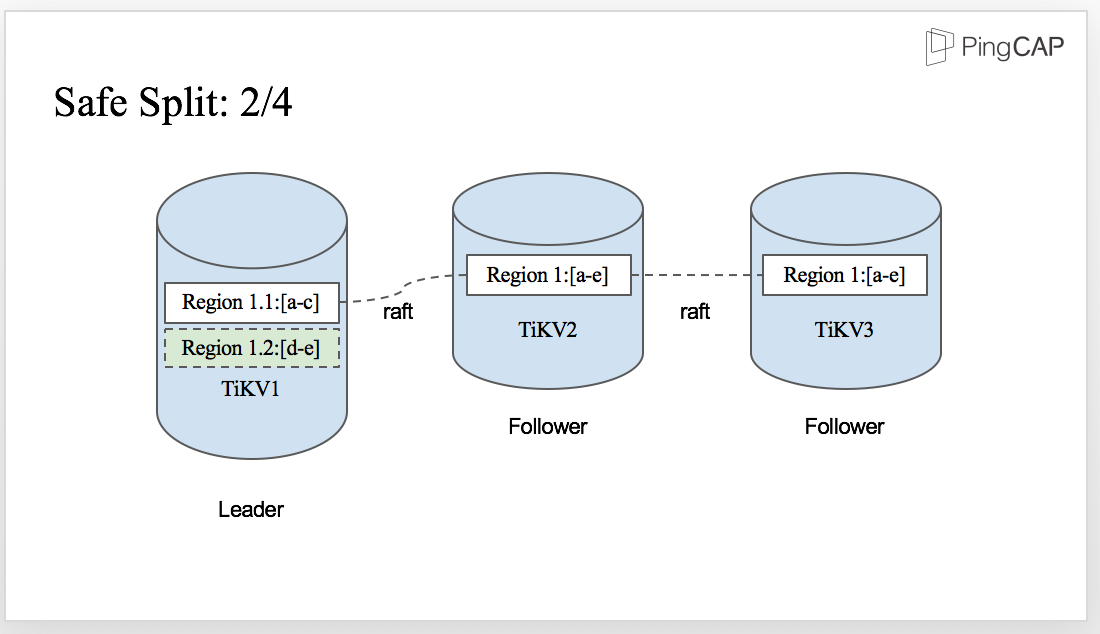
The split is initiated by the Leader, which means Region 1 is split to Region 1.1 and Region 1.2 firstly in the Leader as you can see from the diagram.
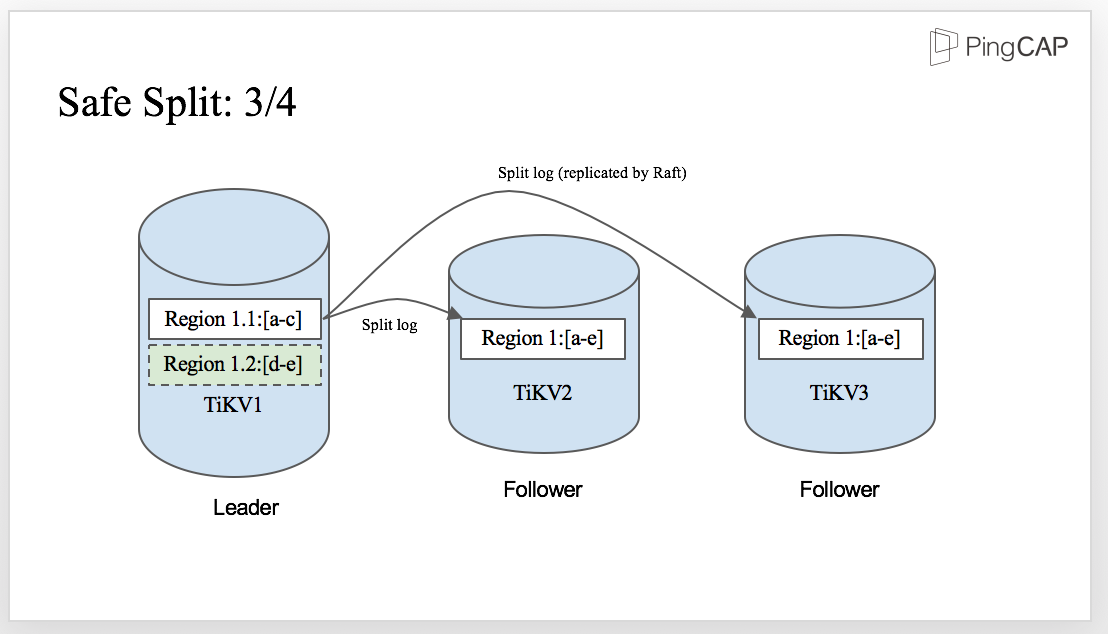
When the split-log is written to WAL in the Leader, it is replicated by Raft and sent to the followers. Then, the followers apply the split log, just like any other normal raft log.

And finally, once the split-log is committed, all the replicas in the Raft group are safely split into two regions on each TiKV node. There is no data lost in the process as the correctness of the split procedure is ensured by Raft.
Scale out
We’ve talked about split. Now let’s see how TiKV scales out. Our project is as scalable as NoSQL system, which means you can easily increase the capacity or balance the workload by adding more machines.

In this diagram, we have 4 physical nodes, namely Node A, Node B, Node C, and Node D. And we have 3 regions, Region 1, Region 2 and Region 3. We can see that there are 3 regions on Node A. Let’s say that Node A encountered a capacity problem, maybe disk is almost full.
To balance the data, we add a new node, Node E. The first step is to transfer the leadership from the replica of Region 1 on Node A to the replica on Node B.
Step 2, TiKV adds a Replica of Region 1 to Node E. Therefore, Region 1 contains 4 replicas temporary.
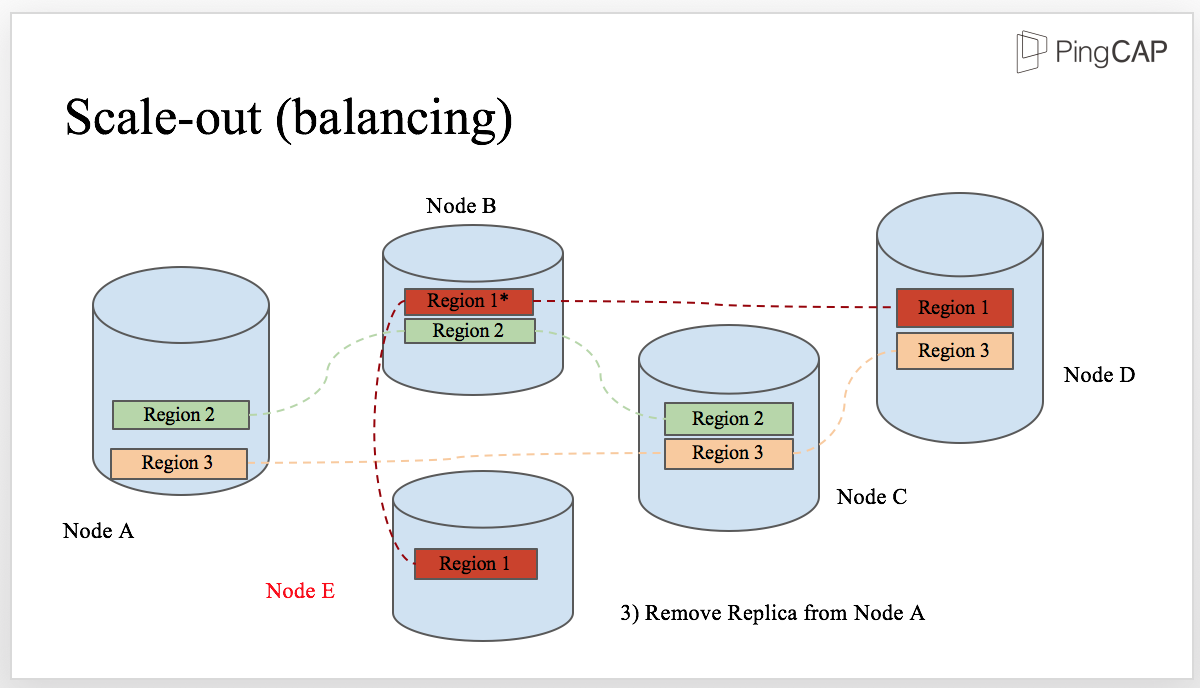
The final step, TiKV removes the replica of Region One from Node A. Now the data is balanced and the cluster scales out from 4 nodes to 5 nodes. In the process of scale-out, this data movement will occur in different regions. The result of the scheduling is that the number of regions is as equal as possible in every physical node.
This is how TiKV scales out.
ACID transaction
Our transaction model is inspired by Google’s Percolator. It’s mainly a decentralized 2-phase commit protocol with some practical optimizations. This model relies on a timestamp allocator to assign increasing timestamp for each transaction.
TiKV employs an optimistic transaction model and only locks data in the final 2 phase commit stage, which is the time that client call Commit() function. In order to deal with the lock problem when reading/writing data in the 2pc stage, TiKV adds a simple Scheduler layer in the storage node to queue locally before returning to the client for retry. In this way, the network overhead is reduced.
The default isolation level of TiKV is Repeatable Read (SI) and it exposes the lock API, which is used for implementing SSI (Serializable snapshot isolation), such as SELECT … FOR UPDATE in mysql, for the client.
Distributed SQL
We take the performance of TiDB very seriously. TiDB has a full-featured SQL layer. For some operations, for example, select count(*), there is no need for TiDB to get data from row to row first and then count. The quicker way is that TiDB pushes down these operations to the corresponding TiKV nodes, the TiKV nodes do the computing and then TiDB consolidates the final results.
Cost based optimizer, aka CBO, is to optimize a plan by calculating the query cost. This optimizer is very complex. There are two key problems: one is how to get the true distribution information of the data; the other is how to estimate the cost of a certain query plan based on this information.
Distributed join will be covered later.
TiDB SQL layer overview
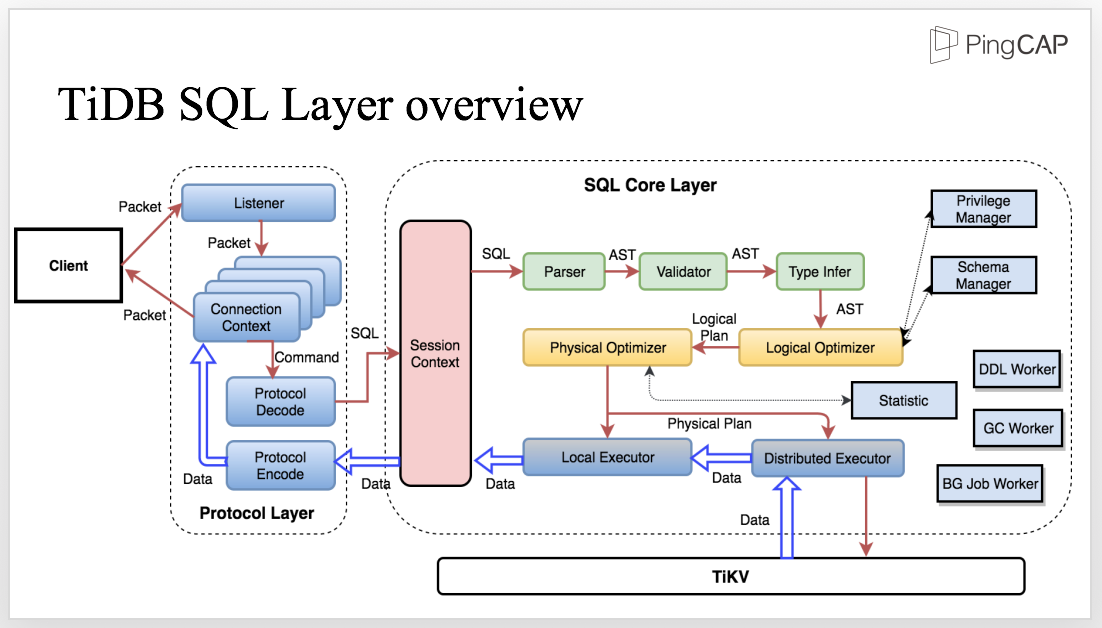
This diagram shows the architecture of the SQL layer. Let’s take a look and see how the process works.
The client sends SQL to the Protocol Layer. Within the life cycle of a connection, we need to maintain the connection context and decode the protocol to get the structured request which will be further processed in the SQL core Layer.
Inside the SQL core layer, we need to maintain the session context which includes all the related information, such as the variable of the session scope. Meanwhile, the session context is also the entrance to the SQL Layer. After the SQL statement enters the SQL layer, the parser parses the SQL statement into AST. The next step is to process the AST, including validation, name resolution, type infer, privilege management, etc.
Then comes the core layer of the SQL engine, the Optimizer. There are two optimizers, the logical optimizer and the physical optimizer. The first step is logical optimization which transfers each AST node into a logical plan and optimizes the SQL logic. Based on the logical plan, the Physical Optimizer makes the physical plan which is then executed by the distributed executor. Here, the optimizer is like a boss who makes plans, and the executor is like the employees who execute the plan and perform the RPC call. During the execution, interactions with the storage layer are inevitable, such as accessing data, computing, and so on.
There are also other crucial components like Privilege Manager, Schema Manager, DDL Worker, GC worker, BG Job Worker, just to name a few.
What Happens behind a query
We have talked about the process. Let’s see an example to show what’s going on behind a query. Assuming we have a schema with two fields and an index. Now we need to run the following query: SELECT COUNT(c1) FROM t WHERE c1 > 10 AND c2 = ‘percona’;
This is a very simple statement and it’s easy to make the logical plan and the physical plan. Note that when it comes to the physical plan, you should calculate the query cost of the plan, which is the cost-based optimization that you’ve been quite familiar with.
The plan works well in a stand-alone database, but what happens in a distributed database that needs distributed computing in most cases? Let’s see the next slide to show how the SQL statement is executed in TiDB.
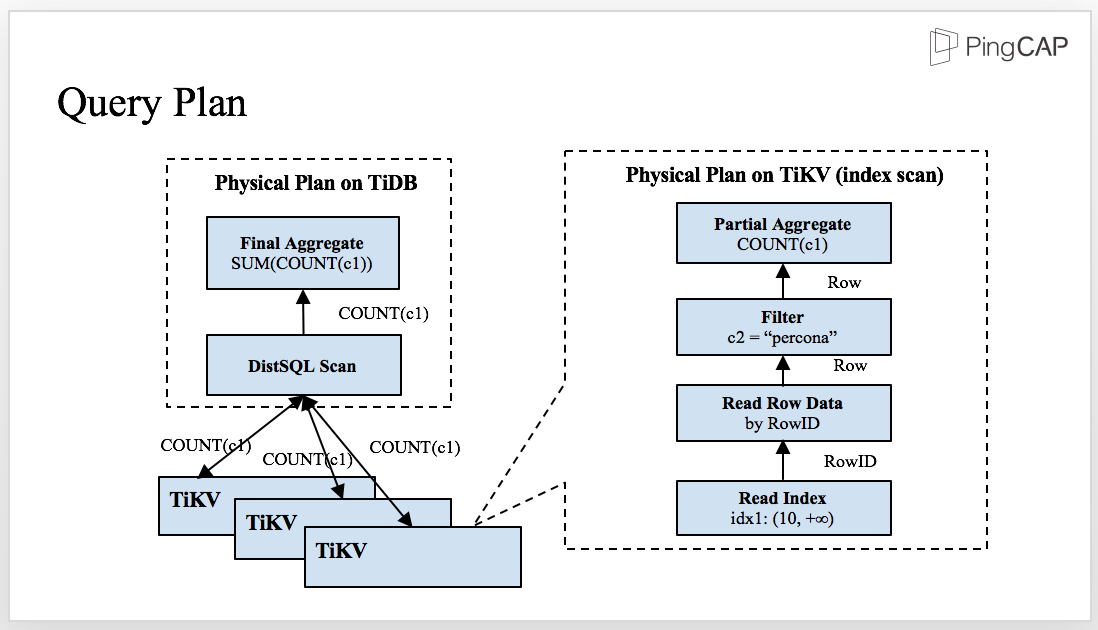
This is the physical plan of the SQL statement. The SQL layer and the storage layer, TiKV, work together. Some predicates and aggregators is pushed down to TiKV and then sent the partial result back to TiDB for final aggregation.
There are several advantages in this approach: First, there are more nodes involved in the computing and therefore, the computing becomes faster. Second, the network transmission is greatly reduced because after filtering and aggregation, the computing can easily access the data because the data is close.
Distributed join (HashJoin)
Now, let’s see a little more complex query: we have two tables, left and right. Now I write a simple join query, let’s see what happens behind a join.
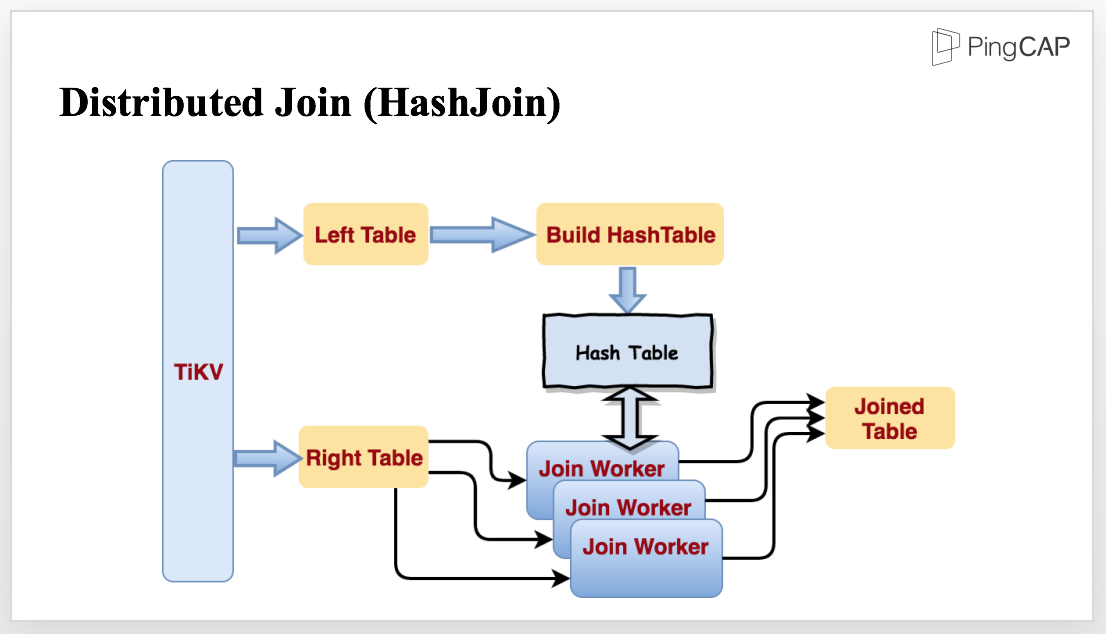
For this query, optimizer may choose hashjoin, because HashJoin performs well in processing small and medium sized data. We have implemented the operator and optimized it for parallel data processing, and make it streaming.
To join the tables mentioned in the previous query, TiKV reads the tables in parallel. When reading the smaller table, TiKV starts to build a Hash Table in memory. When reading the bigger table, the data is sent to several Join Workers. When the Hash Table is finished, all the Join Workers will be notified to start Join in stream and output the Joined Table.
TiDB’s SQL layer currently supports 3 kinds of distributed join type, hashjoin / sort merge join (when the optimizer thinks even the smallest table is too large to fit in memory and the predicates contains indexed column, optimizer would choose sort merge join) / index lookup join.
Tools matter
To help users exploit the best part of TiDB, we have prepared the following tools: Syncer, TiDB Binlog, Mydumper/MyLoader(Loader).
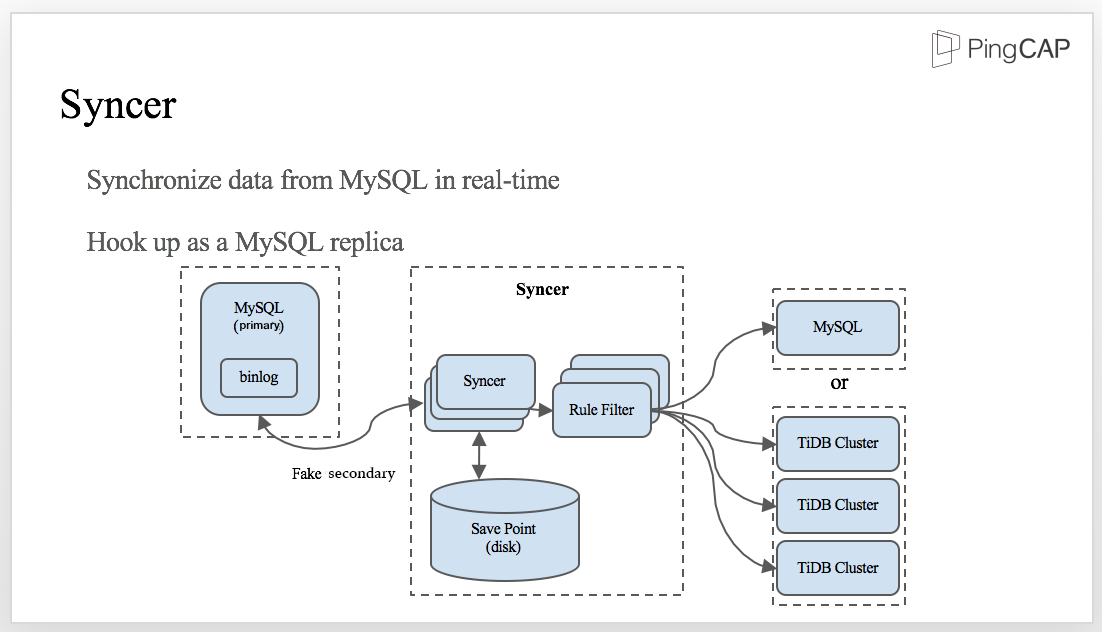
Syncer is a tool to synchronize data from MySQL in real time.
It is hook up as a MySQL replica: we have a MySQL primary with binlog enabled and Syncer acts as a fake secondary. At the very beginning, Syncer gets the position of the current binlog which is the initial synchronizing position. When new data is written into MySQL, Syncer obtains the binlog from the primary, synchronizes the data to the Save Point in the disk, and then applies the rule filter to send data to either MySQL or TiDB cluster.
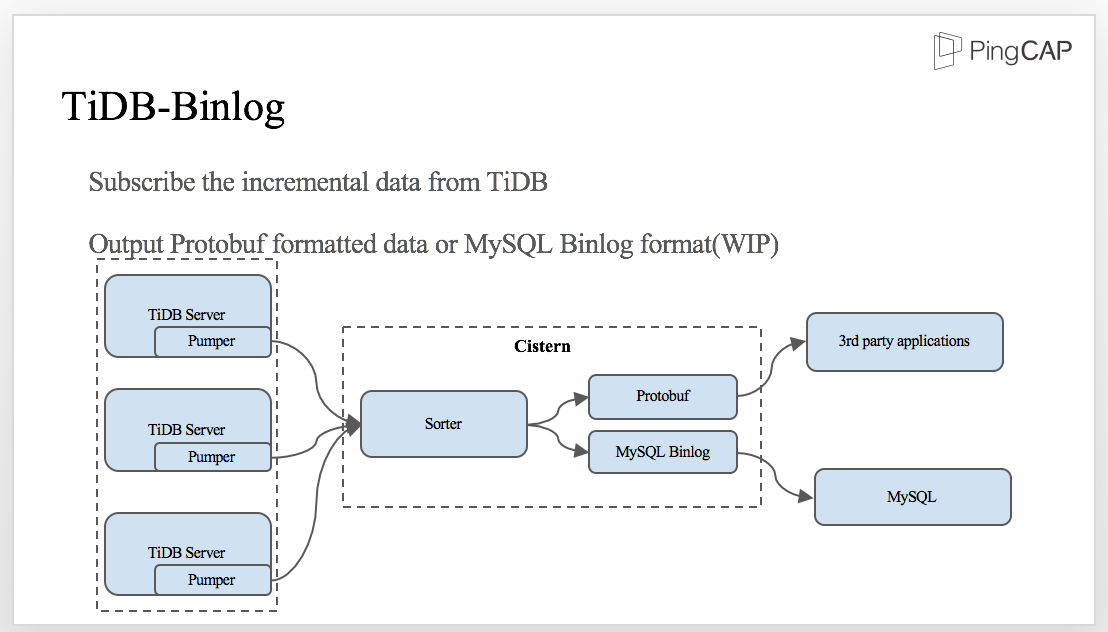
On the other hand, TiDB can output binlogs too. We build TiDB Binlog toolset to make it possible for 3rd party applications synchronize data from TiDB cluster. As TiDB-server is distributed, binlog pumper should be deployed in every TiDB-server instance and send it to a component we called ‘Cistern’. Cistern will sort the transactions by TransactionID (aka. timestamp) in a short period of time, and output as protobuf for downstream application.
For data migration, we don’t have our own tool. We use Mydumper/Loader for data backup and restore in parallel. you can use Mydumper to export data from MySQL and MyLoader to import the data into TiDB.
Use cases
Currently, there are about 20 customers using our products in production environments and more than 200 PoC users contacting us or trying our products.
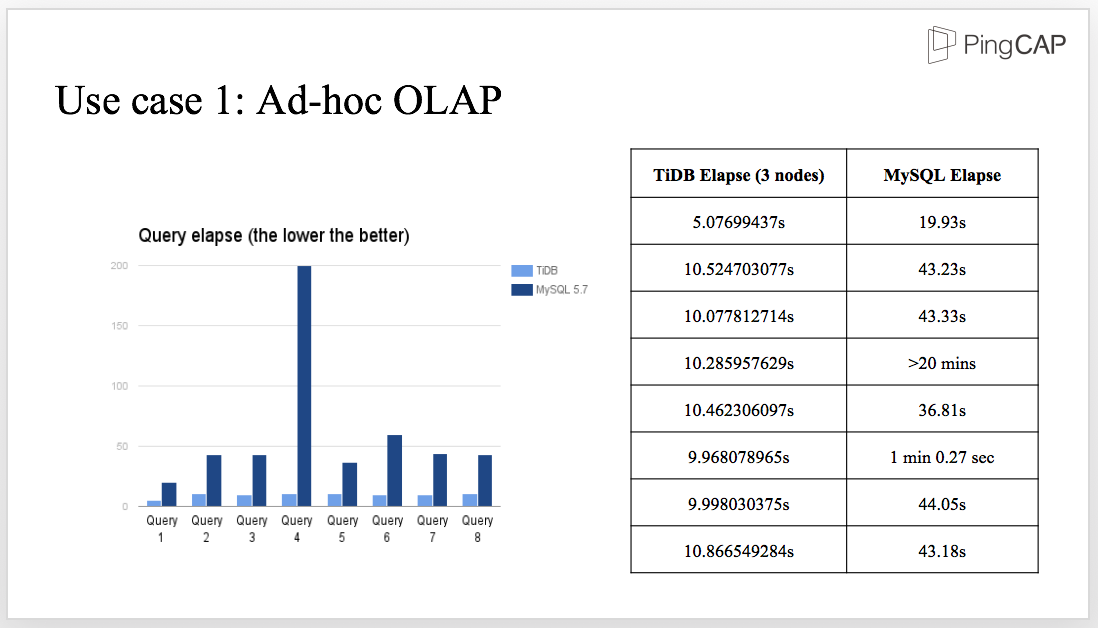
Let’s compare the query elapse between TiDB and MySQL. As you can see from the above diagram, for the ad-hoc OLAP with 8 queries, the time that MySQL takes is almost 4 times more than that of a 3-node TiDB.
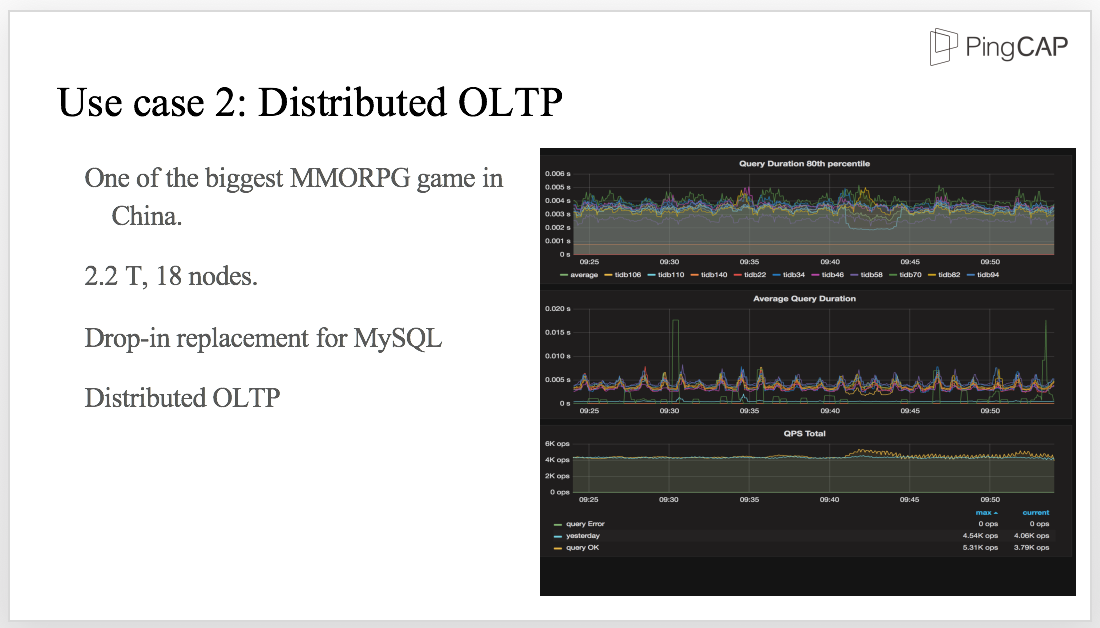
Another customer is using TiDB as the drop-in replacement for MySQL for OLTP workload. You can see from the graph that the latency of 80% query is lower than 3ms and the average query latency is about 5 ms. Besides, it is quite stable.
Sysbench
Let’s see some Sysbench results for Read and Insert in the next few slides. Here are the details of the system that we are using.

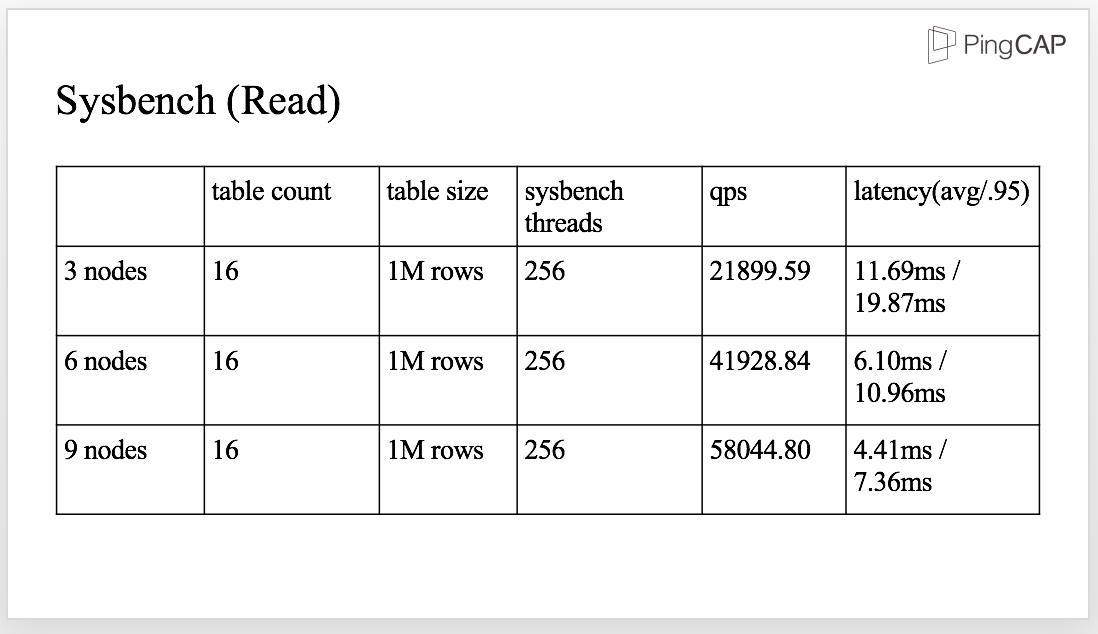
For Read, you can see that the more nodes, the higher the qps (Query per Second), and the lower the latency.
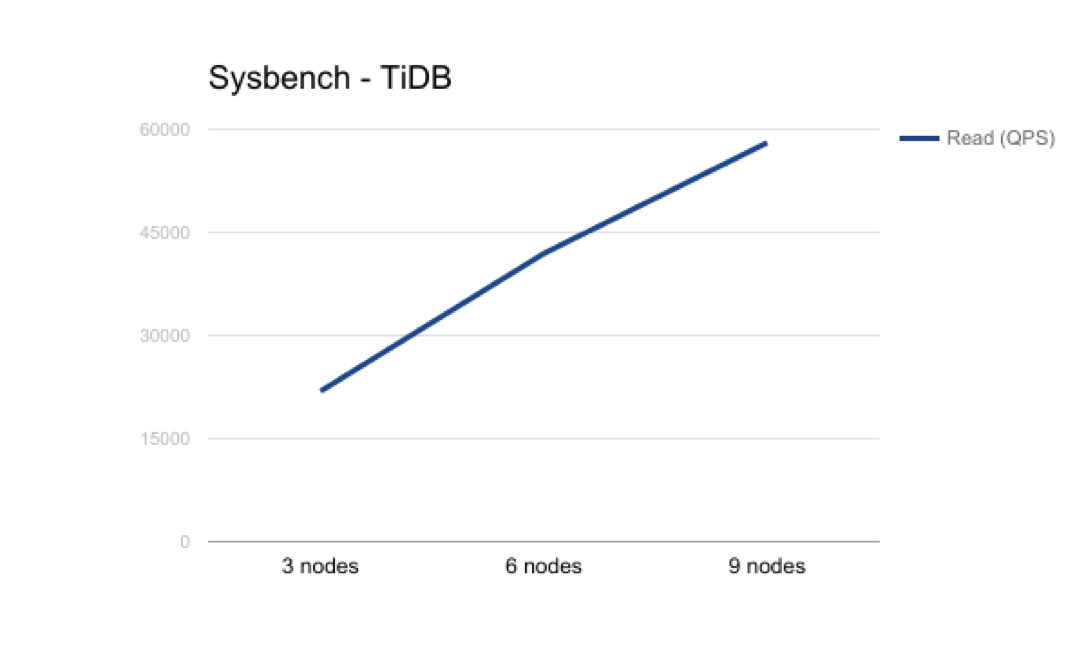
This diagram of Read qps shows the same result. The performance of read is improved significantly as the number of nodes grows.
For Insert, we have the same result as Read.
This is TiDB, SQL at Scale.
Roadmap
The final section of my speech is our roadmap to the future:
-
We are now working on TiSpark, a project integrates TiKV with SparkSQL.
-
We are still improving the Statistic collection framework & cost-based optimizer (CBO).
-
The json type and document store for TiDB has already been put on our agenda.
-
We are going to make TiDB integrate with Kubernetes, which makes it very easy to set up a large cluster.
Once again, we are honored to attend this conference and I hope that there will be more excellent databases. Thank you so much!



TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。