
TiDB 5.4 was officially released on February 15th. As the kick-off release for 2022, it continuously brings features and improvements that deliver:
- Performance optimizations and enhancements
- Functionality extensions for cloud environments
- Ease of use and maintenance
- New utility and configuration parameters
In this article, we will dive into these highlights. For more details of the release, refer to the Release Notes.
Performance optimizations and enhancements
TiDB 5.4 achieves the following major performance improvements:
- Formally supports Index Merge query optimization that enables query plans to utilize indexes on multiple columns for efficient conditional filtering. This significantly boosts query performance with stable response time and little system resource usage.
- Optimizes the performance of the TiFlash storage engine for analysis scenarios with large data volume and frequent reads and writes.
- Significantly improves the performance of TiDB Lightning in large-scale data replication scenarios.
Faster row-to-column store conversion for TiFlash
In Hybrid Transactional and Analytical Processing (HTAP) platforms and applications, data updates are accompanied by massive table scans. Storage engine performance could be a key factor for the stability and performance of the whole system. The HTAP architecture in TiDB separates transactional processing and analytical processing. The same data is automatically converted from row to column storage in the background to respond to Online Transactional Processing (OLTP) or Online Analytical Processing (OLAP) loads according to business needs.
TiDB 5.4 refactors the code architecture of the row-to-column conversion module in TiFlash. It simplifies redundant data structures and adopts CPU caching and vectorization-friendly data structures. The default configuration of TiFlash’s storage engine, DeltaTree, is optimized accordingly.
With the refactoring, the storage layer is significantly optimized in the conversion efficiency from TiKV “row” storage to TiFlash “column” storage format. This improves CPU efficiency during “row-to-column” conversion, which in turn allows more CPU resources to be ready for other computational tasks in high-load situations.
Write performance testing with the column storage engine confirms that the throughput increases by 60% to 90% under different concurrency scenarios.
Introducing Index Merge
Some queries require multiple columns to be scanned at the same time. However, with previous versions of TiDB, you could only select an index on a single column, or a composite column index on multiple columns, for queries with range scans. This affected overall performance even though all columns were already indexed. TiDB 5.4 formally introduces Index Merge, which lets the optimizer simultaneously select multiple indexes on multiple columns. This significantly reduces lookups in query processing and eliminates performance bottlenecks in these scenarios.
Note that Index Merge is not suitable for all application scenarios. For detailed information, please refer to the Release Notes.
The best uses for Index Merge
IndexMergeReader could perform lookup queries using multiple indexes, which could improve query performance especially in the following sample scenario:
SELECT * FROM t1 WHERE c1 < 10 OR c2 < 100;In the above query, there are indexes on both c1 and c2. The query uses an OR operator, so it’s not possible to query data using the c1 or c2 indexes alone. A full table scan is required. However, with Index Merge, SQL commands can first get row_ids for c1 and c2 separately, then use the UNION operation to get the actual rows from the main table.
We will use a testing scenario to show the best ways to use of Index Merge. The data source is TPC-H SF 1. The lineitem table has 600,000 rows. The query will get the rows where price is 930, or orderkey is 10000 with a specified comment string:
SELECT l_partkey, l_orderkeyFROM lineitemWHERE ( l_extendedprice = 930OR l_orderkey = 10000 AND Substring(Lpad(l_comment, 'b', 100), 50, 1) = 'b' )AND EXISTS(SELECT 1FROM partWHERE l_partkey = p_partkey)
When Index Merge is not used, the query execution time is 3.38 s.

Query without Index Merge
When Index Merge is used, the execution time is 8.3 ms. That is 400 times faster than without Index Merge.

Query with Index Merge
In appropriate Index Merge scenarios, CPU and memory consumption is basically negligible because most rows have been filtered out in TiKV.
In the query without Index Merge, since the filtering conditions could not be pushed down, all the rows must be passed to TiDB for selection. Therefore, the memory consumption is much larger. For example, 10 concurrent queries require a memory of 2 GB for table scan through 600,000 rows of data.
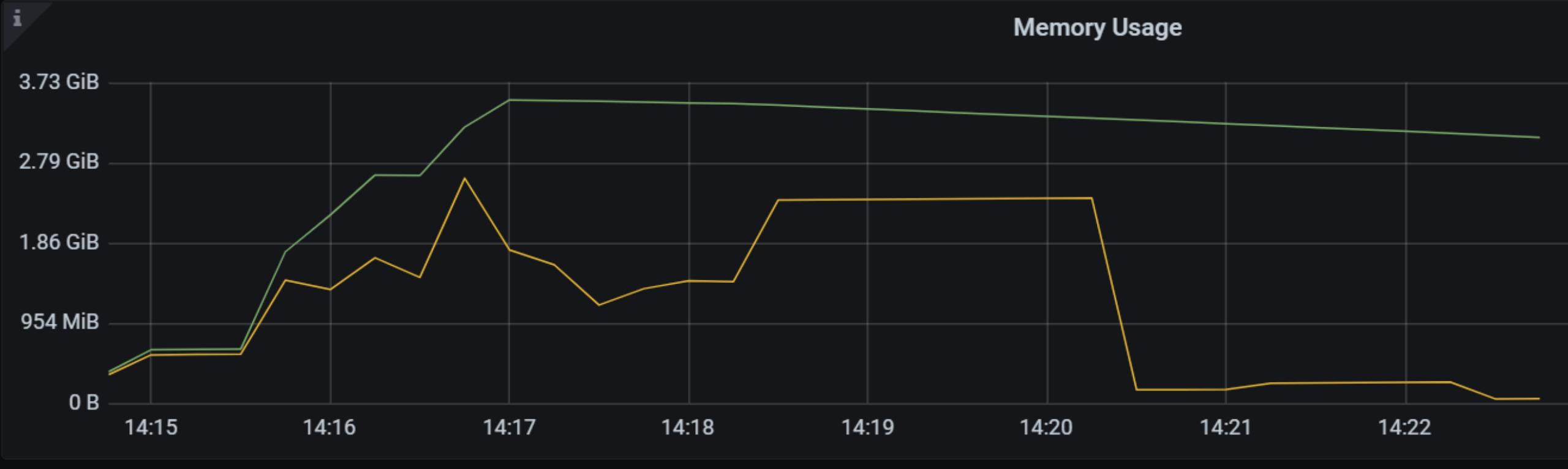
Memory consumption comparison
More efficient data duplication detection for TiDB Lightning
Due to legacy reasons, there may be duplicate data across sharded MySQL instances in a production environment, and conflicting data may be formed when the primary key or unique index is duplicated. Therefore, the merging of multiple MySQL shards into downstream TiDB must be checked for data duplication and processed. Single tables that reach tens of terabytes could bring great challenges for detection efficiency.
TiDB Lightning is a tool for importing large-scale data from CSV or SQL files to new TiDB clusters. Lightning’s local backend mode can encode source data into ordered key-value pairs and insert them directly into TiKV storage. This is a common way to initialize TiDB cluster data.
However, the problem with this mode is that data import does not go through the transaction write interface, so there is no way to detect conflicting data at insertion. Prior to TiDB 5.4, Lightning was only able to do this by comparing KV-level checksums, but this was limited to detecting errors without locating the conflicting data.
The new duplicate data detection feature in TiDB 5.4 allows Lightning to accurately detect conflicting data and has a built-in conflicting data removal algorithm for automatic aggregation. Once conflicting data is detected, Lightning can save it for users to filter and reinsert.
The following table offers detailed performance verification data.
| Lightning threads | Data volume (TiB) | Duplication (%) | Data import duration | Duplication detection duration | |
| Test 1 | 6 | 18 | 0.27% | 8h | 3h 3m |
| Test 2 | 6 | 18 | 0.13% | 8h | 2h 5m |
Functionality extensions for cloud environments
To better integrate with the cloud ecosystem, TiDB 5.4 introduces Raft Engine, a log storage engine that can reduce data transfer costs by more than 30%. This release also supports Azure Blob Storage as the backup target storage. With this support, TiDB 5.4 completes the integration with the major cloud storage service vendors including Google Cloud Platform (GCP), Amazon Web Services (AWS), and Microsoft Azure.
Raft Engine as the TiKV log store
One of the biggest concerns for cloud users is cost, and the overhead generated by the data volume and I/O requests cannot be underestimated. Typically, when distributed databases process writes, they must replicate and persist a large number of logs. This increases the service deployment cost. On the other hand, the quality of service can be significantly affected as workload fluctuates, and the predefined hardware could fail to meet the configurations requirement.
Raft Engine is an open-source log storage engine. Compared with the default RocksDB, Raft Engine has the following advantages:
- Raft Engine compresses the TiDB cluster’s write log and stores it in the file queue without additional full dumping.
- Raft Engine has more efficient garbage collection, which cleans up expired data in bulk. In most cases, it does not use additional background resources.
These optimizations can significantly reduce the disk bandwidth usage of storage nodes in TiDB clusters. In addition, Raft Engine has a lighter execution path, which, in some cases, significantly reduces the tail latency of write requests. Using Raft Engine to store cluster logs can save deployment costs on the cloud and improve service stability.
In an experimental environment, Raft Engine reduced the total write bandwidth of the cluster by about 30% under the TPC-C 5000 warehouse load, with improved front throughput as well.
| Threads=50 | ||||
| TpmC | Client Latency (ms) | CPU % | Write I/O throughput (MB/s) | |
| Vanilla | 28954.7 | 50th: 44.0, 90th: 54.5, 95th: 60.8, 99th: 79.7, 99.9th: 151.0 | 420 | 98 |
| Raft Engine | 30146.4 | 50th: 41.9, 90th: 52.4, 95th: 58.7, 99th: 79.7, 99.9th: 142.6 | 430 | 75 |
| Threads=800 | ||||
| Vanilla | 54846.9 | 50th: 402.7, 90th: 570.4, 95th: 604.0, 99th: 805.3, 99.9th: 1073.7 | 850 | 209 |
| Raft Engine | 56020.5 | 50th: 402.7, 90th: 570.4, 95th: 604.0, 99th: 671.1, 99.9th: 838.9 | 750 | 129 |
For detailed usage information, see the TiKV configuration file documentation.
Azure Blob Storage as backup target storage
In TiDB 5.4, Backup & Restore (BR) supports Azure Blob Storage as the remote target storage for backups. Users deploying TiDB in Azure Cloud can use this feature to easily back up their cluster data to the Azure Blob Storage service with either of the following methods:
- Backup and restore Azure Active Directory (AD)
- Backup and restore data using an access key
For more information, see Back up and Restore Data on Azure Blob Storage.
Ease of use and operational efficiency
TiDB 5.4 also introduces features and enhancements that improve ease of use and operational efficiency. For instance,
- Enhanced collection and management of statistical information. Now, you can set different collection configuration items for different tables, partitions, and indexes. The settings are saved by default for future use.
- Backup & Restore (BR) supports automatic adjustment of backup threads, which can significantly reduce the negative impact brought by backup operations.
- Support for the GBK character set.
System utility and configuration improvement
TiDB 5.4 has made many efforts to optimize system configuration parameters. Here, we will highlight the session variable, the variable that allows reading historical data within a specified time range. You can set the variable as follows:
set @@tidb_replica_read=leader_and_followerset @@tidb_read_staleness="-5"
By this setting, TiDB can select the nearest Leader or Follower node and read the latest historical data within five seconds. TiDB can quickly enable expired reads through session variables, avoiding frequent display of read-only transactions or specifying expired read syntax within each SQL statement. This enhancement is designed to meet the business requirements of low latency and high throughput data access in quasi-real-time scenarios.
For more information on the session variable and a full list of new system configuration parameters, see the Release Notes.
Get started with TiDB 5.4!
These are just a sampling of the highlights included in TiDB 5.4. For a full list of features, improvements, bug fixes, and stability enhancements, see the Release Notes.
If you’re currently not running TiDB, you can download TiDB 5.4 and give it a try. For more information, you can check our documentation and case studies.
If you’re running an earlier version of TiDB and want to try 5.4, read Upgrade TiDB Using TiUP.
And all of you are welcome to join our community on Slack and TiDB Internals share your thoughts with us.
Related Resources

Conference
May 19, 2026
TiDB SCaiLE Europe 2026: Why Engineers Building Agentic AI Should Be in Stockholm on 4 June

Conference
May 12, 2026
TiDB SCaiLE Europe 2026: Speaker Lineup and Session Preview

Thought Leadership
May 7, 2026
What is a Context Platform? A New Pattern for AI Agents in Production
TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。