
※このブログは2026年3月12日に公開された英語ブログ「Why You Should Replace Stored Procedures with a Service Layer」の拙訳です。
主なポイント
- ストアドプロシージャは、デプロイメントの摩擦、バージョン管理の乖離、および可観測性のギャップを生み出し、これらは規模が大きくなるにつれて悪化します。
- サービスレイヤーは、これらをテスト可能でデバッグ可能、かつ独立して拡張可能なアプリケーションコードに置き換えます。
- サービスとデータベースを同一場所に配置させることで、低いレイテンシーを維持しながら、最新のツールやライブラリを活用できるようになります。
- 移行は段階的に行うことができます。新しい機能から開始し、必要に応じて既存のプロシージャを移行します。
リレーショナルデータベースを長年扱ってきた方なら、ほぼ間違いなくストアドプロシージャを目にしたことがあるでしょう。ネットワークのレイテンシーが高コストで、アプリケーションがモノリシックだった時代には理にかなっていましたが、時代は変わりました。このブログでは、なぜストアドプロシージャがチームの妨げになっているのか、そして現代的な代替手段とはどのようなものかを探ります。
ストアドプロシージャとは何ですか?
ストアドプロシージャは、データベース自体の中に存在するコードの一部であり、CALLステートメント、トリガー、またはスケジュールされたイベントを介してオンデマンドで実行されます。MySQL (およびTiDBのようなMySQL互換データベース) では、これらは従来、SQL標準のプロシージャ拡張であるSQL / PSMで記述されます。
MySQLの商用版には最近、ストアドプロシージャ向けのJavaScriptサポートが追加されましたが、コミュニティ版 (およびAWS RDSなどの派生製品) は依然としてSQL / PSMのみをサポートしています。PostgreSQLなどの他のデータベースは複数の言語をサポートしていますが、根本的なトレードオフは変わりません。
ストアドプロシージャはこれまでに2つの目的を果たしてきました。複数のアプリケーションが重複することなくデータベースロジックを共有できるようにする抽象化レイヤーとしての役割、および複数のSQLステートメントを単一のサーバーサイド呼び出しにまとめることでネットワークの往復回数を削減する役割です。
これらはいずれも正当な目標です。しかし、ストアドプロシージャがそれらを達成する方法は、多くの運用上の問題を引き起こします。
ストアドプロシージャに反対する理由
時間の経過とともに、ストアドプロシージャはソフトウェア開発ライフサイクルのほぼすべての側面で摩擦を蓄積していきます。
- デプロイメントとバージョンコントロール:チームはストアドプロシージャを、それに依存するアプリケーションコードとは別にデプロイするため、リリースとロールバックのたびに調整のオーバーヘッドが発生します。さらに悪いことに、本番環境で実行されているバージョンがバージョンコントロール内のものと一致しないことがよくあります。そもそもバージョンコントロールに入っていないことさえあります。
- 言語の不一致:多くのアプリケーションはGo、Java、またはPythonで書かれています。ストアドプロシージャはSQL / PSMで書かれています。これは、頻繁なコンテキスト切り替え、個別のツール、およびデータベース側のコードレビューを担当する人材の不足を意味します。
- デバッグ、テスト、可観測性の機能の制限:ブレークポイントは?ほとんどサポートされません。ユニットテストは?ほとんど行われません。ログ記録、メトリクス、およびトレーシングは?ストアドプロシージャは通常、これらと統合されません。その結果、テストも計測もされていないビジネスロジックがデータベース内に蓄積されていくことになります。
- 機能の制約:外部APIの呼び出し、サードパーティライブラリの使用、または通知の送信が必要ですか?ストアドプロシージャのサポートは非常に限られており、データベースレイヤーとアプリケーションレイヤーの間で検証ロジックが重複することがよくあります。
- ツールの脆弱性:SQL / PSMのIDEサポートは、他の主要な言語に大きく遅れをとっています。コード補完、リファクタリング、リンター、および静的分析といった機能は、欠如しているか、あるいは基本的なものです。
- パフォーマンスとスケーラビリティの制限:データベースエンジンは通常、ストアドプロシージャをあらかじめコンパイルするのではなく逐次解釈して実行し、データベースサーバー自体のコンピューティングリソースを消費します。MySQLデプロイで一般的な単一プライマリのアーキテクチャでは、まさに最も不適切な場所でスケーラビリティの限界を作り出します。
ストアドプロシージャに代わる現代的な選択肢:サービスレイヤー
解決策は明快です。ストアドプロシージャを、データベースアクセスを所有し、他のアプリケーションにHTTP (またはgRPC) APIを公開する専用のサービスレイヤーに置き換えることです。アプリケーションはSQL接続を介してストアドプロシージャを呼び出す代わりに、HTTP経由でサービスを呼び出します。
これにより、一度にいくつかの利点が得られます。
- 標準的な開発プラクティス:データベースロジックは通常のアプリケーションコードになります。バージョンコントロールに保存され、コードレビューを受け、CIでテストされ、他のすべてと同じパイプラインを通じてデプロイされます。デバッグは通常のデバッグになります。
- 言語の柔軟性:パフォーマンス重視ならGo、迅速なプロトタイピングならPythonなど、チームにとって最も理にかなった言語でサービスを実装できます。その言語のエコシステムにあるライブラリ、フレームワーク、およびツールをフル活用できます。
- セキュリティと監査性の向上:サービスレイヤーは、認証、認可、リクエストログ、および監査を追加するための最適な場所となります。これをデータベースの内部で実現するのは、非常に困難です。
- 独立したスケーラビリティ:サービスは、データベースとは別に水平方向にスケーリングします。単一のデータベースプライマリのコンピューティングリソースに制約されることはもうありません。これは、ストレージレイヤーがすでに水平方向にスケーリングするTiDBのような分散型データベースと組み合わせたときに、特に強力です。アプリケーションロジックも同様にスケールできるようになります。
- パフォーマンスの向上:独自のプロセスで実行されるコンパイル済みで最適化されたアプリケーションコードは、一般的にデータベースエンジン内で実行される逐次解釈のSQL/PSMを凌駕します。
- 適切に行われる往復回数の削減:ストアドプロシージャの本来の動機の1つは、複数のSQL操作を単一の呼び出しにまとめることでした。サービスでも同様の役割を果たします。サービスをデータベースの近くに配置し、多段階の操作を内部で処理することで、外部に対しては単一のクリーンなAPI呼び出しを提供します。
アーキテクチャ:サービスをどこに配置するか
データベースに対するサービスレイヤーの配置は、レイテンシーに影響します。
アプリケーションがリモートデータベースと直接通信する場合、すべてのSQLのラウンドトリップがネットワークを経由します。アプリケーションがエンドユーザーの近い場所にあり、データベースから遠い場合、複数のクエリが実行されるにつれてレイテンシーが急速に蓄積されます。
サービスレイヤーは、データベースと同じ場所に配置することでこの問題を解決します。アプリケーションはサービスに対して単一のHTTP呼び出しを行い、サービスは高速なローカル接続を介してすべてのSQLのラウンドトリップを処理します。エンドツーエンドの総レイテンシーは大幅に減少します。
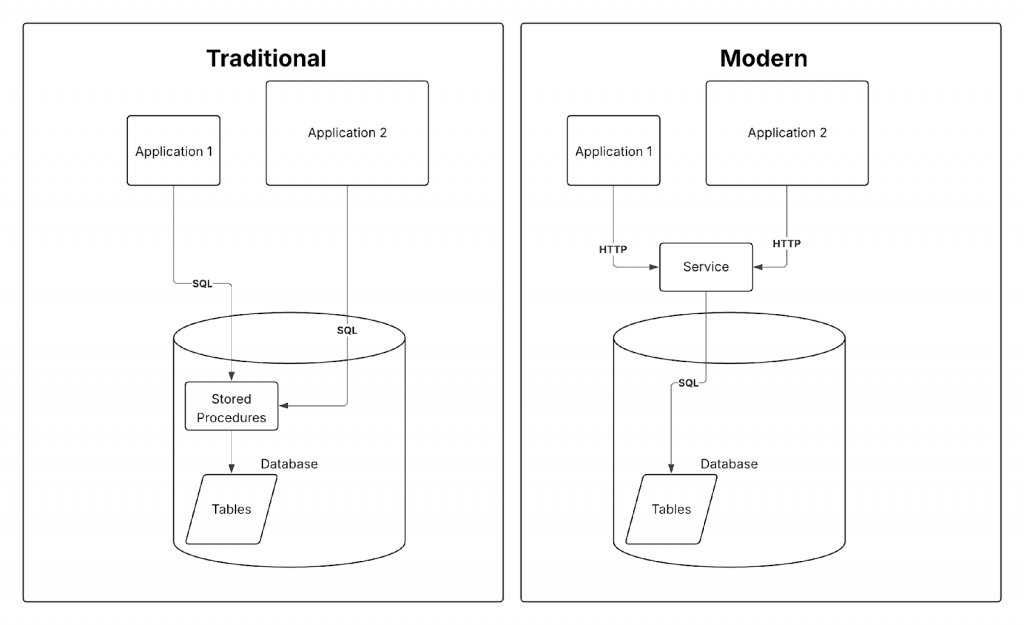
特定のロジックが1つのアプリケーションからのみで使用される場合は、さらにシンプルな方法があります。そのロジックをそのアプリケーションの中に配置するだけです。サービスレイヤーのパターンが最も価値を発揮するのは、複数のコンシューマーが同じデータベース操作を共有する必要がある場合です。
実践的な例
以下の操作がストアドプロシージャとして実装されている書店アプリケーションを考えてみましょう。
- 文字列が有効なISBN-13コード (図書番号) かどうかをチェックする
isbn13_valid関数。 - 図書番号を検証した後に書籍を挿入する
add_bookプロシージャ。 - 書籍の価格を更新する
set_priceプロシージャ。 - 在庫を調整し販売を記録する
sell_bookプロシージャ。 - カタログをJSONドキュメントとして返す
books_jsonビュー。
サービスに移行すると、これらはHTTPエンドポイントになります。
GET /api/v1/books— カタログをJSON形式で返します。POST /api/v1/buy— 在庫を更新しトランザクションを記録して、販売を処理します。
そして、この移行により、ストアドプロシージャでは到底サポートできなかった可能性が広がります。例えば、図書番号の検証では、適切なライブラリ (GoのISBNパッケージなど) を使用して、ISBN-10形式とISBN-13形式の両方の形式を検証できます。また、外部APIから書籍のメタデータを取得して、タイトル、著者、その他のフィールドを自動入力することも可能です。set_priceエンドポイントは、為替レートAPIと連携させることで、通貨間の価格を自動的に変換することもできます。
これらの機能強化は、アプリケーションコードでは容易なことですが、ストアドプロシージャ内では事実上不可能です。
ストアドプロシージャからサービスレイヤーへの移行
ストアドプロシージャからの移行は、一度にすべて行う必要はありません。実践的なアプローチは以下の通りです。
- ストアドプロシージャのインベントリを作成する:各プロシージャが何をしているか、どのアプリケーションがそれを呼び出しているか、重要性を把握します。
- 新しい機能から開始する:新しいデータベースロジックは、最初からサービスレイヤーで構築する必要があります。
- 段階的に移行する:最も問題のあるストアプロシージャ (テストが最も困難なもの、変更頻度が最も高いもの、またはSQL / PSMが提供できない機能を最も必要としているもの) を選び、それらを最初に移行します。
- 並行して実行する:移行期間中は、サービスレイヤー版が本番で検証される間、ストアドプロシージャをフォールバックとして保持しておくことができます。
まとめ
ストアドプロシージャは、かつては一連の課題の合理的な解決策でしたが、現代のアーキテクチャはそれより効果的に解決できるようになっています。ストアドプロシージャは、ネットワークのラウンドトリップをわずかに削減するために、開発速度、テスト可能性、可観測性、およびスケーラビリティを犠牲にしていますが、このトレードオフが現在ではほとんど理にかないません。
サービスレイヤーは、運用上の負担なしに、同じメリット (共有ロジック、ラウンドトリップの削減) を提供します。そして、そのサービスが水平方向にスケーラブルなデータベースに支えられているとき、アプリケーションとデータベースの両側からボトルネックが取り除かれます。
移行を開始するのに最適な時期は何年も前でした。ですが、今から始めるのが現時点での最善です。
データベースアーキテクチャを最新化する準備はできていますか?TiDB Cloud Starterを無料で試して、水平方向にスケーラブルなデータベースがサービスレイヤーのアプローチとどのように連携するかを確認してみてください。
Related Resources

Conference
May 19, 2026
TiDB SCaiLE Europe 2026: Why Engineers Building Agentic AI Should Be in Stockholm on 4 June

Conference
May 12, 2026
TiDB SCaiLE Europe 2026: Speaker Lineup and Session Preview

Product
May 11, 2026
From Preview to Production: TiDB Cloud Dedicated on Microsoft Azure is Now Generally Available
TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。