

※このブログは2026年02月13日に公開された英語ブログ「How to Build an AI Advisor That Shows College ROI (Not Rankings)」の拙訳です。
私は、たくさんの人が学生ローンで苦しんでいるのを知っています。
ある友人は高額な私立学校で音楽の修士号を取得しました。彼女は12万ドルの借金を抱え、現在はスターバックスで働いています。また別の知人は、年間5万ドルもする学校でビジネスの学位を取りました。結局、学位の必要がなかった仕事をしていますが、40歳までローン返済が続きます。
彼らは賢く意欲的な人々です。ただ、17歳で学校を選ぶときに正しい情報を持っていなかっただけです。誰もお金の計算を教えてくれませんでした。
ほとんどの大学受験生向けツールは“雰囲気”を提供します:ランキング、キャンパス写真、合格率など。しかし、多くの家庭にとって本当に重要な質問は表示されません:
「もしこの学校でこの専攻を選んだら、30歳や35歳での私の経済状況はどうなるのか?」
そこで私はCollege Pickerを作りました。これは、学校の名声でもマーケティングでもお金を稼ぐためでもなく、実際の経済的結果に基づいて学校を比較するAI大学アドバイザーです。
重要なポイント
- ランキングは、学費の手頃さや卒業後の成果と大きく乖離していることがあります。
- 「大学費用」は1つの数字ではありません。収入、居住地、奨学金、編入経路によって変わります。
- このツールは、学校ごと・専攻ごと・キャリアパスごとの20年間の純資産予測をモデル化します。
- TiDBを使うことで、複数のデータベースを同期することなく、1つのSQLクエリでテーブルの条件絞り込みと全文検索+ベクトル類似度検索を同時に行えます。
大学ランキングを超えて:データで学生ローン危機を解決
大学ランキングは役に立ちません。US Newsは、卒業後に家賃を払えるかどうかとはほとんど関係のない評価指標で学校をランク付けしています。アメリカ国内で15位の大学であっても、20万ドルの借金を抱え、初任給が4万5千ドルということもあります。
私は「音楽や美術を学ぶな」と言っているわけではありません。言いたいのは、絵画を学びたいなら、収入の見込める専攻をメインにして副専攻として学ぶ方法もある、ということです。アートは続けてください。ただし、現実的に返済できない額の借金を抱えて学位を取るのは避けるべきです。
College Pickerは、すべての17歳が自分に問うべき質問に答えるために作られました:
「この学位は借金に見合う価値がありますか?」
College Pickerの機能
学生プロフィール (収入、州、希望専攻、必要に応じてキャリアパス) を入力すると、College Pickerは次の処理を行います:
- ハイブリッド検索 (キーワード+セマンティック検索) を使って関連する大学を見つける
- 学費、借金、卒業率、卒業後の収入データを取得する
- キャリアパスの要件 (大学院、研修期間など) を調べる
- 20年間の将来予測を生成する (借金返済、給与の昇給、貯蓄や投資)
- 複数のキャリアの比較結果 (有・良・可・不可) を理由とともに出力する
- トレードオフを意思決定ツリーとして可視化する
AIスタック:TiDB Cloud、Claude Opus、GPT-4o miniの組み合わせ
すべてを完璧にこなす単一モデルは存在しないため、用途ごとに最適なツールを使っています。
- TiDB Cloud Starter:私は3つのデータベースを運用したくありませんでした。ユーザーデータはPostgres、エンベディング用にベクトルデータベース、キャッシュにはRedis。副業プロジェクトとしてはインフラが多すぎます。TiDBなら、テーブルの検索とベクトル類似検索を同じSQL文で処理できます。MySQL互換なので新しいことを学ぶ必要もありません。またTiDB Cloud Starterはスケールゼロに対応しているため、利用者がいないときは料金が発生しません。
- Claude Opus 4.5:会話型アドバイザーです。学生は「Stanfordに行くべきか、それともまずコミュニティカレッジに行くべきか?」のような質問をします。そして返ってくるのは決まり文句ではなく、実際のデータに基づいた回答です。
- Claude Sonnet 4:キャリアデータの取得に使います。「小児外科医」のような職業を入力すると、給与データ、研修医としての年数、大学院費用などの構造化データを返します。構造化データの抽出では速度が重要であり、Opusよりもコストが低いためSonnetを使っています。
- GPT-4o mini:大学比較の判定を行います。各選択肢のトレードオフを評価し、「有・良・可・不可」という評価とその理由を出力します。
- OpenAI Embeddings:text-embedding-3-smallを使ってすべてのデータのベクトルを生成します。これにより「カリフォルニア付近で手頃なエンジニアリング系の学校」のようなセマンティック検索が可能になります。
AIワークフローの構築:検索から将来予測までの金融結果をマッピングする
処理パイプラインは次のようになっています。
[学生がプロフィールを入力:収入、住んでいる州、志望専攻]
↓
[ハイブリッド検索(全文検索とベクトル検索)で大学を検索]
↓
[TiDBから大学のデータを取得:学費、卒業後の進路、推定年収]
↓
[Claudeが志望するキャリアとごの年収を調査]
↓
[大学毎に20年の予測財務収支を作成]
↓
[意志決定ツリーを可視化]
↓
[GPT-4o-miniが判定:どの大学が費用対効果が高いか]
↓
[損益分岐点を含む比較結果を表示]
重要なポイント:大学費用は一律の数字ではないということです。家族の収入、州内か州外か、奨学金、そしてコミュニティカレッジからの編入などによって大きく変わります。このシステムはそれらすべてをモデル化しています。
AIアプリケーションで統合されたデータベースが分割されたアーキテクチャより優れている理由
多くのAIアプリケーションは、次のような分割されたアーキテクチャで構築されています:
- Postgres:リレーショナルデータ用
- ベクトルデータベース (PineconeやWeaviateなど):エンベディング用
この構成でも動作はします。しかし、すぐに厄介になる問題がいくつか発生します。
1. リレーショナルデータとベクトルデータ間の「同期コスト」を解消する
大学データが1つのデータベースにあり、エンベディングが別のデータベースにある場合、更新のたびに自分で小さな2フェーズコミットのような処理を管理する必要があります:
- リレーショナルテーブルの行を更新
- エンベディングを再生成
- ベクトルデータベースにupsert
- 途中で何も失敗しないことを祈る
College Scorecardが新しい収入データを公開したとき、同期スクリプトを実行しながら整合性が保たれることを祈ることになります。例えば次のような状態になる可能性があります。Postgresには年収85,000ドルが保存されているが、エンベディングは古い72,000ドルのデータから生成されている。すると検索結果が微妙に間違い始めます。そしてこの種のバグはデバッグが非常に難しくなります。
TiDBでは、この問題は消えます。
UPDATE colleges
SET earnings_10yr = 85000,
embedding = ?
WHERE id = 12345;1つのトランザクションです。1つのトランザクションです。リレーショナルデータとベクトルデータの両方に対してACID保証が適用されます。
2. クエリレイテンシ問題の解決:テーブルの検索とベクトル検索を1つのSQLで実行
私の検索機能には、同時に3つの条件が必要でした:
- 州や収入によるフィルタ
- 「UCLA」のような正確な名称検索
- 「すぐれたエンジニアリングの学校」のようなセマンティック検索
分割されたアーキテクチャ構成のスタックでは、複数回のラウンドトリップが発生します。ベクトルデータベースにクエリを送信してIDを取得し、次にPostgresにクエリを実行してテキスト検索を行い、その結果をアプリケーションコード側でマージして再ランキングします。
TiDBなら、これが1つのクエリで完結します:
SELECT id, name, state, earnings_10yr,
FTS_MATCH_WORD(name, 'UCLA') as text_score,
VEC_COSINE_DISTANCE(embedding, ?) as vector_distance
FROM colleges
WHERE state = 'CA' AND earnings_10yr > 60000
ORDER BY
CASE WHEN FTS_MATCH_WORD(name, 'UCLA') > 0 THEN 0 ELSE 1 END,
vector_distance ASC
LIMIT 10;テーブルの検索、テキスト検索、ベクトル検索、カスタムランキング。すべて1つのクエリで実行できます。ネットワーク往復は1回だけです。(私の環境では約47msでした。)
AIインフラの経済性:副業プロジェクトでは「ゼロまでスケール」が重要
多くのベクトルデータベースは、ベクトル数やクエリ数に応じて料金が発生します。約6,000の大学に対して1,536次元のエンベディングを使用すると、多くのプラットフォームでは概算で最低でも月額約70ドル程度かかります。さらに、リレーショナルデータベースのホスティング費用や、すべてのデータを同期させておくためのエンジニアリング作業の時間も必要になります。
トラフィックが断続的なサイドプロジェクトの場合、TiDB Cloud Starterのゼロまでスケールできる機能は、「このまま運用を続ける」か「プロジェクトを停止する」かを分ける大きな違いになります。
実装の詳細:SQLによるベクトル検索とハイブリッドクエリ
各大学について、私は次のようなデータを保存しています。
CREATE TABLE colleges (
id INT PRIMARY KEY,
name VARCHAR(255),
state VARCHAR(2),
ownership ENUM('public', 'private_nonprofit', 'private_forprofit'),
-- Costs (varies by income bracket)
tuition_in_state INT,
tuition_out_of_state INT,
room_and_board INT,
net_price_0_30k INT, -- Family income $0-30k
net_price_30_48k INT, -- Family income $30k-48k
net_price_48_75k INT, -- Family income $48k-75k
net_price_75_110k INT, -- Family income $75k-110k
net_price_110k_plus INT, -- Family income $110k+
-- Outcomes
graduation_rate_4yr FLOAT,
graduation_rate_6yr FLOAT,
retention_rate FLOAT,
-- Earnings
earnings_6yr INT, -- Median earnings 6 years after enrollment
earnings_10yr INT, -- Median earnings 10 years after enrollment
-- Debt
median_debt INT,
monthly_payment INT,
-- Vector embedding for semantic search
embedding VECTOR(1536),
INDEX idx_state (state),
INDEX idx_earnings (earnings_10yr),
VECTOR INDEX idx_embedding (embedding) USING HNSW
);このVECTOR(1536)カラムは、tuition_in_stateと同じテーブルにあります。同じテーブル、同じ行、同じトランザクションです。
また、net price (支払い金額) に5つの所得区分があることにも注目してください。年収40,000ドルの家庭と150,000ドルの家庭では、支払う金額が大きく異なります。多くの大学比較ツールはこの点を無視しています。すべての人が同じ金額を支払うかのように、定価の学費だけを表示します。しかし実際にはそうではありません。
ハイブリッド検索の実装:キーワード一致とベクトル類似度の統合
学生の検索はかなり曖昧です。
- “UCLA”
- “University of California Los Angeles”
- “カリフォルニア州のいいコンピュータサイエンスの大学”
- “LA近郊で金額が現実的なエンジニアリングの大学”
そのため私は、キーワード一致とセマンティック類似度を組み合わせたハイブリッド検索の方法を構築しました。
export async function POST(request: NextRequest) {
const { query, mode = "hybrid", limit = 10 } = await request.json();
// Generate embedding for semantic search
const queryEmbedding = await generateEmbedding(query);
if (mode === "text" || mode === "hybrid") {
// BM25 text search on college names
const [textResults] = await pool.execute(`
SELECT id, name, state, earnings_10yr,
FTS_MATCH_WORD(name, ?) as relevance
FROM colleges
WHERE FTS_MATCH_WORD(name, ?)
ORDER BY relevance DESC
LIMIT ?
`, [query, query, limit]);
if (mode === "text" || textResults.length >= limit) {
return NextResponse.json({ results: textResults, mode: "text" });
}
}
if (mode === "vector" || mode === "hybrid") {
// Semantic search via vector similarity
const [vectorResults] = await pool.execute(`
SELECT id, name, state, earnings_10yr,
VEC_COSINE_DISTANCE(embedding, ?) as distance
FROM colleges
WHERE VEC_COSINE_DISTANCE(embedding, ?) < 0.5
ORDER BY distance ASC
LIMIT ?
`, [queryEmbedding, queryEmbedding, limit]);
// Merge and deduplicate results
const merged = mergeResults(textResults, vectorResults);
return NextResponse.json({ results: merged, mode: "hybrid" });
}
}
FTS_MATCH_WORD()は正確なキーワード一致を処理します。VEC_COSINE_DISTANCE()はセマンティック検索を処理します。同じデータベース、同じクエリパターンで、2つの検索手法を扱うことができます。
大学名の略称・別名問題:参照テーブルによる検索精度の改善
ここで私は丸1日を無駄にしました。
最初のバージョンでは、単純なあいまい検索を使っていました。
SELECT * FROM colleges WHERE LOWER(name) LIKE '%mit%' LIMIT 5これは遅く、結果もひどいものでした。「MIT」で検索すると、Massachusetts Institute of Technologyより先に、Summit UniversityやSmith Collegeがヒットしてしまいます。
文字列位置の重み付けやレーベンシュタイン距離、正規表現なども試しました。しかしどれも不安定で、遅いものでした。
最終的な解決策は、驚くほどシンプルでした。参照テーブルを作ることです。
CREATE TABLE college_aliases (
alias VARCHAR(255) PRIMARY KEY,
college_id INT,
INDEX idx_college (college_id)
);
-- Examples
INSERT INTO college_aliases VALUES
('UCLA', 110662),
('University of California Los Angeles', 110662),
('UC Los Angeles', 110662),
('USC', 123961),
('University of Southern California', 123961),
('MIT', 166683),
('Massachusetts Institute of Technology', 166683);チャットルートでは、まずエイリアス検索を行い、その後にあいまい検索へフォールバックします。
async function findColleges(terms: string[]): Promise<College[]> {
const colleges: College[] = [];
for (const term of terms) {
// Try alias lookup first (fast, exact)
const [aliasRows] = await pool.execute(
`SELECT c.* FROM colleges c
JOIN college_aliases a ON c.id = a.college_id
WHERE LOWER(a.alias) = LOWER(?)`,
[term]
);
if (aliasRows.length > 0) {
colleges.push(aliasRows[0]);
continue;
}
// Fall back to fuzzy search
const [fuzzyRows] = await pool.execute(
`SELECT * FROM colleges
WHERE LOWER(name) LIKE ?
LIMIT 1`,
[`%${term.toLowerCase()}%`]
);
if (fuzzyRows.length > 0) {
colleges.push(fuzzyRows[0]);
}
}
return colleges;
}さらに、検索ミスもログに記録してシステムを改善していきます:
CREATE TABLE college_lookup_misses (
term VARCHAR(255),
searched_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);毎週このテーブルを確認して、新しいエイリアスを追加しています。ユーザーがどんな略称を使うかを推測するよりも、はるかに信頼性の高い方法です。
大学のROIを計算する:20年間の純資産と損益分岐年齢のモデル化
ある大学、専攻、キャリアパスが決まった場合、20年間の純資産を予測します。
このモデルでは以下を考慮しています:
- 大学費用 (所得調整済み実質負担価格)
- 奨学金
- 専攻別の収入倍率 (コンピュータサイエンス:1.8倍、芸術:0.65倍)
- キャリアパスの要件 (医療系は大学院4年+約24万ドルの借金)
- ローン返済 (10年間の標準プラン)
- 貯蓄率 (15%) と投資利回り (7%)
function generateLifePath(
college: College,
major: string,
career: CareerData,
familyIncome: number
): YearlySnapshot[] {
const timeline: YearlySnapshot[] = [];
// Get income-adjusted net price
const yearlyCollegeCost = getNetPrice(college, familyIncome);
const totalCollegeCost = yearlyCollegeCost * 4;
// Major affects starting salary
const earningsMultiplier = MAJOR_MULTIPLIERS[major] || 1.0;
const baseSalary = college.earnings_10yr * earningsMultiplier;
// Career might require grad school
const gradSchoolYears = career.grad_school_years || 0;
const gradSchoolCost = career.grad_school_cost || 0;
const residencyYears = career.residency_years || 0;
let totalDebt = totalCollegeCost + gradSchoolCost;
let netWorth = -totalDebt;
let currentSalary = 0;
for (let year = 0; year <= 20; year++) {
const age = 18 + year;
let phase = "college";
if (year < 4) {
phase = "college";
currentSalary = 0;
} else if (year < 4 + gradSchoolYears) {
phase = "grad_school";
currentSalary = 0;
} else if (year < 4 + gradSchoolYears + residencyYears) {
phase = "residency";
currentSalary = career.residency_salary || 60000;
} else {
phase = "career";
const yearsWorking = year - 4 - gradSchoolYears - residencyYears;
currentSalary = baseSalary * Math.pow(1.03, yearsWorking); // 3% annual raises
}
// Loan repayment during career years
const loanPayment = phase === "career" ? (totalDebt / 10) : 0;
// Savings and investment
const savings = currentSalary * 0.15;
netWorth = netWorth * 1.07 + savings - loanPayment;
timeline.push({
year,
age,
phase,
salary: Math.round(currentSalary),
debt: Math.round(Math.max(0, totalDebt)),
netWorth: Math.round(netWorth)
});
totalDebt = Math.max(0, totalDebt - loanPayment);
}
return timeline;
}出力は非常に理解しやすくなっています。医療系のキャリアでは、現実を直視させられる結果となります:多くの場合、損益分岐点に達するのは30代半ばですが、長期的な収入で補うことが可能です。
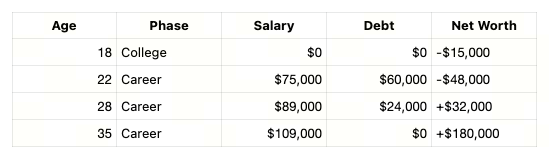
そして音楽修士のあの友人の場合はどうでしょうか?この予測を見れば、彼女が正確に何に手を出すかが分かっていました。借金12万ドル、初任給約3.5万ドル、損益分岐年齢:到達せず。
Claude Sonnetを使ったリアルタイムのキャリア給与データ取得
私の最初のバージョンでは給与データをハードコーディングしていました。200以上の職業とその給与を持つ巨大なJSONファイルを使っていました。
しかし、それは6か月以内に古くなります。給与は変動しますし、新しい職業も登場します。常に修正し続ける必要がありました。
現在はClaude Sonnetに問い合わせて取得しています:
const response = await anthropic.messages.create({
model: "claude-sonnet-4-20250514",
max_tokens: 500,
system: `You are a career data assistant. Given a career, return JSON with:
- title: normalized job title
- median_salary: annual median
- salary_25th: 25th percentile
- salary_75th: 75th percentile
- growth_rate: projected job growth %
- education_years: years of education/training required
- grad_school_required: boolean
- grad_school_years: if required
- grad_school_cost: estimated total cost
- residency_years: for medical careers
- residency_salary: if applicable`,
messages: [{ role: "user", content: `Career: ${careerInput}` }]
});これにより、以下のようなケースも扱えます:
- 「小児外科医」(医学部+研修)
- 「特許弁護士」(学部後に法科大学院)
一般的な職業については、結果をメモリ内にキャッシュして、同じ問い合わせの繰り返し呼び出しを避けています。
React Flowの意思決定ツリーで財務パスを可視化
私は、主要なライフステージでの成果を示す意思決定ツリーを生成します:
function buildDecisionTree(colleges: College[], lifePaths: LifePath[]): TreeNode[] {
const nodes: TreeNode[] = [];
const edges: TreeEdge[] = [];
// Root node: "Now"
nodes.push({
id: "start",
data: { label: "Now (Age 18)", netWorth: 0 },
position: { x: 0, y: 0 }
});
for (const [index, college] of colleges.entries()) {
const path = lifePaths[index];
// Year 1 node
nodes.push({
id: `${college.id}-y1`,
data: {
label: college.name,
phase: "Freshman",
netWorth: path[1].netWorth
}
});
// Year 4 node (graduation)
nodes.push({
id: `${college.id}-y4`,
data: {
label: "Graduation",
netWorth: path[4].netWorth,
debt: path[4].debt
}
});
// Year 10 node (mid-career)
nodes.push({
id: `${college.id}-y10`,
data: {
label: "Year 10",
netWorth: path[10].netWorth,
salary: path[10].salary,
sentiment: path[10].netWorth > 0 ? "positive" : "negative"
}
});
// Connect nodes
edges.push({ source: "start", target: `${college.id}-y1` });
edges.push({ source: `${college.id}-y1`, target: `${college.id}-y4` });
edges.push({ source: `${college.id}-y4`, target: `${college.id}-y10` });
}
// Add "Skip College" path for comparison
nodes.push({
id: "skip-y10",
data: {
label: "No Degree - Year 10",
netWorth: calculateNoDegreeNetWorth(10),
salary: 35000
}
});
return { nodes, edges };
}React Flow+Dagreでレイアウトを行っています。ノードは色分けされており、正の純資産は緑、負の純資産は赤で表示されます。
現在調整している点
- 専攻ごとの乗数は概算です。スタンフォードのコンピュータサイエンス専攻と地域州立大学のコンピュータサイエンス専攻で成果は同じではありませんが、現状では両方に同じ1.8倍の乗数を適用しています。
- 学校固有の乗数は複雑です。CollegeScorecardから専攻別のデータを取得していますが、欠損値や分類の不整合が多くあります。
- キャリア検索は完全に一貫していません。「データサイエンティスト」と2回質問すると、給与レンジが少し異なることがあります。基本的な数値はBLS (米国労働統計局) のような構造化されたソースを使い、Claudeは例外やキャリアパスのロジックに使うことを検討しています。
結果
現在機能していること:
- 6,000以上の大学に対するハイブリッド検索
- 5つの所得区分に基づく費用比較
- 20年間の財務予測 (キャリアパス別)
- 意思決定ツリーによる可視化
- 学校同士のAI判定による比較
- コミュニティカレッジから編入代替案
- 文字入力せずに音声での質問が可能
次のステップ:
- 奨学金データベースの統合
- 地域別生活費調整
- 学校別専攻収益 (全国平均ではなく)
- 複数年の過去傾向
実際に使ってみよう
大学データは教育省のCollegeScorecardから取得しています。AIレイヤーにより財務モデリングと自然言語インターフェースを追加しています。
同様の仕組みを作りたい場合、TiDB Cloud Starterはハイブリッド検索を標準で提供します:FTS_MATCH_WORDでキーワード検索、VEC_COSINE_DISTANCEで意味検索を行います。同じクエリ、同じデータベースで実行可能です。Postgres+ベクトルデータベース+Redisを組み合わせる必要はありません。
この構築から得た主な洞察:大学のランキングではなく、ROIが重要です。
20万ドルの学費で5万ドルの仕事に就くより、4万ドルの学費で同じ仕事に就く方が良い投資です。計算は難しくありません。この形のデータが他では提示されていないだけです。
もしこのツールが友人が大学を選ぶときに存在していれば、彼女は今12万ドルの負債を抱えていなかったかもしれません。これが私がこのツールを作った理由です。
私のCollege Picker GitHub repoで、TiDB Cloud Starterとハイブリッド検索を使って財務優先のアドバイザーを構築した例を確認できます。



TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。