

※このブログは2026年02月11日に公開された英語ブログ「Prompt To Production: Building Scalable AI on TiDB with Kiro」の拙訳です。
このブログでは、データベース上でAIに直接推論させることに関する技術的深掘りをします。
食品廃棄物は、静かな社会物語です。毎年、世界中で約13億トンの食料が廃棄されていますが、その多くは冷蔵庫の奥にあるものを単に忘れてしまうことが原因です。使いかけの玉ねぎ、忘れ去られたほうれん草、そしてポツンと残された一個のトマト——これらは単なる食材ではなく、実現しなかった食事の「亡霊」なのです。
深夜のコーディングセッション中、自分の冷蔵庫を見つめながら、現代のテクノロジーを使ってこれらの食材を蘇らせることができないだろうかと考えました。これが、残り物の「クズ」をAI生成の料理に変え、同時に環境への影響を追跡する、ハロウィンをテーマにしたWebアプリRecipe Reanimatorのアイデアのきっかけとなりました。
しかし、このプロジェクトは単にレシピを作るだけのものではありませんでした。ユーザーアカウントやサステナビリティ指標といった厳密に構造化されたデータと、AI生成コンテンツの柔軟な性質を組み合わせたハイブリッドデータアーキテクチャの管理を学ぶ旅でもありました。そのために、私たちは複数の技術を組み合わせた「キメラ」を構築しました。具体的には、リレーショナルデータベースとしてTiDB Cloudを使用し、AI駆動の開発パートナーとしてKiroを活用しました。
目標:「冷蔵庫の墓場」問題を解決する
今回のミッションは、ユーザーが残り物を“よみがえらせる”ことができるインターフェースを作るという、シンプルながら技術的には難易度の高いものでした。そのためには、パントリー内の食材を認識するための画像認識、LLMによる高度なレシピ生成、そして削減できたCO₂量を記録し続ける仕組みが必要でした。
私たちは次のようなシステムの構築を目指しました:
- Vision-to-Pantry:ユーザーが写真を撮影すると、Geminiが画像から食材を抽出します。
- The Cauldron:食材をドラッグ&ドロップして調理の準備を行うのユーザーインターフェースです。
- Impact Tracking:節約できた金額と削減された炭素排出量をリアルタイムで計算します。
- The Library:“よみがえらせた”レシピ、お気に入り、買い物リストを保存する永続的なストレージです。
課題はAIのロジックだけではありませんでした。重要だったのはデータの整合性です。ユーザー、これまでの節約履歴、保存したお気に入りといった構造化された関係を扱いながら、機能が増えても保守が複雑化しないシステムを構築する必要がありました。
技術スタック:なぜハイブリッドアプローチを選んだのか
データレイヤーを選定するにあたり、私たちの要件には明確な分断があることに気付きました。レシピデータは、LLMが生成するJSONの塊であり、プロンプトによってスキーマが変化する非常に非構造的なデータです。一方で、ユーザー認証やサステナビリティ指標、各種リレーションといったコアとなるビジネスロジックには、厳格なACID準拠が求められました。
そこで私たちは、主要なリレーショナルデータベースとしてTiDBを採用しました。分散SQLデータベースであるTiDBは、PythonのSQLAlchemyで利用できるMySQL互換のインターフェースを提供しながら、アプリが拡散してもインフラの限界に直面しないような水平スケーラビリティを備えています。
さらに、これを補完するために次の技術を採用しました:
- バックエンド:高性能な非同期API処理のため、Python (FastAPI) を採用しました。
- オーケストレーション:画像認識とレシピ生成にはGoogleのGeminiを使用しました。
- 開発ツール:KiroというAIファーストのIDEツールを使用しました。これはModel Context Protocol (MCP) をサポートしており、TiDBのスキーマを直接「認識」して操作することができます。
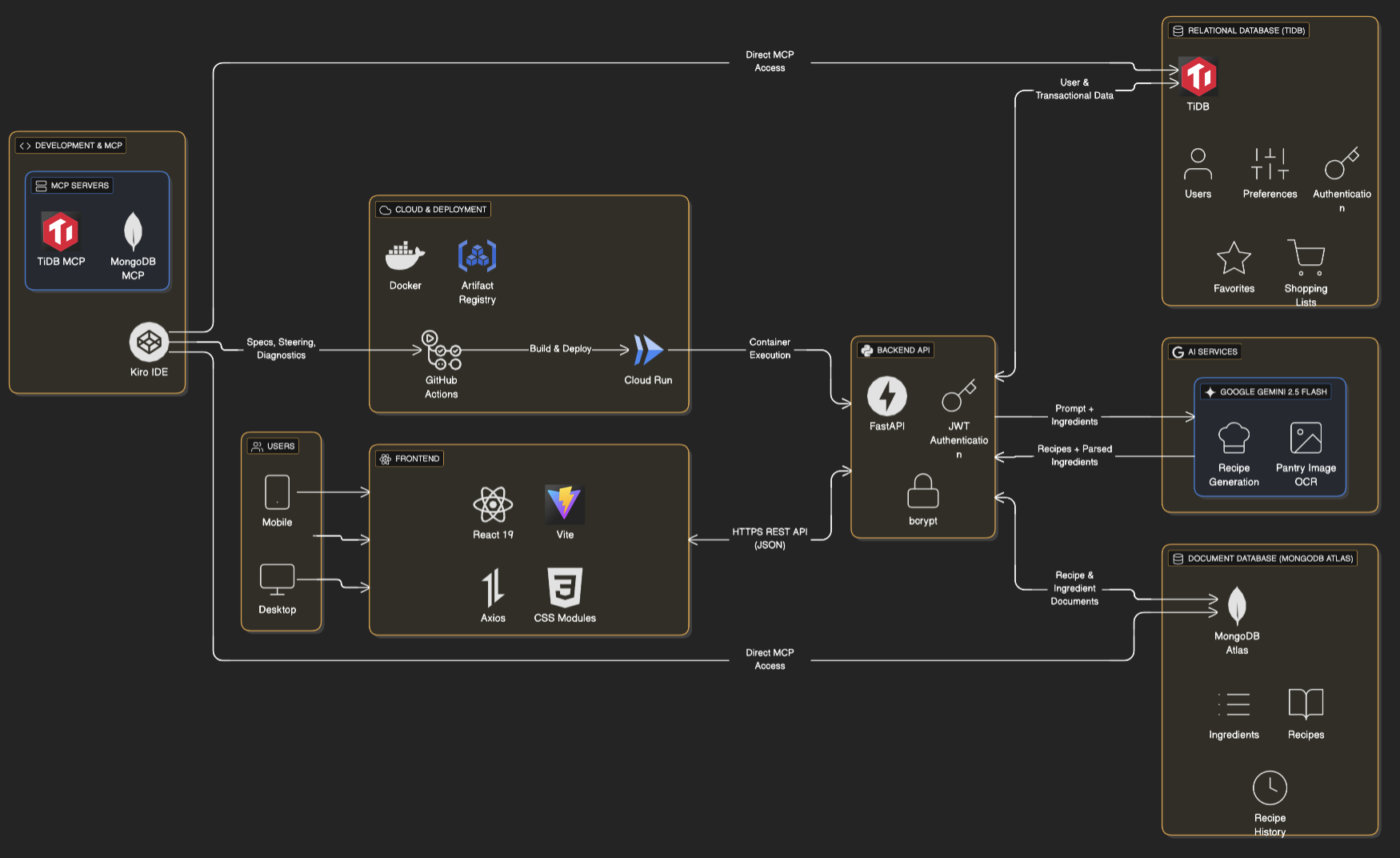
アーキテクチャ:キメラをつなぎ合わせる
AIプロジェクトでよくある失敗は、すべてのデータをドキュメントストアに詰め込んでしまうことです。私たちはこの方法を採りませんでした。Recipe Reanimatorでは、TiDBが「頭脳」として状態管理や関連を担当し、MongoDBが「肉体」(つまりレシピそのもののデータ) を扱う役割を担っています。
私たちはTiDBを、次の3つの重要な領域の管理に利用しました:
- アイデンティティとセキュリティ:ユーザーのハッシュ化された認証情報やセッションデータの管理
- 環境貢献の記録:累積CO₂削減量や金銭的な節約額のトラッキング
- 関連マッピング:ユーザーのユニークIDと、別の場所に保存されている特定のレシピIDを関連付ける処理
この基盤を整えたうえで、次の課題は実際にスキーマを構築することでした。私たちは手作業で定型的なDDLスクリプトを書くのではなく、KiroのMCP統合を活用し、AIアシスタントがTiDBインスタンスに直接やりとりできるようにしました。
実装:生きたスキーマを定義する
初期段階で直面した課題の1つは、「Waste Score (食品ロススコア)」を正確に追跡できるスキーマを定義することでした。食品カテゴリごとの炭素フットプリントに関する履歴データを保存する必要があったためです。私たちはTiDBを活用し、すべての「reanimation (食品の再生)」イベントがユーザーの総合インパクトスコアと確実に紐付くようにしました。
以下のPythonのコードは、PydamicのBaseModelを使用してコアとなるShoppingItemモデルを定義した例です。このモデルは、TiDBのMySQL互換インターフェースとシームレスに連携します。
from pydantic import BaseModel, Field
from datetime import datetime
from typing import Optional
class ShoppingItemCreate(BaseModel):
"""Model for creating a shopping list item"""
ingredient_name: str = Field(..., description="Name of the ingredient")
quantity: Optional[str] = Field(None, description="Quantity needed")
recipe_id: Optional[str] = Field(None, description="Recipe ID this item is for")MCPを介してKiroをTiDBに接続する
最も大きな「なるほど!」という瞬間は、KiroをTiDBインスタンスと連携させたときに訪れました。MCPサーバーを使用することで、Kiroが開発環境内でDESCRIBEやSELECTを実行できるようにしたのです。
たとえば「Favorites (お気に入り)」機能を追加する必要があったとき、私たちは単にAIに「何かコードを書いて」と依頼したわけではありません。代わりに次のように依頼しました。“TiDBにある既存のuserテーブルを確認し、MongoDBのrecipeIDと連携するfavoritesテーブルのリレーショナルスキーマを提案してください。“
AIは実際のスキーマを参照しながらSQLを生成し、そのSQLはKiroのターミナルによって実行されました。Kiroの設定内にあるmcp.jsonファイルでMCPとの接続を設定するため、次のコードを追加しました:
{
"mcpServers": {
"fetch": {
"command": "uvx",
"args": [
"mcp-server-fetch"
],
"env": {},
"disabled": true,
"autoApprove": []
},
"TiDB": {
"command": "uvx",
"args": [
"--from",
"pytidb[mcp]",
"tidb-mcp-server"
],
"env": {
"TIDB_HOST": "gateway01.ap-southeast-1.prod.aws.tidbcloud.com",
"TIDB_PORT": "4000",
"TIDB_USERNAME": "<username>",
"TIDB_PASSWORD": "<password>",
"TIDB_DATABASE": "RecipeReanimator"
},
"disabled": false,
"autoApprove": [
"switch_database",
"show_tables",
"show_databases",
"db_execute"
]
}
}
}
この接続が確立されると、AIは新しく追加されたテーブルやスキーマの更新など、必要なあらゆる情報を即座に把握できるようになりました。これにより、カラム名やデータ型について“ハルシネーション”を起こすことなく、対応するFastAPIのCRUDエンドポイントを生成できるようになりました。
制御ドキュメントでKiroを導く開発ガイド
優れた実験には必ずプロトコル (手順書) が必要です。Kiroはもともと賢いツールですが、私たちは単に「汎用的」なSQLコードを書かせたいわけではありませんでした。私たちのTiDB環境やFastAPIアーキテクチャに自然に適合するコードを書いてほしかったのです。制約のない「vibe coding」は、接続処理の扱い方などに細かな不整合を生みがちであることにも気付きました。
これを解決するために、私たちはKiroのSteeringドキュメントを活用しました。これはプロジェクト全体のルールで、AIにとっての「魔導書」のような役割を果たし、アーキテクチャ上の意思決定を生成ロジックに直接組み込むものです。私たちは.kiro/steering/tech.mdファイル内で、「reanimation」ロジックがデータベースとどのように連携すべきかを正確に定義しました。
これらのルールを設定することで基盤が整いました。AIがどのドライバを使うかを推測するのではなく、pytidbモジュールや私たちの好む接続パターンに沿って動作するようになったのです。これにより、核心的な問題に直面します:負荷がかかった状態でこれらの結果を結合する際、どうやって性能を維持するか、という点です。
TiDBプロトコルの実装
Kiroは私たちのドキュメントによって「誘導」されていたため、FastAPIコードベースではpytidbを用いた直接接続パターンを優先することを理解していました。これにより、全体での「Waste Leaderboard (廃棄量のリーダーボード)」のようなデータベース集約型の新機能を追加する際にも、正しいSSL設定やクエリ構造が常に使用されることが保証されました。
以下のコードは、Steeringドキュメントによる指示を与えた後にKiroが生成したコードの例です。TIDB_DATABASE_URLのフォーマットに厳密に従い、certifiヘルパーを用いてSSL接続を安全でわかりやすく処理している点に注目してください:
from pytidb import TiDBClient
def _reconnect_tidb(self) -> bool:
"""
Reconnect to TiDB if connection is lost.
Returns:
True if reconnection successful, False otherwise
"""
try:
settings = get_settings()
tidb_url = f"mysql+pymysql://{settings.tidb_user}:{settings.tidb_password}@{settings.tidb_host}:{settings.tidb_port}/{settings.tidb_database}?ssl_ca={certifi.where()}"
self._tidb_client = TiDBClient.connect(tidb_url)
self._tidb_connected = True
logger.info("TiDB client reconnected successfully")
return True
except Exception as e:
logger.error(f"Failed to reconnect TiDB client: {e}")
self._tidb_connected = False
return False
これらのガードレールを設けることで、「ハルシネーション」的に生成される接続文字列を修正する手間を排除できました。1,000件の同時接続”を想定した負荷テスト下でも、このプロセスで生成されたコードは高い安定性を維持しました。TiDBの特性を活かし、高トラフィック時に標準的なMySQL環境で見られるようなレイテンシの急上昇なしで、これらの同時接続を処理することができました。
成果とメトリクス:実運用での効果測定
Kiroweenハッカソンの終了時には、Recipe Reanimatorは完全に機能するシステムとなりました。技術スタックがばらばらであったにもかかわらず、一体感のある仕上がりを実現できました。
本番に近いテスト環境 (500人のユーザーが同時に食材を“再生”するシミュレーション)では、TiDB層がユーザープロファイルや影響指標の参照においてP99レイテンシ15ms未満を維持し、リアルタイムのサステナビリティ指標を計算する際に懸念されていたボトルネックを解消しました。
| 指標 | 導入前 (モック/手動) | 導入後 (TiDB + MCP) |
| スキーマ設計時間 | 4時間 | 45分 |
| API開発速度 | 1x | 22.5x (Kiro経由) |
| クエリレイテンシ (P99) | 該当なし | 12-15ms |
| データ整合性 | 頻繁に問題あり | 問題なし |
データからは、TiDBのようなマネージドサービスを使用することで、データベースの信頼性や接続プーリングを気にすることなく、作業の90%をAIプロンプトやゴシック風UIなど“楽しい部分”に集中できたことが示されました。
次のステップ:モンスターにさらなる知能を
Recipe Reanimatorはまだ始まりにすぎません。次のステップとして、TiDBのカラム型ストレージエンジンであるTiFlashを活用し、全ユーザーを対象としたリアルタイム分析クエリを実行する予定です。これにより、コミュニティ全体の影響を示す「グローバルな食材再生レポート」を生成できるようになります。従来のような別途ETLパイプラインを用意せずとも、TiFlashが提供するOLAP性能を活かすことが可能です。
裏側では、TiDBのHTAP設計により、分析処理をライブデータ上で直接実行できます。これは、リアルタイムのインタラクションと分析処理を組み合わせるAIシステムに特に適しています。
AIアプリケーションを構築する際は、データを見つけた最初のストレージに単に格納するのではなく、用途に応じて最適な仕組みを組み合わせる方法を検討しましょう。TiDBを堅牢に管理したい部分に使い、KiroのようなAIツールをコードとデータベースの橋渡しに活用するのです。
ぜひ試してみてください:
- 無料で最初のTiDBクラスタをデプロイする
- Kiro and MCPについて詳しく学ぶ
Related Resources

Product
May 11, 2026
From Preview to Production: TiDB Cloud Dedicated on Microsoft Azure is Now Generally Available

Product
May 1, 2026
How We Built mem9: Lessons From Shipping Persistent Memory for AI Agents
Thought Leadership
April 30, 2026
When AI Agent Memory Outgrows SQLite: How to Tell, and What to Move to Next
TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。