
※このブログは2025年12月10日に公開された英語ブログ「Distributed SQL Database: Architecture, Scale, and High Availability」の拙訳です。
分散データベースとは、複数のノードにデータを分散させるあらゆるシステムを指します。しかし、分散SQLデータベースはその中でもより厳格なサブセットです。完全なSQLセマンティクスとACIDトランザクションを維持し、水平スケーリングのためにデータを自動的にパーティショニングし、Raftなどのコンセンサス・アルゴリズムを用いたレプリケーションを採用することで、書き込みの一貫性と確実ななフェイルオーバーを実現します。端的に言えば、分散型SQLは、手動のシャーディングや不安定なフェイルオーバースクリプトを必要とせず、分散システムとして振る舞うリレーショナルデータベースを提供します。たとえデータが複数のノードにスケールしても、分散SQLデータベースにおけるACIDトランザクションは保たれるのです。
現代のアプリケーションには、弾力的なスケーリング、地理的に分散したユーザー対応、そして障害発生時でも止まらない可用性が求められています。分散型SQLは、まさにそのために構築されました。ダウンタイムなしでのスケールアウト・スケールイン、データレジデンシーを考慮したユーザー近接へのデータ配置、そして自動的なリーダー選出とクォーラム書き込みによるノードやAZ (アベイラビリティゾーン) の障害回避を、標準的なSQLを使い続けながら実現します。
このブログでは、コアとなる構成要素 (パーティショニング、レプリケーション、トランザクション) を定義し、分散型SQLが従来のRDBMSやNoSQLの選択肢と比較してどのようにアプリケーション開発を向上させるかを解説します。また、リアルタイムかつクラウドネイティブなアーキテクチャにおける具体的なメリットについても概説します。
分散SQLデータベースとは何か?
分散SQLデータベースとは、データをノード間にパーティショニングし、Raftなどのコンセンサスによるレプリケーションで高可用性を実現するとともに、大規模環境でもACIDトランザクションを維持するクラウドネイティブなデータベースです。その核心は、クラウドやクラスタの分散特性を活用することで、従来のSQLデータベースが持つスケーラビリティ、可用性、および対障害性を拡張することにあります。
分散型SQLと分散データベースの比較 (およびNoSQLとの比較)
| 分散SQLデータベース | 分散データベース | NoSQLデータベース | |
| SQL対応 | 複雑なクエリや結合を含む、完全なSQLセマンティクスを維持します。 | SQLに対応する場合としない場合があります。スケーラビリティ簡素化のために機能を削ることが一般的です。 | 通常SQL対応はないか制限されており、クエリモデルはエンジンによって異なります。 |
| トランザクション (ACID) | ノードをまたいだ完全なACIDトランザクションを提供します。 | 保証されません。一部のシステムではACID特性を弱めるか、完全に排除しています。 | 複数行 / 複数ドキュメントにわたるACIDは制限されるか提供されず、キー単位の保証に留まることが多いです。 |
| 水平スケーリング | アプリ側のシャーディング論理なしで、水平スケーリングのためにデータを自動的にパーティショニング・複製します。 | データをノード間に分散させますが、スケーリングモデルや保証内容はシステムによって異なります。 | 通常スケーリング性能は高いですが、データモデリングや一貫性のトレードオフをアプリ側で管理する必要があります。 |
| 一貫性モデル | 合意プロトコル (Raft等) を使用しクォーラム合意時のみコミットするため、強力な一貫性と予測可能なフェイルオーバーを実現します。 | システムにより異なり、可用性を優先するものや、結果整合性を採用するものがあります。 | 結果整合性であることが多く、強力な一貫性は (利用可能な場合でも) 制限があるかコストが高くなります。 |
| スキーマと結合 | スキーマ、結合、およびリレーショナルな保証をデータベース側で維持します。 | 一部の設計では、スキーマや結合、その他のリレーショナル機能が排除されています。 | 多くは柔軟なスキーマ (またはスキーマレス) で結合をサポートせず、データの非正規化が必要です。 |
| フェイルオーバー挙動 | 合意形成とレプリケーションの仕組みにより、確実なフェイルオーバーが組み込まれています。 | 実装に依存します。カスタムスクリプトや手動の運用作業が必要になる場合があります。 | 専用のフェイルオーバースクリプトや、アプリ側での注意深いロジックの実装が必要になることが多いです。 |
| アプリ側の複雑性 | 分散の詳細を隠蔽することを目的としており、アプリ側からは単一のSQL DBとして扱うことができます。 | シャーディングや一貫性、リトライ処理などの複雑さがアプリケーションコードに押し出されることがあります。 | トランザクションや制約といったリレーショナルな保証を、アプリ側で再実装しなければならないことが多いです。 |
クラウドネイティブアプリケーションがスケーラブルで耐障害性のあるデータを必要とする理由
クラウドネイティブアプリケーションは、流動的なトラフィック、全世界からのユーザー、そして絶え間ない変化という、妥協できない3つの課題に直面しています。分散型SQLは、ダウンタイムなしのスケーリング、レイテンシ削減のためのユーザー近接へのデータ配置、そして標準SQLを使い続けながらの自動リーダー選出とレプリカクォーラムによるノードやAZ障害の克服を実現することで、これらの要件を満たします。
これは業務において極めて重要です。季節的なトラフィック急増のたびにリシャーディングプロジェクトを行う必要はなくなり、マルチリージョンでのデータベース展開においても、データ局所性を考慮した配置やフォロワーリードによってSLOを達成できます。また、バックグラウンドタスクとトランザクションの一貫性により、オンラインのままローリングアップデートを進行できます。その結果、データレイヤーは高速、正確、かつ高可用であり続けます。これこそが、メンテナンス時間や障害対応に追われることなく新機能をリリースするために、クラウドネイティブサービスが必要としているものです。
分散型SQLアーキテクチャ (仕組み)
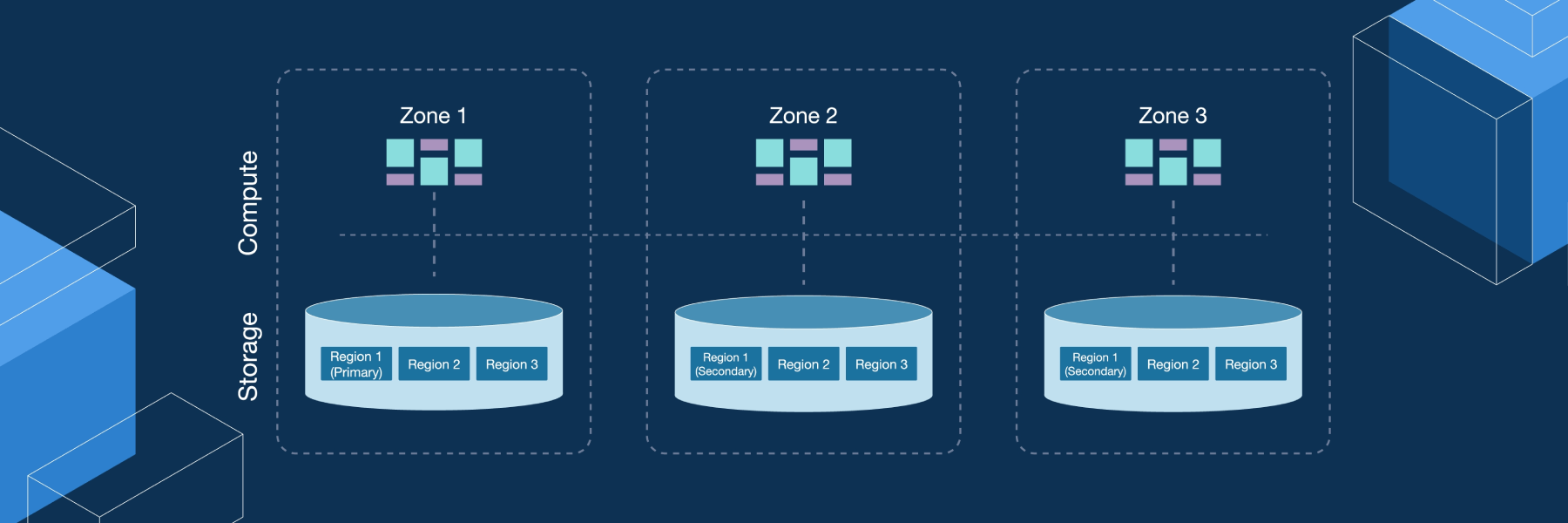
分散SQLデータベースのアーキテクチャは、主に2つのレイヤー、すなわちコンピューティングレイヤーとストレージレイヤーに分かれています。
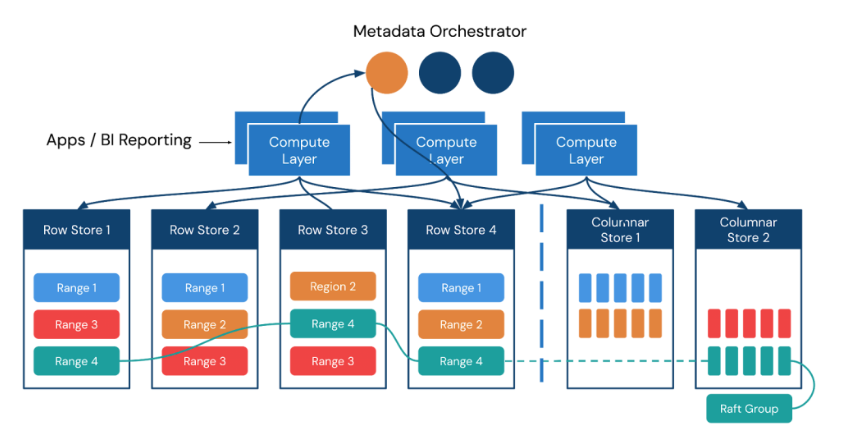
図1. 典型的な分散型SQLデータアーキテクチャ
コンピューティングレイヤーとストレージレイヤー
コンピューティングレイヤーは、外部に対してSQLプロトコルの接続エンドポイントを公開するステートレスなSQLレイヤーです。コンピューティングレイヤーはSQLリクエストを受信し、SQLの解析と最適化を行い、最終的に分散実行プランを生成します。このレイヤーは水平スケーラブルであり、ロードバランシングコンポーネントを通じて外部に統一されたインターフェースを提供します。このレイヤーの役割は、SQLの計算と分析、およびストレージレイヤーへの実際のデータ読み取りリクエストの送信のみに限定されます。
ストレージレイヤーは、分散トランザクション対応キーバリューストレージエンジンを使用したデータ保存を担います。リージョンはデータを保存する基本単位です。各リージョンは特定のキー範囲のデータを保存し、これはStartKeyからEndKeyまでの左閉右開区間となります。
各ストレージノードには複数のリージョンが存在します。ストレージAPIは、キーバリューペアレベルで分散トランザクションをネイティブにサポートしており、デフォルトでスナップショット分離をサポートしています。これが、分散SQLデータベースがコンピューティングレイヤーで分散トランザクションをサポートする仕組みの核心です。
SQL文の処理後、コンピューティングレイヤーはSQL実行計画をストレージレイヤーAPIへの実際の呼び出しに変換します。これにより、ストレージレイヤーにデータが保存されます。ストレージレイヤーのすべてのデータは、自動的に複数のレプリカ (デフォルトでは3レプリカ) で維持されます。これらのレプリカにより、ストレージレイヤーにネイティブな高可用性と自動フェイルオーバー機能が備わります。
データパーティショニングとデータベースシャーディング (およびそれぞれの適用タイミング)
このセクションでは、実務におけるデータベースシャーディングとデータパーティショニングの違い、あるいはデータベースがレンジを自動分割すべきケースとアプリレベルのシャーディングが依然として有効なケースについて解説します。
データパーティショニングは、データ量や負荷の増加に応じて、テーブルやキースペースをレンジ/リージョンに分割し、ノード間で自動的にバランス調整を行うシステム管理の手法です。アプリケーション側は単一の論理データベースを維持し、プラットフォーム側がパーティションの移動、ホットレンジの分割、関連するキーの同一ノード配置を行うことで、レイテンシーを予測可能な状態に保ちます。
データベースシャーディングは、多数の独立したデータベースやスキーマを作成するアプリケーション管理の手法です。機能はしますが、ルーティング、再シャーディング、フェイルオーバー、およびシャードをまたぐクエリの管理はユーザー側の責任となります。
それぞれの使い分けは以下の通りです。
- データパーティショニング:ルーティングロジックや再配置の労力が不要になるため、ほとんどのワークロード (特にマルチテナントSaaSやイベント集約型システム)に適しています。
- データベースシャーディング:アプリレベルのシャーディングは、例外的な制約(法的な隔離、テナントごとの厳格なSLA、レガシーな境界)がある場合にのみ使用し、その場合でも各シャード内部ではデータベースによるパーティショニングを維持することを目指すべきです。
データベースレプリケーションと高可用性のためのRaftコンセンサス
分散型SQLは各パーティションを複数のノードに複製し、Raftコンセンサス (あるいは類似のクォーラムプロトコル) を用いて書き込みを調整します。リーダーが変更を提案し、フォロワーがログエントリを複製、過半数がそれを承認した時点で書き込みがコミットされます。リーダーが故障した場合、クラスターは新しいリーダーを自動的に選出するため、クライアントは一貫性のある読み取り/書き込みを継続できます。
以下が重要な理由です。
- 確実なフェイルオーバー:過半数の合意によりスプリットブレインを防ぎ、コミット済みのデータを保護します。
- 障害ドメイン:レプリカはゾーン/リージョンをまたぐことができるため、ノードやAZの障害を回避できます。
- 読み取りオプション:フォロワーはフォロワーリード (過去のデータを許容する読み取り) を提供でき、書き込みの一貫性を損なうことなく、リージョン間のレイテンシを削減できます。
大規模環境におけるACIDトランザクション (MVCC、悲観的 vs 楽観的)
分散型SQLは、スナップショット読み取り用の多版型同時実行制御 (MVCC) と、書き込み用の悲観的または楽観的トランザクションモードを使用することで、パーティションをまたいだACID特性を維持します。
- 悲観的:最初の書き込みリクエストで行をロックします。競合が多く、競合発生時のコストが高い長時間実行トランザクションに最適です。
- 楽観的:ロックなしで処理を進め、コミット時に検証を行います。競合が少なく、高スループットなワークロードに最適です。
プランナーとKV間のコーディネーションにより、2位相コミットとキーごとのタイムスタンプを用いて、複数行または複数テーブルにわたる操作のトランザクション性を保証します。これにより、書き込み側が安全に処理を進める一方で、読み取り側は一貫したスナップショットを参照できます。
マルチリージョン展開におけるCAP定理のトレードオフ
分散システムにおけるCAP定理の文脈では、ネットワーク分断の発生時に完全な一貫性と可用性を同時に両立させることはできません。分散型SQLシステムは通常、CP (一貫性+分断耐性) を選択した上で、配置および読み取り戦略を駆使することで高い可用性と低レイテンシを維持します。
- データ局所性を考慮した配置:リーダーを書き込みパスの近くに配置し、クォーラムレプリカを障害ドメインをまたいで保持します。
- フォロワー / ラーナーリード:近接するレプリカから一定の過去のデータを許容する読み取りを提供することで、リージョン間のRTTを削減します。
- レイテンシーバジェット:書き込み負荷の高いグローバル分散アプリでは、書き込みのたびに地球規模のクォーラムが発生するのを避けるため、地域ごとの書き込みルーティング (テナント単位またはキー単位) を検討します。
その結果、書き込みに対する実用的な強い一貫性と、ローカル接続に近い読み取りパフォーマンス、そして障害発生時の洗練された振る舞いが実現されます。
分散型SQLが現代のアプリケーション開発を向上させる理由
近年、分散SQLデータベースは、リレーショナルデータベースに代わるポピュラーな選択肢として台頭してきました。これらは従来のSQLデータベースとNoSQLデータベース双方の利点を兼ね備えています。また、混合ワークロードのより効率的なデータ処理や、複数ノードにわたるストレージ構成を可能にします。
なぜ分散SQLデータベースが現代のアプリケーション開発を向上させるのか、そして従来のデータベースシステムと比較してどのような利点があるのかを詳しく見ていきましょう。
予測不可能なワークロードに対応する弾力的なスケーリング (スケーラブルなデータベース)
現在のデータ駆動型の世界において、組織はかつてないスピードで膨大なデータを生成・収集しています。ユーザーのインタラクションからIoTデバイスに至るまで、データの量、速度、多様性は拡大し続けています。
その結果、企業はこの増え続けるデータをいかに効果的に管理・処理するかという大きな課題に直面しています。分散SQLデータベースは、こうした増大するデータ要件に対処するための堅牢なソリューションとして登場し、以下の機能を提供します。
- 拡張性のあるデータストレージ:単一のサーバーに依存するのではなく、クラスタ内の複数のノードにデータを分散させます。データ量が増加しても、クラスタに新しいノードをシームレスに追加できるため、水平スケーリングが可能です。
- 弾力的なコンピューティングパワー:分散SQLデータベースは、そのアーキテクチャの分散特性を活かし、クエリの実行を複数のノードに分散させます。この並列処理能力により、組織はクラスター全体の合算された計算能力を活用できます。その結果、クエリのレスポンスタイムが短縮され、システム全体のパフォーマンスが向上します。
- データ圧縮と最適化:データを圧縮することでストレージの占有領域を削減し、同じインフラ内でより多くのデータを保存することを可能にします。
常時稼働、耐障害性データベース (障害ドメイン、AZ / リージョン対応)
組織は、卓越したユーザー体験を提供する、高いスケーラビリティと常時稼働性を備えたアプリケーションの提供を目指しています。しかし、リアルタイムの応答性を必要とする現代のアプリケーションが求めるスケーラビリティと可用性の要求に、従来のデータベースシステムはしばしば対応しきれない状況にあります。
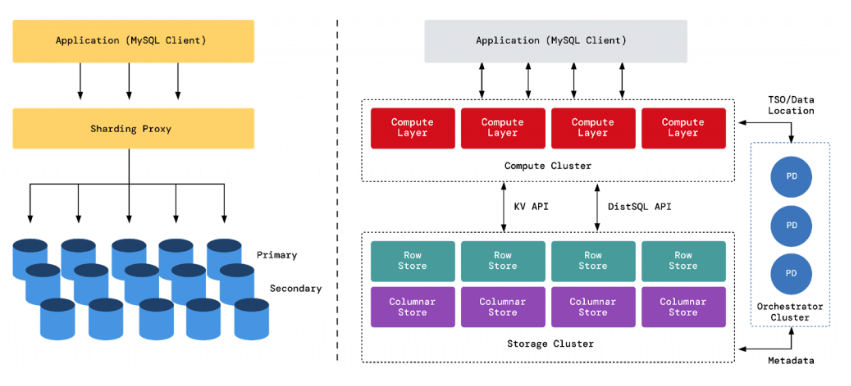
図2. 技術的な複雑さを伴うシャーディングを実装した従来型データベースシステムの例と、Raftレプリケーションと自動フェイルオーバーを備えた分散SQLデータベースシステムの比較
分散SQLデータベースは、これらの課題に対処し、アプリケーションのスケーラビリティと可用性を大幅に向上させる強力なソリューションとして登場しました。その仕組みは以下の通りです。
- 分散クエリ実行:クエリのワークロードをクラスタ全体に分散させることで、分散SQLデータベースは各ノードの集合的な計算能力を活用できます。これにより、複雑なクエリのレスポンスタイムを効果的に短縮します。
- ストレージとコンピューティングの分離アーキテクチャ:ストレージとコンピューティングを分離したアーキテクチャでは、異なる機能が2種類のノード (書き込みノードとコンピューティングノード) に分割・割り当てられます。これにより、必要に応じてデプロイする書き込みノードとコンピューティングノードの数を個別に決定できます。
- インテリジェントなデータ配置:分散SQLデータベースは、複数のアベイラビリティゾーン (AZ) にあるデータノード間でデータをインテリジェントに分散・複製し、高可用性と対障害性を提供します。これは、単一のノードまたは半数未満のノードが故障してもシステムが動作し続けられることを意味し、従来のモノリシックなデータベースでは決して達成できない特性です。
要約すると、高可用性が標準で組み込まれています。データは障害ドメイン (ノード、AZ、リージョン) をまたいでクォーラムによって複製され、障害時にはリーダーが自動選出されるため、書き込みの一貫性が保たれ、サービスが継続されます。ヘルスチェック、Raftタイムアウト、および配置ポリシーによってフェイルオーバーが確実になり、カスタムスクリプトなしで厳格なSLOを満たす常時稼働の姿勢を実現します。
よりシンプルなスタック—手動のシャーディング不要、可動部品の削減
分散型SQLでは、データベースがパーティショニング、リバランシング、およびフェイルオーバーを処理するため、シャードルーターや再シャーディングジョブ、独自のHAツール群を廃止できます。パーティションをまたぐトランザクション、オンラインDDL、およびローリングアップデートはプラットフォーム内部で実行されるため、運用の対象領域が削減されます。コンポーネントが減ることは、インシデントの減少、そして新機能の開発に充てられる時間の増加を意味します。
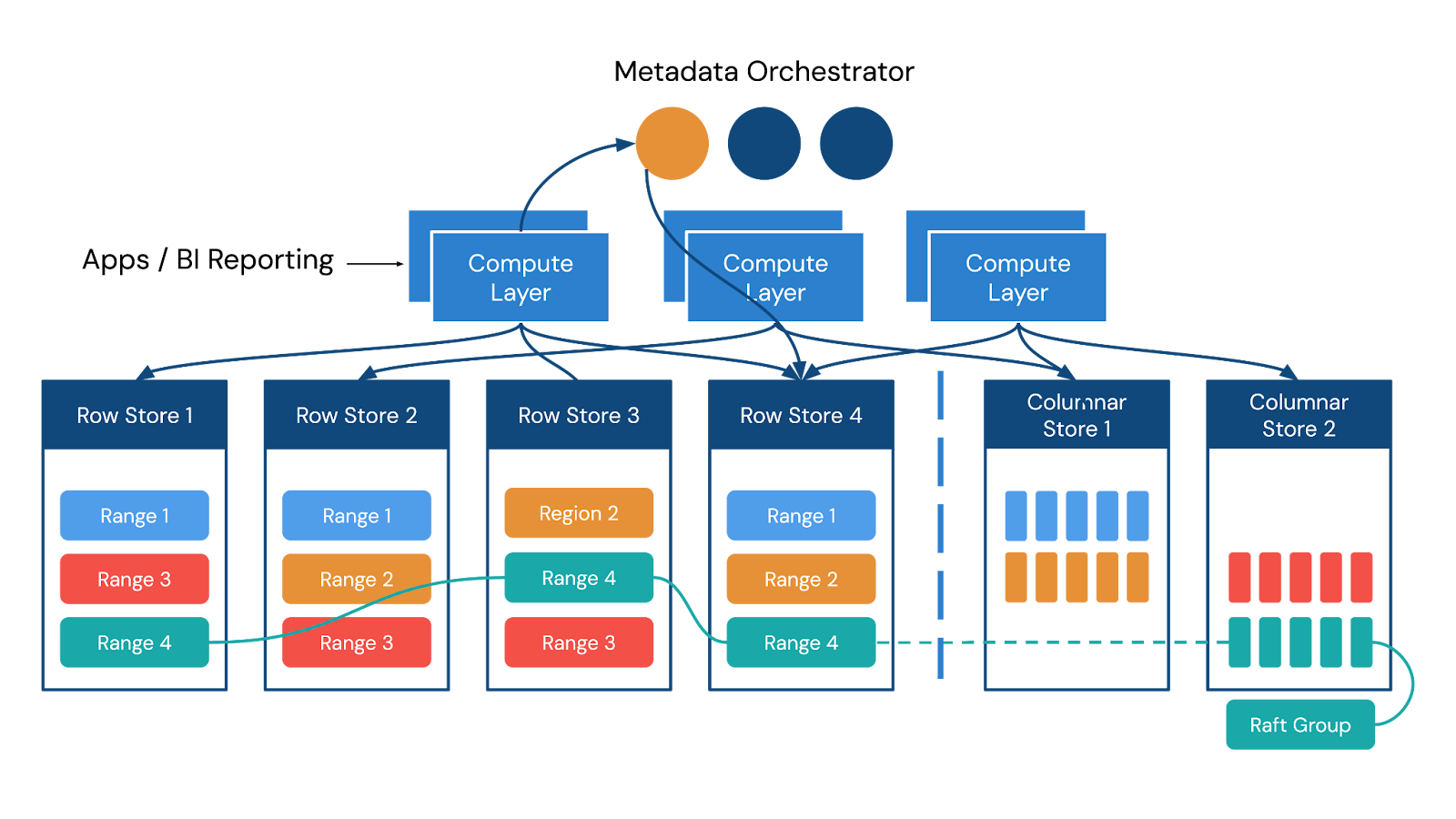
図3. 現代的なトランザクションアプリケーション向けにスケーラビリティと信頼性を備えた分散型SQLアーキテクチャの例。トランザクションデータに対するリアルタイム分析を組み合わせたもの。
分散SQLデータベースは、複雑化した技術スタックを整理し、アーキテクチャを簡素化し、データ管理に伴う複雑さを軽減することで価値あるソリューションを提供します。
- 統合されたデータ管理:分散SQLデータベースは、異なるデータ管理ニーズを単一の統一されたシステムに統合します。データ管理を統合することで、組織は技術スタックを簡素化し、統合に関する課題を減らし、運用を効率化できます。
- エコシステムツールやフレームワークとの統合:これらのデータベースは、主要なエコシステムツールやフレームワークとシームレスに統合できるように設計されています。プログラミング言語、フレームワーク、およびデータ処理プラットフォームと統合するためのコネクタやAPIを提供します。
- 簡素化されたデータ運用:分散SQLデータベースは、自動化および管理ツールを標準で備えています。ノードを1つずつアップグレードすることで実行中のクラスターへの影響を最小限に抑える、自動ローリングアップデートを活用しています。また、分散型データベースクラスター全体に対して統一されたビューと制御を提供する、直感的なウェブベースのインターフェースやコマンドラインツールも提供しています。
主なユースケースとパターン
分散型SQLが特に大きな価値を発揮する代表的な場面と、本番環境で機能させるためのパターンは以下の通りです。
SaaSマルチテナント、フィンテック耐障害性、Eコマースピークイベント
- SaaSマルチテナント:テナントの隔離を維持しながらハードウェアを共有します。自動パーティショニングとテナントごとのリソース制御を使用して、ノイジーネイバーを防止し、アクティブなテナントをユーザーの近くに配置し、手動のシャーディングなしでティアを個別にスケーリングします。
- フィンテックのレジリエンス:決済、元帳、リスク管理において、クォーラムレプリケーションと確実なフェイルオーバーを備えたACIDトランザクションを実行します。稼働時間と監査の要件を満たすため、営業時間内にオンラインDDLやローリングアップデートを実施できます。
- Eコマースのピーク対応:弾力的なスケールアウト / インとデータ局所性を考慮した配置により、フラッシュセールや季節的な需要変動を吸収します。重い読み取り処理を分析用レプリカに逃がし、書き込みパスを購入者の近くに固定することで、チェックアウト時のレイテンシを安定させます。
クラウドネイティブデータベース運用とゼロダウンタイムアップグレード
Kubernetes / クラウドスタックと同様の運用を実現:宣言型変更、健全性に基づくロールアウト、自動修復。分散型SQLはオンラインスキーマ変更、ローリングバージョンアップグレード、SLOを遵守するバックグラウンドタスク (インデックス構築、コンパクション) をサポートします。CI/CDと統合し、スキーマをコードとして扱い、事前チェック (レイテンシ / ラグ予算) を追加し、分単位のRPO/RTOでバックアップ / リストアを活用することで、メンテナンスウィンドウなしで機能を継続的にリリースできます。
実装チェックリスト
以下のチェックリストを使用して、概念を本番環境対応の計画に落とし込みます。キーとパーティションを実際のワークロードにマッピングし、レプリカ / クォーラムとリーダー配置を設定し、マルチリージョントポロジのレイテンシ予算を定義し、運用開始後のサービス開始後の運用に必要な可観測性と障害テストを確定させます。
パーティショニング戦略、レプリケーション/コンセンサス、スキーマおよびインデックス
- キーとアクセスパス:最も頻度の高いクエリに合わせた主キーを選択してください (例:(
tenant_id,created_at))。ホットスポットを発生させる単調増加キーは避けてください。 - パーティショニングヒント:レンジの分割はデータベースの自動分割に任せてください。明示的なパーティショニングの追加は、リージョンサイズの制限やアーカイブデータの隔離を目的とする場合に限定してください。
- レプリカファクターとクォーラム:障害ドメインごとにレプリカ数を設定してください (例:AZをまたいで3)。クォーラム間の距離に対する書き込みレイテンシを検証してください。レプリカ数は奇数を推奨します。
- リーダーの配置:書き込み負荷の高いワークロードの近くにリーダーを固定してください (テナントごと、またはキーごとのローカリティ)。
- インデックス設計:頻繁に使用されるフィルターには選択性の高いセカンダリインデックスを作成してください。書き込み増幅とストレージオーバーヘッドを検証してください。読み取り中心のエンドポイントにはカバリングインデックスを追加してください。
- DDLの安全性:レートリミット付きのバックフィルを備えたオンラインDDLを使用してください。変更はフィーチャーフラグ管理下で段階的に実施してください (先にデプロイし、後で有効化)。
レイテンシ予算とトポロジ設計
- APIごとのバジェット:重要なエンドポイントごとにp50 / p95 / p99のターゲットを定義します (例:チェックアウトのp99≦300ms)。そこから逆算して各区間ごとのSLO (DBがバジェットの50%以下など) を決定してください。
- 読み取りのローカリティ:一定の過去のデータを許容するクエリには、フォロワー / ラーナーリードを使用してください。OLTPの読み取り/書き込みはリーダーと同じ場所に配置し続けます。
- 書き込みのローカリティ:地球規模のクォーラムを避けるため、テナントまたはシャードキーごとに、書き込みをリージョン内のリーダーにルーティングしてください。
- データレジデンシ:データやテナントにリージョンラベルを付与してください。配置ポリシーを適用し、境界を越えたデータフローを検証してください。
- フェイルオーバーの体制:クラウドリージョンごとに予備リーダー候補を事前に計算しておきます。AZの消失やクラウドリージョンからの退避に関するランブックをリハーサルしてください。
- コストとレイテンシのトレードオフ:展開前に、追加レプリカやクラウドリージョン間リンクによる影響をモデリングしてください。
可観測性、サービスレベル目標 (SLO)、障害テスト
- ゴールデンシグナル:QPS、p95 / p99レイテンシー、エラー率、Raftの健全性 (リーダー選出、ログの遅延)、TiKVリージョン / パーティションのホットスポット、およびコンパクション / バックフィルのキューに関するダッシュボードを標準化します。
- テナント別の視点:ノイズィネイバーを早期に検知するため、テナントやティアごとにメトリクスを分類します。ティアごとのバジェット超過をアラート通知します。
- トレースと実行計画:実行計画を含むスロークエリのサンプルをキャプチャします。リリースやDDL実行後の実行計画の乖離を追跡します。
- SLOとエラーバジェット:APIおよびリージョンごとにSLOを公開します。デプロイの可否判定やスロットリングを、残りのエラーバジェットと連動させます。
- バックアップとリストアの訓練:分単位のRPOと時間単位のRTOを目標に設定します。PITRとテーブルレベルのリストアを四半期ごとにテストしてください。
- 障害訓練:AZ消失、リーダー消失、およびネットワークリンクの瞬断のシミュレーションを計画します。自動フェイルオーバー、クライアントのリトライ挙動、およびp99が合意された範囲内に収まることを検証してください。
TiDB (分散型SQL) をはじめよう
分散型SQLでMySQLワークロードを近代化したい場合は、まずマネージドクラスタ上でスケーリング、フェイルオーバー、およびオンラインDDLを検証することから始めてください。モダンなアプリケーションを支える適切な分散SQLデータベースの選択は困難を伴う場合があります。しかし、組織とともに進化し続けることができる、より優れた選択肢があります。それがTiDBです。TiDBは、クラウドネイティブ、データ集約型、およびAI駆動型アプリケーションのために構築されたオープンソースの分散SQLデータベースです。
TiDBは、弾力的なスケーリング、リアルタイム分析、およびデータへの継続的なアクセスにより、あらゆるモダンなアプリケーションを強力にサポートします。スケールアウト型RDBMSやインターネット規模のOLTPワークロードにTiDBを採用している企業は、以下のような特徴を持つ分散型データベースの恩恵を受けています。
- MySQL互換:世界で最もMySQL互換性の高い分散SQLデータベースを活用できます。TiDBはMySQL5.7とプロトコル互換性があります。これにより、開発者は豊富なツールやフレームワークのエコシステムを引き続き利用できます。
- 水平スケーラブル:TiDBは、手動のシャーディングなしでデータワークロードに対する完全な透過性を提供します。データベースのアーキテクチャがコンピューティングとストレージを分離しているため、必要に応じてデータワークロードを即座にスケールアウト / インできます。
- 高可用性:TiDBは、システム停止やネットワーク障害時でもデータへの継続的なアクセスを可能にするため、自動フェイルオーバーと自己修復を保証します。
- 強い一貫性:TiDBは、データをグローバルに分散させる際もACIDトランザクションを維持します。
- 混合ワークロード (HTAP) 対応:合理化された技術スタックにより、リアルタイム分析が容易になります。TiDBのスマートクエリ最適化エンジンは、一連のオペレーターで構成される最も効率的なクエリ実行計画を選択します。
- ハイブリッドおよびマルチクラウド対応:TiDBを使用すると、ITチームは世界中のどこにでも、パブリック、プライベート、およびハイブリッドクラウド環境において、VM、コンテナ、またはベアメタル上にデータベースクラスターをデプロイできます。
- オープンソース:Apache2.0ライセンスのもとで100%オープンソースである分散型データベースにより、ビジネスイノベーションを解き放ちます。
- セキュリティ:TiDBは、転送中および保存中のデータの両方をエンタープライズレベルの暗号化で保護します。
デプロイメントの選択 (マネージドクラウド vs セルフマネージド)
- マネージド分散SQLデータベース (TiDB Cloud):価値を実現するための最短ルートです。自動化されたプロビジョニング、スケーリング、バックアップ、アップグレード、および24時間365日の運用が提供され、パイロットプロジェクト、SaaS製品、またはインフラよりも機能開発に集中したいチームに最適です。迅速な検証、予測可能なSLO、および最小限の運用オーバーヘッドが必要な場合は、このオプションを選択してください。
- フルコントロールのためのセルフマネージドTiDB:独自のVM、コンテナ、またはベアメタル上で完全に制御可能です。トポロジー、セキュリティ管理、およびメンテナンスウィンドウを自社で管理できるため、特殊なネットワーキング/コンプライアンス要件、カスタムのオブザーバビリティ、または詳細なパフォーマンスチューニングが必要な場合に適しています。SREチームが体制として整っており、厳格なプラットフォーム制約がある場合は、このオプションを選択してください。
デモ、ドキュメント、およびフリートライアルCTA
- サンプルアプリのクローン:実際のワークロード (またはsysbench) をTiDBに向けて実行してください。バースト時の読み取り/書き込みレイテンシを検証し、MySQL互換性によってアプリケーションコードの変更が不要であることを確認してください。
- ドキュメントの深掘り:アーキテクチャ (コンピューティングとストレージの分離、Raft)、マルチリージョン向けの配置ルール、およびテナントの隔離とコスト制御のためのリソースグループを確認してください。
- 10分間のクイック検証:無料のTiDB Cloudクラスタを起動し、同時コネクション負荷、巨大なテーブルに対するオンラインDDL、およびローリングアップデートやフェイルオーバーをテストしてください。p95 / p99およびエラー率をキャプチャし、自社のSLOと比較してください。
FAQ
分散型SQLを使用する場合でも、データベースのシャーディングは必要ですか?
一般的には不要です。分散型SQLは、単一の論理データベースの背後で自動的なパーティショニングとリバランシングを処理するため、シャードルーターや再シャーディングのワークフロー、あるいはシャードをまたぐ結合を管理・維持する必要はありません。法的な隔離やテナントごとの厳格なSLOを目的としてデータをセグメント化することはあるかもしれませんが、その場合でも各セグメント内部はデータベースによって自動パーティショニングされた状態を維持できます。
Raftコンセンサスはどのようにしてデータベースの高可用性を保証するのですか?
各データパーティションは複数のレプリカを保持します。書き込みはRaftを介したクォーラム (過半数) によってのみコミットされます。リーダーが故障した場合は新しいリーダーが自動的に選出され、スプリットブレインを防ぎながら一貫性を維持してサービスを継続します。これにより、ノード、AZ、またはリージョンをまたいだ予測可能なフェイルオーバーが可能になります。
CAP定理はACIDトランザクションを利用できないことを意味しますか?
いいえ。CAPはネットワーク分断が発生している際に適用される定理です。分散型SQLシステムは通常、CP (一貫性+分断耐性) を選択した上で、データ局所性を考慮した配置やフォロワー / ラーナーリードを活用することで、高い可用性と低レイテンシーを維持します。実際のアプリケーションにおいて、実用的なパフォーマンスとACIDトランザクションを両立させることが可能です。
分散型SQLと分散型データベースの違いは何ですか?
「分散型データベース」は、多くのノードと多様な設計を含む広義のカテゴリです。分散型SQLはそのサブセットであり、コンセンサスレプリケーションと自動パーティショニングによって完全なSQLとACIDを維持するものを指します。そのため、手動のシャーディングやカスタムのフェイルオーバースクリプトを必要とせずに、水平スケーリングと強い一貫性を実現できます。
TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。