
TiDB 5.2のリリースをここに発表します。エンタープライズグレードのデータベースであるTiDBは、オンライントランザクション処理(OLTP)機能とオンライン分析処理(OLAP)機能を備えており、大量のデータを処理することができます。これらの機能は、金融、インターネット、ロジスティクス、小売、オンラインゲームなどの世界のさまざまな業界で徹底的に試験された後、現在は高い評価を受けています。
上記業界のますます多くの企業が、その規模の大小に関係なく、変化し続ける市場にどのように適応していくか、あるいはこの市場をどのようにリードしていくかという課題に直面しています。競争的優位を確保しようとする企業に必要なのは、鮮度の高いデータに基づく意思決定を行うこと、およびビジネスに関する、唯一の信頼できるリアルタイムの情報源を得ることです。しかし、以下に挙げる大きな課題が立ちはだかっています。
- 無秩序に散在するデータサイロからインサイトを引き出すには、複雑な作業が必要になる。
- レガシーデータベースインフラストラクチャでは、トラフィックの突発的な増加に対応できない。
- テクノロジースタックが複雑なため、高度なメンテナンスが必要になる。
- インテリジェントなリアルタイムサービスの需要を満たすには、データをコンスタントに変更しなければならない。
- ビジネス成長に対応するため、広範囲に及ぶインサイトを迅速に獲得しなければならない。
- 高可用性とビジネス継続性を確保しつつ、セキュリティ要件やコンプライアンス要件を満たす必要がある。
企業からのフィードバックに基づき開発されたTiDB 5.2は、実世界のシナリオに重点を置いており、大規模なリアルタイムデータ処理の需要に応えるため、トランザクション処理や分析処理の境界をさらに広げることを目指しています。テスト結果によると、TiDB 5.2は安定性、リアルタイムパフォーマンス、ユーザービリティの面でTiDB 5.1をアウトパフォームしています。高負荷の大規模クラスタの場合でも、同時実行性の高い書き込みや読み取りの場合でも同様の結果がでています。企業がビジネスのポテンシャルを引き出し、デジタルトランスフォーメーションを促進させる上で、TiDB 5.2は今後も役に立つはずです。
この記事で取り上げているTiDB 5.2の特徴は、全体の一部のみです。特徴と改良点すべてを確認したい場合は、TiDB 5.2リリースノートをご覧ください。
TiDB 5.2の特徴
ここ数年、ますます多くの企業が、どのように全データをリアルタイムで照会すればいいのか、あるいはどのように分析すればいいのか、懸命に模索しています。ビジネス要件を満たすため、各シナリオでそれぞれ違ったデータストレージソリューションに頼っており、やむを得ずオンラインデータとオフラインデータが分離した状態に甘んじています。しかし、このような状況下では、データはサイロ化され、データスタックは複雑なものになる可能性があります。現在、ビジネスの全体像を把握することがますます難しくなってきています。TiDBはこうした問題を解決するために開発されました。TiDBを利用すれば、データスタックをシンプル化し、データベースを本来あるべき姿に戻すことができます。TiDB 5.2は、以下の魅力的な新機能を備えたことで、さらに一歩進化しました。
高負荷下でも、フリクションレスなカスタマーエクスペリエンスを実現
ミッションクリティカルなアプリケーションにおいて、安定的かつフリクションレスなカスタマーエクスペリエンスを維持するには、クエリ遅延を低く抑える必要があります。特に書き込み負荷が高い場合はこのことが言えます。これらのほとんどがポイントクエリであり、一部にはショートレンジのインデックスベースのクエリが含まれています。この場合、プライマリ/セカンダリアーキテクチャを採用することによって、MySQLのスケーラビリティの制限に対処することができます。複数のMySQLシャードからのアップストリームデータは、DMデータ移行ツールによって、TiDBクラスタに集約されます。その後、TiDBサーバーがデータ転送プロセスからの集約型クエリを処理し、各トランザクションをスムーズに処理できるようにします。
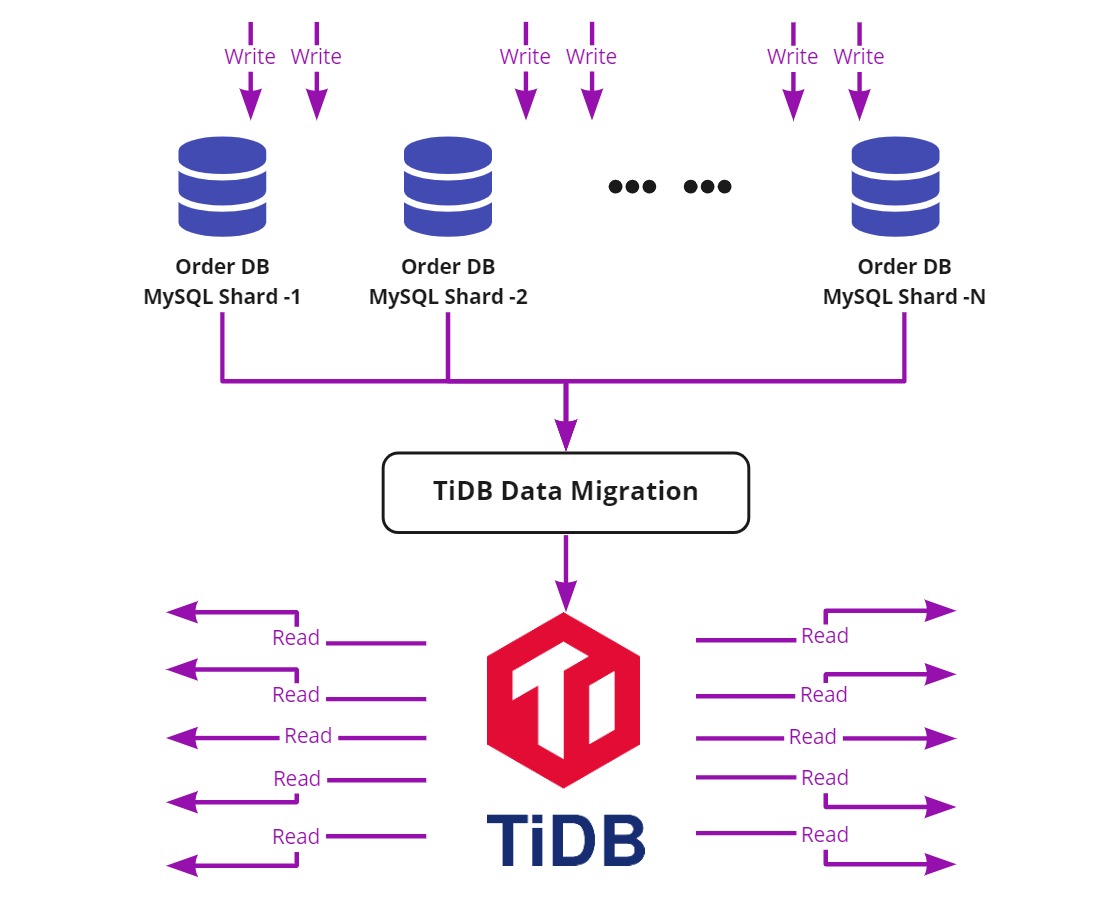
書き込み負荷が高い状況下における大規模クラスタの安定性を改善
今回のリリースでは、データ定義言語(DDL)ステートメントを実行する際、データ領域の範囲のバランスがとられるようになったほか、大きなテーブルをより迅速にインデックス付けできるようになりました。
ストレージノードの速度が遅い場合は、トラフィック管理のため、Leaderは通常動作している他のノードに自動的に転送されます。単一ノードでジッターが発生した場合でも、この機能により、クラスタ全体の全体的スループットが確保されます。
RaftログキャッシュとRaftメッセージのメモリ使用量が厳しく制限されているため、書き込み負荷が高い状況下でも、TiKVにOOM問題は発生しません。
クラスタリソースの使用量を最適化
TiDB 5.2では、QPSに基づき、ホットスポットに優先順位を付け、クラスタリソースのバランスをとることができます。クラスタのCPU分散をよりバランスのとれたものにすることで、単一ノードによって生じるボトルネックを回避することができます。パフォーマンスを検証するため、小さなテーブル内でホットスポットを監視するというシナリオをシミュレーションしたところ、CPU使用率が大幅に最適化され、QPSがほぼ2倍になりました。また、TiDB 5.2では、TiFlashの分析処理(AP)エンジンのホットスポットをスケジューリングすることができます。これにより、HTAPシナリオでのロードバランシングが大きく一歩前進することになります。
データ移行の効率性が向上
DMのバージョンが古いほど、消費されるCPUリソースは多くなります。例えばDMノードがバイナリログ複製を実行する場合において、QPSが1,000~3,000に達したときは、そのCPUリソースの消費率は35%~50%になります。こうした問題を解決するため、DM v2.0.6には、リレーログの読み取り/書き込みやデータコード変換など、いくつかの改善が施されています。テスト結果によると、DM v2.0.6ではCPUの使用率を最大50%下げることができます。
また、今回のリリースによって、データ複製の遅延も最適化されます。MySQLシャードからの書き込みを複製し、それをTiDBに集約する場合(推定される集約後のQPSは200,000)、DMは複製の遅延をほぼ間違いなく1秒未満に低減できます。
よりインテリジェントなデータ検索
eコマースプラットフォームの場合、大々的なセール期間中は、クエリが通常の数十倍になり、クエリパフォーマンスが低下する場合があります。このようなケースでは、クエリの対象は通常、ショートレンジのインデックスベースデータです。考えられる要因には、多様なクエリステートメント、複数テーブルの結合クエリ、データ集約、サブクエリ、TopN演算子、ページネーション制限などが含まれます。また、企業によって保有しているデータ量が異なることも、データ処理に影響を与えます。
クエリの効率を改善するには、よりインテリジェントなオプティマイザーが必要です。そうすれば、データベースは正確なインデックスによって最適な実行プランを選択し、その結果をより迅速かつ安定的に返すことができます。
インデックス選択を改善
TiDBでは、統計データに基づいてインデックスが選択されています。TiDB 5.2では、統計データが陳腐化または欠落した場合、TiDBオプティマイザーが最初にヒューリスティックスルールを有効化し、選択しうるインデックスの数を減らします。これによって、インデックス選択の正確性が高まります。
また、コスト見積りプロセスを強化し、オプティマイザーが自動的に正しいインデックスを選択するようにしたため、手動によってSQLステートメントのバインディングを作成する必要はありません。
SQL Plan Managementのユーザービリティを改善
SQL Plan Management(SPM)は、SQLバインディングを実行し、手動でSQL実行プランに介入するための機能群です。今回のリリースで、SPMのユーザービリティが改善されており、以下の操作を行うことができます。
- バインディングが作成されたとき、タイムスタンプによってSQLステートメントをソートできる。
- EXPLAINを実行することで、SQLステートメントがバインディングを作成するかどうかを確認できる。
- ブロックリストを使用することによって、自動的にキャプチャされた、ステートメントのバインディングの一部を防護できる。
迅速な意思決定のためのリアルタイムインサイト
迅速な意思決定を行う必要がある企業にとって、リアルタイムのビジネスインテリジェンスは決定的に重要です。しかし、データサイズがますます大きくなる中、このようなアジリティを維持するにはどうすればいいのでしょうか。
TiFlashは、MPPモードでのクエリ実行をサポートしています。これにより、コンピューティングリソースを最大限活用し、リアルタイムのクエリパフォーマンスを実現できます。TiFlashがサポートする関数や演算子が増えるほど、TiDBが計算のためにTiFlashにプッシュダウンできるSQLステートメントも増えます。つまり、リリースごとにサポートされるようになる関数や演算子が1つだけだとしても、関連するクエリの効率性はかなり改善されます。
TiDB 5.2では、プッシュダウンできる関数や演算子が多数追加されています(MOD、LENGTH、LOG、ROUND、DATE、INET_ATONなど)。これにより、TiFlashによるSQL構文のサポートがさらに充実します。詳細については、リリースノートにある一覧表をご覧ください。テストによって明らかになったことは以下のとおりです。
- シングルスレッドの処理では、単純なクエリの遅延を数10秒から1秒未満に減らすことができる。複雑なクエリの遅延を数分から約1秒に減らすことができる。
- マルチスレッドの処理では、単純なクエリの遅延を1秒未満に減らすことができる。複雑なクエリの遅延を約10秒に減らすことができる。
来年には、残りのMySQL関数と演算子をサポートするほか、引き続きクエリの応答時間を最適化していく予定です。
同時実行性の高いワークロードでも、低い運用コスト
急成長しているビジネスやデータ主導のイノベーションシナリオでは、TiDBが持つ水平方向の拡張性とリアルタイムHTAP機能のおかげで、同時実行性の高いワークロードを管理することができます。今回のリリースでは、ビッグデータのリアルタイム分析がさらに強化されているため、運用コストを削減し、安定性を向上させることができます。TiFlashにより、書き込みパフォーマンス、MPP実行、同時実行処理のサポート、クラスタメンテナンスが改善されました。
TiDBのユースケース
これらのすべての魅力的な機能と改善点を備えたTiDBは、以下のユースケースに対応できます。
- シナリオ1:顧客からの同時実行性の高い集約型クエリにより、ミッションクリティカルなアプリケーションの安定性が損なわれており、その結果、カスタマーエクスペリエンスの質がさらに低下している。
- 大型テーブルのオンラインインデックス作成を高速化し、自動Leader転送を実装し、TiKVのメモリ使用量を最適化することによって、書き込み頻度が高い状況下での大規模クラスタの安定性を改善します。
- ホットスポットスケジューリングアルゴリズムを最適化し、QPSベースの統計を実装することによって、クラスタリソースの使用率を向上させます。カラム型ストレージエンジンであるTiFlashは、ホットスポットスケジューリングもサポートするようになりました。
- TiDB Data Migrationツール(DM)によるデータ複製の遅延を抑制することによって、データ移行の効率性を改善します。1秒あたりのクエリ数(QPS)が200,000クエリの負荷下でも、複製の遅延をほぼ間違いなく1秒未満に抑えます。
- シナリオ2:リアルタイムクエリを実行する場合、データ検索プロセスが不安定になる可能性がある。また、効率性がクエリ対象のデータのサイズに左右される。
- クエリのヒューリスティックな最適化を導入することによって、およびコスト見積りの精度を改善することによって、インデックス選択を改善します。
- バインディングを作成する際のSQL Plan Managementのユーザービリティを改善します。
- シナリオ3:複雑なリアルタイムクエリが原因で、ビジネス判断をタイムリーに行うことができない。
- プッシュダウンのための演算子をさらに実装し、超並列処理(MPP)エンジンを最大限に活用することによって、クエリ応答時間を短縮します。
- シナリオ4:同時実行性の非常に高い書き込み負荷がかかった場合、リアルタイム分析の機能と安定性が不十分となり、追加の運用コストやメンテナンスコストが生じる。
- ピーク時にトラフィックが2倍あるいは3倍にもなったときの書き込みパフォーマンスを増強します。
- デッドロックを防止することによって、MPPの堅牢性を向上させます。
- 書き込み負荷が高い状況下で、同時実行性の高いフルテーブルクエリ(最大30テーブル以上)に対応できるように機能を強化します。これにより、メモリ不足(OOM)エラーを低減または排除することができます。
- TiFlashクラスタのメンテナンスを行う際、アプリケーション側への影響を軽減します。システムは自動的に、または手動操作によって、不安定状態から回復できます。フロントエンドからの新たなクエリは、スケーリング中でも中断されません。
ぜひお試しください!
TiDBを初めて知ったという方は、TiDB 5.2をダウンロードしてぜひ試用してみてください。TiDB 5.2の詳細については、こちらの説明書とケーススタディをご覧ください。
現在、旧バージョンのTiDBを利用していて、TiDB 5.2を試してみたいという場合は、Upgrade TiDB Using TiUP(TiUPを使ってTiDBをアップグレード)をお読みください。また、ぜひSlackのTiDBコミュニティに参加し、お客様のアイディアを聞かせてください。
当社の創設者の1人であるMax Liuは、次のように述べています。「複雑な作業はTiDBに任せて、ユーザーの作業をシンプルに」。今回のリリースは、OLTPとOLAPのユーザーシナリオの枠を押し広げる上で、TiDBにとっての大きな一歩です。今後もユーザーのフィードバックに基づき、TiDBを最適化していきます。
献身的に協力してくれたTiDBコミュニティと、製品を改良する際に支援してくれたユーザーに感謝しています。また、TiDB 5.2.0をテストしフィードバックを行なってくれたLi Auto社、Tencent Interactive Entertainment Group、Xiaomi社を始めとするすべての企業に対し、心より感謝しています。私たちの業務提携とオープンコラボレーションによって、TiDBは業界をリードするワールドクラスのデータベースになるでしょう。
PingCAPについて
PingCAPは、エンタープライズ向けのソフトウェアサービスプロバイダーとして2015年に設立され、オープンソースでクラウドネイティブなワンストップのデータベースソリューションを提供することにコミットしています。PingCAPの社名は、ネットワークの疎通を確認するために使用されるコマンド「Ping」とCAP定理の「CAP」の2つの単語を組み合わせています。3つのうち2つを選ばなければならないとされるCAP定理のC (Consistency – 一貫性)、A (Availability – 可用性)、P (Partition Tolerance – ネットワーク分断への耐性) ですが、この3つの全てに接続したい (Ping) という思いが込められています。PingCAPの詳細については https://pingcap.co.jp をご覧ください。
本件に関するお問合わせ先
PingCAP株式会社 広報部
Email:pingcapjp@pingcap.com