自治体公開データをAI活用へ。LobbyAIがTiDB Cloud Starterを主要DBに選んだ理由
記事公開日:2026年5月27日

自治体営業・政策渉外を支援するLobbyAI株式会社は、全国の自治体が公開する議事録、計画書、入札情報、統計情報などをAIで解析し、企業が自治体ごとの課題や提案機会を把握できるほか、専門家が自治体情報に係る高度な分析および追跡を行うことができるSaaS「LobbyAI」を提供している。
自治体営業では、地域ごとの政策課題、予算、部局、議会での議論、過去の調達状況などを読み解く必要がある。しかし、こうした情報は自治体ごとに公開形式が異なり、議事録、PDF、Office文書、HTMLページ、統計表などに分散している。人手だけで継続的に追い続けるには限界があり、同社では公共データ取得のためのAIを独自開発した。しかしAIによって高速に取得される巨大なデータをプロダクション品質で顧客に提供するにはいくつもの技術的課題があったという。
そのような状況下にあった同社がデータ基盤として初期設計の段階から採用したのが、TiDB Cloud Starterだった。
あらゆる要求を満たす基盤が必要だった
LobbyAIは、自治体が公開する議事録などのあらゆる公開文書および統計情報を横断的に検索・分析し、企業が「どの行政機関に、どのような提案を、いつ行うべきか」「今まさにそこで何が起こっているのか」を判断するための膨大な公共情報を提供するサービスだ。
ユーザーは、自治体名やキーワードによる検索だけでなく、AI要約・ディープリサーチ・通知機能などのAI機能を通じて、公共情報を簡単に、実務に使える形で把握できる。また、必要な場合は元自治体職員・元国会議員・元議員秘書のメンバーが顧客と伴走し共に目標達成を支援する。
しかし技術部門においては、公共情報を単に蓄積すれば上記の機能要件を達成できるわけではなかった。
一次情報たるデータそのものが欠損・重複しているケースや、”花火大会のお知らせ”などビジネス価値の低いノイジーなデータが混ざってしまうケースも多かった。
そのためデータ全体の品質を後処理としてのデータエンジニアリングで担保する仕組みが必要不可欠であり、選定するデータ基盤はそのための条件をクリアする必要があったという。
一方で、同社はスタートアップでもある。データ量が増えるたびにシャーディングを設計したり、データベース運用に多くの人員や資金を割いたりするのではなく、プロダクト開発と顧客価値の改善に集中できる必要もあった。
「自治体の公開情報は価値がありますが、企業が営業や政策渉外に使うには、そのままでは扱いづらい面があります。議事録、PDF、統計表、HTMLページが自治体ごとに別々の形で公開されていて、人が追い続けるには限界があります。扱うデータ量が大きくなることは最初から分かっていたので、後から何が起こっても苦しまない基盤を選びたいと考えていました」(石川 聡, Co-Founder, CTO)。
TiDB Cloud Starterを選んだ4つの理由
LobbyAIがTiDBを選定した理由は大きく4つある。
1つ目は、巨大なデータの正確性を保ちながら安定的に運用可能であることだ。全国の自治体から収集される膨大な公開データは、一度投入して終わりではなく、新規の会議や文書の追加に合わせて日々差分更新や重複排除が行われる。TiDBは分散データベースとしてスケールさせながら、RDBの強力な制約や自動バックアップによりデータ同士の関係や一貫性を適切に保てるため、データ同士の関係や一貫性を保ちながら、安定して書き込み・読み込みを行える。公共データの投入、検索・閲覧、通知、リサーチ履歴の管理まで、プロダクトの中核データを1つのデータベースで扱える点が要件に合っていた。
2つ目は、データ分析基盤としても機能するほどに大規模なデータに対しても高い応答性能を持つことだ。LobbyAIは、自治体ごとの定量データと、議事録や文書に含まれる定性データを組み合わせて活用する。TiDBは行指向の通常ワークロードに加え、TiFlashによる列指向の分析ワークロードも同じTiDB基盤で処理できるHTAPアーキテクチャとして構成されている。これにより、増え続ける公共データを対象にした複雑な集計や分析処理でも、ユーザーから見た応答性能を落とすことなく高速に処理できる応答性能を単一のデータベースで確保できている。
3つ目は、顧客が利用するアプリケーション側からも、これまで通りの実装で参照できることだ。LobbyAIのデータ収集パイプラインはPythonで構築され、WebアプリケーションはNext.jsとPrismaを中心に構成されている。TiDBはMySQL互換であるため、既存のSQLやORMの知識をそのまま活かしながら、大量データを扱える分散データベースを利用できる。ビッグデータを運用したことのあるチームでなくとも直感的に利用可能で、これまで通りの慣れ親しんだ実装でスムーズに開発を進めることが可能だ。
4つ目は、低コストであることだ。LobbyAIが採用したTiDB Cloud Starterはリソースの利用量に応じた従量課金制を採用している。公共データの投入バッチ、日常的な検索・閲覧、AI機能のためのデータ参照など、負荷の種類やアクセスパターンが一定ではなく、まだ変化しやすい初期フェーズにおいても、過剰な固定費を発生させることなく最適なコストパフォーマンスで運用を開始できる点が評価された。
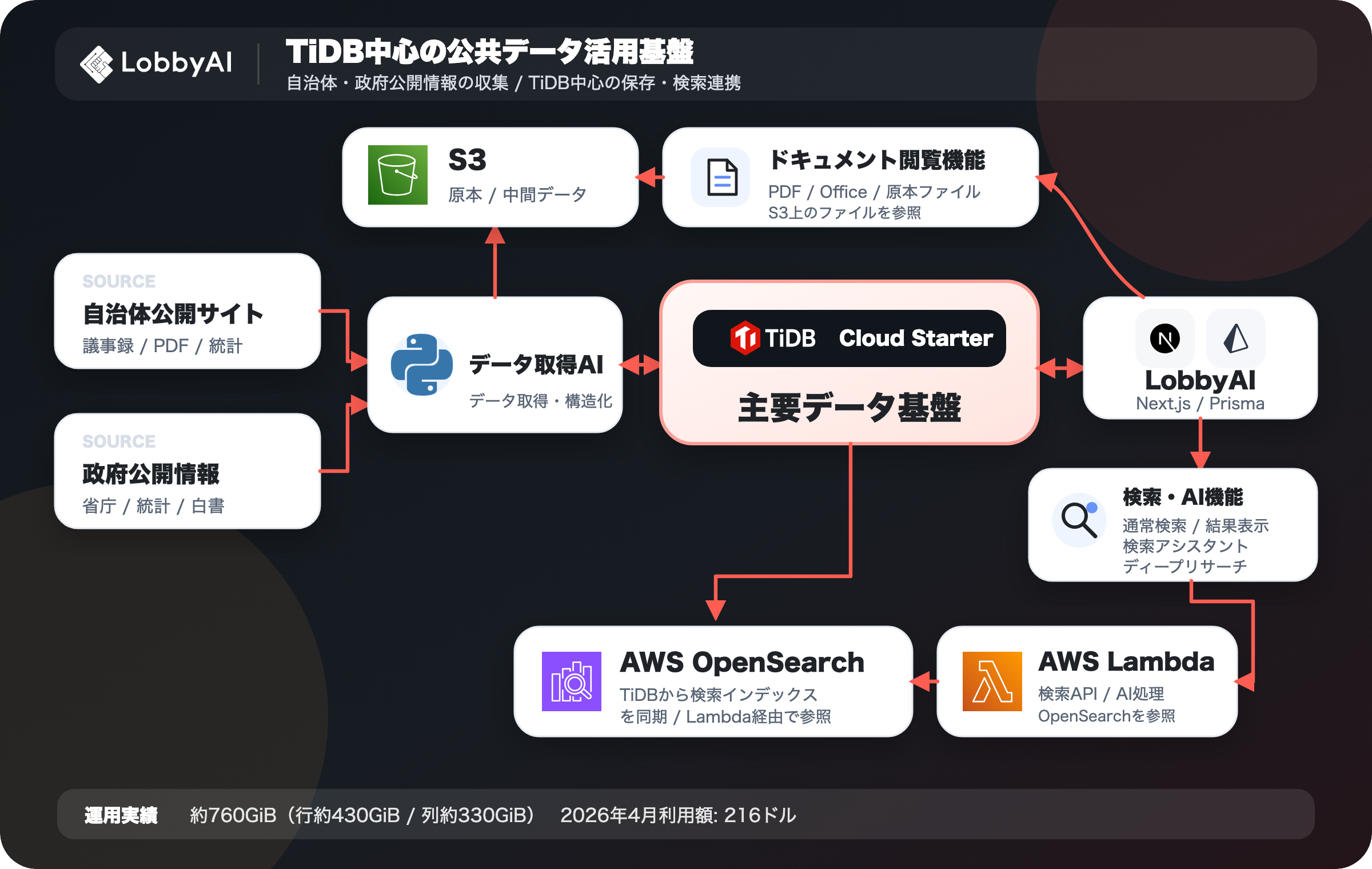
本番基盤とアーキテクチャ
本番環境では、TiDB Cloud Starterを中心に、収集バッチ、ストレージ、Webアプリケーションを組み合わせた構成を採用している。
データ取得AIは自治体サイトを巡回し、議事録、文書URL、PDFやOffice文書の本文、ページ単位のテキストを抽出する。Webアプリケーション側ではNext.jsとPrismaを中心に、自治体検索、議事録検索、文書検索、通知設定、AIアシスト、ディープリサーチを提供している。
この構成でS3が担うのは、原本ファイルや中間データの保管だ。一方、TiDBはプロダクト上で参照される構造化データの信頼できる保存先となる。検索用データはTiDBからAWS OpenSearch Serviceへ連携される。フロントエンドの通常検索、検索アシスタント、ディープリサーチなどの機能は、OpenSearchを直接参照するのではなく、AWS Lambdaを経由して検索インデックスを利用する。また、ドキュメント閲覧機能ではS3上の原本ファイルや中間データを参照できる。これにより、データ収集バッチ、検索基盤、ファイル閲覧、ユーザー向けアプリケーションの間で、TiDBを中心にした責務分離を保てているという。
LobbyAIの本番基盤とTiDB Cloud Starterの位置づけ
また、TiDB Cloud Serverless DriverやPrisma adapterのように、HTTPベースでTiDB Cloud Starterへ接続できる選択肢があることも、サーバレス環境への展開を進める際の安心材料になっている。
約760GiB規模のデータを月200ドル台で運用
現在、同社のTiDB Cloud Starter環境では、全国の自治体データを含む合計約760GiB規模のデータを扱っている。それでも2026年4月1日から4月30日の利用額は216ドルだった。ストレージは行ベースで約430GiB、列ベースで約330GiBである。
仮に、同じ規模のデータを従来型の構成で扱い、将来の増加に備えて余裕を持ったインスタンスを常時確保する必要があれば、同社のようなスタートアップにとって固定費は大きな負担になるはずだった。TiDB Cloud Starterの従量課金モデルにより、同社はデータ量の増加を受け止めながら、過剰な固定費を避けることができている。
同社が評価するコスト面の効果は、単に月額費用が低いことだけではない。大量投入のタイミングと通常利用時で負荷が変わるプロダクトでは、固定的な余剰リソースを抱えずに済むことが、開発判断の自由度につながる。新しいデータ種別の追加やAI機能の検証を行う際にも、インフラコストを過度に気にせず試しやすい点が、初期フェーズのプロダクト開発に合っていた。
「データ量が増えることは最初から分かっていましたが、そのために大きな固定費を先に抱えるのは避けたいと考えていました。TiDB Cloud Starterは、実際の利用に応じて始められるので、当時設立初期であった我々の段階でも大量データを扱うプロダクトを現実的に検証・運用できました」(石川 聡, Co-Founder, CTO)。
評価しているポイントと今後期待する機能
過去のAI機能開発に係るPoCでは、Preferred Networksが公開する日本語テキスト埋め込みモデル「pfnet/plamo-embedding-1b」で生成した埋め込みをTiDB Vector Searchに格納し、議事録・文書検索への適用可能性を試した。
この検証を通じて、既存のTiDB上でベクトル型・ベクトルインデックスを扱えることや、検索・RAG基盤への応用可能性を確認したという。最終的に開発予定だった機能についてはエージェントが複数の情報源を参照しながら調査するAgentic-RAGを採用したため、ベクトル検索そのものの本番採用は見送ったが、TiDB Vector Searchは検索・RAG基盤の技術選定を進めるうえで有用な検証環境になった。
今後TiDB Cloudに期待しているのは、全文検索の全リージョン対応と、日本語形態素解析(Kuromoji、Sudachi、Lindera など)への対応だと石川氏は語る。
LobbyAIでは、議事録や自治体文書など、日本語の長文テキストを大量に扱う。現在は、TiDBからAWS OpenSearch Serviceへデータを同期しSudachiで形態素解析・分かち書きを行いインデックスを構築している。 AWS Lambda経由でフロントエンドの通常検索、検索アシスタント、ディープリサーチが参照する構成を採っている。ただし、検索基盤を別途持つこの状態では、データ同期、インデックス運用、監視、費用の負担が増える。
もしTiDB Cloud上で、日本語の形態素解析に対応した全文検索を、利用リージョンを問わず本番機能として活用できるようになれば、あらゆるデータ基盤のほぼ全てをTiDBに寄せられる可能性がある。
近年、英語圏の技術コミュニティでは「Postgres Is Enough」や「Postgres Is All You Need」といった言い方で、PostgreSQLの汎用性が語られることがある。
全文検索、JSON、ベクトル検索、拡張機能などを組み合わせることで、多くのアプリケーション要件を単一のデータベースに集約できるためだ。
一方で、日本語の長文検索では、形態素解析や分かち書きへの対応が検索品質を大きく左右する。TiDB Cloudがこうした2バイト言語圏の全文検索に本格対応すれば、日本語圏における「TiDB Is All You Need」に近づける可能性があると石川氏は語る。
LobbyAIが目指しているのは、行政や公共領域の情報を、誰もが意思決定に活用できる社会基盤に変えていくことだ。TiDBは、大量の公共データを扱うLobbyAIの主要データ基盤として、今後もプロダクトの成長を支えていく。