記事公開日:2026年6月23日

株式会社Livetoonは、AIキャラクター、IP活用、生成AIを用いた受託開発など、エンターテインメントとAI技術を組み合わせた事業を展開しています。特に、STT (音声認識)、LLM、TTS (音声合成) を組み合わせ、ユーザーの声に自然な音声で応答するSTS (Speech-to-Speech) の開発に力を入れています。
AIキャラクターとのビデオ通話・チャットアプリ「kaiwa」は、こうした音声対話AIを実際のユーザー体験として実装した社内プロダクトの一つです。この記事では、kaiwaの本番環境を例に、LivetoonがTiDB Cloud Starterをどのように活用しているかを紹介します。Livetoonではkaiwaに限らず、AIキャラクター開発、IP活用、受託開発などの音声対話AI開発でもTiDBを活用しています。

kaiwaのビデオ通話・チャット体験
音声対話AIでは、会話の裏側で多くのデータが動く
kaiwaでは、ユーザーの発話を起点に複数の処理が連続します。音声認識で発話内容をテキスト化し、直近の会話履歴や必要な記憶を参照し、LLMが応答を生成し、TTSで音声化する。その後、会話内容や更新すべき記憶を保存し、次回以降の応答に活かします。
STTやTTSは、外部APIにすべて任せるのではなく、Livetoon側で管理するPrivate APIとしてホストしています。特にTTSはLivetoonで自社開発しており、キャラクター体験に合わせた音声表現や応答速度を追求しやすい構成にしています。本番環境では、ClientからPublic ALBを経由してBackend APIに入り、Backend APIがアプリケーションデータ、ベクトル検索、LLM、STT/TTSを呼び分けます。
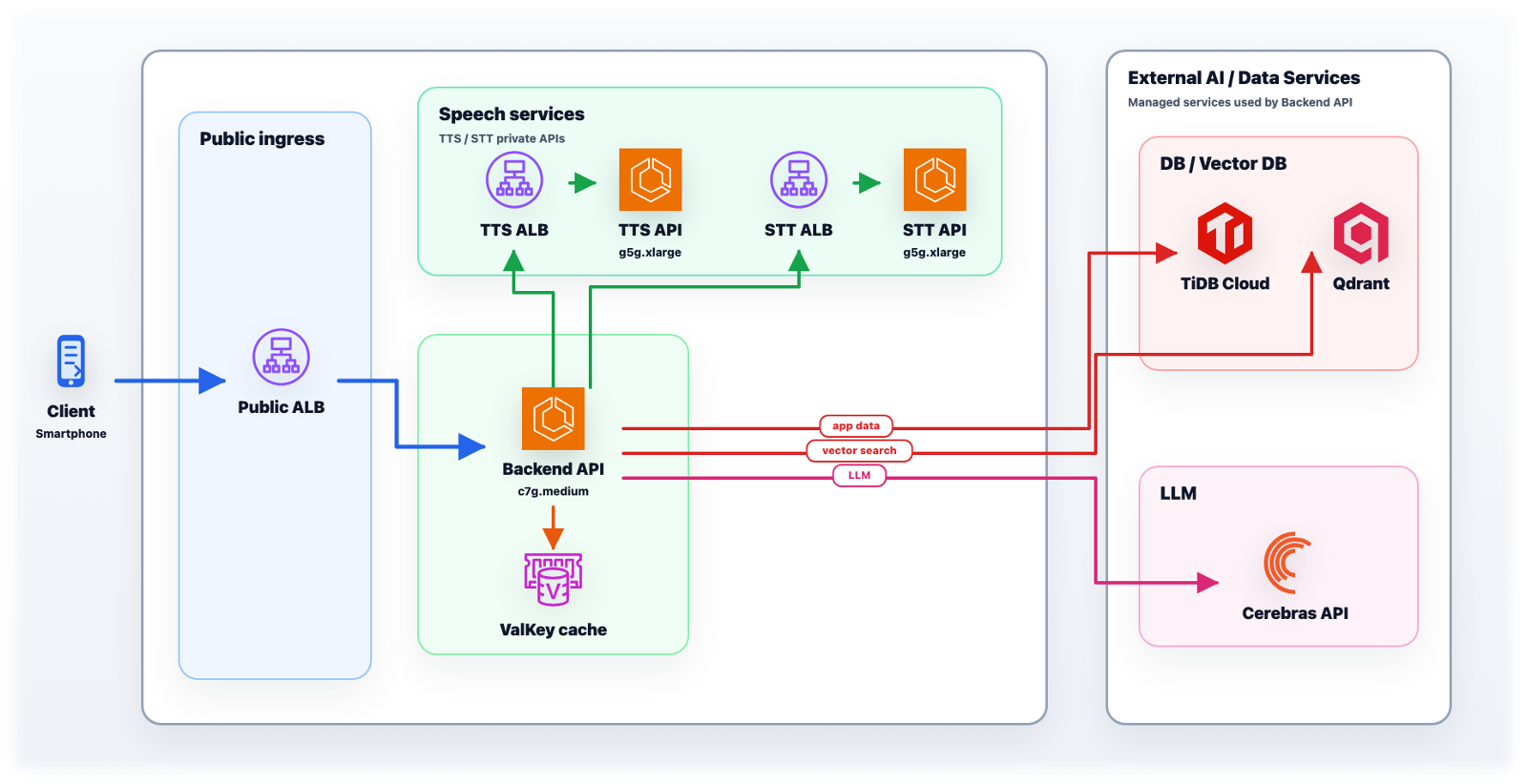
kaiwa本番環境のインフラ構成図
STT、TTS、LLMを組み合わせた音声対話AIでは、発話のたびに会話履歴の書き込み、過去文脈の読み出し、記憶データの参照、キャラクター設定の取得、会話後の状態更新などが発生します。テキストチャットより短い発話や相づち、話題転換が連続しやすく、自然な会話体験を作ろうとするほど、データベースには細かな読み書きが求められます。
複数DB構成から、TiDB Cloud + Qdrantへ
TiDB Cloudを導入する前、kaiwaの本番システムでは用途ごとに複数のデータベースを使い分けていました。ユーザー情報やキャラクターに関する構造化データはAurora PostgreSQLに、会話履歴や文書型記憶はDocumentDBに、応答生成時に即時参照する必要がある記憶データはQdrantに格納する構成です。

DB構成の整理:Aurora PostgreSQL + DocumentDB + QdrantからTiDB Cloud + Qdrantへ
それぞれの選択には理由がありましたが、開発が進むにつれて、どのデータをどこに置くのか、どのDBを正とするのか、どのタイミングで同期するのかを毎回考える負荷が大きくなっていきました。監視やバックアップ、権限管理、障害時の切り分けも、DBの種類が増えるほど複雑になります。
現在、kaiwaの本番環境ではTiDB Cloud Starterを利用しています。TiDBには、ユーザーデータ、キャラクター設定、会話履歴、文書型記憶など、音声対話体験を支える主要なアプリケーションデータを集約しました。Qdrantは引き続き、即時検索が必要なベクトル記憶の用途で利用しています。完全に一つのDBへ統合したわけではありませんが、構造化データと会話・記憶まわりのデータをTiDBに寄せたことで、中心的なデータをSQLの世界で扱いやすくなっています。
採用の決め手と、使ってみて感じた価値
TiDB Cloudを選んだ理由の一つは、書き込みを含めたスケールへの期待です。音声対話AIでは、ユーザーの発話がそのままデータの発生源になります。会話が活発になるほど、読み込みだけでなく書き込みも増えます。TiDBはMySQL互換の分散SQLデータベースであり、現在の規模に合わせて小さく始めながら、将来の負荷増加に備えられる点が魅力でした。
TiDB Cloud Starterの始めやすさも重要でした。Livetoonでは、自社プロダクトだけでなく、PoCや受託開発の初期検証も多く発生します。生成AI領域ではモデル利用料、GPU、音声処理などDB以外のコストも大きいため、必要なタイミングで素早く立ち上げ、利用状況に応じて伸ばせることは開発スピードに直結します。
本番導入では、AWSのプライベートエンドポイント接続 (AWS PrivateLink) を利用してTiDB Cloudへ接続できることも導入のハードルを下げました。DB接続をインターネットに露出せず、アプリケーションが動くAWS環境からプライベートな経路で接続できるため、既存のネットワーク設計に自然に組み込みやすく、セキュリティ面の不安も抑えられます。
さらに、MySQL互換であることも大きな理由でした。Livetoonのバックエンドでは主にASP.NET Coreを利用しており、アプリケーション開発ではEntity Framework Coreを活用しています。TiDBでもMySQL向けの既存エコシステムを活かしやすく、特別なSDKや独自仕様に強く依存せずに移行できる点を評価しました。
実際に使ってみると、主要データをTiDB中心に考えられることが開発体験に効いています。以前は、ユーザー情報、会話履歴、記憶データが複数のDBにまたがり、機能追加のたびに同期や整合性を意識する必要がありました。現在は、まずTiDBを中心にデータモデルを考え、必要に応じてQdrantのベクトル検索を組み合わせる判断がしやすくなっています。
ベクトル検索領域でもTiDB活用を検証中
現在、kaiwaでは即時検索が必要な記憶データのためにQdrantを利用しています。ユーザーの過去の発話、好み、関係性、文脈に応じた記憶を検索し、応答生成に渡すことは、音声対話AIにとって重要です。現状は、Embeddingsの生成を約30ms、Qdrantでの検索を約5msで処理し、会話体験を損なわない高速なベクトルRAGを実現しています。
一方で、ベクトル検索のためだけに別のDBを運用し続けることには複雑さがあります。そこで現在、Qdrantで担っているベクトル検索の一部または全部を、TiDB Vector Searchへ置き換えることを検証しています。構造化データ、会話履歴、文書型記憶、ベクトル検索をより近い基盤で扱えるようになれば、データの置き場所や同期の考慮をさらに減らせます。
また、事業や受託開発案件の進捗によって、より高い可用性や運用機能、予測しやすい性能が必要になる場面も出てきます。その際には、TiDB Cloud Essentialなど上位プランの利用も選択肢になります。Starterで小さく始め、必要になったタイミングで拡張していけることは、Livetoonのように新しいAI体験を作り続けるチームにとって重要です。
音声対話AIの体験づくりに集中できる基盤へ
Livetoonにとって、kaiwaでのTiDB Cloud Starter導入は、単なるデータベースの置き換えではなく、音声対話AIの体験づくりに集中するためのデータ基盤整理でした。MySQL互換による移行のしやすさ、水平スケールへの期待、Starterプランの始めやすさ、プライベートエンドポイント接続、複数DB構成を整理できる点は、kaiwaの本番システムに合っていました。kaiwaでの本番運用に加えて、LivetoonではAIキャラクター、IP活用、受託開発などの音声対話AI開発でもTiDBを活用しており、現在進行形の複数のAI開発を支える有力な選択肢になっています。