



※このブログは2026年2月12日に公開された英語ブログ「LLM Reasoning vs. Vector Search: Lessons from Building CrowdSnap’s Sentiment Analytics」の拙訳です。
TiDB CloudユーザーであるCrowdSnap社は、レビューやアンケートなどのデータセットをアップロードすると、感情のトレンドや相関関係といったインサイトを自然言語で引き出せるAI分析プラットフォームを構築しています。これにより、煩雑なデータを鋭い意思決定へと変換しています。
同社はプロンプト分析機能を構築する際、AI開発で典型的な分岐点に突き当たりました。それは、オンデマンドな感情分析のために、LLM (Azure OpenAI経由のGPT) による直接的な推論に頼るべきか?それとも、高速で反復可能な情報取得のために、ベクトルデータベースを採用すべきか?という問いです。
彼らは実際のデータセット (200〜1,000行) を用いて、速度、コスト、精度の測定テストを行いました。単発の実行ではGPTがわずかに優れていましたが (レイテンシ2〜5秒)、反復的な処理においてはTiDBのベクトル検索が圧倒しました (クエリあたり0.3秒と400倍高速で、1,000回の分析あたりのコストは10〜15ドルに対しわずか0.11ドル)。わずか51回のクエリ実行で、損益分岐点を突破しています。
画期的な解決策:ハイブリッドなフロー — 的確で文脈豊かな生成にはGPTを、エンベディングの保存 (コサイン距離によるマッチング) にはTiDBを活用します。規模を拡大させるAI開発者にとって、これは賢明な戦術と言えます。まずはLLMでプロトタイプを作成し、その後にコスト効率が良く反復性能の高いパフォーマンスを実現するためにTiDBを組み合わせるのです。
ベンチマーク、コードスニペット、そして意思決定マトリクスを掘り下げていきましょう。次世代のAI構築において、どちらを選択すべきか (あるいはどう組み合わせるべきか) を解き明かしましょう。
すべてのAI開発者が直面する決断
CrowdSnap社のプロンプト分析機能の構築を始めたとき、典型的な岐路に立たされました。感情分析のためにLLMを直接呼び出すべきか、それともベクトルデータベースのアーキテクチャに投資すべきか、という問題です。
直感に頼るのではなく、両方のアプローチを構築し、実際のデータセットを用いて直接比較してみました。その結果、パフォーマンスやコスト、そしてそれぞれのアプローチがどのような場面で理にかなっているかについて、私の思い込みが覆される発見がありました。
このブログでは、GPT直接利用と、大規模な本番環境での感情分析に向けたTiDBベクトル検索を比較し、それぞれの実装から得られたベンチマークやトレードオフ、そして教訓を共有します。
結論:答えはAかBではなく、それらをどう組み合わせるかでした。
私たちが構築しているもの
CrowdSnap社のプロンプト分析機能は、ユーザーが任意のデータセット (アンケート、レビュー、フィードバックなど) をアップロードし、自然言語で質問を投げかけることで、インサイトや感情のパターン、相関関係などを明らかにできるツールです。これは「データのためのChatGPT」のようなものですが、数百から数千ものデータに対して効率的に実行するというアーキテクチャ上の課題が伴います。
この比較が重要である理由
AIの分野は、必ずしも実際のデータに裏付けられていない「ベストプラクティス」であふれています。例えば、以下のような意見を耳にすることがあるでしょう。
- 「AIアプリには常にベクトルデータベースを使うべきだ」
- 「LLMは本番環境で使うにはコストが高すぎる」
- 「ベクトル検索の方が常に高速だ」
しかし、これらは本当に正しいのでしょうか?そしてより重要なのは、どのような場合に正しいのかということです。
このブログでは、本番環境のAI分析プラットフォームを構築する過程で得られた、実際のベンチマーク、リアルなコスト計算、そして実際のトレードオフを公開し、こうした喧騒の真実を明らかにします。
エグゼクティブ・サマリー
実環境でのパフォーマンスを把握するため、データセットの規模を徐々に大きくして、両方のアプローチをテストしました。
| 200行 – GPT直接利用:26.2秒 – TiDBベクトル検索:374.6秒 (初回エンベディング) + 3.5秒 (クエリ) – 結果:感情分布で分析された238のドキュメント | 500行 – GPT直接利用:29.3秒 – TiDBベクトル検索:908.6秒 (初回エンベディング) + 14.4秒 (クエリ) – 結果:608文書を処理 | 1000行 – GPT直接利用:33.7秒 – TiDBベクトル検索:1,733.6秒 (初回エンベディング) + 26.5秒 (クエリ) – 結果:1,234文書を処理 |
見えてきたパターン
初回の分析においては、GPT直接利用が一貫して高速です。しかし、ここで興味深いのは、一度TiDBがデータをインデックス化すると、その後のクエリは驚異的に速くなるということです。
セマンティック類似性検索の場合:
- GPT直接利用:クエリあたり120秒以上 (再分析が必要なため)
- TiDBベクトル検索:クエリあたり0.3秒 (ベクトル検索)
- 速度の優位性:反復的なクエリにおいてTiDBは400倍高速です
大規模運用時のコスト (分析1,000回あたり):
- GPT直接利用:1,000回の分析ごとに10〜15ドルの継続的な費用
- TiDBベクトル検索:初回インデックス作成時に0.11ドル + 反復クエリ用の月額費用1〜2ドル
結論:1回限りのの分析ではGPT直接利用が勝りますが、反復的なクエリやスケーラビリティが求められる本番環境のアプリケーションでは、TiDBベクトル検索が優位です。
パフォーマンス分析
TiDBの初回のエンベディングが低速な理由:
- レート制限:Azure OpenAIのエンベディングAPIによる制限 (3リクエスト / 秒)
- ネットワークオーバーヘッド:複数のラウンドトリップ (クライアント → サーバー → Azure → TiDB)
- バッチ処理:遅延を伴う逐次的なバッチ処理
- データベースへの書き込み:各ドキュメントに対するベクトルとメタデータのインサート
TiDBベクトル検索が400倍高速な理由:
- ベクトルインデックス:事前計算されたエンベディングにより、即時に類似度検索が可能
- コサイン距離:TiDB内で最適化されたベクトル演算
- APIコールの排除:クエリが完全にデータベース内で完結
- 並列処理:データベースによる効率的な同時実行クエリの処理
損益分岐点の計算:
1,000行のデータセットの場合:
- TiDBベクトル検索の先行コスト:1,733.6秒 (初回のみ)
- GPT直接利用のクエリごとのコスト:33.7秒 (実行のたびに発生)
- 損益分岐点:1,733.6 ÷ 33.7 ≈ 51回のクエリ
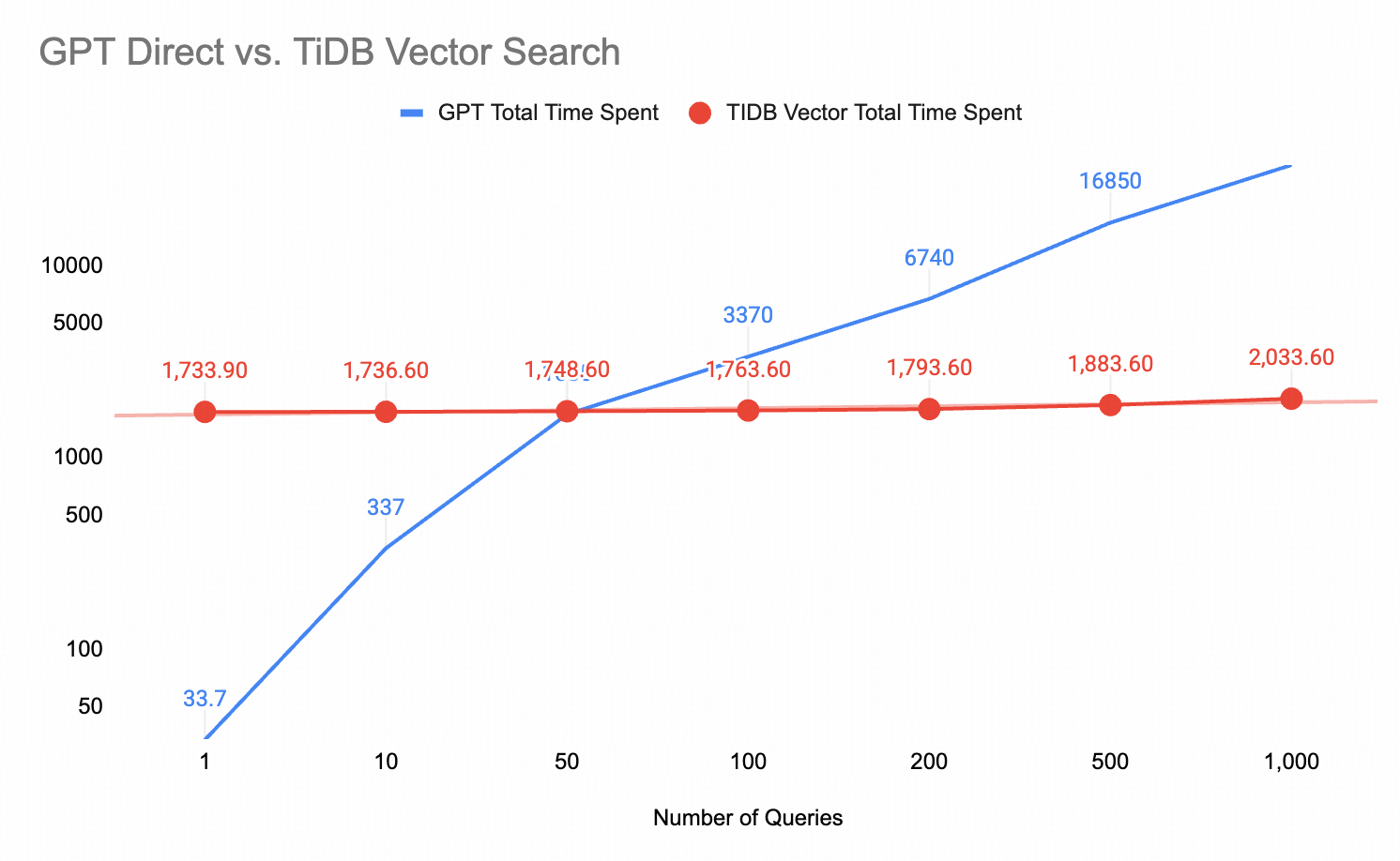
同じデータセットに対して51回以上のクエリを実行すると、全体としてTiDBの方が高速になります。セマンティック類似度検索 (0.3秒対120秒) においては、わずか15回のクエリでTiDBが優位に立ちます。
テストした2つのアプローチ
私は、根本的に異なる2つのアーキテクチャ・アプローチを用いて、同じ感情分析機能を2回構築しました。
どちらの実装も最終的には感情に関するインサイトをユーザーに提示しますが、その仕組みは大きく異なり、パフォーマンス、コスト、スケーラビリティにおいて明確な違いが生じます。
結論:最も効果的な解決策は、どちらか一方のアプローチを選択することではなく、推論とセマンティック・メモリをいかに組み合わせてスケールするシステムを構築するかを理解することにありました。
パス1:直接的なLLM (推論 / 生成)
Azure OpenAIのGPTモデルを使用して、生のテキストに対して直接的な推論を行い、自然言語理解を通じてオンデマンドで感情分類、要約、インサイトを生成します。
仕組み:
ユーザーがデータ (Excel / CSV) をアップロードし、分析タイプを選択して、自然言語のプロンプトを入力します。システムはデータとプロンプトをGPTモデルに送信し、モデルがインプットを分析して、構造化されたインサイトを即座に返します。

サポートされている分析タイプ
| 1.2.1 感情分析 – ポジティブ/中立/ネガティブの分類 – 感情スコアリング – 分布の可視化 – コンテキストに基づくインサイト | 1.2.2 ワードクラウド / 頻度分析 – キーワード抽出 – 出現頻度のカウント – 意味のある単語のフィルタリング – 共起パターン |
| 1.2.3 トピッククラスタリング – テーマの特定 – カテゴリーのグループ化 – トピックの相関関係 – トレンド検知 | 1.2.4 感情分析 – 感情検知 (喜び、怒り、悲しみなど) – 感情トーンの評価 – 強度のスコアリング – エモーショナルジャーニーのマッピング |
パス2:TiDBベクトル検索 + AI (セマンティック・メモリ&リトリーバル)
Azure OpenAIのエンベディングを使用してテキストをセマンティック・ベクトルにエンコードし、TiDBに保存およびインデックス化します。このアプローチでは、クエリ実行時に新しいインサイトを生成するのではなく、ベクトル類似度検索とデータベース分析を通じて、以前に計算されたセマンティックおよび感情シグナルの高速な検索、集計、および再利用を可能にします。
仕組み:
ユーザーがデータをアップロードすると、テキストの各行がAPIを介して1536次元のベクトルに変換されます。ベクトルはメタデータと共にTiDBに保存されます。ユーザーがクエリを送信すると、サーバー側でそのクエリもベクトルに変換されます。その後、TiDBがセマンティック類似度検索を実行して最も関連性の高いドキュメントを取得し、感情スコアを含む結果がサーバーからブラウザに返されます。
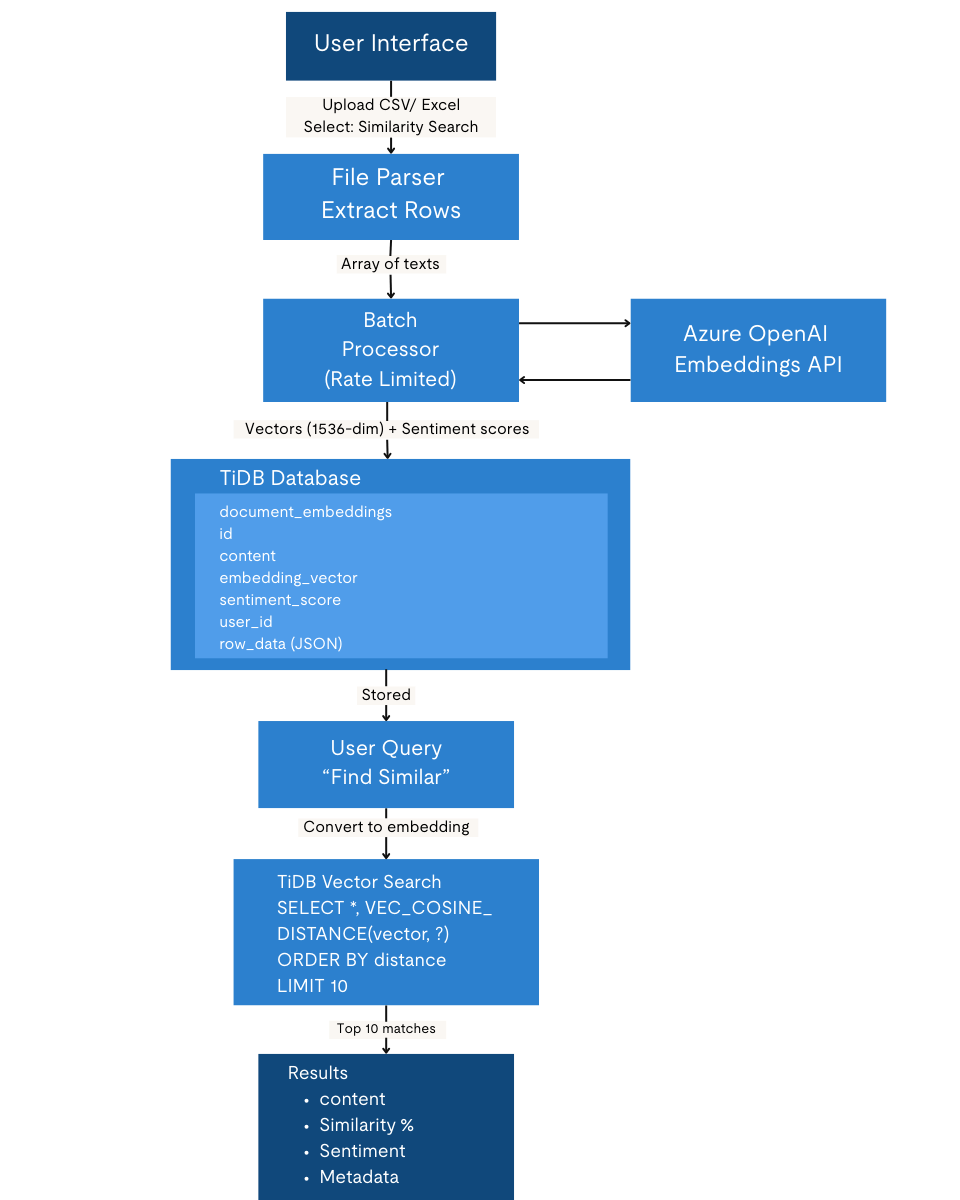
サポートされている機能:
| 2.2.1 セマンティック検索 – 類似したフィードバック/回答の検索 – キーワードではなく意味によるクエリ – 多言語理解 – コンテキストを考慮したマッチング | 2.2.2 感情データの保存とリトリーバル – 永続的な感情スコア – 履歴トレンド分析 – ユーザー固有のフィルタリング – 統計の集計 |
| 2.2.3 バッチ処理 – 数百のテキストを処理 – すべてのエンベディングを保存 – 分布の分析 – 結果のエクスポート | 2.2.4 ベクトル演算 – コサイン類似度 – 最近傍探索 – クラスタリングの可能性 – 次元削減への対応 |
エンベディングを生成する
以下に、テキストの各行がAzure OpenAIを使用して1536次元のエンベディングに変換される簡略化された例を示します。これが、後にセマンティック検索のために保存およびインデックス化されるエンベディングです。
async function embedText(text) {
const response = await azureClient.embeddings.create({
model: 'text-embedding-ada-002',
input: text,
});
return response.data[0].embedding; // 1536 dimensions
}TiDBにエンベディングを保存
一度生成されたエンベディングは、元のテキストや関連フィールドと共にTiDBに永続化されます。これにより、毎回再処理することなく、将来のクエリでデータを再利用できるようになります。
await db.insertDocumentEmbedding(
text,
embedding, // VECTOR(1536)
sentimentScore, // DECIMAL(10,4)
metadata, // JSON
userId
);TiDBでのベクトル検索
クエリ実行時、TiDBはコサイン距離を使用してベクトル類似度検索を行い、最も関連性の高いドキュメントを返します。このクエリは、エンベディングが保存された後の主要な抽出方法となります。
async searchSimilarDocuments(queryEmbedding, topK = 10, userId = null) {
const vectorString = `[${queryEmbedding.join(',')}]`;
const searchSQL = `
SELECT
id,
content,
sentiment_score,
row_data,
VEC_COSINE_DISTANCE(embedding_vector, ?) AS distance
FROM document_embeddings
${userId ? 'WHERE user_id = ?' : ''}
ORDER BY distance ASC
LIMIT ?
`;
比較分析
1. パフォーマンス:Excelアップロードによる一回限りの分析 (100行)
Excelファイルからの100行に対して、GPT感情分析とベクトルデータベースを比較し、各アプローチのパフォーマンス時間を測定するテスト。
データセット 👉🏼[ヘッダーに関する質問]
TiDBベクトル検索 (バッチエンベディング + 保存):59.81秒
GPT直接利用 (単一ステップ解析):44.47秒
結果:GPT直接利用は一回限りの分析を約15秒早く完了し、約25%のレイテンシ向上を示しています。この利点は、初期のベクトル取り込みコストの大部分を占めるエンベディング生成とデータベース書き込み操作を回避することから得られます。
GPT直接利用が高速な理由 (44.47秒 vs 59.81秒)
| TiDBベクトル検索のオーバーヘッド (59.81秒の内訳) 1. エンベディング生成 – Azure OpenAIを使用してテキストをベクトルに変換 (1リクエストあたり 約2-3秒) 2. データベースへの挿入 – TiDBにエンベディングを保存 (約1-2秒) 3. ベクトル類似性検索 – コサイン類似度の計算 4. ネットワーク遅延 – 複数のラウンドトリップ (クライアント → サーバー → Azure → TiDB) | GPT直接利用 API (44.47秒の内訳) 1. 1回のAPIコール – 直接的な感情分析 2. エンベディングの生成なし – ベクトル生成をスキップ 3. データベース操作なし – ストレージのオーバーヘッドなし 4. ネットワークラウンドトリップの削減 クライアント → サーバー → GPT (完了) |
主な違いは構造的なものです。ベクトル検索は、結果が得られる前にテキストをエンベディングして保存し、クエリを実行する必要がありますが、GPT直接利用は、1つのエンドツーエンドのステップでテキストを分析し、即座に結果を返します。
- ベクトル検索の工程:テキスト → エンベディング → 保存 → 検索 → 結果 (4ステップ以上)
- GPT直接利用の工程:テキスト → GPT分析 → 結果 (2ステップ)
| ベクトル検索 が適している場合 – 意味的類似性検索 – 関連コンテンツの検索 – 複数のクエリで再利用可能なエンベディング – 初期インデックス作成後のオフライン分析 | GPT直接利用 が適している場合 – 単発の感情分析 – 類似性検索が不要な場合 – 速度が重要な場合 – 複雑性が低い場合 |
| 指標 | GPT直接利用 | TiDBベクトル検索 |
| 分析速度 | 2–5秒 | 0.1–0.5秒 |
| バッチ処理 | 逐次 (遅い) | 並列 (速い) |
| 拡張性 | APIレート制限あり | 高い拡張性 |
| クエリあたりのコスト | $0.002–0.01 | $0.0001–0.001 |
| レスポンス時間 | 変動あり | 一定 |
| 同時実行ユーザー数 | 1分あたり〜60リクエスト程度 | データベースの性能に依存 |
2. 正確性と品質
| 項目 | GPT直接利用 | TiDBベクトル検索 |
| 感情分析の精度 | 95%以上 | 85–90% |
| 文脈の理解 | 非常に優れている | 良好 |
| ニュアンスの検知 | 卓越している | 標準的 |
| 皮肉・アイロニー | 十分に検知可能 | 限定的 |
| 多言語対応 | 強力 | エンベディングに依存 |
| カスタムドメイン | プロンプトで調整可能 | 再学習が必要 |
3. コスト分析
| GPT GPT直接利用 (1,000 テキスト分析あたり) – 入力トークン:約500トークン/テキスト × 1,000 = 50万トークン – 出力トークン:約200トークン/テキスト × 1,000 = 20万トークン – コスト:1,000分析あたり約10–15ドル – 月額コスト (1万テキスト):100–150ドル | TiDBベクトル検索 (1,000 テキストあたり) – エンベディング生成:約50万入力トークン = 0.10ドル – ストレージ:1,000ベクトル × 1,536次元 × 4バイト = 6MB = 0.01ドル/月 – クエリ:約1,000検索 = 0.01ドル – 初期コスト:約0.11ドル (1回限り) – 月額コスト (1万検索):1–2ドル |
4. 意思決定マトリックス:GPT直接利用とTiDBベクトル検索
| 判断基準 | GPT直接利用 | TiDBベクトル検索 | 選択の目安 |
| 単発の分析 | 非常に優れている | 許容範囲 (取り込み負荷あり) | 結果が一度だけ必要な場合はGPT直接利用 |
| 繰り返しのクエリ | 非効率 (都度再処理が必要) | 非常に優れている (一度保存し、何度もクエリ可能) | 再利用の多いワークフローにはTiDBベクトル検索 |
| 大規模データセット (1000件超) | 低速かつ高コスト | バッチ処理により効率的にスケール | ボリュームとスケール重視ならTiDBベクトル検索 |
| リアルタイム分析 | 可能 | 可能 | 両者ともリアルタイムのユースケースに対応可能 |
| セマンティック検索 | 限定的 | 専用設計で高速 | 類似性検索にはTiDBベクトル検索 |
| 文脈・複雑な推論 | 強力 (ニュアンス、皮肉、説明) | エンベディングの品質に依存1 | 深い理解が必要ならGPT直接利用 |
| 履歴クエリとトレンド | 非対応 | 永続ストレージによりネイティブ対応 | 長期的な分析にはTiDBベクトル検索 |
| トレンドと集計分析 | リクエストごとに再計算 | 効率的なSQLベースのクエリ | ダッシュボードや分析にはTiDBベクトル検索 |
| データの永続性 | なし (ステートレス) | 完全な永続性 | メモリベースのシステムにはTiDBベクトル検索 |
| マルチユーザープラットフォーム | 分離が困難 | データベースによるユーザーレベルの分離 | SaaS製品にはTiDBベクトル検索 |
| カスタムインサイトの生成 | 非常に柔軟 (プロンプト駆動) | エンベディングに制限される | 探索的な作業にはGPT直接利用 |
| エクスポートとデータの再利用 | 限定的 | データセット全体の出力が可能 | 後続のワークフローにはTiDBベクトル検索 |
| スケール時のコスト | 線形増加 | データ取り込み後は低速な増加 | 本番環境の経済性重視ならTiDBベクトル検索 |
| 実装の複雑さ | 低い | 中〜高 | MVPならGPT直接利用、長期システムならTiDBベクトル検索 |
| 本番環境への適応性 | ツールとしては良好 | プラットフォームとして強力 | 本番用アプリにはTiDBベクトル検索 |
現在の実装状況
| パス1:GPT直接利用 エンドポイント: POST /api/chat – メイン分析エンドポイント分析タイプ ✅ 感情分析 (シンハラ語&英語) ✅ ワードクラウド / 頻出単語 ✅ トピックのクラスタリング ✅ 感情検知 機能: ✅ 各分析タイプごとのカスタムシステムプロンプト ✅ バイリンガル出力 ✅ チャート用構造化JSONレスポンス ✅ テキスト分析に基づく段落形式のインサイト ✅ リアルタイム処理 ✅ Sentryによるエラー追跡 | パス2:TiDBベクトル検索エンベディング データベース: ✅ TiDB Serverlessクラスタ ✅ VECTOR (1536次元) サポート ✅ ユーザーの分離 (user_idフィルタリング) ✅ 感情スコアの保存 ✅ メタデータJSONの保存 機能: ✅ Azure OpenAI text-embedding-ada-002 ✅ コサイン類似度検索 ✅ レート制限付きバッチ処理 ✅ ユーザー固有のデータ分離 ✅ 感情スコアリング (ポジティブ/ニュートラル/ネガティブ) ✅ 履歴データの取得 ✅ Sentryによるモニタリング |
性能ベンチマーク:負荷下での反復分析
テストシナリオ:100件の顧客レビュー
GPT直接利用
Processing: 100 texts
Method: Sequential API calls
Time: 180 seconds (3 minutes)
Cost: $1.50
Rate limit: Hit after 60 requests, paused
Result: Rich insights with context
TiDBベクトル検索
Processing: 100 texts
Method: Batch embedding + storage
Embedding time: 30 seconds
Storage time: 5 seconds
Search time (10 queries): 2 seconds
Cost: $0.02 initial + $0.001 per query
Result: Fast semantic search, persistent storage
シナリオ:反復類似性クエリ (再解析とベクトル検索)
GPT直接利用
Query: "Find feedback similar to 'poor customer service'"
Method: Re-analyze all texts with custom prompt
Time: ~120 seconds (re-process all)
Cost: $1.20 per query
Accuracy: Excellent (understands context)
TiDBベクトル検索
Query: "poor customer service"
Method: Generate embedding, vector search
Time: 0.3 seconds
Cost: $0.0001 per query
Accuracy: Very good (semantic matching)
最速の勝者:TiDBベクトル検索 (類似性検索において400倍高速化)
セキュリティとプライバシーの比較
| 評価項目 | GPT直接利用 | TiDBベクトル検索 |
| データストレージ | なし (一時的) | データベース内に永続化 |
| データ保持 | Microsoftによる30日間保持* | ユーザー側で制御可能 |
| ユーザーの分離 | なし | user_idによるフィルタリング |
| GDPRコンプライアンス | Azureのコンプライアンスに準拠 | ユーザー側の責任 |
| データ暗号化 | 通信時のTLS | TLS + 保存データの暗号化 |
| 監査ログ | APIログ | 完全なデータベース監査 |
| 削除する権利 | 30日後に自動削除 | 手動削除 |
スケーラビリティ分析
| パス1:GPT直接利用 制限事項 – レート制限:60リクエスト/分 (TPM:15万 トークン / 分) – 逐次処理 (バッチ処理では低速) – コストが利用量に応じて線形に増加 – キャッシュ機構なし 拡張戦略 – リクエストのバッチ化 – 一般的な分析内容のキャッシュ – レート制限の管理 – 複数のAPIキー利用 (高コスト) | パス2:TiDBベクトル検索 利点 – データベースの水平スケールが可能 – 並列クエリ処理 – コスト増加が線形を下回る (利用量に対して緩やか) – キャッシュ機能内蔵 拡張戦略 – TiDBコンピューティングノードの追加 – インデックスの最適化 – クエリ用リードレプリカの活用 – user_idによるパーティショニング スケーラビリティの勝者:TiDBベクトル検索 (成長により適している) |
開発者体験
| パス1:GPT直接利用 メリット: ✅ シンプルなAPI統合 ✅ データベースのセットアップ不要 ✅ 柔軟なプロンプトエンジニアリング ✅ 迅速なプロトタイピング デメリット: ❌ 各分析タイプごとのカスタムシステムプロンプト ❌ バイリンガル出力 ❌ チャート用構造化JSONレスポンス ❌ テキスト分析に基づく段落形式のインサイト コードの複雑性:低 | パス2:TiDBベクトル検索エンベディング メリット: ✅ 慣れているSQLの利用 ✅ 標準的なCRUD操作 ✅ 強力なクエリ機能 ✅ データ永続化の組み込み デメリット: ❌ データベースのスキーマ設計 ❌ ベクトル操作の学習コスト ❌ エンベディングの管理 ❌ バッチ処理のロジック コードの複雑性:中〜高 |
技術参考資料
- Azure OpenAI:https://learn.microsoft.com/en-us/azure/ai-services/openai/
- TiDBベクトル検索:https://docs.pingcap.com/ja/ai/vector-search-overview/
- OpenAI Embeddings:https://platform.openai.com/docs/guides/embeddings
意思決定フレームワーク:いつ何を使用するか
これらの実験を行った結果、私が使用した判断基準は以下の通りです。
GPT直接利用を選択する場合:
- 一回限りの分析やアドホックなインサイトが必要なとき
- データセットが小さいとき
- 最大限の正確性と微細な理解が必要なとき
- プロトタイピングフェーズで迅速なイテレーションを望むとき
- 同じデータに対して繰り返しクエリを実行する必要がないとき
TiDBベクトル検索を選択する場合:
- 本番アプリケーションを構築しているとき
- ユーザーが同じデータセットに対して複数のクエリを実行するとき
- セマンティック類似性検索 (関連コンテンツの検索) が必要なとき
- 大規模環境でのコスト効率が重要なとき
- 大規模なデータセットがあるとき
- マルチユーザーの分離とデータ永続化が必要なとき
- データのプライバシーが重要であり、プライバシーを保護するワークフローを純粋にLLM上で実行するコストや運用上のオーバーヘッドを避けたいとき
GPT直接利用とTiDBベクトル検索を併用した方法
CrowdSnapでは、最終的に両方のアプローチを実装しました:
- ユーザーが即座に感情分析を行いたい「クイックインサイト」機能にはGPT直接利用
- ユーザーがパターンを探索し、類似の回答を見つけ、複数のクエリを実行できる「ディープ分析」モードにはTiDBベクトル検索
このハイブリッドアプローチにより、ユーザーは必要に応じたスピードと、深く掘り下げたい時のパワーという、両方の長所を活用できるようになります。
主な教訓
- ベクトルデータベースが常に最初から速いわけではありません:初期のエンベディング生成には時間がかかります。TiDBベクトル検索は、同じデータに対して複数回クエリを実行する必要がある場合に真価を発揮します。
- コストのスケールは大きく異なります:GPT直接利用では、すべての分析にコストがかかります。TiDBでは、インデックスを一度作成すれば、その後のクエリはほぼ無料です。
- 精度とスピードは真のトレードオフです:GPTの文脈理解は優れていますが、多くのユースケースにおいて、ベクトル類似性は「十分な」精度であり、かつ遥かに高速です。
- スケールにはアーキテクチャが重要です:複数のユーザーや大規模なデータセット向けに構築する場合、ベクトルデータベースのアーキテクチャはパフォーマンスとコストの面で大きな利益をもたらします。
試してみよう
CrowdSnap Analysisは、プライバシーバイデザインによる高速で正確なアナリティクスに焦点を当てています。基盤となるインフラストラクチャにMPC (マルチパーティ計算) を使用することで、生の入力データに直接アクセスせずにデータを分析でき、プライバシーリスクと運用オーバーヘッドを削減します。
これらのアプローチを試してみたいですか?CrowdSnap Prompt Analysis betaをチェックして、両方の実装が動作しているところを確認してください。
同様の機能を構築することに興味がある開発者にとって、TiDBのベクトル検索機能を使用すれば、個別のベクトルデータベースを管理することなく、アプリケーションにセマンティック検索を驚くほど簡単に追加できます。
技術スタック:Azure OpenAI (GPT-4 & text-embedding-ada-002), TiDB Cloud, Next.js
- TiDBをGPTと組み合わせて根拠となる説明を生成し、ハイブリッドの精度をさらに向上させることができます――例えば、ベクトル検索の結果をLLMプロンプトの入力として使用することで、ニュアンスとスピードのバランスを取ることができます。 ↩︎


TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。