

※このブログは2025年7月17日に公開された英語ブログ 「Scaling Observability: Why TiDB Moved from Prometheus to VictoriaMetrics」 の拙訳です。
Prometheusは当初から、TiDBにおけるリアルタイムパフォーマンスメトリクスの収集、保存、クエリ、およびオブザーバビリティのための主要ツールとして活用されてきました。さらに、TiDBはTiDB Clinicを用いたオフライン診断をサポートしており、収集したメトリクスを再生することで過去の問題を調査することが可能です。
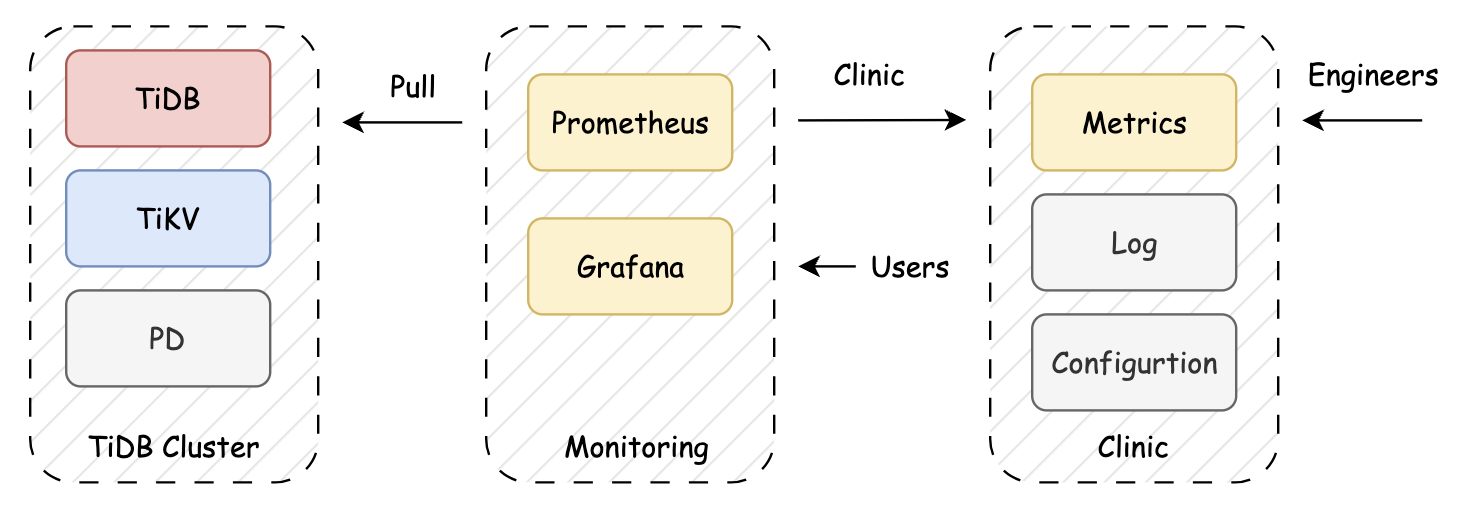
図1. TiDB Clinicが提供するオフライン診断の仕組み
しかし、デプロイメントの規模が拡大するにつれ、Prometheusの使用に伴う課題も増大しました。本ブログでは、こうした成長に伴う課題と、最終的に高性能なオープンソースの時系列データベースおよび監視ソリューションであるVictoriaMetricsへ移行した理由について考察します。
TiDBのオブザーバビリティ:大規模環境におけるPrometheusの限界
Pinterest社はPingCAPの最大級のエンタープライズ顧客のひとつであり、700ノード以上で構成されるTiDBクラスタを運用し、70万QPS超のトラフィックを処理しています。しかし、同チームは監視上の問題に直面し始めました。TiDB Clinicを使用した診断セッション中、Prometheusが継続的にクラッシュし、運用負荷が増大するとともに、インシデントの解決が遅れる要因となっていました。
スケーラビリティの問題
PingCAPがPinterestチームと共同作業を行った際、ハイエンドのi4i.24xlargeインスタンス (96コア、768GB RAM) においても、Prometheusで頻繁にメモリ不足 (OOM) によるクラッシュを起こすことが確認されました。クエリの失敗や再起動に長時間を要することが、問題の効果的な診断能力に大きな影響を与えていました。
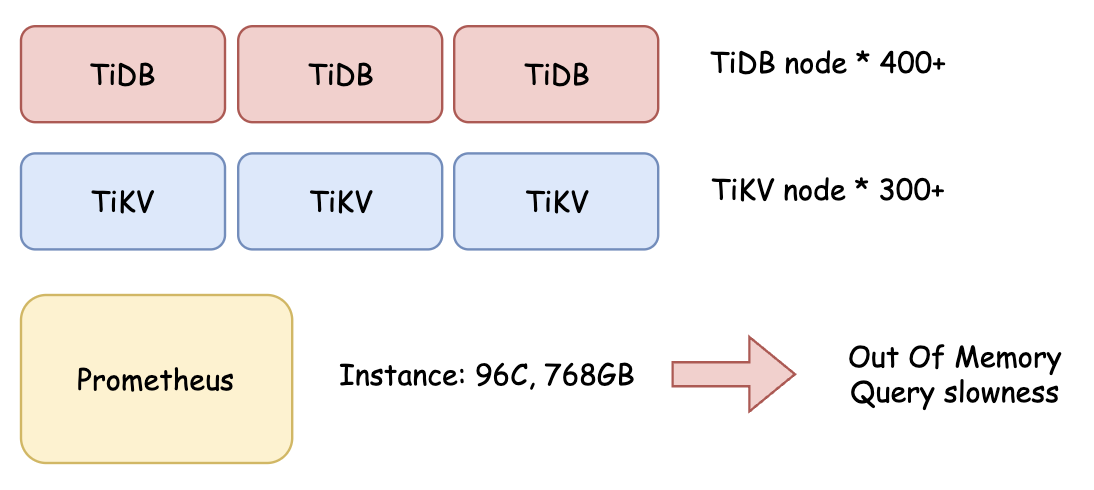
図2. Prometheus使用時に発生したPinterestのOOMクラッシュを示す図解.
OOM (Out of Memory) Problem
大規模なクエリを実行する際、Prometheusは頻繁にOOM (メモリ不足) が発生し、クラッシュを引き起こしていました。再起動プロセスには追加の課題がありました:
- 長時間の復旧プロセス:OOMクラッシュの後、PrometheusはWrite-Ahead Log (WAL) のリプレイを行う必要があり、この処理には最低でも40分を要し、場合によっては完全に失敗することもありました。
- 繰り返すOOM:一部のケースでは、WALのリプレイ中に再度OOMが発生し、Prometheusの回復を阻害しました。
- 長時間のダウンタイムとデータ損失:このような不安定な挙動により、監視システムの長時間停止やメトリクスの潜在的な損失が発生し、ミッションクリティカルなクラスタに対する信頼性が確保できませんでした。
以下のログは、400ノード構成のテスト環境におけるクラッシュ復旧にかかった時間を示しています:
WALリプレイ開始時刻:22:52:07

WALリプレイ終了時刻:23:34:32、所要時間:42分

これらの制約は、よりスケーラブルで耐障害性の高い監視ソリューションの必要性を浮き彫りにしました。
クエリのパフォーマンス
大規模なクエリでは、時間の範囲を15分に制限する必要がありました。そうしないと、クエリが大幅に遅延するか、完全に失敗する結果となりました。
Clinicデータ収集においても同様の問題が発生しました。1時間分のメトリクスを取得しようとすると、クエリは40分間実行された後、最終的にOOM (メモリ不足) により失敗しました。
総所有コスト (TCO)
Prometheusを使用する場合、大規模な監視インスタンス (i4i.24xlarge、96コア、768GB RAM) を割り当てる必要がありましたが、それでも安定性とパフォーマンスに課題を抱えていました。
TiDBがより優れたオブザーバビリティのためにVictoriaMetricsに切り替えた理由
社内チームおよびクラウド顧客の進化するニーズに対応するため、代替となる時系列データのバックエンドを評価した結果、最終的にVictoriaMetricsへの移行を決定しました。以下に、移行の主な理由とそれに伴う具体的な改善点を示します。
1.より良いリソース利用効率
VictoriaMetricsに移行した後、リソース消費が大幅に削減されることを確認しました。
- CPU使用率は50%未満
- メモリ使用率は35%未満に抑えられ、OOMクラッシュが解消
- 高負荷のクエリでも安定したパフォーマンスを維持
2.クエリパフォーマンスの向上
- 以前はPrometheusで15分間の時間の範囲に限定されていた大規模クエリが、VictoriaMetricsでは数時間の範囲にわたって実行可能になりました。
- クエリの実行速度が向上し、トラブルシューティングや過去データの分析がより効率的になりました。
- ただし、最も大きなクエリの一部は依然として実行が困難であり、さらなる最適化の余地があることを示しています。
3. リソース消費の削減とTCOの改善
VictoriaMetricsに切り替えたことで、Pinterestはリソース消費を大幅に削減しながら安定性を向上させました。さらに、ストレージ効率の改善によりディスク使用量も減少し、監視のコスト効率が向上しました。
全体として、VictoriaMetricsはより高い安定性、効率性、スケーラビリティを提供し、TiDBの監視においてより信頼性の高いソリューションとなりました。
これらの改善をPinterestで検証した後、同チームは無事にVictoriaMetricsへの移行を成功させました。
TiDBオブザーバビリティ:パフォーマンステスト結果
VictoriaMetricsの効果を評価するために、Pinterestのクラスタで異なる構成を用いたテストを実施しました。結果は以下の表に示す通り、VictoriaMetricsがリソース使用量を大幅に削減し、クエリパフォーマンスを向上させたことを示しています。
| メトリクス | 期間 | パフォーマンス |
| Prom – KVリクエスト | 過去15分 | 失敗 |
| VM – KVリクエスト – デフォルト設定 | 過去15分 | 30秒で失敗 |
| VM – KVリクエスト – チューニング済み | 過去15分 | 1分で失敗 |
| VM – KVリクエスト – リリース版 | 過去15分 | 成功 (3分) |
| Prom – 99% grpc リクエスト時間 | 過去30分 | 失敗 (26秒) |
| Prom – 99% grpc リクエスト時間 | 過去1時間 | 失敗 (15秒) |
| VM – 99% grpc リクエスト時間 – デフォルト設定 | 過去1時間 | 成功 (8.4秒) |
| VM – 99% grpc リクエスト時間 – チューニング済み | 過去1時間 | 成功 (7.4秒) |
| VM – 99% grpc リクエスト時間 – リリース版 | 過去1時間 | 成功 (6.5秒) |
重要なポイント
- PrometheusはKVリクエストで継続的に失敗していたのに対し、VictoriaMetrics は特にリリース構成で大幅な改善を示し (3分で成功)、安定した動作を実現しました。
- PrometheusはgRPCリクエスト時間の取得に苦戦し、30分や1時間のクエリでも失敗していました。
- VictoriaMetricsはgRPCクエリパフォーマンスを大幅に改善し、実行時間をデフォルト設定の8.4秒からリリース設定の6.5秒まで短縮しました。
- VictoriaMetricsの各種構成 (デフォルト、チューニング済み、リリース) は、maxQueryDurationやmaxSeriesといったパラメータが調整され、パフォーマンスと成功率に影響を与えました。
スムーズな移行戦略
データ保持期間が10日間であったため、リスクを最小限に抑え、PrometheusからVictoriaMetricsへの移行を円滑に進めるために段階的な移行アプローチを採用しました。
ステップ1:並行運用による観察
- テスト結果に基づき、メトリクスのスクレイピングがTiDBクラスタに与える影響は最小限であることが分かりました。
- 即時の切り替えは行わず、PrometheusとVictoriaMetricsを並行して稼働させ、既存の監視ワークフローを妨げることなくパフォーマンスや安定性を観察しました。
ステップ2:検証とモニタリング
- このフェーズでは、PrometheusとVictoriaMetricsの間でデータの正確性、クエリ性能、システムの安定性を比較しました。
- エンジニアはVictoriaMetricsのリソース使用状況、クエリ応答時間、障害率を継続的に監視し、信頼性を確認しました。
ステップ3:最終切り替え
- 十分な監視データが集まり、すべてが問題なく稼働していることを確認した後、VictoriaMetricsへの完全移行を実施しました。
- この時点でPrometheusを停止し、ダウンタイムやデータ損失なく移行を完了しました。
この段階的な移行戦略により、突然の切り替えに伴うリスクを回避しつつ、安定した移行を実現できました。
設定および統合に関する考慮点
PrometheusからVictoriaMetricsへの移行には、スクレイプ設定、ディスカバリーファイル、起動スクリプト、Grafanaダッシュボード、Clinic統合など、複数の主要コンポーネントにわたる調整が必要でした。
スクレイプ設定とディスカバリーファイルの継承
- VictoriaMetricsは、ほとんどのPrometheusの構成と互換性を維持しています。
- 互換性のないパラメータを処理するために軽微な修正を加えるだけで、既存のスクレイプ設定ファイルやディスカバリーファイルを再利用することができました。
スタートアップスクリプトのテスト
クエリパフォーマンス、リソース制限、安定性のバランスを取るため、3種類の異なるVictoriaMetrics起動構成をテストしました。最終的には、チューニング構成 (Tuned Configuration) アプローチを採用しました。
1. デフォルト構成 (ベースライン設定)
- 最小限のチューニングによる基本的なセットアップ
- データ保持期間を10日間、最大スクレイプサイズを400MBに設定
docker run -it -v {PATH}/victoria-metrics-data:/victoria-metrics-data \
--network host -p 8428:8428 victoriametrics/victoria-metrics:v1.106.1 \
-retentionPeriod=10d \
-promscrape.config=/victoria-metrics-data/vm.config \
-promscrape.maxScrapeSize=400MB
2. チューニング構成 (制限の緩和・最終的に選択 ✅)
- より大規模なクエリに対応するため、クエリ実行時間と時系列数の上限を引き上げた構成。
docker run -it -v {PATH}/victoria-metrics-data:/victoria-metrics-data \
--network host -p 8428:8428 victoriametrics/victoria-metrics:v1.106.1 \
-search.maxSeries=5000000 \
-search.maxLabelsAPISeries=5000000 \
-search.maxQueryDuration=1m \
-promscrape.config=/victoria-metrics-data/vm.config \
-promscrape.maxScrapeSize=400MB \
-search.maxSamplesPerQuery=1000000000 \
-search.logSlowQueryDuration=30s \
-retentionPeriod=10d
3. リリース構成 (制限を大幅緩和・採用せず)
- Further increased limits to support more complex and long-running queries.
docker run -it -v /mnt/docker/overlay2/victoria-metrics-data:/victoria-metrics-data \
--network host -v /var/lib/normandie:/var/lib/normandie:ro,rslave \
-p 8428:8428 victoriametrics/victoria-metrics:v1.106.1 \
-search.maxSeries=50000000 \
-search.maxLabelsAPISeries=50000000 \
-search.maxQueryDuration=10m \
-promscrape.config=/victoria-metrics-data/vm.config \
-promscrape.maxScrapeSize=400MB \
-search.maxSamplesPerQuery=10000000000 \
-search.logSlowQueryDuration=30s \
-retentionPeriod=10d
診断用のClinicコマンド
TiDBのClinic診断データを収集するため、Prometheusの代替としてVictoriaMetricsを使用するようコマンドを調整しました。
tiup diag util metricdump --name {cluster_name} --pd={PD_URL}:{PD_PORT} \
--prometheus="{VICTORIA_URL}:8428" --from "-1h" --to "-0h"
Grafanaダッシュボードの調整
- GrafanaのデータソースとしてVictoriaMetricsを使用するよう設定しました。
- 各ダッシュボードに必要な修正を行い、新しいVictoriaMetricsデータソースをデフォルトに設定しました。
最後に:TiDBオブザーバビリティの今後
オブザーバビリティは、TiDBクラスタの健全性と高パフォーマンスを維持するうえで、依然として非常に重要な柱です。VictoriaMetricsへの移行により、スケーラビリティ、信頼性、効率性が大きく向上しました。
今後の改善ポイントとしては、以下のような取り組みが考えられます:
- 超大規模クエリへの最適化
- 10日を超える長期メトリクス保持のためのストレージソリューションの検討
- リソース使用率とユーザー体験の向上を目的とした、統合監視プラットフォームの構築
VictoriaMetricsは、大規模なTiDBオブザーバビリティにおける強力な基盤であることが実証されました。
TiDBの監視やオブザーバビリティに関するご質問がございましたら、ぜひTwitter、LinkedIn、またはSlackチャンネルを通じてお気軽にお問い合わせください。



TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。