
※このブログは2026年4月7日に公開された英語ブログ「Reducing P999 Latency in Distributed Databases with TiDB 8.5」の拙訳です。
主なポイント
- 分散OLTPシステムにおいてSLOを損なうのは平均レイテンシーではなく、テールレイテンシーです。
- 本番環境の各種クラスタでは、TiDB 8.5へのアップグレード後、ワークロードの変更なしにP999レイテンシーが数十秒から100ms未満に低下しました。
- 最大の成果は、稀ではあるが致命的な処理のストール (GC一時停止、ロック競合、ストレージスナップショットのオーバーヘッド) を排除したことによって得られました。
- TiDB 8.5は、不要なタスクの削除、高コストな操作の置き換え、およびクリティカルパス外へのタスクの並べ替えにより、スタック全体を最適化しています。
- 高QPSで、厳格なレイテンシー要件を持つ大規模なワークロードが最も恩恵を受けます。
分散データベースにおけるP999レイテンシーの削減は、現代のOLTPシステムにおける最も困難な課題の一つです。わずかな遅いリクエストがサービス全体に波及し、サービスレベル目標 (SLO) を破り、特にトレーディングプラットフォームやリアルタイムアプリケーションのようなレイテンシーに敏感な環境では、ビジネス成果に直接影響を与えます。
これがテールレイテンシーの課題です。システムがスケールするにつれて、変動要因が重なります:キューイングが小さな遅延を増幅させ、ファンアウトによる並行処理によって、稀に発生する遅いサブリクエストが頻繁なユーザー直面の課題へと変わり、スタック全体に隠れたボトルネックが予測不可能なスパイクを生み出します。
実際には、悪影響を及ぼすのは中央値ではなく、P99やP999です。TiDB 8.5では、平均値を改善するのではなく、レイテンシーのばらつきを体系的に削減することで、この問題に根本から対処します。
本番環境で観察されたこと
TiDB 8.5はパフォーマンスに焦点を当てたリリースです。インプレースの本番アップグレード (同一のワークロードと設定、TiDB / TiKVバージョンのみをv7.5.6からv8.5.4に変更) において、実際のOLTPサービスにとって最も重要な要素に段階的な変化が見られました。
- テールレイテンシーが劇的に減少:P999は数十秒から1秒未満へと推移し、一部のウィンドウでは数十ミリ秒まで低下しました。
- スロークエリの負荷が低下:スロークエリのバーストは、時間枠に応じて約30%~90%減少しました。
- リソースの挙動がよりスムーズに:TiKVのCPU使用率は平均で約10%~25%低下し、極端なスパイクが減少しました。
以下の図は、これらの本番クラスタで観察されたレイテンシー分布の変化をまとめたものです。アップグレード前 (TiDB 7.5) とアップグレード後 (TiDB 8.5) のパーセンタイルレイテンシー曲線を比較しています。
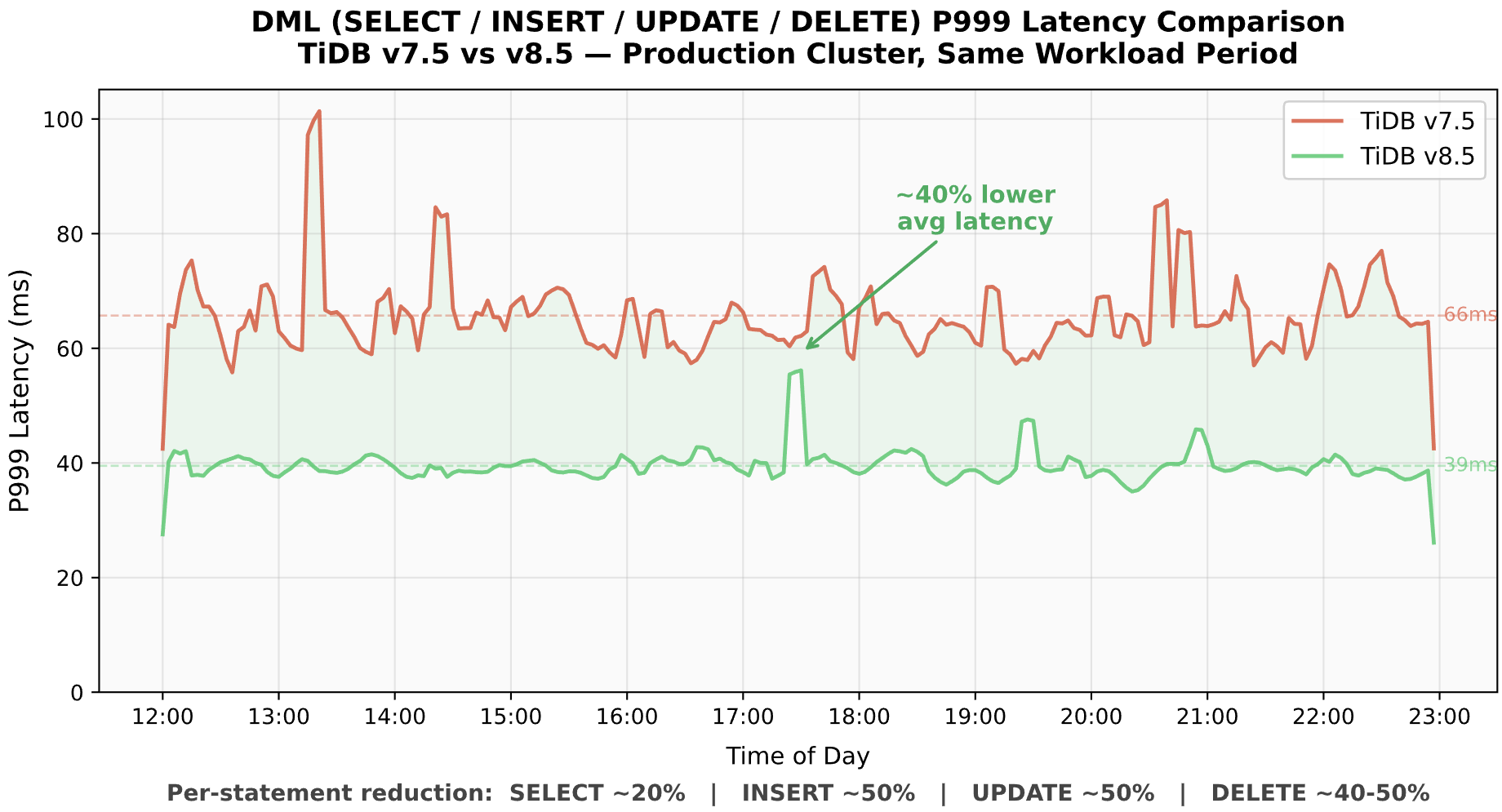
図1:大規模な本番クラスタ (100以上のTiKVノード、ストアあたり4TiB以上のデータ、150K以上のQPS) で実行されている混合読み取り / 書き込みOLTPワークロードにおけるレイテンシーの改善。
これらの結果は特定のワークロードに依存するものではなく、負荷がかかっている状態でTiDBがレイテンシーを制御する方法における体系的な改善を反映しています。
TiDB 8.5の恩恵を最も受けるワークロード
これらの改善がどこから来ているのか、そしてそれがお客様のシステムに適用されるかどうかを理解するためには、TiDBでテールレイテンシーを引き起こすワークロードの特性を見ることが重要です。
上記の本番環境の結果が示すように、すべてのデプロイメントで同レベルの改善が見られるわけではありません。成果は特定の条件下で最も顕著になります。
| 最適化 | 根本原因 | 最適なケース |
| メモリアロケーションのプーリング (削除) | GoランタイムのGC一時停止とgoroutineスケジューリングの遅延がSQL層で散発的なレイテンシースパイクを引き起こす | 多数の短時間のOLTPクエリを伴う高QPS (100K+);P99でGoのGC一時停止が顕著;毎秒数万行が変更される |
| ART(Adaptive Readix Tree) membuffer (置き換え) | 赤黒木を採用したMemDBがCPU時間の大部分をキー比較に費やす;長い共通接頭辞を持つキーのO (log n) 比較が高コスト | 多数のインデックスを持つ大きなテーブル;長い共通接頭辞 (テーブル接頭辞、インデックス接頭辞) を共有するキー;列数の多いテーブルに対する書き込み負荷の高いDML |
| 非同期スナップショット / SST mutex (並べ替え) | ストレージの非同期スナップショットの所要時間がSSTファイル数とともに増加する;メタデータ操作中のmutex競合がフォアグラウンドの書き込みをブロックする | TiKVストアあたりの大きなデータ容量 (例:4TiB+);多いSSTファイル数 (100K–200K+);レイテンシーに敏感な読み取りと並行して継続的な書き込み負荷がある |
| gRPCバッチング / TSO並列化 (削除) | PDおよびTiKVとの調整オーバーヘッドがクエリごとのラウンドトリップを追加する | 高いファンアウトを持つクエリ;多数のTiKVノードを持つデプロイメント;PD/TiKVへのネットワークレイテンシー |
実際には、高QPS、大規模なデータ容量、多数のインデックス、および厳格なレイテンシーSLOを組み合わせたシステムで最大の成果が得られます。そこでは、小さな非効率性が積み重なってテールレイテンシーのスパイクを引き起こしやすいためです。
QPSが低いワークロードやデータセットが小さい場合、テールレイテンシーが調整やストレージレベルのストールに支配されないため、影響はそれほど劇的ではありません。しかし、ベースラインのオーバーヘッド削減により、依然として測定可能な改善が得られます。
TiDB 8.5が分散データベースのP999レイテンシーを削減する方法
TiDB 8.5は、アーキテクチャのすべてのレイヤーに体系的な最適化を通じて、テールレイテンシーの課題に対処します。これらは段階的なな微調整ではなく、パフォーマンスの変動の根本原因を標的とした基本的なエンジニアリングの改善です。
最適化戦略
TiDBのような分散システムでは、レイテンシーはリクエストの経路に沿った並列実行、調整、および待機イベントといった複数のステージにわたる依存関係から発生します。問題は、それをどのように体系的に削減するかです。
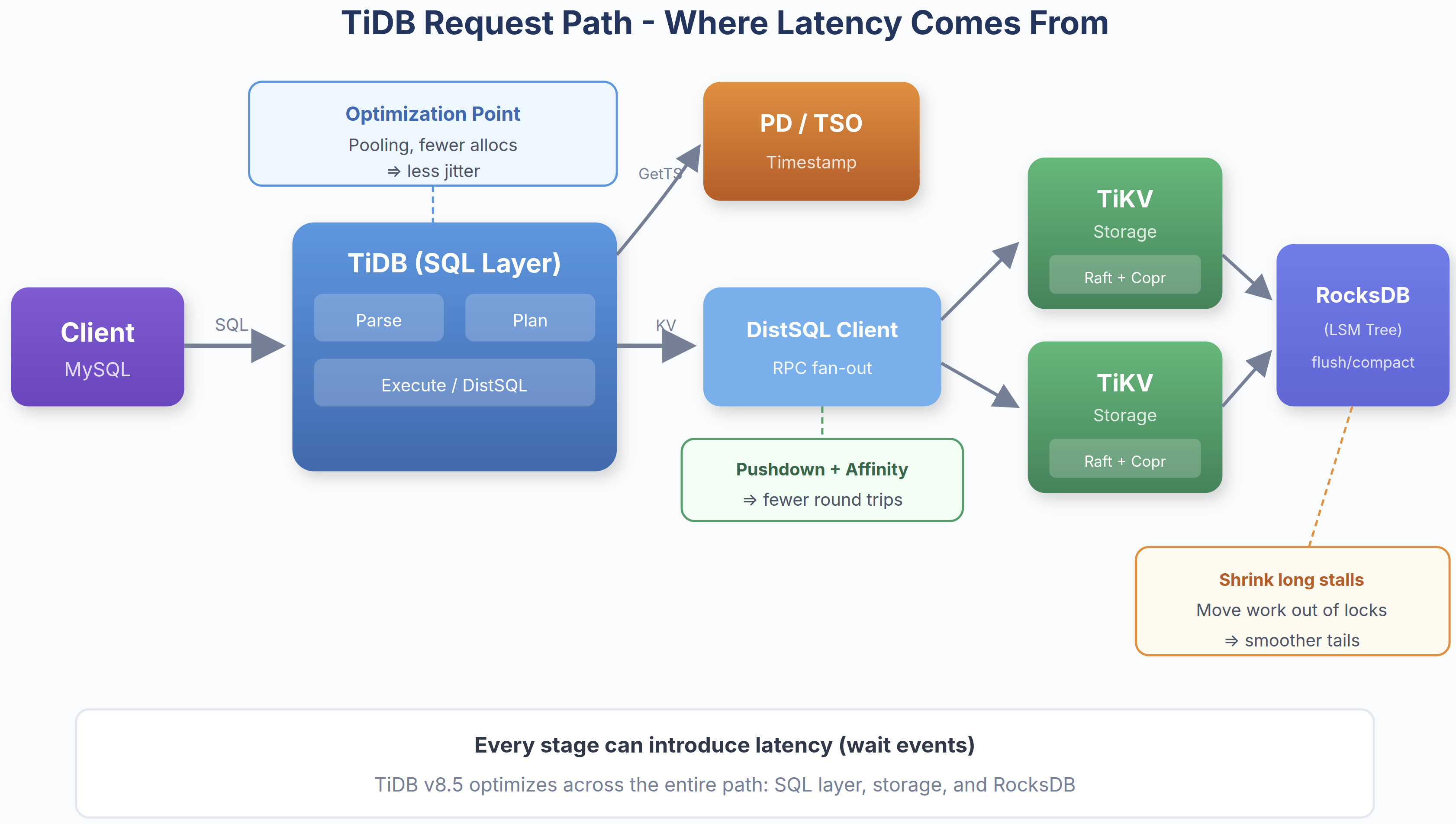
図 2:レイテンシーはあらゆる段階で追加され、効果的な最適化にはスタック全体で作業、ラウンドトリップ、およびストールを削減する必要があります。
これらの改善は独立したものではなく、一貫したパターンに従っています。Serial Performance Optimization (OSDI’25) によれば、レイテンシーは3つの主要なレバーを通じて削減できます。
- クリティカルパスからタスクを削除する (待機の減少、ラウンドトリップの減少)
- 高コストなタスクを低コストなものに置き換える (より優れたデータ構造、競合の減少)
- ストールを避けるためにタスクを並べ替える (プーリング、パイプライン化、ホットなロックの外への作業の移動)
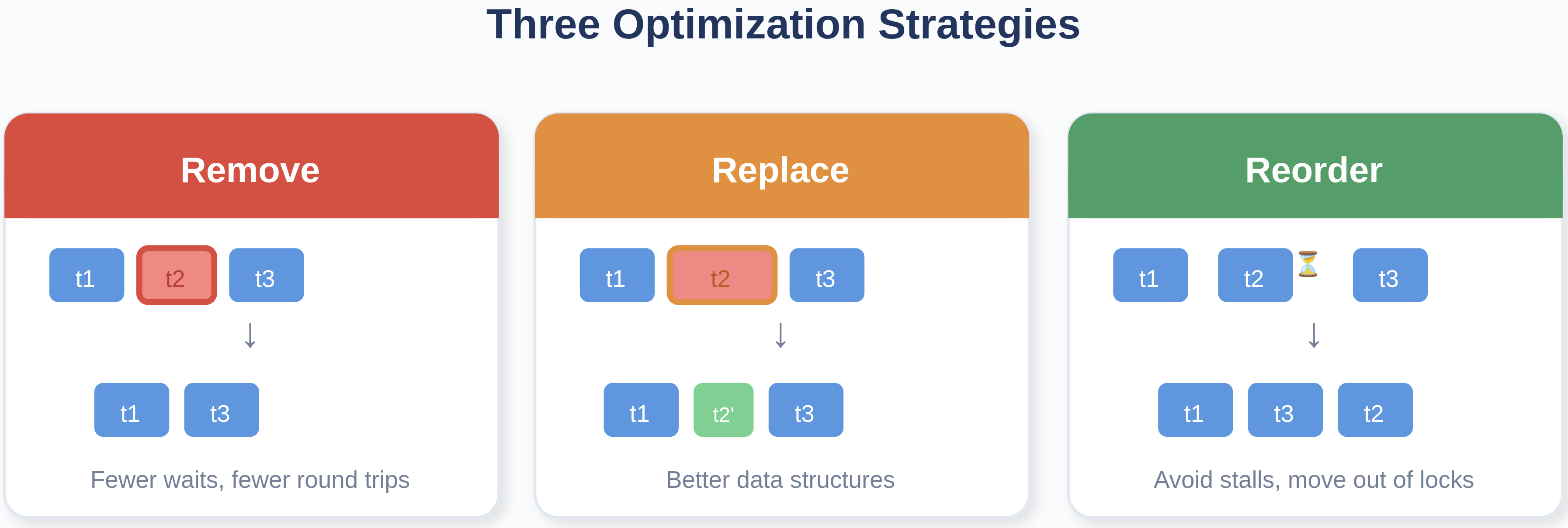
図3:Serial Performance Optimization (OSDI’25) で説明されている3つの最適化戦略。
| 戦略 | TiDB 8.5の変更点 | 影響 |
|---|---|---|
| 削除 | メモリプーリング、goroutineの再利用、RPC調整の削減 | GCおよびスケジューリングのオーバーヘッドを低減 |
| 置き換え | 赤黒木を採用したMemDBをARTに置換 | 比較回数の減少、キャッシュローカリティの向上 |
| 並べ替え | 非同期スナップショット + SST mutexの最適化 | 長時間のストールを排除 |
主要な最適化
TiDB 8.5のパフォーマンス向上作業は、TiDB -> TiKV -> RocksDBのパスにおけるこれら3つの動きの組み合わせです。
削除
これが重要になる場合:対象のクラスタが、多数の短時間のクエリを伴う高QPS OLTPワークロード (100K+ QPS) を実行している場合。これらの条件下では、クエリごとのメモリアロケーション、goroutineの作成、およびGoランタイムのスケジューリング / GCの累積コストが、クエリ全体のレイテンシーの大きな割合を占めるようになります。
TiDBでは通常、goroutineとメモリは安価で低コストなリソースであると想定しています。しかし、OLTPシナリオでは、多くのクエリが十分に短いため、「実際の作業を行うための待機」に費やされる時間が顕著になります。例としては、Goランタイムでのスケジューリング待機やメモリのガベージコレクションが挙げられます。
複数の小さなステップを一つにまとめることで、調整の待機や冗長な分散作業をどのように削減すべきでしょうか?TiDB 8.5では、いくつかのメモリアロケーションの最適化を導入しています。
- Goroutineの再利用:コプロセッサーへのリクエストごとに新しいgoroutineを作成する代わりに、TiDBは特定のコプロセッサー / DistSQLリクエストで余分なgoroutineの開始を回避します。
- ExecDetailsにおけるアロケーションの削減:実行詳細の構造体がプールされ、クエリごとに割り当てられるのではなく再利用されるようになりました。
- RuntimeStatsの最適化:実行統計の収集が最適化され、アロケーションのオーバーヘッドが削減されました。
- BuildCopIteratorの改善:コプロセッサーイテレータの構築パスで、事前割り当てされたバッファを使用するようになりました。
例えば、TiDBにおけるhandleキー (通常は主キー) 処理によるメモリアロケーションです。些細なことのように思えるかもしれませんが、その影響は実際には大きいです。
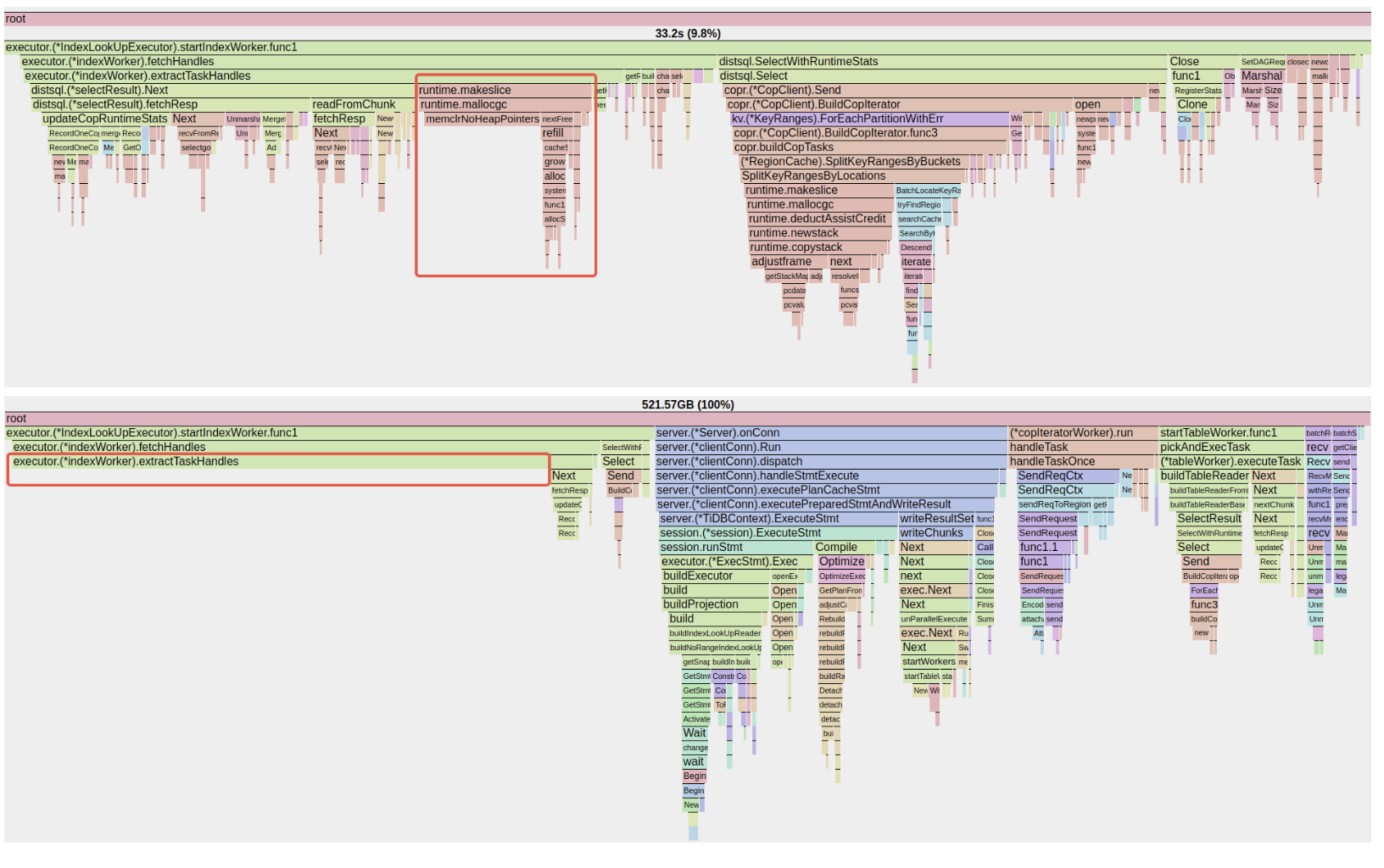
図4:最適化前後のCPUフレームグラフ。クリティカルパス上のアロケーションオーバーヘッドの削減を強調。
置き換え
これが重要になる場合:
- システム内に多数の大規模なトランザクションや、大きなバッチサイズのDML実行がある場合。これは実行中に多数の
MemDB読み取り / 書き込み操作が発生することを意味し、そこでは赤黒木がうまく機能しません。 - ユーザーテーブルに多数のインデックスがある、またはユーザーキーが長い共通接頭辞を共有している (これはTiDBでは一般的です。テーブルのすべてのキーは
t{tableID}_rまたはt{tableID}_i{indexID})で始まります)。共通接頭辞が長ければ長いほど、各赤黒木の比較が高コストになり、冗長なバイト比較に多くのCPUサイクルが浪費されます。
ホットパスのデータ構造とアルゴリズムをキャッシュフレンドリーにします。パフォーマンスの向上の中には、分散実行とは全く関係ないものもあります。それは、コアとなるメモリ内メカニズムを、ワークロードのキー形状に一致するものに置き換えることで実現します。TiDBでは、トランザクションワークロードにおいて長い共通接頭辞を持つキーが頻繁に含まれます。比較の多い構造を接頭辞に優しい構造 (例:トランザクションメンバッファ用のラディックスツリー形式のインデックス) に置き換えることで、変更あたりのCPUサイクルを削減し、キャッシュローカリティを向上させます。その結果、スループットが向上し、さらに重要なことに、負荷がかかっている状態でのレイテンシーのジッターが減少します。

図5:比較の多いホットパスを示す赤黒木MemDBのCPUプロファイル
TiDB 8.5では、デフォルトのメンバッファとして赤黒木をARTに置き換えます。ARTはラディックスツリーベースのメモリ内インデックスであり、以下の特徴を持ちます。
- キーの数に依存せず、キーの長さをkとしたときO (k) のルックアップ計算量を提供します。
- 長い共通接頭辞 (テーブル接頭辞、インデックス接頭辞など) を持つキーに対して特に効率的です。
- ポインタベースのツリー構造と比較して、優れたキャッシュローカリティを提供します。
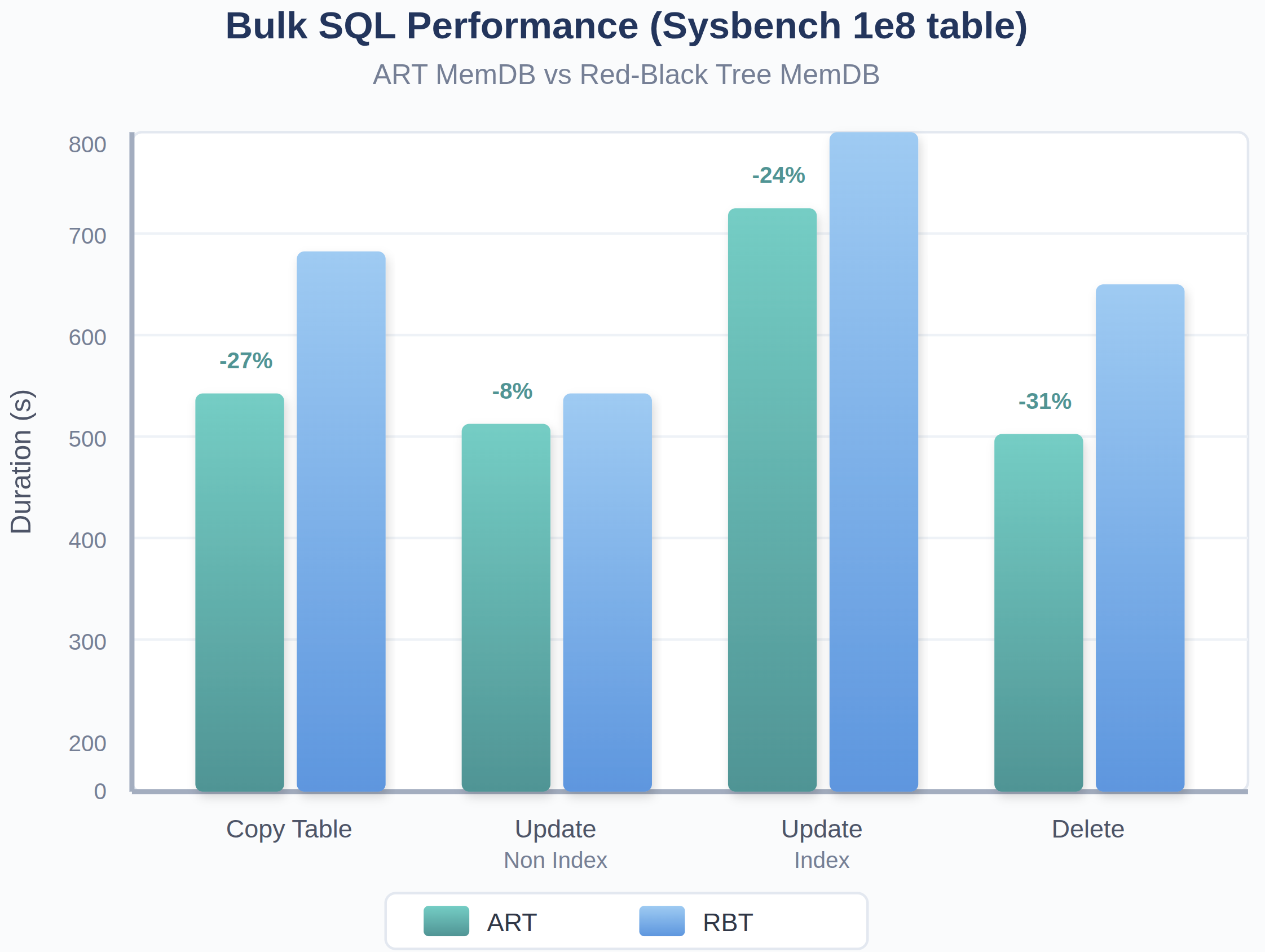
図6:ART MemDBは赤黒木と比較して、ワークロード全体でDMLの実行時間を短縮
sysbenchスキーマを使用したコピーテーブル (“insert into select * from”)、update_non_index、update_index、deleteベンチマークテストにおいて、ARTベースのMemDBはすべてのテストでより優れたパフォーマンスを示しています。
並べ替え
これが重要になる場合:対象クラスタのTiKVストアが大きなデータ容量 (ノードあたり数TB) を保持しており、結果としてSSTファイル数が多い (100K–200K) 場合。これらの条件下では、ストレージのメタデータ操作 (非同期スナップショットの取得など) が、ファイル数に比例した期間mutexを保持し、フォアグラウンドの読み取りおよび書き込み操作をブロックします。これが、P99.9+で観察される稀ではあるが壊滅的な数秒のレイテンシースパイクの主な原因です。
数分に及ぶテールを発生させる最も簡単な方法は、時折発生する「ストップ・ザ・ワールド」スタイルのストールに遭遇することです。スタックの成長、goroutineの頻繁な入れ替わり、ロック競合、またはデータ量とともに増大するストレージエンジンのクリティカルセクションです。TiDB 8.5は、システムをより予測可能にすることでこれに対処します。
- 一般的なエグゼキュータパスにおけるリクエストごとのgoroutineの作成に代わる、プーリング / 再利用。
- 競合の多いロックの外への作業の移動 (特にSSTファイル数とともにスケールする可能性のあるストレージエンジンのメタデータ更新内)。
- 運用タスク中のフォアグラウンド作業の停止の回避 (例えば、安全な同時書き込みを許可し、正確性が必要な場所でラッチを使用することにより、SSTインジェクションによるレイテンシーへの影響を軽減)。これらの変更がマイクロベンチマークで「小さく」見えたとしても、稀ではあるが壊滅的なストールを排除するため、P99 / P999を不均衡なほど改善します。

図7:SSTファイル数が増えるにつれて、非同期スナップショット所要時間のテールレイテンシーが高くなり、大容量データケースにおいてパフォーマンスの問題を引き起こします
RocksDBにおける改善点は以下の通りです。
- Make
VersionStorageInfoをポインタにすることで、バックグラウンドスレッドで解放できるようにしました。以前は、この構造体の解放がmutexをブロックし、SSTファイル数が多い場合にフォアグラウンドの書き込みをストールさせていました。 SaveToのfile_locationsの生成を、mutexの外にあるPrepareApplyに移動しました。
結果は以下の通りです。
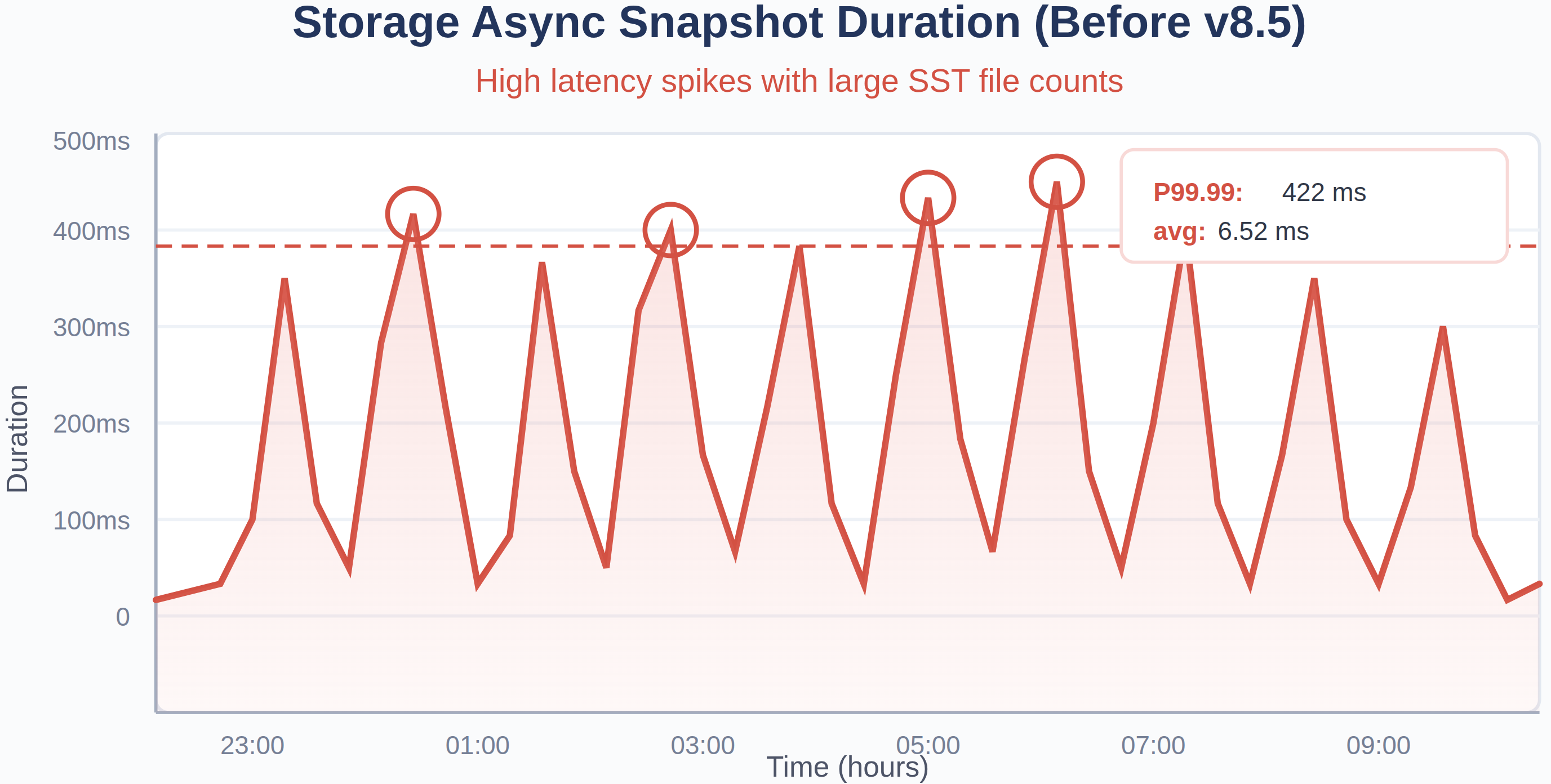
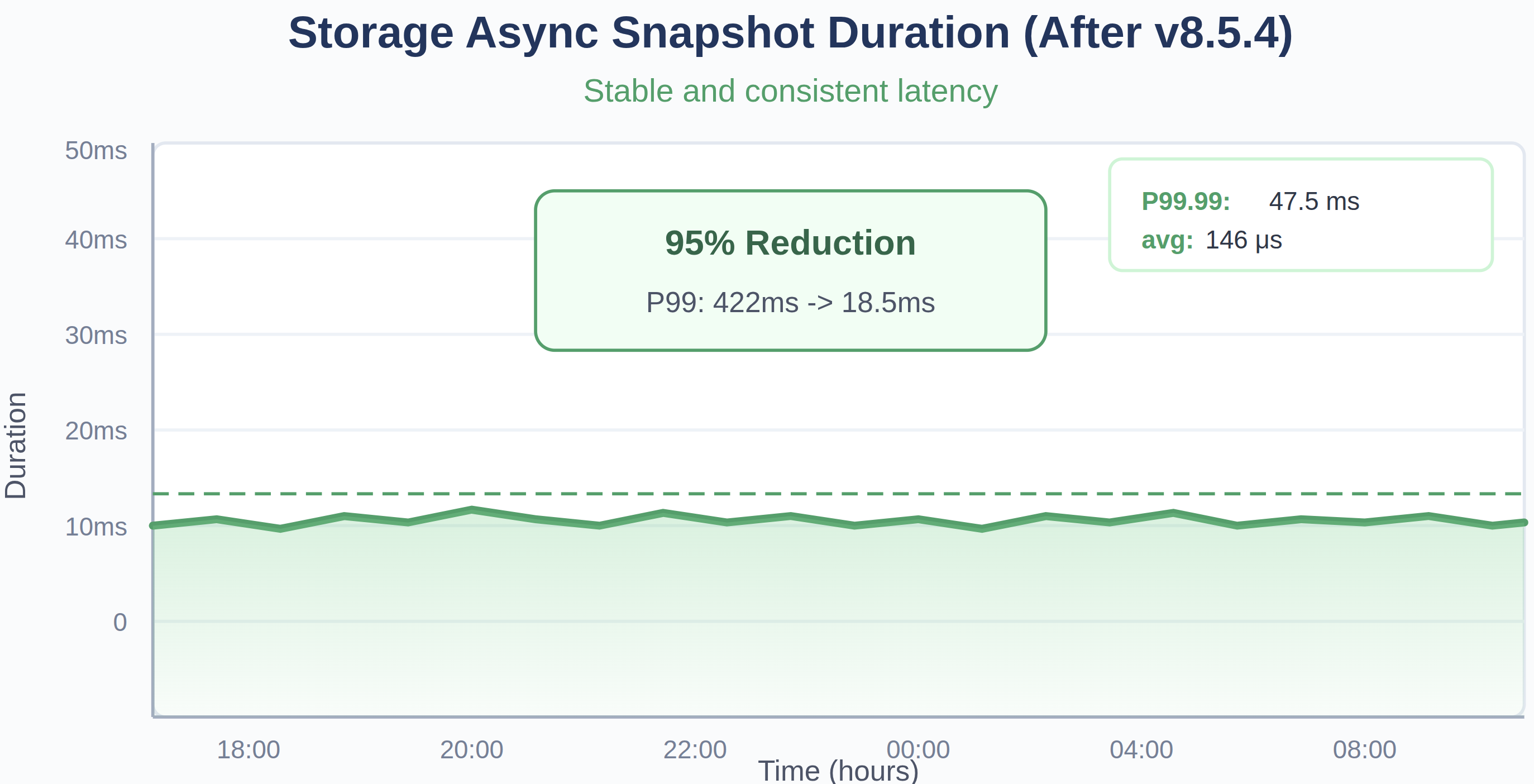
図8:TiDB 8.5.4へのアップグレード前後のストレージ非同期スナップショットの所要時間
TiDB 8.5におけるシステム全体の改善
改善点は段階的な微調整ではなく、パフォーマンスの変動の根本原因に対処する基本的なエンジニアリングの強化です。主な技術的改善点:
- TiDB層:メモリアロケーション / Goroutineの最適化、コプロセッサー / DistSQLワーカーの最適化、ART membuffer。追加の改善点については、リリースノートを参照してください。
- TiKV層:非同期スナップショットの最適化、書き込み停止なしのSSTインジェクション。追加の改善点については、リリースノートを参照してください。
TiDB v8.5は「一つの魔法のような機能」ではありません。これは、スタック全体にわたって一貫したパフォーマンス戦略を適用した結果です。さらに重要なことに、これらの最適化と改善はTiDB v8.5.4でデフォルトで有効になっており、大多数のOLTPシナリオでその恩恵を受けることができます。
次に、これらの改善が実際に機能していることを確認するために、本番データに目を向けます。
TiDB 8.5.4の本番環境での結果
あらゆる最適化の真の尺度は、本番環境におけるその影響です。これらの結果は、TiDB 8.5が実際の運用ワークロードの下で、分散データベースのP999レイテンシーをいかに削減できるかを示しています。3つのケースはいずれも、テールレイテンシーが取引の成功率やビジネス成果に直接影響を与える、ミッションクリティカルなオンライン取引サービスに供されています。
本番クラスタのプロファイル
これらの結果を理解するには、ワークロードを理解する必要があります。以下は3つの本番クラスタの概要です。
| ケース1 (150K QPS) | ケース2 (155K QPS) | ケース3 (31K QPS) | |
| 環境 | 20+ TiDB / TiKV / PD 32Cノード 24h本番メトリクス |
20+ TiDB / TiKV / PD 32Cノード 24h本番メトリクス |
10+ TiDB / TiKV / PD 32Cノード 24h本番メトリクス |
| ワークロードタイプ | 混合読み書き、オンライン取引プラットフォーム | 混合読み書き、オンラインSaaSサービス | 混合読み書き、ミッションクリティカルなオンラインサービス |
| 読み書き比率 | 両方重い — 毎秒数万行の変更または更新 | 両方重い — ケース1と同等の強度 | 中程度の負荷だが、同様にレイテンシーに敏感なアクセスパターン |
| TiKVストアあたりデータ量 | ~4 TiB | ~4 TiB | より小さいが無視できない量 |
| ノードあたりSSTファイル数 | ~200K | ~200K | より少ない |
| クラスタ規模 | 100+ TiKVノード、ストアあたり〜10Kリージョンピア | 100+ TiKVノード、ストアあたり〜10Kリージョンピア | より小規模なクラスタ |
| トランザクションパターン | 標準的なOLTPトランザクション | 大規模トランザクション (バッチあたり200K+ 行の非トランザクションDMLバッチ) | 標準的なOLTPトランザクション |
| レイテンシー感度 | 極めて重要 — 読み取りレイテンシーのスパイクは取引成功率に直接影響 | 極めて重要 — 同様のビジネスインパクト | 極めて重要 — 同様のビジネスインパクト |
ケース間で改善が異なる理由:ケース1とケース2は、すべての最適化が同時に機能している大規模、高QPSのクラスタです。ケース3はQPSが低くクラスタも小さいため、絶対的なレイテンシーの数値はすでに良好でしたが、相対的なスロークエリの削減率は最も劇的です。
P999レイテンシーの改善
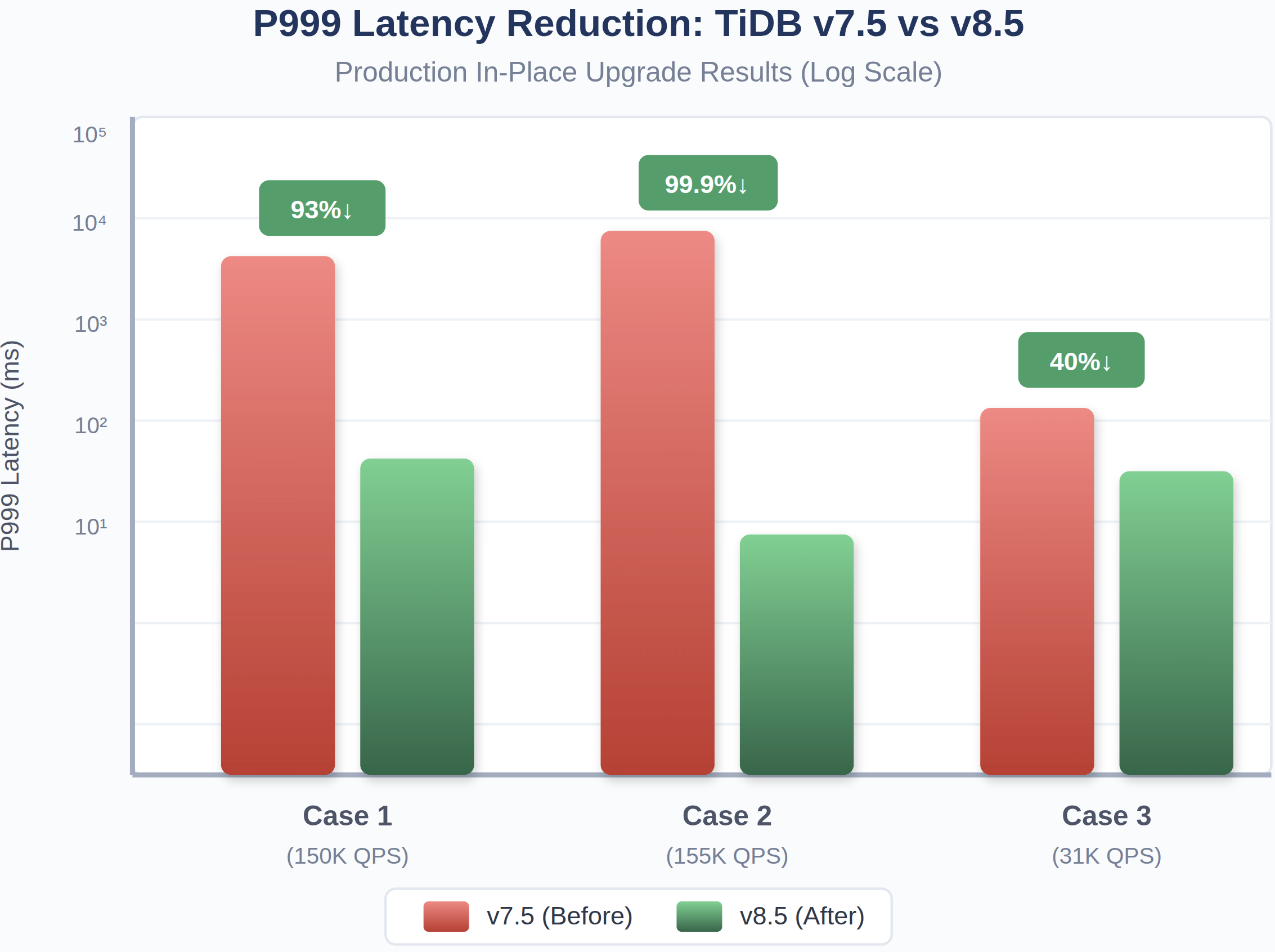
図9:v7.5からv8.5へのP999レイテンシーの削減
ある本番クラスタでは、P999が分単位のレベルから100ms未満に低下しました。
リソース効率の向上
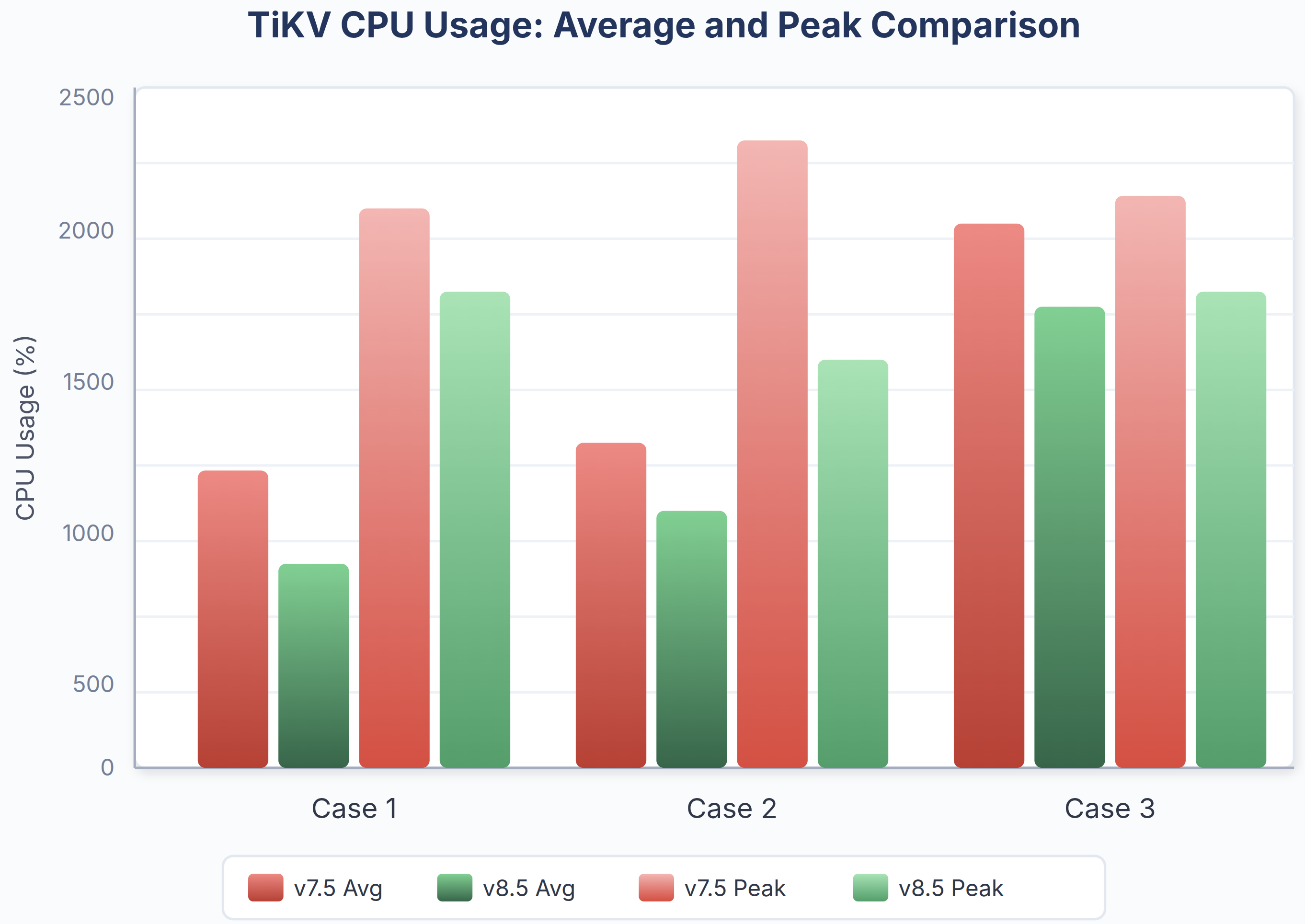
図10:v7.5とv8.5におけるTiKVの平均CPU使用率とピークCPU使用率の比較
スロークエリの排除
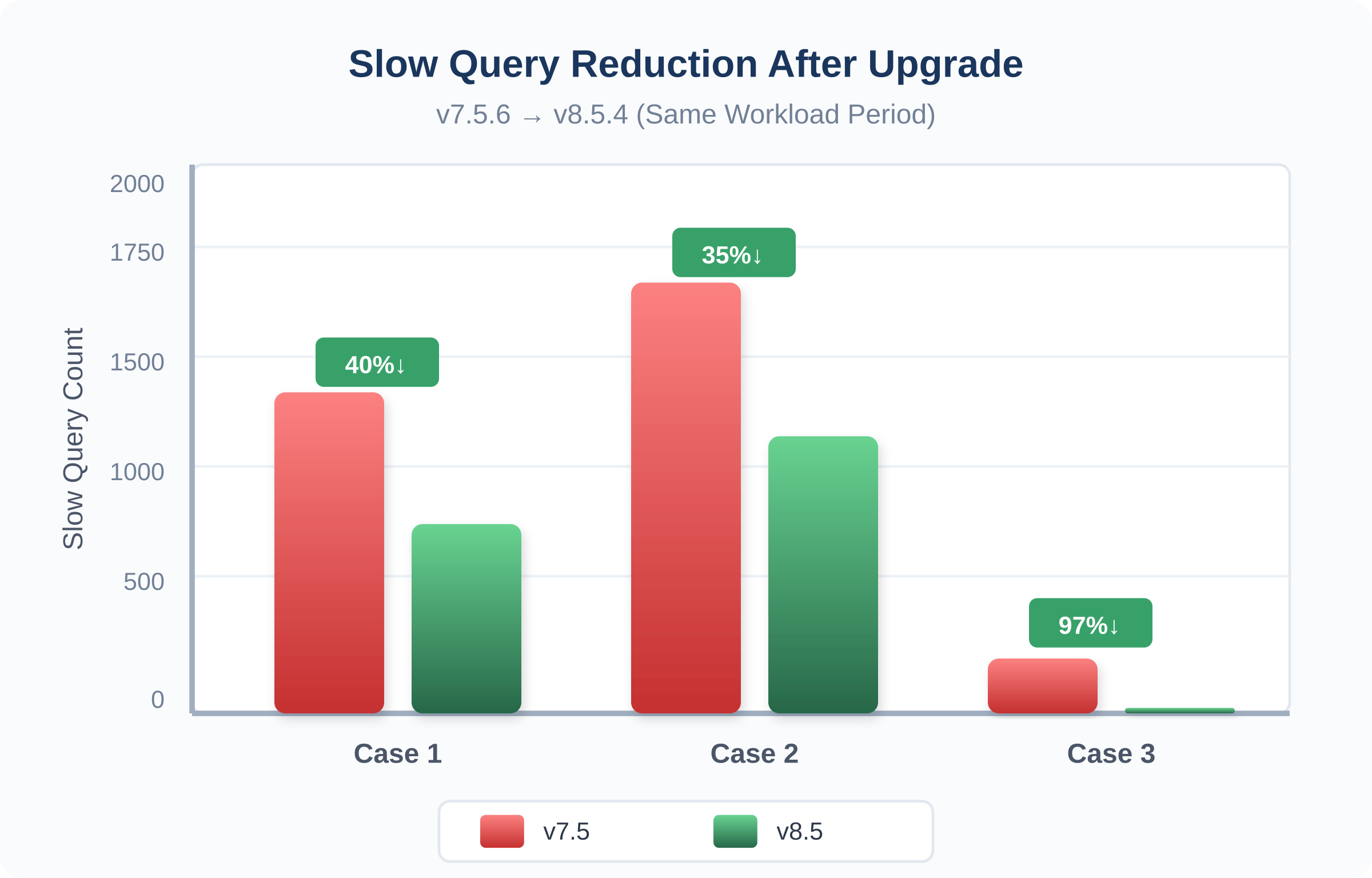
図11:3つのケースと2つのバージョンにわたるスロークエリの削減
90%以上のスロークエリ削減 (ケース3)。
DML操作のパフォーマンス
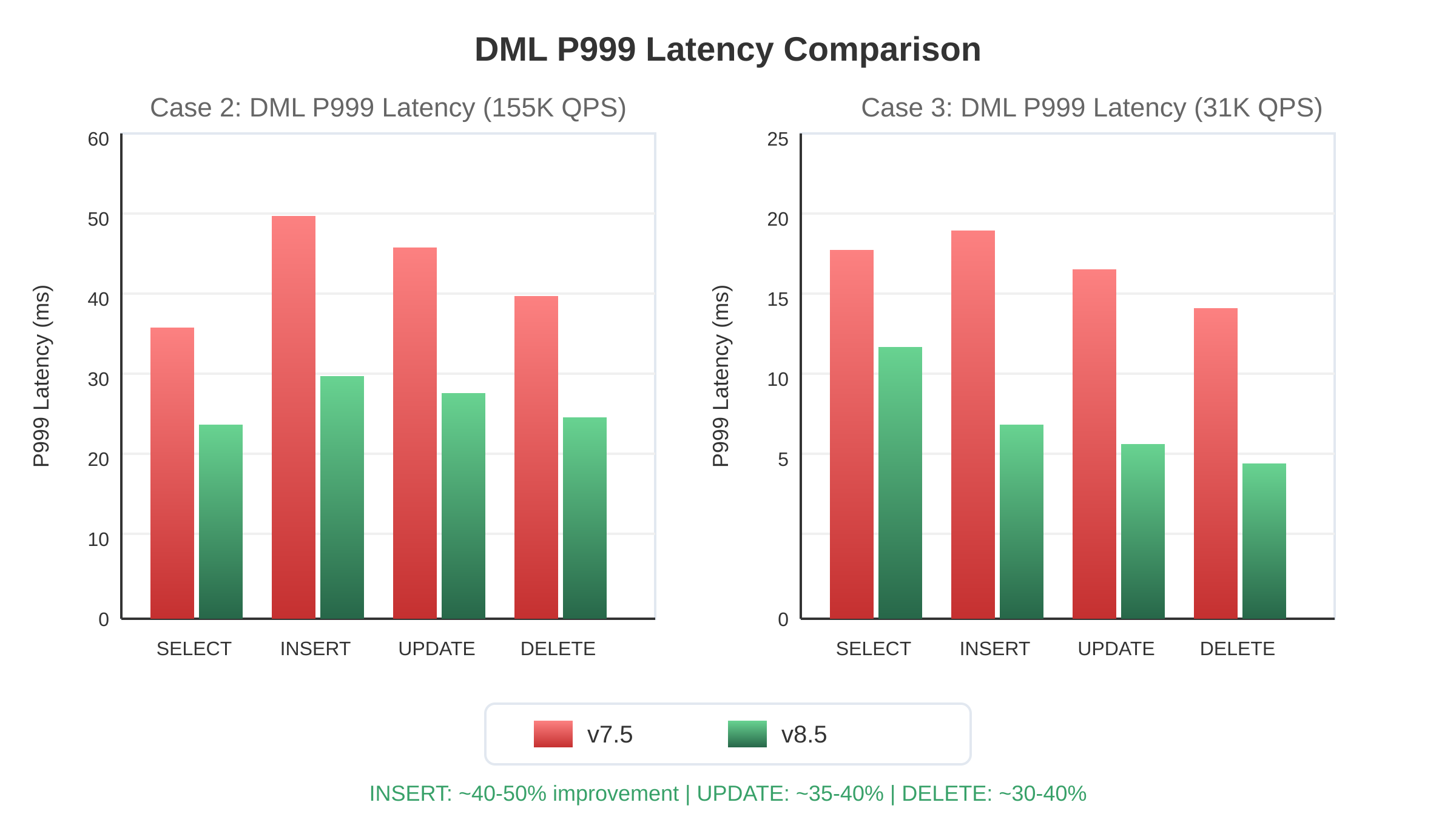
図12:両バージョンにわたるDML P999レイテンシーの比較
TiDB 8.5.5におけるテールレイテンシー改善の拡張
TiDB 8.5における改善は、リクエストの経路全体でのストールの排除とオーバーヘッドの削減によるレイテンシー分散の解消に焦点を当てています。
TiDB 8.5.5では、この基盤の上に構築します。分散削減の新しいソースを導入するのではなく、実行のローカリティ向上とネットワークラウンドトリップの削減を通じて、クリティカルパスをさらに短縮します。
これらの強化は、前述と同じ原則に従っています。主に削除 (不要な調整の排除) と並べ替え (データが存在する場所の近くへ作業を移動) です。

図13:プッシュダウン実行とデータローカリティを通じて、インデックスルックアップを2回のネットワークラウンドトリップから1回に短縮
インデックスルックアップのプッシュダウン
インデックスとテーブルデータが同じ場所に配置されている場合、インデックスルックアップを2つではなく1つのCoprocessor RPCで実行できるようになりました。
これにより、クリティカルパスからネットワークラウンドトリップが丸ごと1回削除され、ルックアップの多いクエリにおいてレイテンシーと調整オーバーヘッドの両方が削減されます。
データアフィニティスケジューリング
データアフィニティスケジューリングにより、テーブル行とそれに対応するインデックスエントリ、またはパーティションレベルのワーキングセットなどの関連データが、同じTiKVノード内に配置される可能性が高まります。
これによりプッシュダウンのヒット率が向上し、より多くのクエリがより少ない調整ステップで実行できるようになり、負荷のかかっている状態でのレイテンシーがさらに削減されます。
影響
適切なワークロードにおいて、これらの最適化はTiDB 8.5で得られた成果に加えて、さらなる改善を提供します。内部テストの結果は以下の通りです。
- テールレイテンシーをさらに最大20~30%削減
- TPMCベンチマークで最大20%の向上
今すぐTiDB 8.5を試して、今後のTiDB 8.5.5の強化により、OLTPパフォーマンスをどこまで高められるかを確認してください。
Related Resources

Conference
May 19, 2026
TiDB SCaiLE Europe 2026: Why Engineers Building Agentic AI Should Be in Stockholm on 4 June

Conference
May 12, 2026
TiDB SCaiLE Europe 2026: Speaker Lineup and Session Preview

Product
May 11, 2026
From Preview to Production: TiDB Cloud Dedicated on Microsoft Azure is Now Generally Available
TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。