


※このブログは2025年10月27日に公開された英語ブログ「How to Replicate TiDB to a Mirrored Database in Microsoft Fabric with TiCDC」の拙訳です。
TiDBは、クラウドネイティブ、データ集約型、およびAI駆動型アプリケーション向けに構築されたオープンソースの分散型SQLデータベースです。MySQLと互換性があり、水平スケーラビリティ、強力な一貫性、および高可用性を特徴としています。Open MirroringのためのTiCDCレプリケーションソリューションを活用することで、TiDBは Microsoft Fabricとシームレスに統合されます。これにより、あらゆるTiDBデプロイメント環境から Microsoft Fabric OneLakeへの継続的なリアルタイムデータ同期が可能となり、AIおよび分析のためにデータが即座に利用可能になります。
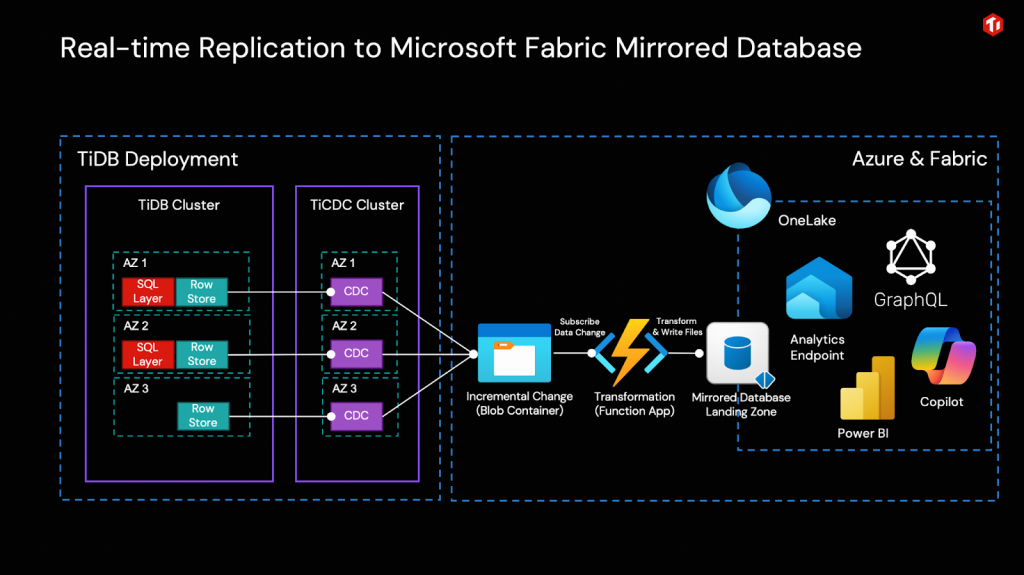
Open Mirroringは、データ処理関連のISV (独立系ソフトウェアベンダー) や顧客が、オープンなDelta Lakeテーブルフォーマットに基づいて Microsoft FabricのMirroring機能を拡張できるように設計されています。この機能により、TiDBはオープンなMirroringパブリックAPIに基づいて、変更データをMicrosoft Fabric内のMirrored Databaseに直接書き込むことが可能になります。Microsoft FabricのOpen Mirroringの詳細については、Open Mirroring in Microsoft Fabricをご覧ください。
このブログでは、このオープンソースの統合ソリューションの実装について詳しく説明し、各コンポーネントの設定方法を実施することで、詳細なステップバイステップの手順を紹介します。
前提条件
- TiDBクラスタのデプロイパターン (TiDB CloudまたはTiDB Self-Managed) や、デプロイ場所 (パブリッククラウド上またはオンプレミス) に関わらず、接続するためのTiCDCクラスタをデプロイしてください。あるいは、評価目的でTiDB Labsが提供するサンドボックス環境を利用することも可能です。
- Fabricサブスクリプションを持つMicrosoft Azureアカウントと、Azureサービス (特にEntra ID、Storage service Blobs) コンテナー、Function App、Event Grid) に関する基礎知識が必要です。
- PythonおよびPython仮想環境の基本的な使用方法。
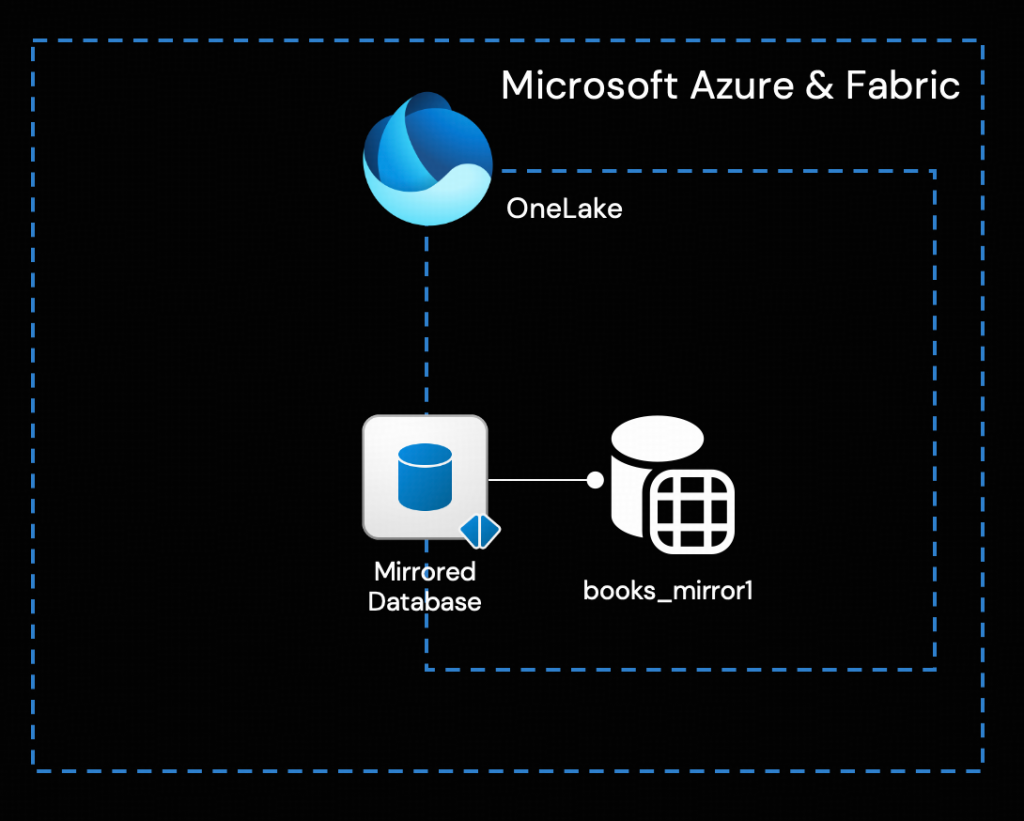
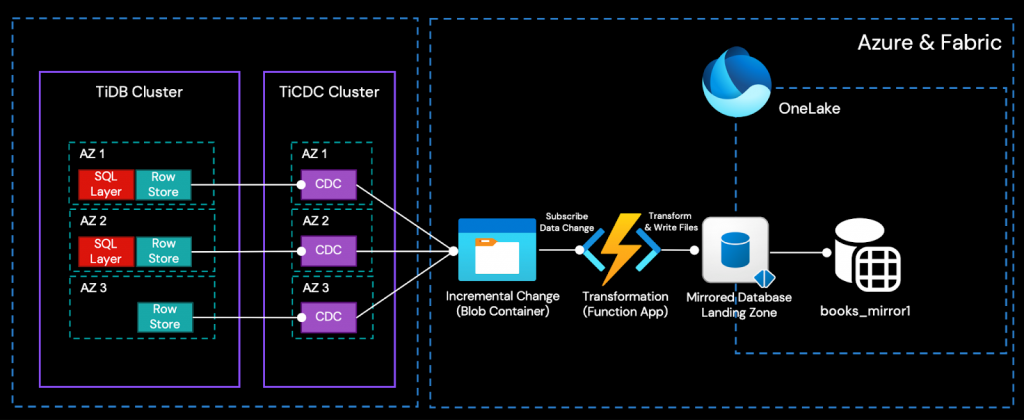
アーキテクチャ概要
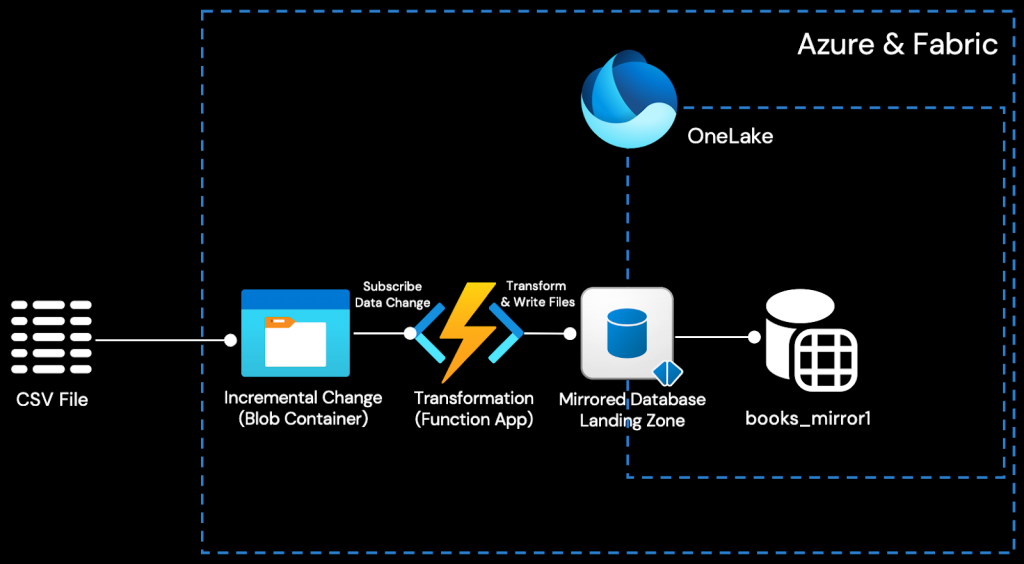
簡単に言えば、TiCDCクラスタは、TiDBクラスタによって生成された増分データ変更をCSVファイルとしてリアルタイムで捕捉し、Azure Object Storage (Blob) に書き込みます。Azure Function AppがEvent Gridを介してBlobからの変更イベントをサブスクライブすることで、オープンなMirroring APIを呼び出し、増分データをFabric Mirrored Databaseにリアルタイムで書き込み、OneLakeに統合できます。
このように、唯一のデータ変換は、TiCDCの出力をOneLakeの取り込み形式にリアルタイムで変換するためにAzure Functionによって実行されます。その後、Fabricに組み込まれたビジネスインテリジェンス、人工知能、データサイエンスのためのツールを直接使用できます。
このソリューションのアーキテクチャを理解するために、このセクションでは主要コンポーネントの概要を説明します。構築の準備が整ったら、「テーブルレプリケーションのステップバイステップの例:TiDBからMicrosoft Fabricへ」セクションの詳細な手順に従ってください。
TiCDCクラスタ
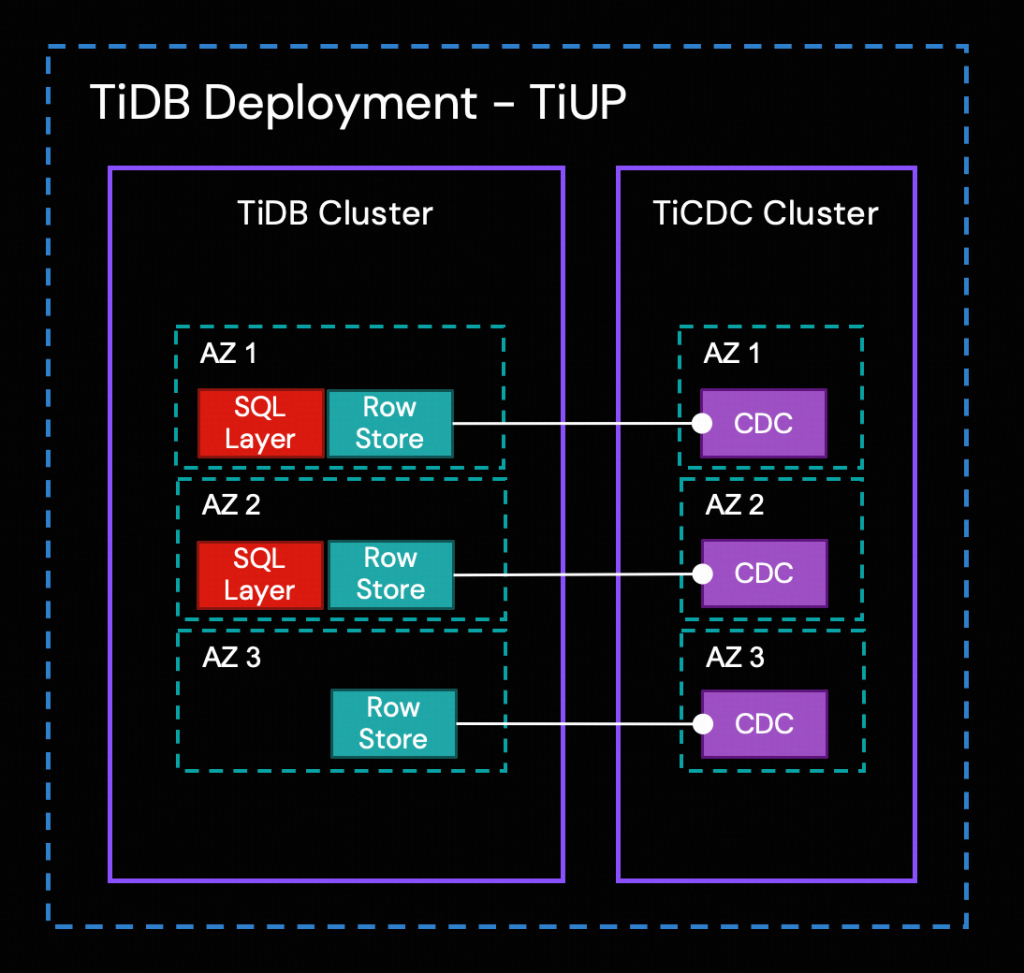
TiCDCは、TiDBからトランザクション単位の増分データを捕捉し、捕捉したデータをソート し、行ベースの増分データをダウンストリームのシンク (出力先) へエクスポートするために使用されるツールです。TiDBと同様に、TiCDCクラスタは高可用性デプロイメントをサポートしています。本番環境では、マルチノード、クロスAZ (アベイラビリティゾーンをまたいだ) トポロジーが一般的です。
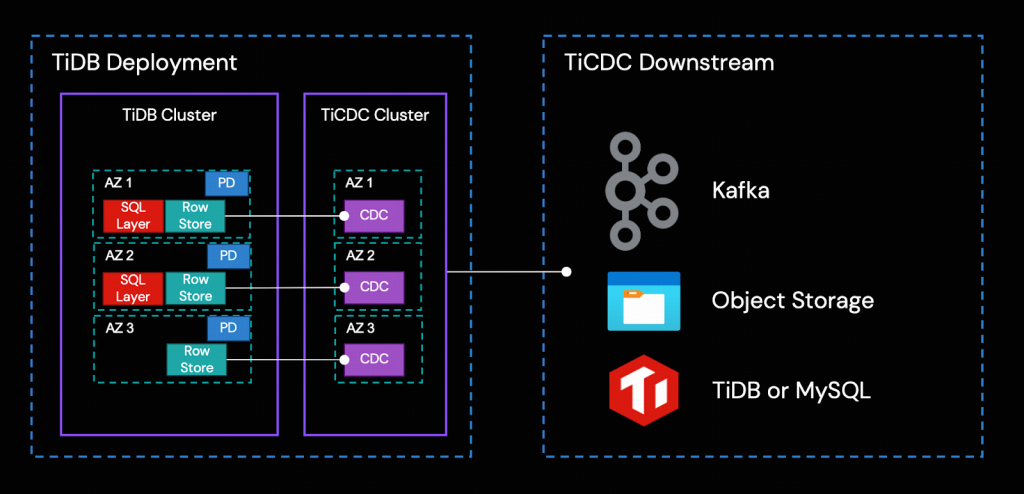
TiCDCの高可用性は、TiDBのPlacement Driver (PD) によって実現されます。レプリケーションプロセスは以下のステップで構成されています。
- 複数のTiCDCプロセスが、Row Storageノードからデータ変更を取得します。
- TiCDCがデータ変更をソートし、マージします。
- TiCDCがレプリケーションタスク (Changefeed) を通じて、データ変更をダウンストリームシステムに複製します。
捕捉されたすべての変更について、TiCDCは「少なくとも一度」出力します。TiDBのRow StorageまたはTiCDCクラスタで障害が発生した場合、TiCDCは同じ増分変更を繰り返し送信する可能性があります。
Azure Blob Containerオブジェクトストレージは、この統合ソリューションにおけるTiCDCのダウンストリームとなります。
Azure Blobコンテナー、Function App、およびEvent Grid
Blobコンテナーに変更データが到着すると、Event Gridを介してAzure Function Appが起動されます。その関数内で、以下の2つの主要なタスクが実行されます。
- TiCDCイベントのペイロードを、OneLakeのMirrored Databaseによって指定された受け入れ可能なフォーマットに変換します。
- 変換された変更データを、Mirrored DatabaseのLanding Zoneに取り込みます。
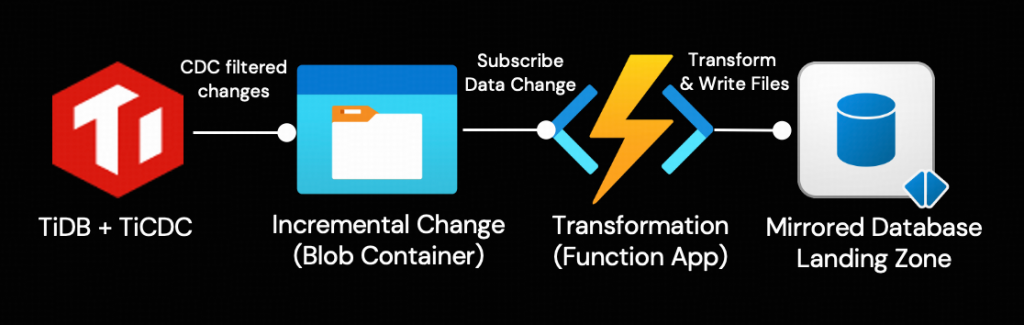
Mirrored DatabaseのLanding Zone
すべてのMirrored Databaseには、OneLake内にメタデータおよびデルタテーブル用の固有のストレージ場所があります。Open Mirroringは、Function Appがメタデータファイルを作成し、増分データをOneLakeにプッシュできるようにするためのランディングゾーンフォルダを提供します。ミラーリング機能は、このランディングゾーン内のファイルを監視し、新しく追加されたテーブルやデータを読み取ります。
データがMirrored Databaseに取り込まれると、Open Mirroringは複雑なデータ変更の処理を簡素化し、すべてのミラーリングされたデータが継続的に最新の状態に保たれ、分析に利用できる状態であることを保証します。
Mirrored Databaseのランディングゾーンを用いたワークフローを効率化するために、当社のソリューションは、必要なFabric Mirroring APIとのすべての相互作用を管理するPythonユーティリティを提供しており、ランディングゾーンの要件とファイル形式への準拠を確実にします。
Pythonユーティリティ
このオープンソース統合を簡素化するために、私たちは2つのヘルパーPythonスクリプトを提供しています。
- 管理者ツールテンプレート:レプリケーション管理者を対象として設計されており、Mirrored Database内のテーブルを管理するためのハイレベルなAPIインターフェースを提供します。私たちは、TiCDCのCSVファイル形式との互換性を確保するために、オリジナルのMicrosoftバージョンに手を加えました。
- Azure関数テンプレート:これは、スターターテンプレートとして提供される、Azure Function App用の部分的に完成されたコアスクリプトです。これを直接ご自身のAzure関数に組み込み、特定のビジネスロジックに合わせてカスタマイズできます。
これら両ツールの詳細な使用方法については、以下のステップバイステップガイドで提供されます。
テーブルレプリケーションのステップバイステップ例:TiDBからMicrosoft Fabricへ
注記
- この例では、既存の環境からの明確な分離を確実にするため、このサンプルワークロード専用の新しいリソースグループとストレージアカウントを作成します。これが唯一の方法ではありませんが、権限の分離を強制する最も簡単な方法です。
- この詳細な例で使用するTiDBのバージョンはTiDB 8.5.1です。
ステップ1. Microsoft FabricでMirrored Databaseを作成する
Microsoft FabricのMirrored Databaseは、一般公開されているRest APIを使用するか、またはMicrosoft Fabricポータルを通じて作成できます。このブログでは、Microsoft Fabricポータル経由の手順を案内します。
- Microsoft Fabricポータルにサインインします。
- 新しいワークスペースを作成します。この例では、ワークスペース名をintegration-demoとします。
- ワークスペース内で、「+ New item」をクリックし、Mirrored databaseアイテムを選択します。
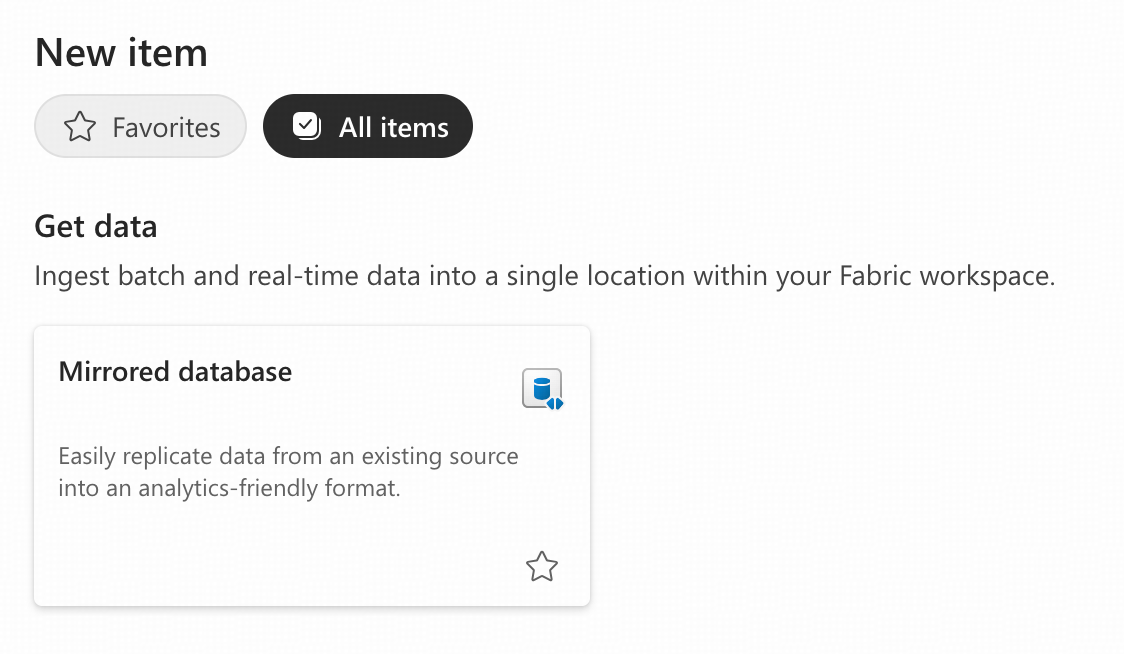
- 名前を付けます。この例では、Mirrored Databaseの名前をbs_mirror1とします。「Create」をクリックし、作成が完了するまでこの画面から移動しないでください。

- Mirrored Databaseが作成され、レプリケーションが自動的に開始された後、この画面が表示されます。Landing Zone URLをコピーして、今後のために保存しておく必要があります。以降の手順では、このLanding Zone URLを<landing_zone_url>というプレースホルダーで表記します。
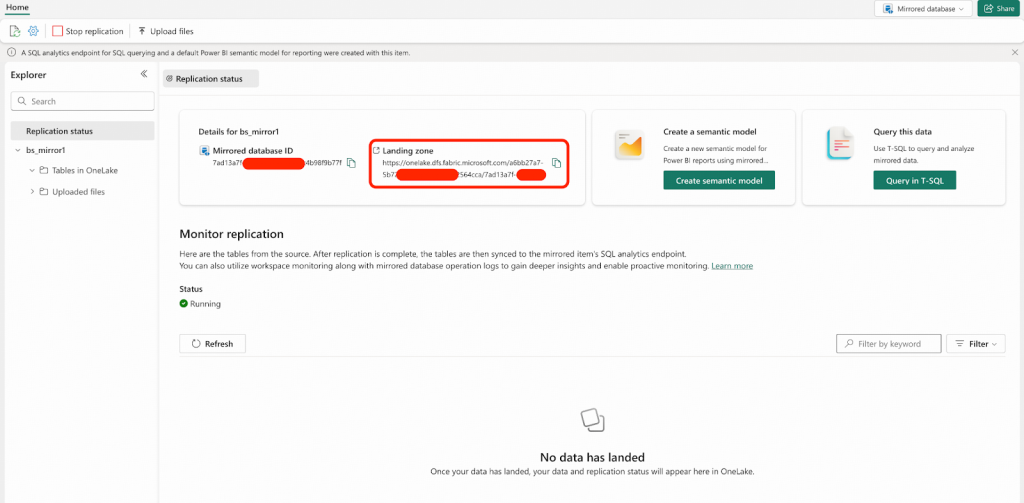
Microsoft Fabricで空のMirrored Databaseを作成しましたが、デフォルトでは既にレプリケーションが開始されています。あなたのデータベースは、データファイルが Landing Zoneに取り込まれるのを待機している状態です。
ステップ2. 複製ワークロード用の専用Azureリソースグループを作成する
このステップは任意ですが、推奨されます。複数のAzureリソースを作成するため、それらを単一のリソースグループに配置することで、IAM (Identity and Access Management:IDおよびアクセス管理) の権限制御が簡素化されます。このアプローチは、サンプルワークロードのアクセスを既存の環境から分離することで、セキュリティのベストプラクティスを順守します。
- Microsoft Azure Portalにサインインします。
- Resource groupsに移動します。bgl-pilot-rgという名前の新しいリソースグループを作成します。また、そのリソースグループにサブスクリプションとリージョンを割り当てる必要があります。この例では、TiDBクラスタが米国オレゴン州にデプロイされているため、以降作成するすべての新しいリソースについて、可能な限り (US) West US 2を選択します。
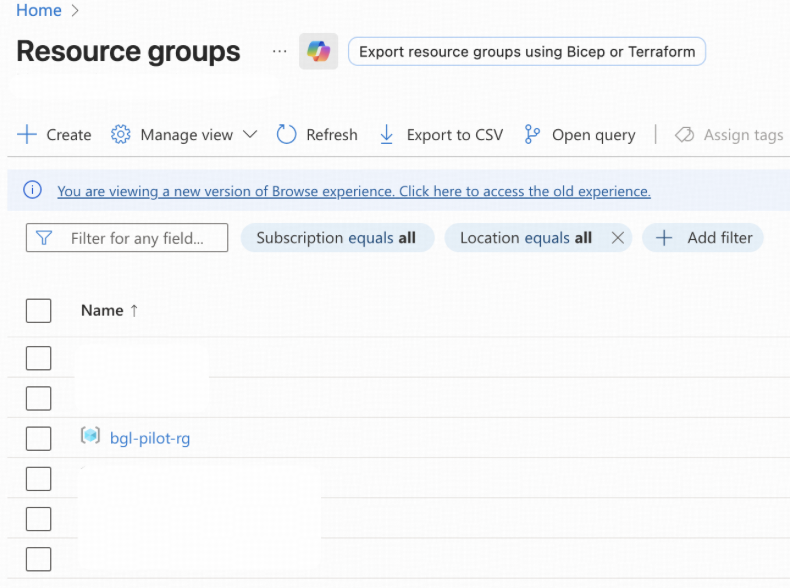
- 他のステップで作成される新しいAzureリソースはすべて、リソースグループbgl-pilot-rgに配置されます。
ステップ3. TiCDCシンク先用の新しいストレージアカウントとBlobコンテナーを作成する
TiCDCは、TiDBのRow Storageから変更データを捕捉し、それをリアルタイムでAzure Blob Storageコンテナーに供給することでデータを複製します。このBlobコンテナーは、後続の処理のために増分トランザクションデータをキャッシュする、中間的なステージング領域として機能します。
- Microsoft Azure Portalにサインインします。
- Storage accountsに移動します。新しいストレージアカウントを作成し、リソースグループbgl-pilot-rgに配置する必要があります。作成したストレージアカウント名を控えてください。以降の手順では、お客様のストレージアカウント名を表すために、プレースホルダー<storage_account_name>を使用します。
- 作成したストレージアカウント内で、この例のためにtidb-demo-cdcという名前の新しいBlobコンテナーを作成します。
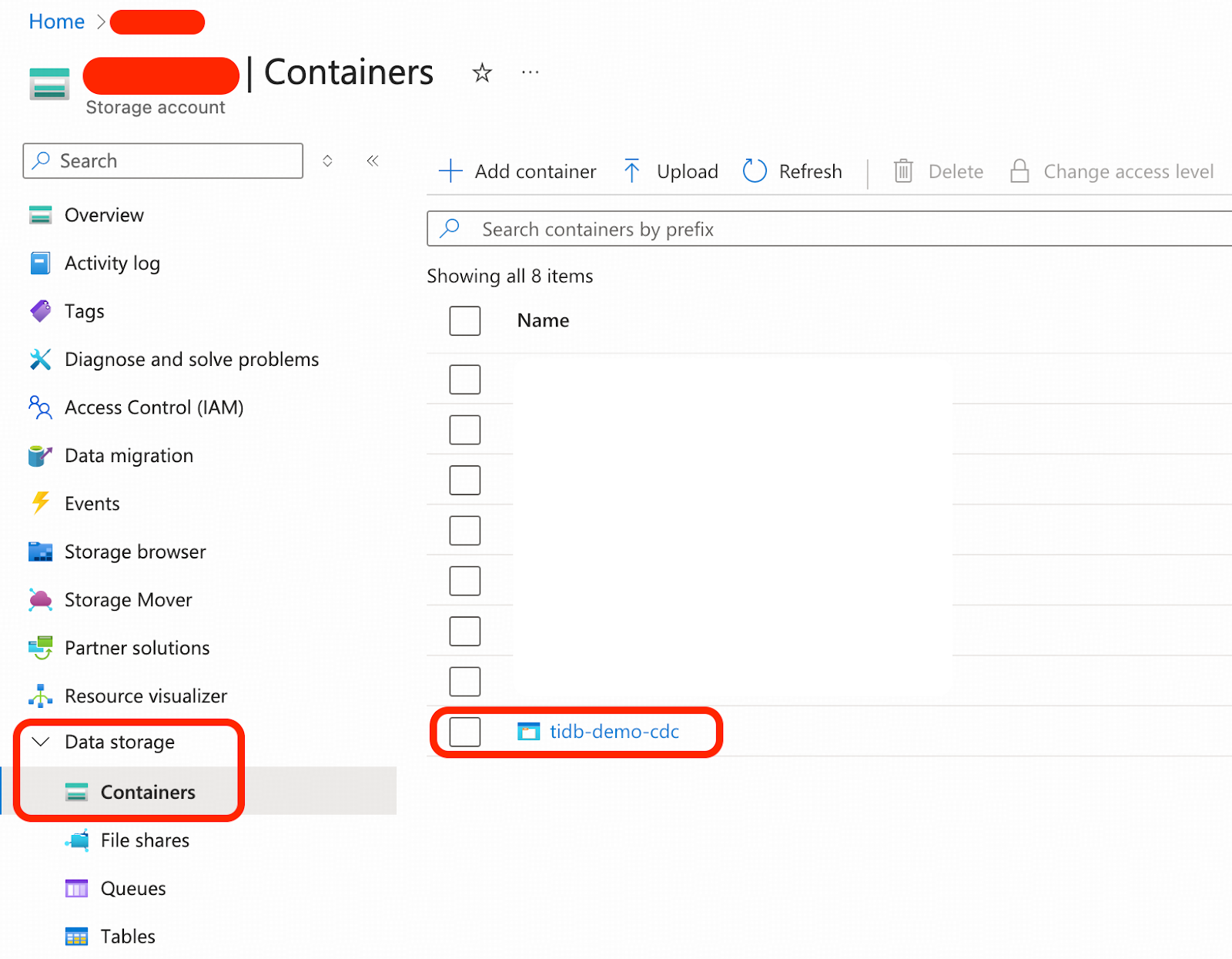
ステップ4. レプリケーションワークロード用にMicrosoft Entra IDを準備する
レプリケーションワークロードは、Azure Data LakeおよびAzure内のその他の必要なリソースへのアクセス許可を必要とします。このステップでは、レプリケーションワークロードの認証のために、まず登録アプリケーションを作成します。
- Microsoft Azure Portalにサインインします。
- App registrationsに移動します。「+ New registration」をクリックし、その他の設定はすべて既定値のままにして「Create」をクリックします。この例では、fabric-appという名前を付けます。
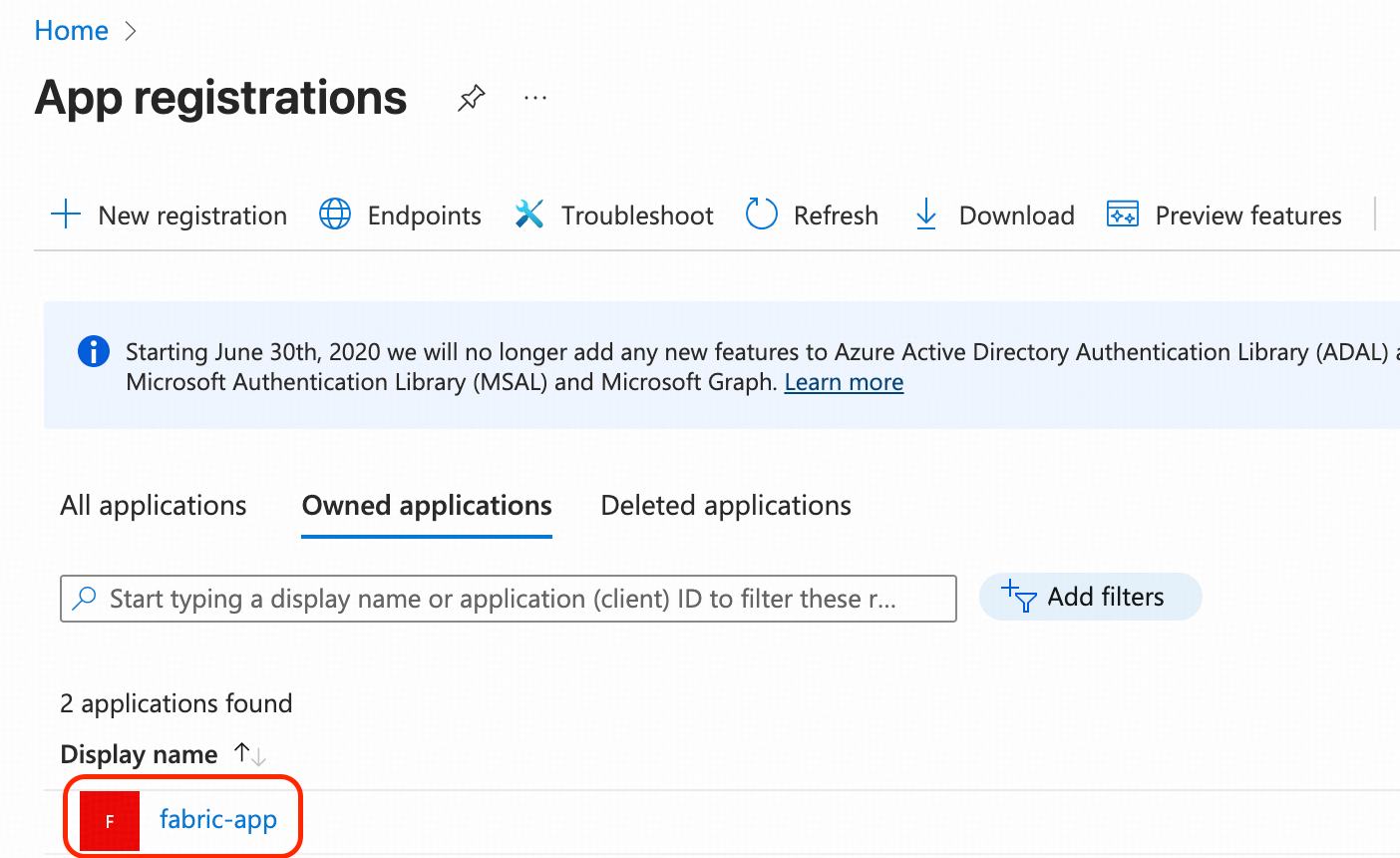
- fabric-appをクリックし、その概要ページに移動します。その後、以下の3つのタスクを完了します。
- アプリケーション (クライアント) IDを控えておきます。以降のステップでは、これを<fabric_app_client_id>と表記します。
- ディレクトリ (テナント) IDを控えておきます。以降のステップでは、これを<fabric_app_client_tenant>と表記します。
- クライアント資格情報 (Client credentials) のためのクライアントシークレットを生成し、そのシークレット値を控えておきます。以降のステップでは、これを<fabric_app_client_secret>と表記します。
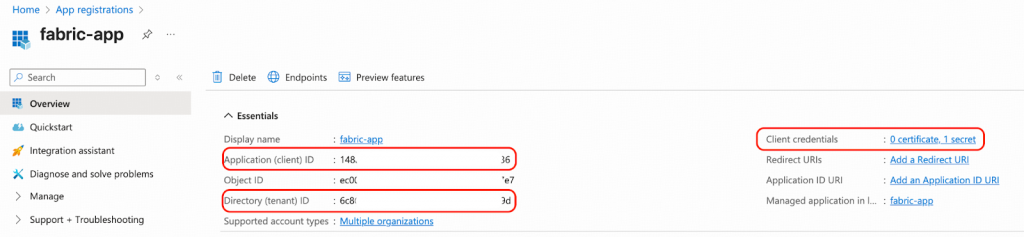
登録アプリケーションfabric-appをEntra IDグループに追加します。この例でのグループ名はsa-general-python-app-test-groupです。
- Microsoft Entra IDに移動します。
- グループを作成し、fabric-appをそのメンバーとして割り当てます。
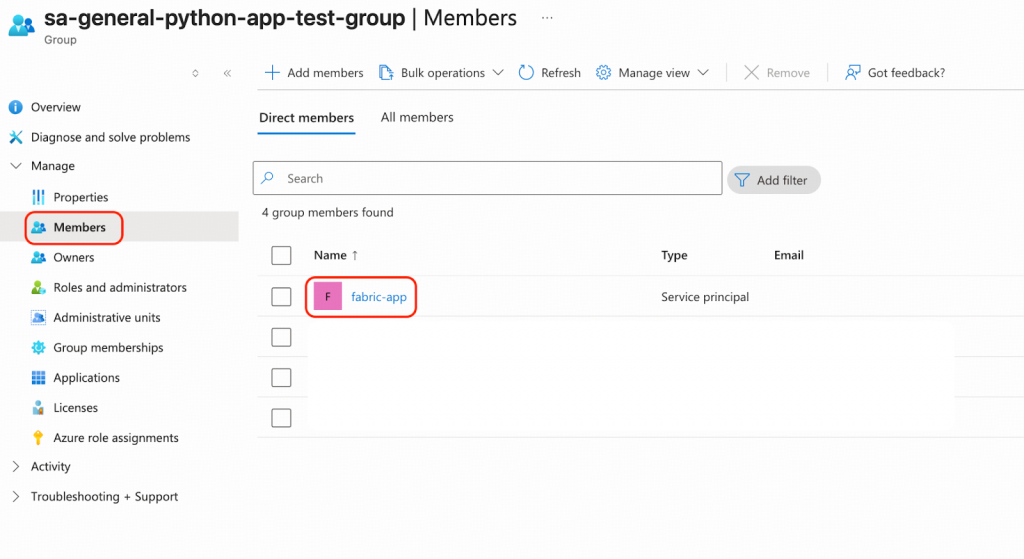
レプリケーションワークロードの認可のために、登録アプリケーションfabric-appに必要なアクセス許可を付与します。
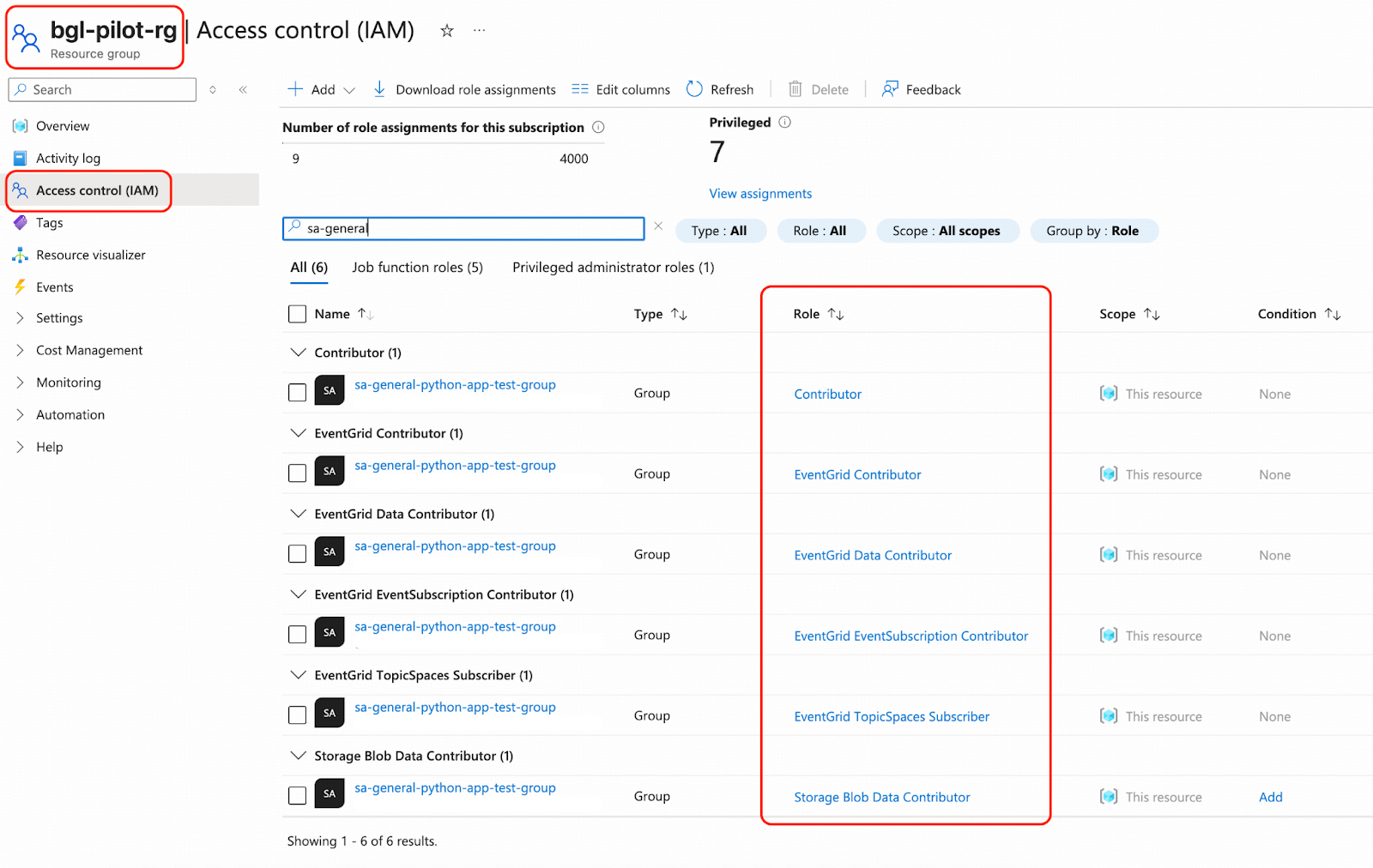
- Azureポータルからsa-general-python-app-test-groupにアクセス許可を付与します。リソースグループに移動しbgl-pilot-rgをクリックし、アクセス制御 (IAM) をクリックします。「+ Add」をクリックし、続いて「Add role assignment」をクリックします。以下のロールが推奨されます。
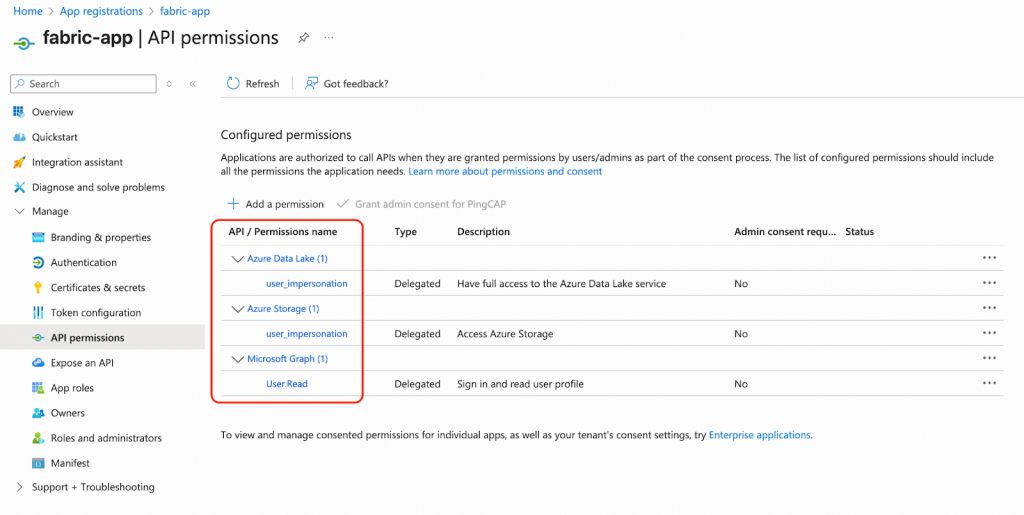
- Azureポータルからfabric-appにアクセス許可を付与します。App registratoionsに移動し、API permissionsの下にあるfabric-appをクリックします。以下のアクセス許可が推奨されます。
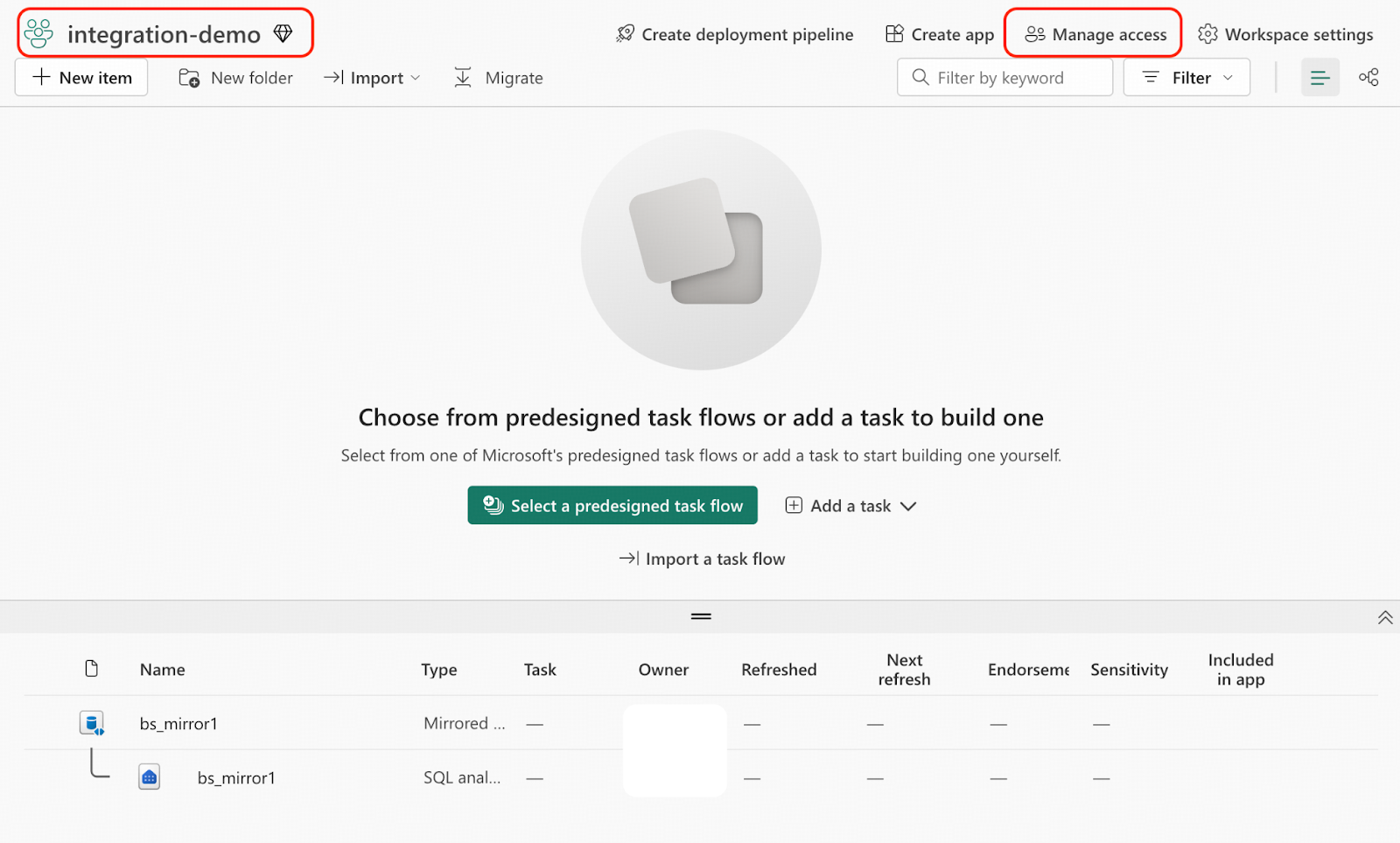
- 次に、Microsoft Fabricポータルにサインインします。
- ワークスペースintegration-demoに移動し、Manage accessをクリックします。
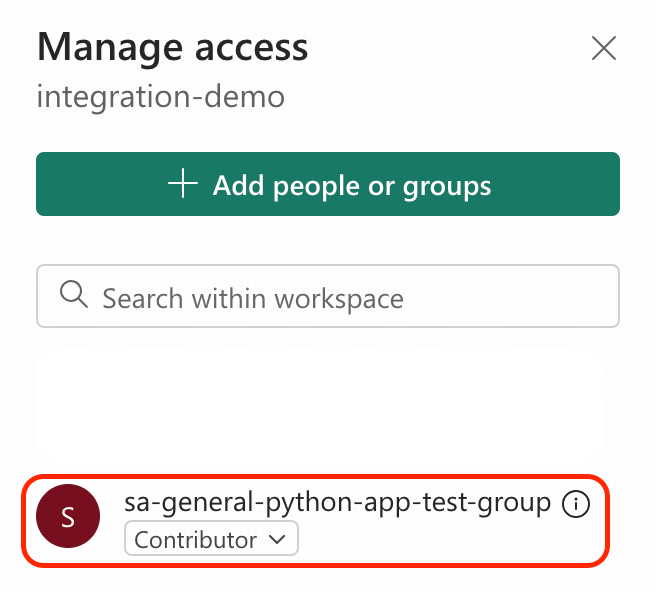
- sa-general-python-app-test-groupにContributorのアクセス許可を付与します。
ステップ5. ミラーリングされたデータベースにテーブルを作成する
この例では、bookテーブルをTiDBからFabric OneLakeへリアルタイムでレプリケートします。
Mirrored Database内にミラーリングされたデルタテーブルを作成する必要があります。以下のタスクは、Python 3.11を設定したPython仮想環境内で実行することが推奨されます。
- Mirrored Databaseを管理するためのハイレベルなAPIを提供する、Python管理者ツールテンプレートをダウンロードします。このウォークスルーでは、booksテーブル用の事前定義されたメタデータが含まれている、ソリューションバージョンの管理者ツールテンプレートをダウンロードします。
wget https://raw.githubusercontent.com/pingcap-inc/tidb-course-labs/refs/heads/main/solution/microsoft-fabric-mirrored-database/openmirroring_admin_solution.py
wget https://raw.githubusercontent.com/pingcap-inc/tidb-course-labs/refs/heads/main/solution/microsoft-fabric-mirrored-database/requirements.txt- Pythonスクリプトopenmirroring_admin_solution.pyの430行目付近を修正し、以下のプレースホルダーを、ステップ1およびステップ4でコピーした実際の値に置き換えてください。

- Python仮想環境に必要な依存関係をインストールします。
pip install -r requirements.txt - Mirrored Database内に、空のテーブルbooks_mirror1を作成します。
python openmirroring_admin_solution.py --create-table --table-name books_mirror1 - Microsoft Fabricポータルにサインインします。
- ワークスペースintegration-demoに移動し、bs_mirror1 Mirrored Databaseを開いて、「Uploaded files」セクションを展開します。_metadata.jsonファイルが存在することを確認してください。OneLakeはこのメタデータを使用して、非同期的にDelta Tableを作成します。
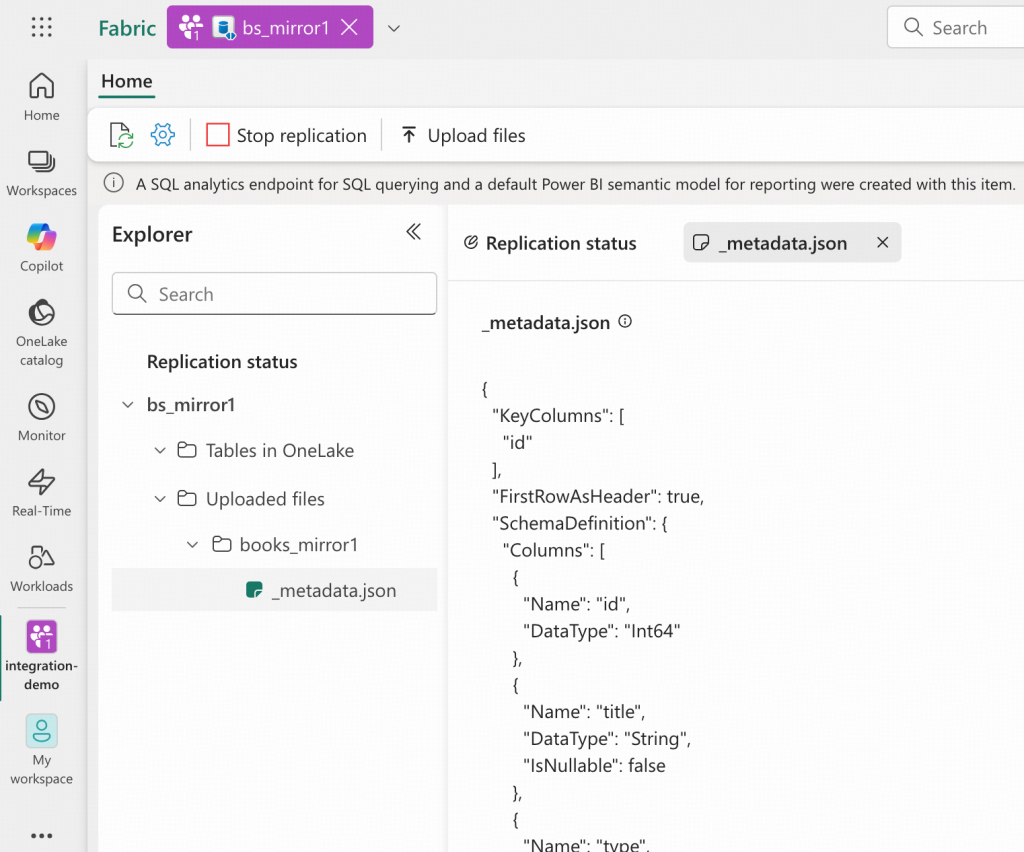
これで、booksテーブルの定義がMirrored Database内にbooks_mirror1として配置されたため、予期された構造を持つデータがLanding Zoneにアップロードされると、OneLakeへ自動的にインポートされます。このテーブル定義は、openmirroring_admin_solution.py内の変数target_table_metadataによって定義されています。実際のシナリオでは、このように独自のメタデータを追加したり、必要に応じて外部化したりすることができます。
ステップ6. 変更フィードリスナーとしてイベントトリガーを展開する
このステップでは、Blobコンテナーtidb-demo-cdcとMirrored Database bs_mirror1のLanding Zoneとの間にChangefeedリスナーを作成します。これは、Azure Event Grid上にデプロイされたAzure Function Appを実装することで実現されます。
以下の情報を念頭に置きながら、このチュートリアルに従ってイベント駆動型のAzure Function Appを開発およびデプロイしてください。
- Azure Function Appの名前はtable-books-cdc-triggerとする必要があります。
- Blobコンテナーのパスはtidb-demo-cdcです。
- すべてのリソースは、リソースグループbgl-pilot-rgの下に作成してください。
- TiCDCは変更データをCSVファイルとしてアップロードします。トリガーを設定する際は、そのフィルタリングルールが.csv拡張子を持つファイルをターゲットとするようにしてください。この例での、アップロードされる変更データBlobのフルパスはtidb-demo-cdc/<tidb-cluster-name>/bookshop/books/<start-tso-sequence>/<yyyy-mm-dd>/CDCnnnnnnnnnnnnnnnnnnnn.csvのようになります。
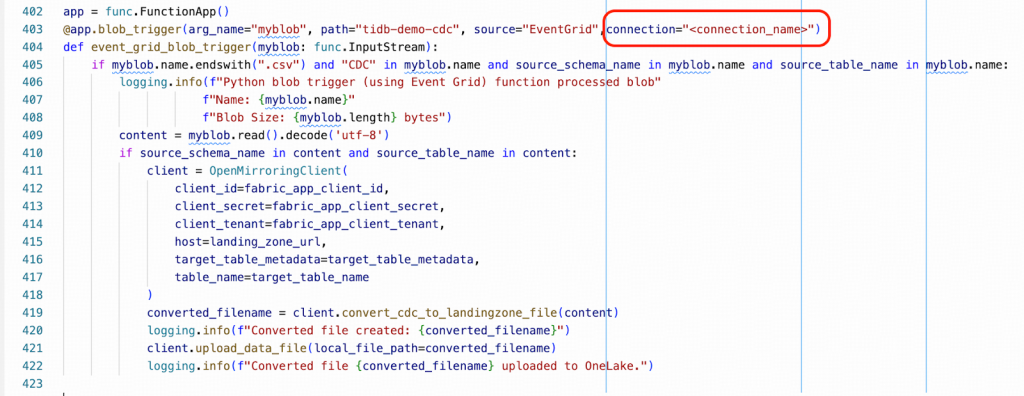
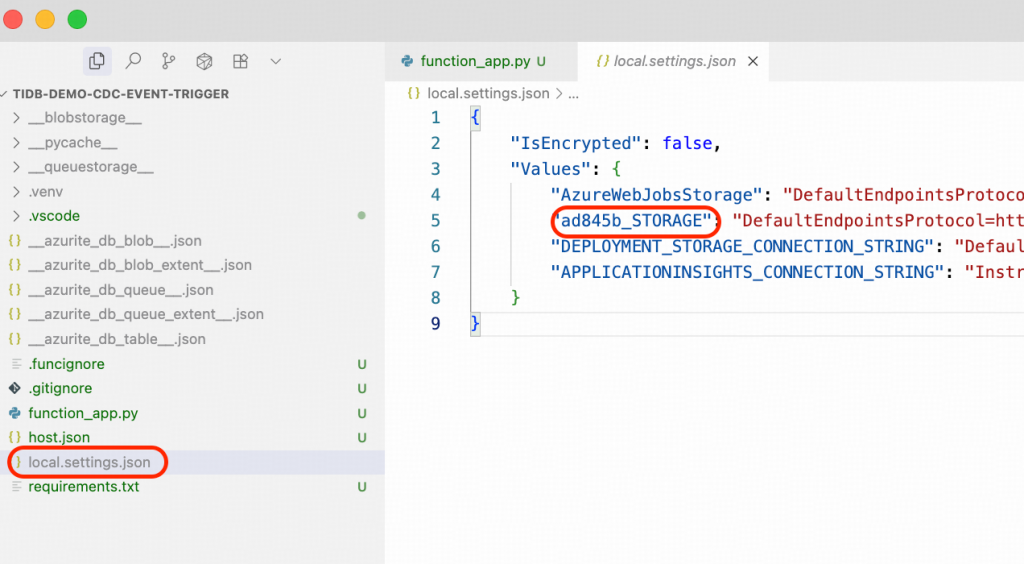
- Pythonスクリプトfunction_app.pyでは、トリガーの関数名はevent_grid_blob_triggerとする必要があります。例えば、VS Codeエディターでは以下のように表示されます。

すべてのステップを完了したら、作成されたfunction_app.py Pythonスクリプトをダウンロードし、VS Codeワークスペース内のものと置き換えてください。
- booksテーブルの変更データを抽出し、Landing Zoneにアップロードする機能を備えた、Python Azure Functionテンプレートとrequirements.txtをダウンロードします。
wget https://raw.githubusercontent.com/pingcap-inc/tidb-course-labs/refs/heads/main/solution/microsoft-fabric-mirrored-database/function_app.pywget https://raw.githubusercontent.com/pingcap-inc/tidb-course-labs/refs/heads/main/solution/microsoft-fabric-mirrored-database/requirements.txt- VS Codeワークスペースにあるfunction_app.pyとrequirements.txtを、ダウンロードしたファイルで置き換えます。
- Pythonスクリプトfunction_app.pyの12行目付近を修正し、以下のプレースホルダーを、ステップ1およびステップ4でコピーした実際の値に置き換えてください。

- 次に、Pythonスクリプトfunction_app.pyの403行目付近を修正し、プレースホルダーである<connection_name>を実際の接続名に置き換えてください。この値は、あなたのlocal_settings.jsonファイル内で見つけることができます。その形式はxxxxxx_STORAGEのようなものです。
- 修正した関数をAzure Function Appに再デプロイします。
ステップ7. TiDBおよびTiCDCクラスタの準備
TiCDC (TiDB Change Data Capture) は、TiDBクラスタから行レベルのデータ変更を捕捉し、それをリアルタイムでダウンストリームプラットフォームに出力する、TiDBのコアコンポーネントです。TiDB CloudとTiDB Self-ManagedクラスタのどちらでもTiCDCを有効にできます。
このステップは、TiDB Self-Managedでのみ必要です。TiDB Cloudを利用している場合は、TiCDCがクラウドサービスによって完全にマネージドされているため、このステップを省略できます。以下の手順は、TiDB Self-Managedクラスタ向けにTiCDCクラスタをデプロイする方法を説明します。
高可用性のため、この例では、TiDBクラスタの構成に合わせてTiCDCクラスタを3つのアベイラビリティゾーンにまたがってデプロイします。これは顧客のニーズに合わせて調整可能ですが、単一ノードでも機能するものの、本番環境では複数のノードをゾーンをまたいで配置することが推奨されます。既存のTiDBクラスタは、オンプレミスでも、AWS、GCP、Azureなどのあらゆるクラウド環境に配置されていても構いません。
TiDB初心者向けのヒント
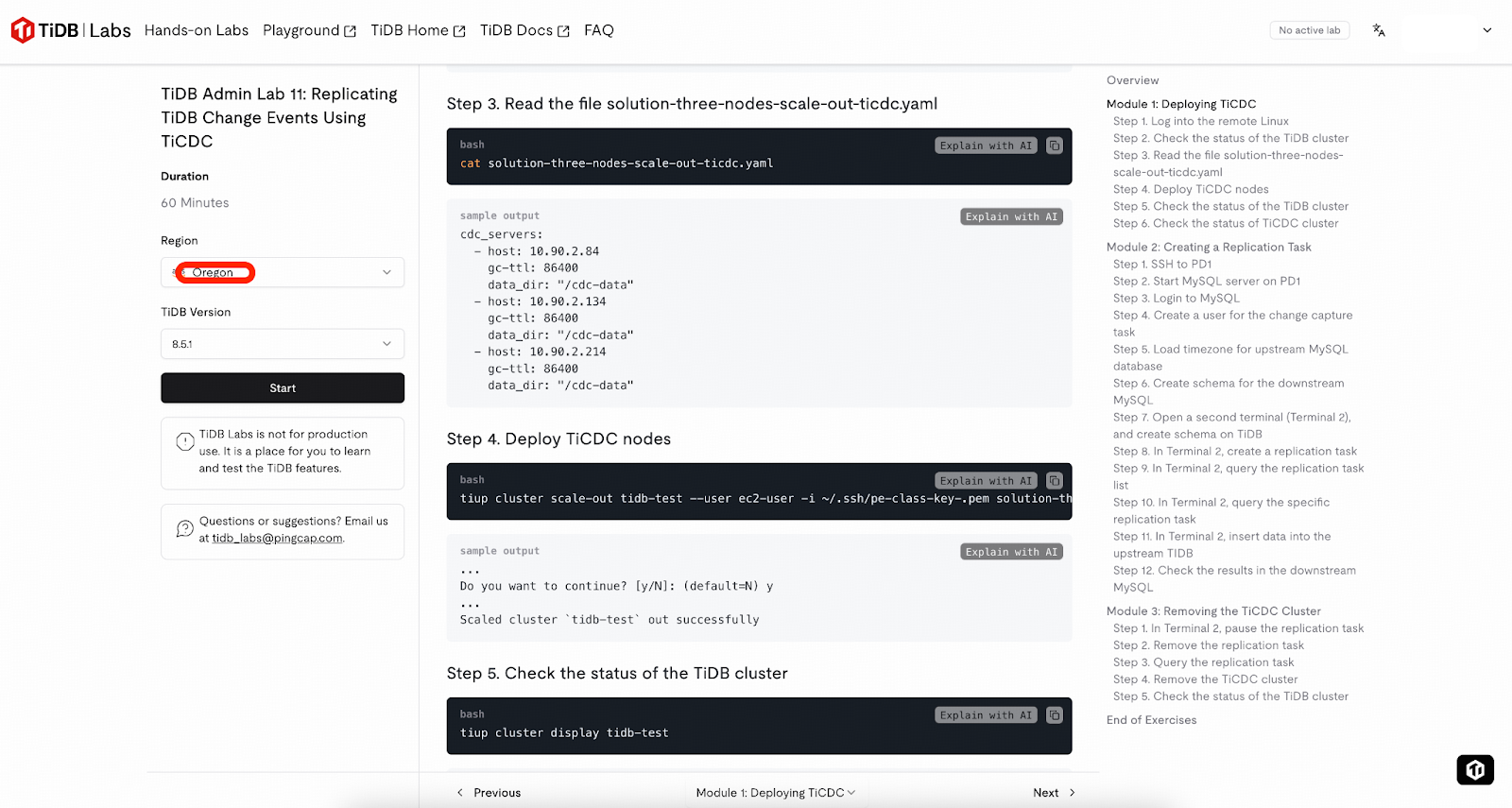
もしTiDBおよびTiCDCを初めてご利用になる場合、このステップのタスクは複雑に感じられるかもしれません。TiDB Labsが提供するサンドボックス環境 (1インスタンスあたり2時間) の利用をお勧めします。単にOregonリージョンを選択してラボを開始し、ガイダンスに従って
モジュール1を完了し、動作するTiCDCが有効化されたTiDBクラスタをプロビジョニングした後、そのままステップ6 – サンプルスキーマの準備に進んでください。
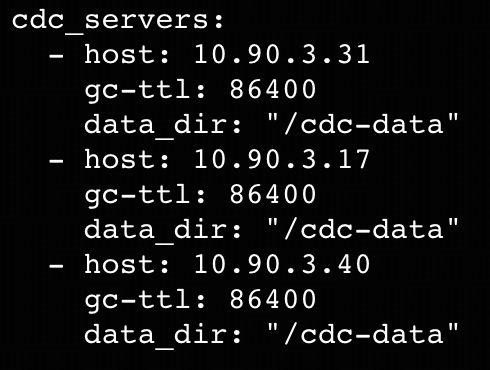
- TiDBクラスタと並行して、TiCDCクラスタ用に追加のノードを3台準備してください。ノードの要件はこちらを参照してください。この例では、これらのノードのプライベートIPアドレスは10.90.3.31、10.90.3.17、および10.90.3.40です。
- TiCDCクラスタ用のYAML設定ファイルを作成します (例:example.yaml)。
- TiUPコントロールマシンから、以下のtiup cluster scale-outコマンドを実行してTiCDCクラスタをデプロイしてください。このコマンドのパラメーターに関する詳細な説明については、ドキュメントを参照してください。
tiup cluster scale-out <tidb_cluster_name> --user <tidb_deploy_user> -i <auth_private_key> example.yaml -y- TiCDCクラスタが稼働していることを確認するには、TiUPコントロールマシンから以下のコマンドを実行してください。<pd_private_address>の部分を、クラスタ内の任意のPlacement Driver (PD) ノードのプライベートアドレスに置き換えてください。この例では、アドレスは10.90.3.21です。
tiup ctl:v8.5.1 cdc capture list --pd=http://<pd_private_address>:2379
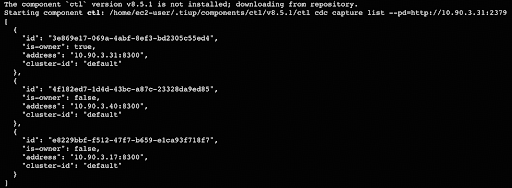
これでソースとなるTiDBクラスタとTiCDCクラスタの準備が整いましたので、次のステップでデータの準備を行います。また、TiCDCはChangefeedが設定されていない状態でも動作することに留意してください。
ステップ8. サンプルスキーマの準備
TiDB初心者へのヒント:TiDB Labsが提供するサンドボックス環境を利用している場合は、モジュール2は実行しないでください。代わりにこのステップを実行してください。
ここでは、bookshopデータベース内のbooksテーブルを使用してレプリケーションを実施します。このステップでは、お使いのTiDBクラスタ内にこのスキーマとテーブルを作成します。
- スキーマ作成用のSQLスクリプトをダウンロードします。
wget https://raw.githubusercontent.com/pingcap-inc/tidb-course-labs/refs/heads/main/solution/microsoft-fabric-mirrored-database/bookshop_demo.sql- お使いのTiDBクラスタに接続し、SQLスクリプトを実行してください。mysqlクライアントを使用してTiDB SQLレイヤーに接続する方法の詳細な説明については、ドキュメントを参照してください。
mysql> SOURCE bookshop_demo.sql- テーブルbookshop.booksに100行のレコードがあることを確認してください。
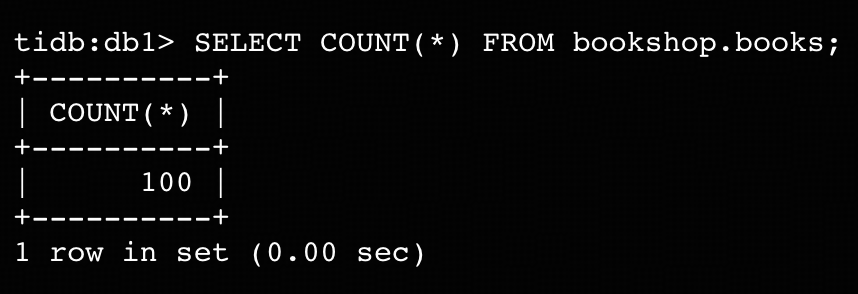
ステップ9. 初期テーブルデータをランディングゾーンにアップロードする
このステップでは、Dumplingを使用してTiDBからテーブルbooks全体をCSVファイルとしてダンプし、それをMirrored DatabaseのLanding Zoneにアップロードします。その後、FabricがデータをOneLakeへ自動的にプッシュします。
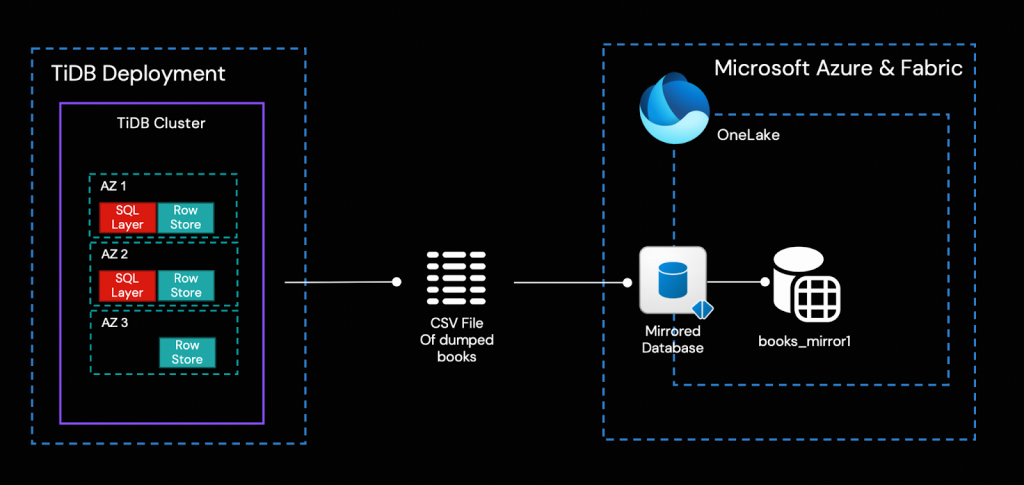
- bookshop.booksテーブル全体をCSVファイルにエクスポートします。この例では、このタスクをTiUPコントロールマシン上で実行しますが、別のマシンから実行することも可能です。Dumplingの使用に関する詳細については、ドキュメントを参照してください。以下のコマンドにおける${HOST_TIDB_SERVER_IP}は、接続可能なTiDBサーバーインスタンスのいずれかのIPアドレスを表します。
tiup dumpling:v8.5.1 -uroot -P4000 -h ${HOST_TIDB_SERVER_IP} --filetype csv --csv-null-value "N/A" -t 1 -o /tmp/books -T bookshop.books- エクスポートされたファイルが/tmp/books/ディレクトリに存在することを確認してください。
ls -l /tmp/books/- ステップ5でダウンロードしたPythonスクリプトを使用して、bookshop.books.000000000.csvをbs_mirror1 Landing Zoneにアップロードしてください。(もしDumplingをステップ5で使用したマシンとは別のマシンで実行した場合は、最初にCSVファイルをそのマシンにコピーする必要があります。)
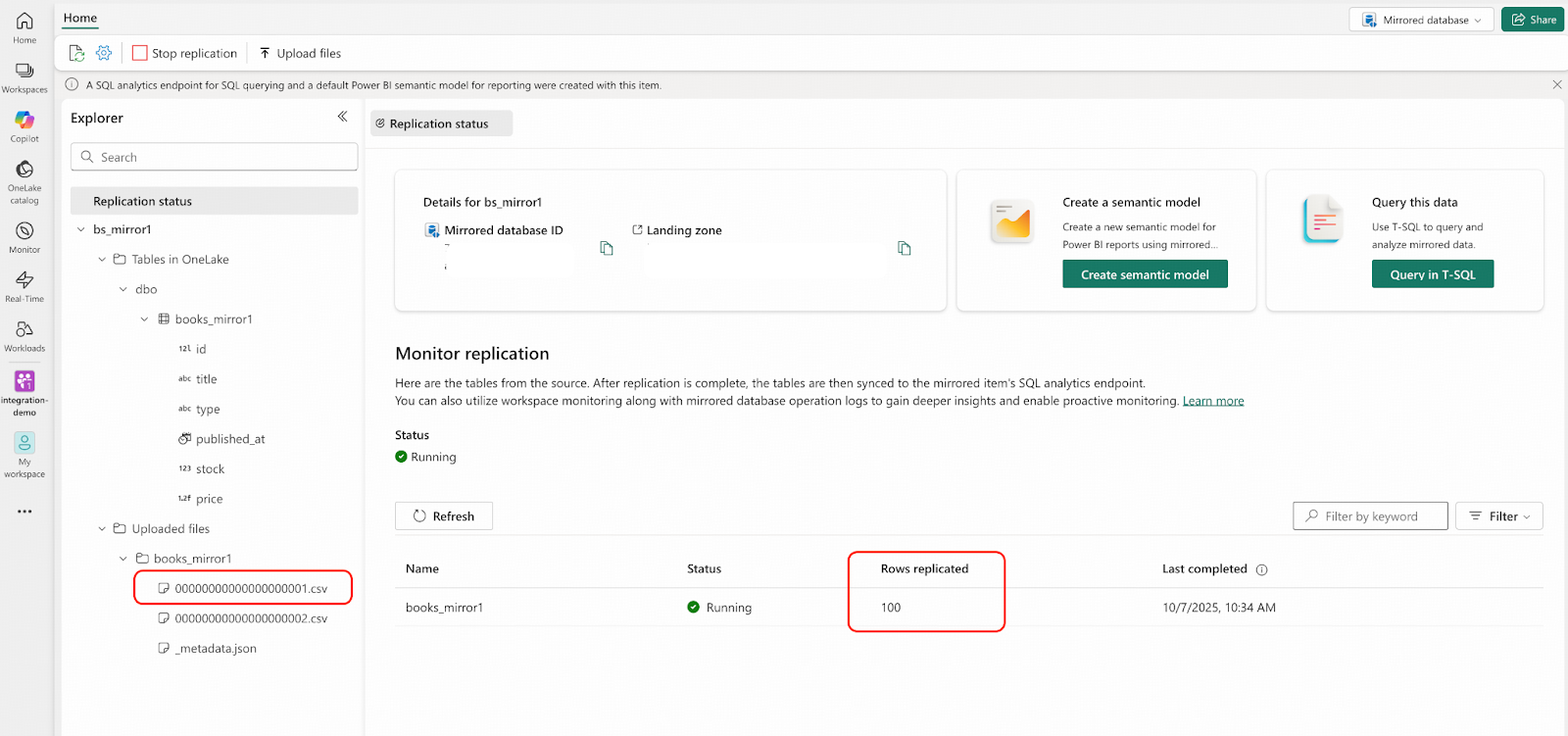
python openmirroring_admin_solution.py --upload-data-file --table-name books_mirror1 --local-file-path /tmp/books/bookshop.books.000000000.csv- Microsoft Fabricポータルで、integration-demoワークスペースに移動し、bs_mirror1 mirrored databaseを開いてください。以下のスクリーンショットで強調表示されている領域に示されているとおりに、結果を確認します。
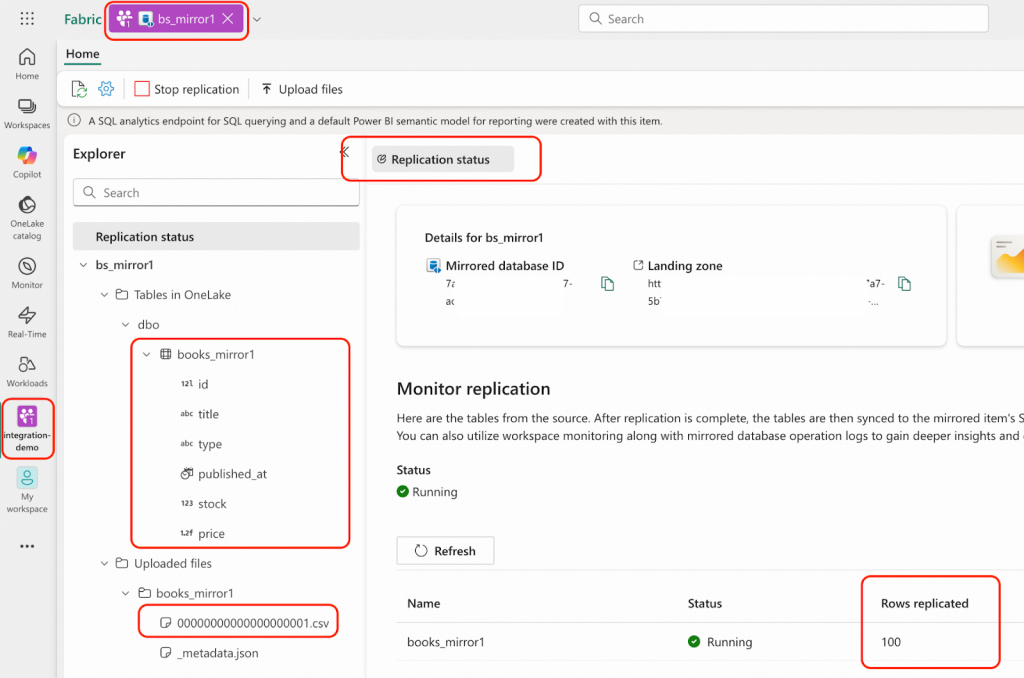
これでMirrored Databaseはソースデータベースと同じデータを持つ状態になりましたが、リアルタイムのChangefeedはまだ有効になっていません。
ステップ10. 増分レプリケーションのためのTiCDC Changefeedを開始する
このステップでは、テーブルbookshop.booksに対するすべてのトランザクション変更を捕捉し、その変更をBlobコンテナーtidb-demo-cdcに送信するようにTiCDCに指示するChangefeedを作成します。このChangefeedには、既にイベントリスナーとなるAzure関数をデプロイ済みです。
- Microsoft Azureポータルにサインインし、ご使用のストレージアカウントに移動して、ストレージアカウントキーを有効にし、取得してください。詳細な手順については、[こちらのドキュメントを参照してください。
- TiUPコントロールマシン上で、Changefeed設定ファイル (books.toml) を作成してください。
[filter]
rules = ["bookshop.books"]
[sink]
protocol = "csv"
enable-partition-separator = false
[sink.csv]
null = "N/A"- 以下のコマンドを実行してChangefeedを有効にしてください。プレースホルダーをご自身のストレージアカウント名とストレージアカウントキーの実際の値に置き換えてください。${HOST_PD1_PRIVATE_IP}は、クラスタ内の任意のPlacement Driver (PD) ノードのプライベートIPアドレスを表します。
export ACCOUNT_NAME="<storage_account_name>"
export ACCOUNT_KEY='<storage_account_key>'
export CONTAINER_NAME="tidb-demo-cdc"
tiup cdc:v8.5.1 cli changefeed create --pd=http://${HOST_PD1_PRIVATE_IP}:2379 \ --sink-uri="azure://${CONTAINER_NAME}/tidb-test?safe-mode=true&account-name=${ACCOUNT_NAME}&account-key=${ACCOUNT_KEY}" \
--changefeed-id="replication-task-1" \
--sort-engine="unified" \
--config=books.toml- アクティブ化されたChangefeedを確認するために、以下のコマンドを、出力と合わせて使用してください。
tiup cdc:v8.5.1 cli changefeed query \
--pd=http://${HOST_PD1_PRIVATE_IP}:2379 \
--changefeed-id=replication-task-1ステップ11. TiDBに変更を適用し、Microsoft Fabric Mirrored Databaseで結果を確認する
- TiDBに接続し、bookshop.booksテーブルに対して1件のアップデートを実行してください。
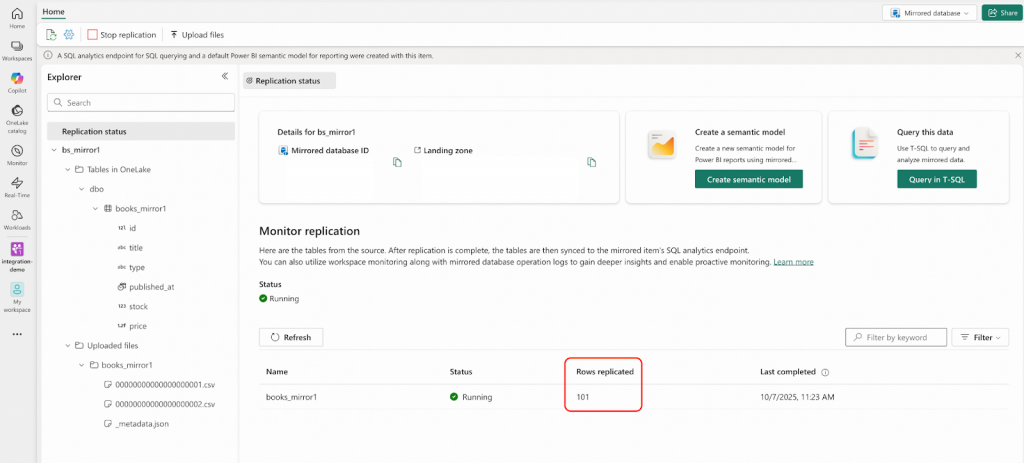
UPDATE bookshop.books SET price = price*0.9 WHERE id=1;- Fabricポータルに移動してください。CSVファイルがLanding Zoneに自動的にアップロードされているのが確認できます。ただし、「Rows replicated (複製された行)」のカウントはまだ100のままで、すぐに101には更新されないことに注意してください。
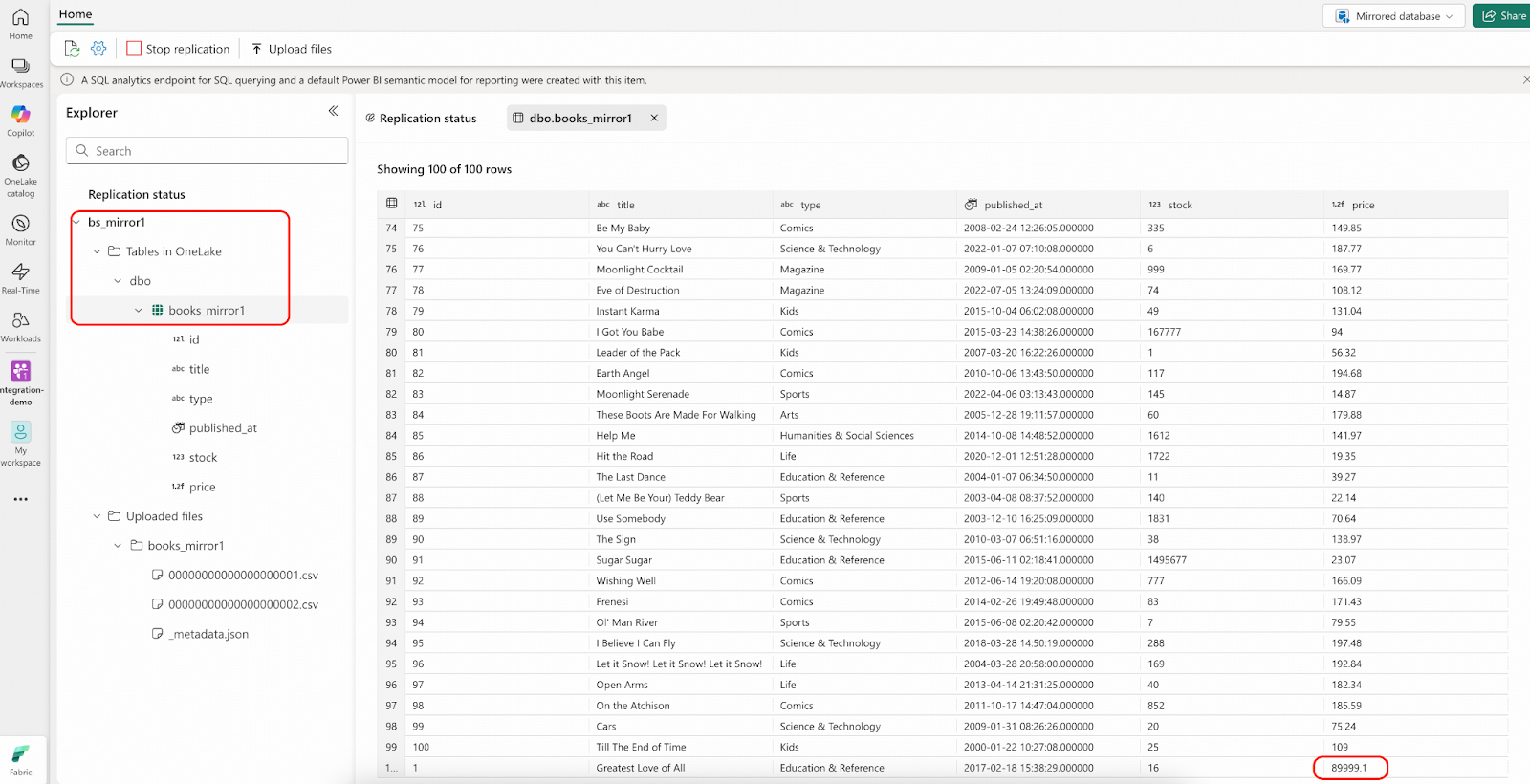
- 少し待って、「Rows replicated (複製された行)」のカウントが101に変わったら、IDが1の行を確認してください。OneLake内の価格は、bookshop.books.000000000.csvファイルの値の0.9倍になっているはずです。
- TiDBに接続し、bookshop.booksテーブルに1件のインサートを実行してください。
INSERT INTO bookshop.books VALUES (NULL,'Introduction to TiDB', 'Education & Reference', NOW(), 100, 20.0);Microsoft Fabricで結果を確認する
- Fabricポータルに移動してください。CSVファイルが再度Landing Zoneに自動的にアップロードされており、ファイル名が順次インクリメントされていることが確認できます。なお、「Rows replicated (複製された行)」のカウントはまだ101のままであり、まもなく102に更新されます。
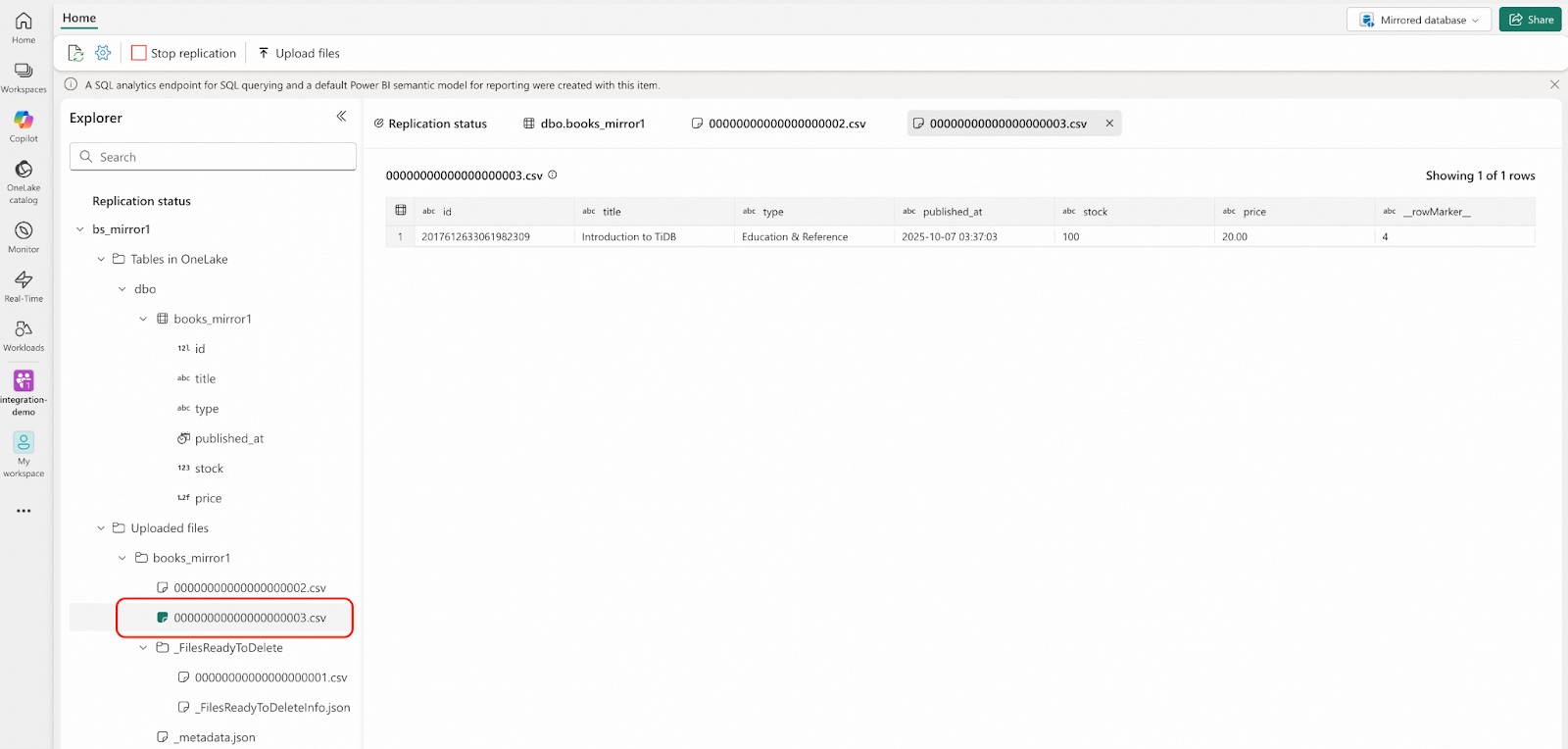
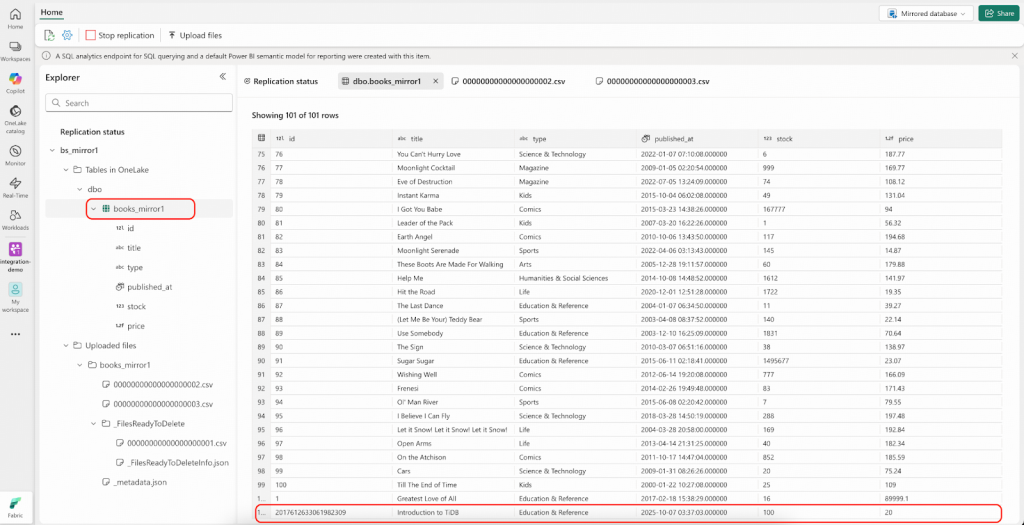
- TiDBに接続し、bookshop.booksテーブルから5行のレコードを削除してください。
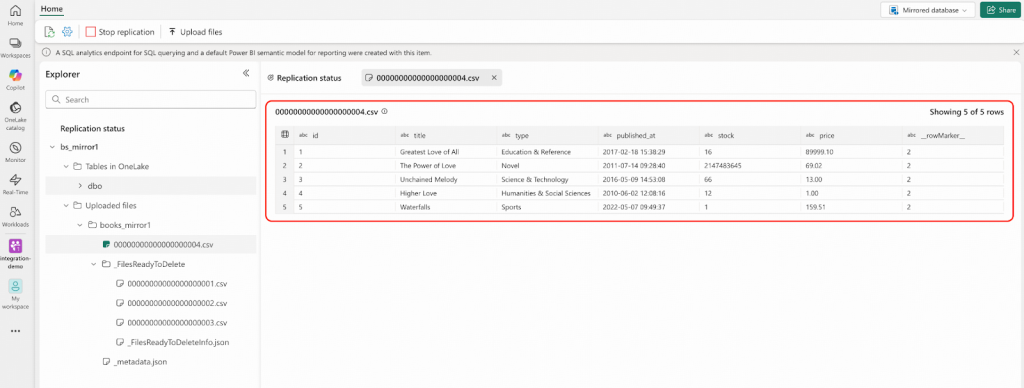
DELETE FROM bookshop.books WHERE id IN (1,2,3,4,5);- Fabricポータルに移動してください。以下のスクリーンショットに示されているものと同様の結果が表示されます。
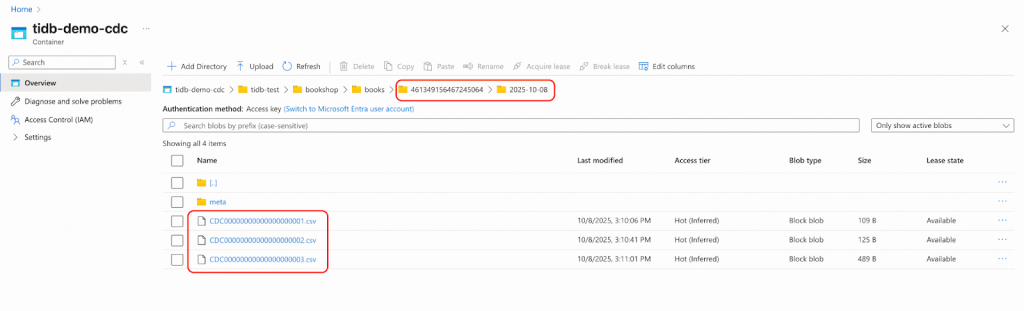
- Microsoft Azureにサインインし、tidb-demo-cdcという名前のBlobコンテナーに移動して、ステージングされたChangefeedのCSVファイルを調べます。TSOおよび日付時刻のフォルダ名は、この例とは異なることに注意してください。CSVファイルの命名規則に細心の注意を払ってください。これは、Landing Zone内のファイルと以下の2つの重要な点で異なっています。
- ファイル名の先頭に「CDC」というプレフィックスが付いています。
- シーケンス番号がLanding Zone内の対応するファイルよりも「1」少なくなっています。これは、Landing Zoneの最初のファイルが完全なデータインポートを表すのに対し、これらのファイルは増分変更のみを含んでいるためです。
例えば、ここにあるファイルCDC00000000000000000003.csvは、Landing Zone内の00000000000000000003.csvに対応します。
- SQL分析エンドポイントから、T-SQLを使用して、あなたのMirrored Database内に96行のレコードがあることを確認できます。
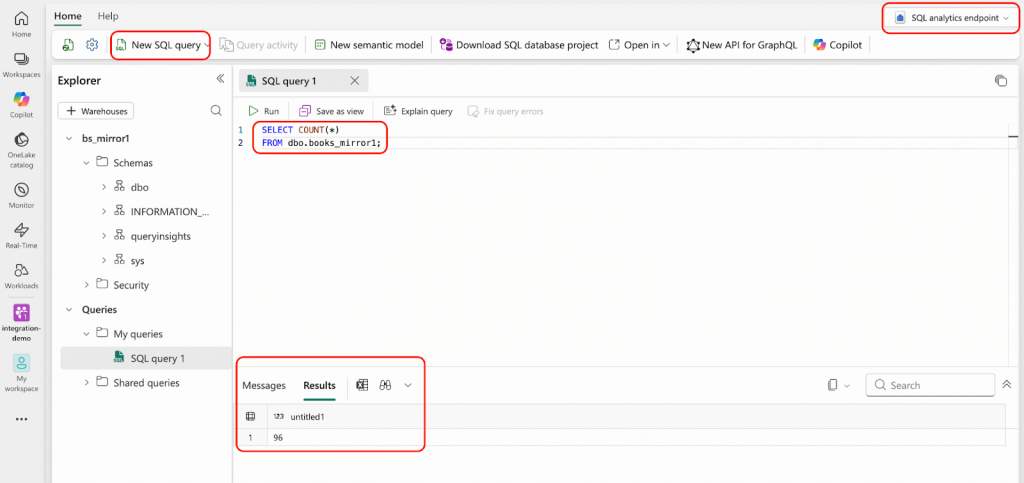
これで、運用データがリアルタイムでOneLakeに複製されましたので、このドキュメントに記載されているすべての機能を使用して、すぐにデータを分析することができます。
ベストプラクティス
- ステップ9と10の間では、bookshop.booksテーブルは変更されないままであり、これは読み取り専用アクティビティの期間またはトランザクションの一時停止を示しています。このダウンタイムを排除し、アプリケーションがトランザクションの処理を継続できるようにするためには、ステップ10でChangefeedを作成する際にstart-tsオプションを使用する必要があります。start-tsの値は、ステップ9のDumplingエクスポート開始時に捕捉されたTSO (Timestamp Oracle) に設定してください。このTSO (Posの値) は、ステップ9のファイル/tmp/books/metadataの中で見つけることができます。
- あなたのビジネス要件に基づいて、Mirrored DatabaseのランディングゾーンとBlobコンテナーに対して異なるリテンションポリシーを設定できます。
まとめ
このブログ記事では、TiCDCとOpen Mirroringを使用した、TiDBからMicrosoft Fabricへのリアルタイムデータレプリケーションのための統合ソリューションを紹介しました。詳細な手順に従うことで、ユーザーはTiDBのデータをOneLakeにシームレスに統合し、Fabricの強力な分析およびAI機能のメリットを享受できます。この統合により、データの鮮度と一貫性が確保され、ビジネスは情報に基づいた意思決定のためにタイムリーな洞察を得ることができます。TiDBのデータストリーム捕捉およびレプリケーション機能についてさらに詳しく知りたい場合は、当社のTiCDCドキュメントをご覧ください。
TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。