
※このブログは2025年12月19日に公開された英語ブログ 「Object Storage: The New Backbone of Database Architecture」 の拙訳です。
AIワークロードが最初に本番システムに投入され始めた当初、多くのチームでは、ボトルネックはコンピュートに現れると考えられていました。GPUを増やすこと、CPUを高速化すること、メモリプールを拡張すること――それが自然なスケーリングの方向性だと思われていたのです。
しかし、実際に最初に限界を迎えたのは、そこではありませんでした。
システムが問題を起こした原因は、コンピュートの不足ではありませんでした。ストレージの余力が先に尽きてしまったのです。CPUが飽和するよりもはるかに早い段階でクエリレイテンシが悪化し、レプリケーションは処理に追いつかなくなり、コンパクションジョブは想定していた実行時間を超えてしまいました。その結果、コストは性能向上のペースを上回って増加していきました。
AIは単にワークロードを増大させただけではありません。将来に対する備えが最も不十分だったデータベースアーキテクチャの領域、すなわちストレージを浮き彫りにしたのです。
このような傾向は業界全体で繰り返し見られており、そこには大きな構造的変化が示されています。データベース設計における戦略的な重心は、コンピュートからストレージレイヤーへと徐々に移りつつあるのです。
変化の焦点:ストレージアーキテクチャがシステムの優位性を決定づける時代
長年にわたり、コンピュートの進化はデータベース性能を大きく向上させてきました。しかし、その時代はすでに終わりを迎えています。
現在のワークロードは、大規模かつ急速に増大するデータセット、マルチモーダルなクエリパターン、頻繁なベクトル演算、そして巨大なコンテキストウィンドウを生成するマルチエージェントAIシステムによって形作られています。さらに、特にコンシューマ向けやAI駆動のアプリケーションでは、トラフィックの予測が以前よりもはるかに困難になっています。
FlipkartのBig Billion Daysセールは、その状況をよく示しています。クラスタは数週間前からスケールアウトする必要があり、セール後も段階的にしかスケールダウンできませんでした。それでもなお、コストの多くはコンピュートではなく、ディスクやレプリカの準備に費やされていました。
この課題は決して特定の企業に限ったものではありません。業界全体を見渡すと、もはやコンピュートが最初の制約条件になるケースは少なくなっています。代わりに、ストレージのスループット、IOPSの上限、レプリケーションによるオーバーヘッド、コンパクションの負荷といった要素が、先に顕在化するようになっています。
初期の分散データベース――初期のTiDBアーキテクチャも含めて――は、今とは異なる時代のハードウェアやワークロードを前提として設計されていました。ワークロードが進化するにつれて、それらの前提は次第に制約となっていきました。現在では、どれだけストレージを中心に深く設計されているかが、競争上の優位性を左右する要因になりつつあります。
Cursorのデータベース遍歴から得られた3つの教訓
この変化は、Cursorが最近経験したインフラの変遷によって明確に示されています。この内容は、同社のCTO兼共同創業者がスタンフォード大学のCS153の講義で共有したものです。
教訓1:分散SQLは洗練されているが、複雑さが足かせになることがあります
Cursorは当初、コアとなるインデックス処理のワークロードに対して、Spanner系の分散SQLシステムを採用しました。理論上は、強い整合性、自動シャーディング、水平スケーラビリティといった利点を備えていました。しかし実際には、プロダクトを進化させる以上にデータベースの管理に時間を費やすことになり、最終的には、よりシンプルなマネージドPostgreSQL構成へと移行しました。
ここから得られた教訓は、分散SQLが欠陥を抱えているということではありません。スケールした環境では、理論的な洗練さよりも、シンプルさが勝る場面が多いということです。
教訓2:従来型データベースが、書き込みが止まらないAIワークロードに苦戦する理由
PostgreSQLは汎用性の高い強力なデータベースですが、MVCCやバキューム処理を前提としたシングルノードのストレージエンジンである点は変わりません。Cursorのように、継続的な更新、巨大なテーブル、急速なデータ増加を伴うワークロードでは、チューニングはいずれ限界に突き当たりました。
根本的な解決策は、さらなる最適化ではありませんでした。アーキテクチャそのものを見直すことだったのです。Cursorは、最大かつ最も高負荷なテーブルを、オブジェクトストレージを基盤とするシステムへ移行しました。
この教訓は明確です。現代のAIワークロードにおいては、従来型データベースはいずれ、オブジェクトストレージを前提に設計されたシステムに及ばなくなるということです。
教訓3:将来のデータアーキテクチャはオブジェクトストレージファーストへ
Cursorは試行錯誤を重ねる中で、現代的な構成にたどり着きました。それは、大規模データの永続的な置き場所としてオブジェクトストレージを据え、その上にコンピュートやクエリエンジンを重ねるというパターンです。オブジェクトストレージは、耐久性、容量、そしてコスト効率の高いスケーリングを担い、データベースはストレージではなく、コンピュートを提供するサービスとして位置付けられるようになりました。
なぜオブジェクトストレージがデータベースの前提を変えるのか
オブジェクトストレージは、コールドデータ向けの低コストな保存先として語られがちです。しかし、これがデータベースの基盤になると、システムの振る舞いはそれ以上に大きく変わってきます。
オブジェクトストレージは、イミュータブルなデータ特性、非常に高い耐久性、そして事実上無制限の容量を提供します。耐久性はローカルのレプリカに依存するのではなく、ストレージレイヤーそのものが担うようになり、コストの予測性が高まり、ライフサイクル管理もシンプルになります。
データがオブジェクトストレージに移行すると、データベースの中核コンポーネントは再設計が必要になります。並行制御、インデックス戦略、コンパクションの流れ、キャッシュ設計、リカバリロジック、ワークロード分離、分散実行といった要素はすべて変わってきます。コンピュートとデータが密結合していることや、レプリカを多用して耐久性を確保することなど、ローカルストレージやブロックストレージを前提に成り立っていた設計上の仮定は、もはや当てはまらなくなっていくのです。
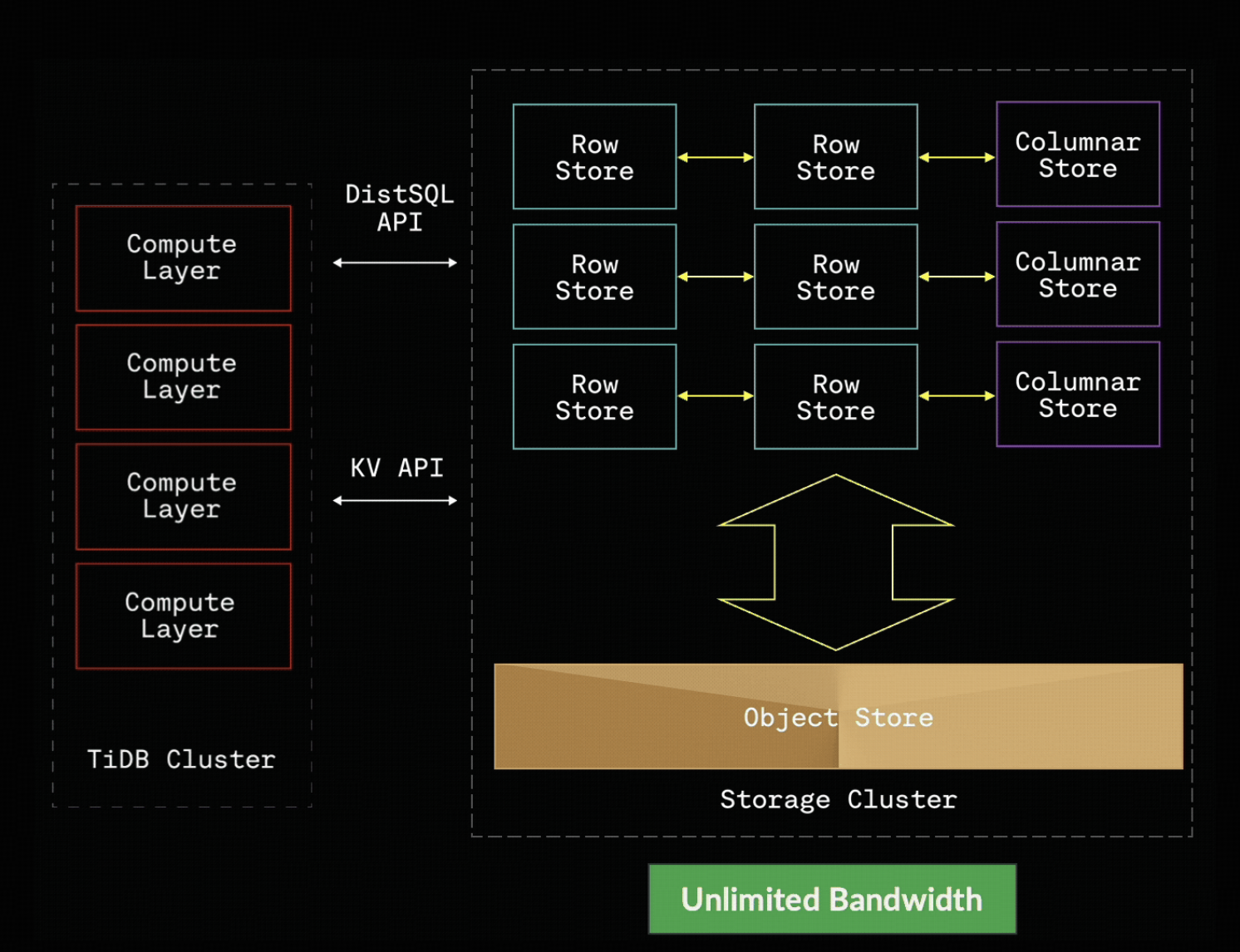
図1:コンピュートとオブジェクトストレージの分離で実現する弾力的スケーリングと統合ワークロード
このため、オブジェクトストレージは既存のアーキテクチャに単純に重ねるだけでは効果を発揮できません。その利点を最大限に引き出すには、システムをゼロから設計し直す必要があります。
TiDBにとって重要な理由
TiDBは、多くの分散SQLシステムと同様に、Google Spannerに触発され、ローカルディスクやEBSなどのクラウドボリュームを基盤として構築されています。多くの同業システムと異なり、TiDBは大規模かつミッションクリティカルな本番環境での運用に耐えるように強化されています。
しかし、Cursorの事例が示すのは、より本質的なポイントです。優れたSpannerスタイルのシステムであっても、AIワークロードが急増する状況では根本的な負荷に直面します。巨大なベクトルデータ、長期の履歴、エージェントのトレース、さらに同じ論理データ上でOLTP、分析、AIワークロードを同時に提供する必要があることが、ディスク中心のアーキテクチャに大きな負荷を与えます。
TiDB X:オブジェクトストレージ時代に向けての設計
TiDB Xは、私たちの分散SQLデータベースの最新アーキテクチャで、シンプルな考え方に基づいて設計されています。すなわち、オブジェクトストレージが真のデータソースとなり、データベースはその上でコンピュートとクエリを担うレイヤーであるということです。
すべてのコアデータはオブジェクトストレージ上に存在し、安価で耐久性が高く、独立してスケール可能な容量を提供します。コンピュートはステートレスかつ弾力的であるため、OLTP、分析、AIといったハイブリッドワークロードをその場しのぎの回避策ではなく第一級の標準機能として扱えます。TiDB Cloudの従量課金モデルにより、チームはアイドル状態のクラスタに支払う必要はなく、実際に処理した分だけ支払う仕組みとなっており、急激な負荷変動の多いAI駆動ワークロードにも自然に対応できます。
一つの大規模データベースから、数百万の小規模データベースへ
AIやエージェント型システムは、このアーキテクチャをさらに進化させます。一つのモノリシックなデータベースではなく、各エージェントが独自のコンテキストストアや一時的なステート、あるいは一時的なベクトルインデックスを生成するようになるのです。
これにより、モデルは一つの大規模データベースから、数百万もの小規模で弾力的かつ一時的なデータベースへと変わります。このモデルが成立するのは、耐久性がオブジェクトストレージ上で担保され、コンピュートがステートレスかつ使い捨て可能である場合に限られます。この変化がなければ、AI時代のアーキテクチャはすぐにコストが膨れ上がり、運用も不安定になってしまいます。
TiDB Cloudで始める、アプリ書き換えなしのスケール
AIコーディングアシスタント、エージェント型RAGシステム、マルチテナントSaaSプラットフォーム、あるいは大量かつ急速に変化するデータを扱うプロダクトを開発する場合、Cursorが直面したのと同じ構造的課題に直面します。
従来の道をたどることもできます――伝統的なデータベースで始め、スケーリングの限界にぶつかり、ワークロードを少しずつ移行し、最終的にオブジェクトストレージを中心に再構築する方法です。
あるいは、その旅の終着点からスタートすることも可能です。
TiDB Xを基盤としたTiDB Cloudは、最初からオブジェクトストレージを土台とする環境を提供します。スケール実績のある分散SQL、単一の論理システムでのハイブリッドワークロード、そしてAI時代に最適化された弾力的な従量課金を備えています。
これらのアーキテクチャ変革は、すでに本番環境のAIシステムにも影響を与えています。汎用エージェント型AIプラットフォームのManusは、巨大なコンテキスト増加、書き込み負荷の高いワークロード、再設計なしでのスケーリングという同様の課題に直面していました。TiDB Xを基盤とするTiDB Cloudを採用することで、オブジェクトストレージを爆発的な成長と大規模エージェント群の基盤として活用することができました。
TiDB Cloudを使って、数千のエージェントによる秒以下のブランチングをどのようにスケールさせたのか、その詳細を確認できます。



TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。