
※このブログは2026年2月6日に公開された英語ブログ「OpenClaw Memory Architecture: Building a Local-First RAG with SQLite」の拙訳です。
編集者注:PingCAPでは分散型システム (TiDB) を開発していますが、私たちは規模を問わず、エレガントなエンジニアリングを高く評価しています。OpenClawは、「ローカルファーストなRAGデータベース」の完璧なユースケースを示しています。運用コストをゼロにし、完全なデータプライバシーを確保し、個人ユーザーのために瞬時に起動させたい場合、SQLiteは極めて現実的な選択肢です。
私たちは適材適所のツール選びが重要だと考えています。デスクトップではSQLiteが威力を発揮し、クラウドや大規模環境ではTiDBがその本領を発揮するように設計されています。ローカルアーキテクチャの境界線を正しく理解することは、なぜ、そしていつ分散型システムへとステップアップすべきかを知る手がかりになります。
それでは、OpenClawがいかにしてローカルファイルを活用し、個人向けのRAGシステムを構築しているのか、その詳細を見ていきましょう。
分析の前提
- 対象プロジェクト:OpenClaw (およびその派生版Moltbot / ClawdBot)
- 分析バージョン:
mainブランチのコミット9025da2(2026年1月30日時点) - 対象範囲:
src/memory/*の実装
OpenClawは「永続的なメモリー」をコア機能として掲げています。ユーザーのコンテキストを記憶し、使うほどに自分専用のツールへと進化していくという約束です。エンジニアの視点でこれを読むと、データはどこに保存されるのか?Dockerコンテナを動かす必要があるのか?データが外部のベクトル検索クラウドに送信されるのではないか?といった疑問が自然と湧いてくるでしょう。
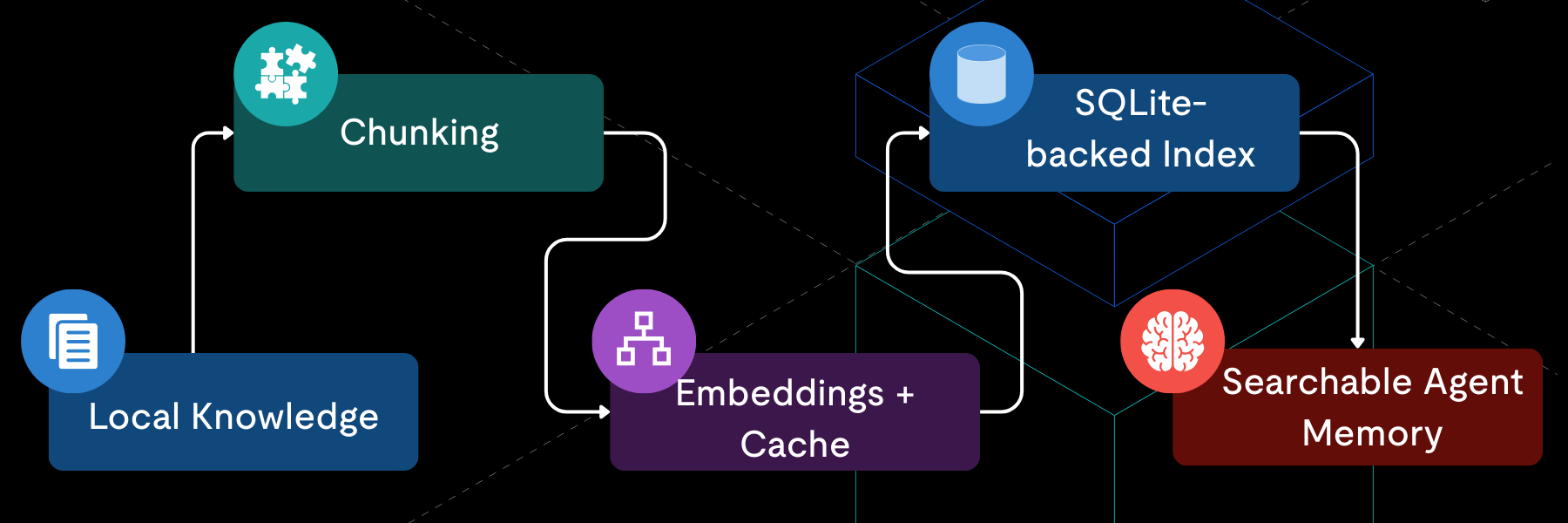
その答えはsrc/memoryの中にあります。OpenClawの永続メモリーは、SQLiteのみで動作する軽量なRAGローカル検索システムです。
このシステムは、ローカルにあるMarkdown形式のナレッジを分割し、エンベディングを生成して、そのインデックスをローカルの.sqliteファイルに保存します。情報の取り出しは、ベクトル検索、キーワード検索、またはその両方を組み合わせたハイブリッド検索によって行われます。
AIエージェントにおけるデスクトップ向けRAGの課題
個人用AIエージェントのメモリーシステムを構築する際には、サーバーサイドのRAGとは大きく異なる、特有の制約がいくつも存在します。
- 運用ゼロ:エージェントを利用するためだけに、ユーザーがPostgreSQLをインストールしたり、Dockerを起動したり、複雑な認証情報を管理したりする手間を強いてはなりません。
- ローカルファースト:「ナレッジベース」の実体は、通常、ユーザーのディスク上にあるMarkdownファイル (
MEMORY.mdなど) のフォルダに過ぎません。インデックスは、このローカル性を尊重する必要があります。 - 回復性:たとえ高度な機能 (ローカル用のベクトル検索拡張機能など) の読み込みに失敗したとしても、システムとして動作し続けなければなりません。
ローカルファーストAIにSQLiteが最適な理由
これらの制約を踏まえ、コードベースからは明確な意思決定のプロセスが見て取れます。
なぜベクトル専用データベースではないのか?専用のベクトルデータベースは強力なインデックス機能を提供しますが、通常はサービス指向アーキテクチャ (データの投入、独立したプロセス) を前提としています。ローカルツールにおいて、ユーザーに別途ベクトルデータベースを起動させることは、導入の大きな障壁となります。
なぜMySQLやPostgreSQLではないのか?本番環境ではフル機能のリレーショナルデータベース管理システムを推奨しますが、個人のマシンで動かすとなると運用上のオーバーヘッドが生じます。OpenClawに求められるのは「ダウンロードして即実行」できることです。ローカルでmysqldプロセスを要求したり、接続文字列の設定を強いたりすることは、ゼロ設定という目標に反します。
決断は?SQLiteはこの特定の需要に完璧に合致しています。
- サーバーへの依存なし:ポートもバックグラウンドプロセスも必要ありません。
- 単一ファイルによるポータビリティ:インデックス全体がたった一つの
.sqliteファイルに収まるため、バックアップも極めて容易です。 - エコシステム:
FTS5(全文検索) やsqlite-vec(ベクトル検索) といった拡張機能を利用することで、単一のバイナリ内で実用的なRAGスタックを構築できます。
| 特徴 | SQLite (OpenClaw) | ベクトル専用DB | 従来のRDBMS |
| セットアップ | 運用ゼロ (ダウンロードして即実行) | 別途サービスやDockerが必要 | サーバープロセスと設定が必要 |
| ポータビリティ | 単一の.sqliteファイルのみ | データの移動に大きな手間がかかる | 移行作業が複雑 |
| 検索機能 | ベクトル + キーワード (ハイブリッド) | ベクトル検索に特化 | 主にキーワード検索 |
SQLiteによるベクトル検索とハイブリッド検索の実装
OpenClawにおいて、SQLiteは単なるストレージではありません。インデックス作成プロセス全体を管理するステートマシンとして機能しています。
データフロー
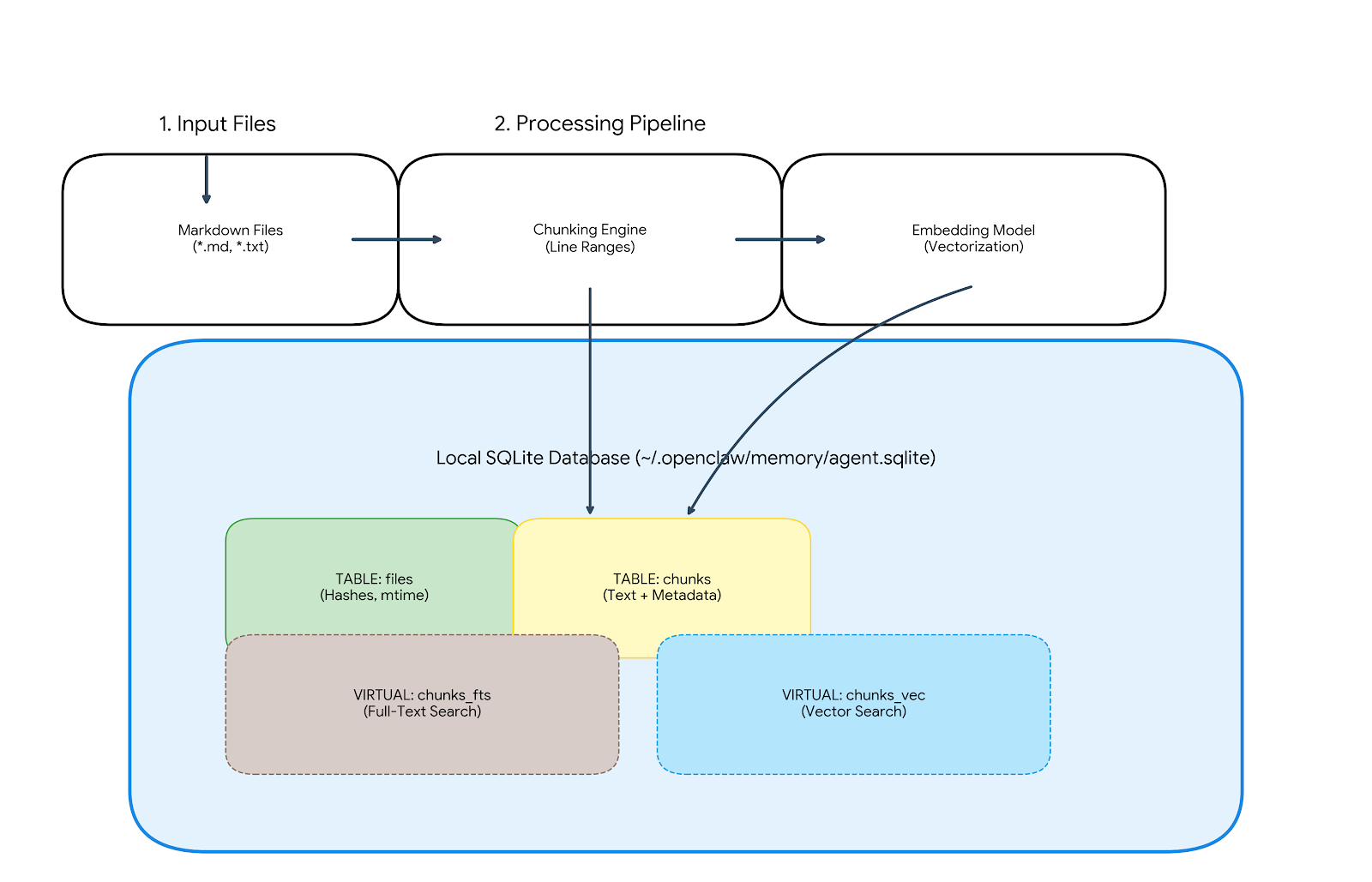
- 入力:Markdownファイル (
memory/**/*.md) およびセッションの書き起こし - 処理:テキストを行単位でチャンクに分割し、エンベディングを生成
- 出力:検索された上位K個のチャンクをプロンプトビルダーに送出
ストレージのレイアウト
インデックスは~/.openclaw/memory/{agentId}.sqliteに保存されます (フォークしたバージョンによっては~/.clawdbotや~/.moltbotになります)。
~/.openclaw/
└── memory/
├── my-agent.sqlite # The active index
├── my-agent.sqlite-wal # Write-Ahead Log
└── my-agent.sqlite-shm # Shared Memoryデータベースは、4つの主要なテーブルと、2つのオプションの仮想テーブルで構成されています。
- files:ファイルの最終更新時刻、サイズ、およびコンテンツのハッシュ値を追跡し、変更のないファイルの再インデックス作成をスキップします。
- chunks:データの信頼できる情報源です。テキスト本体、行の範囲、およびJSON形式でシリアライズされたエンベディングを格納します。
- chunks_vec (仮想テーブル):
sqlite-vecがロードされている場合、このテーブルにバイナリ形式の浮動小数点ベクトルを格納し、高速な類似性検索を可能にします。 - chunks_fts (仮想テーブル):FTS5が利用可能な場合、このテーブルでテキストのインデックスを作成し、キーワード検索を可能にします。
コード解説:インデックス作成と情報取得
OpenClawがこの構造に対してどのようにクエリを実行しているかを見ていきましょう。ここでは段階的な機能縮小を重視しています。これは、もしベクトル拡張機能が利用できない場合でも、システムがより低速ながらも動作可能な代替パスへと自動的に切り替わることを意味します。
1. ベクトル検索 (高速なパス)
sqlite-vecが利用可能な場合、SQLで直接ベクトルの類似性検索を実行できます。
クエリの仕組み:メタデータテーブル (chunks) と専用のベクトルテーブル (chunks_vec) を結合し、テキストコンテキストを取得します。スコアリングにはvec_distance_cosineが使用されている点に注目してください。
SELECT c.id, c.path, c.start_line, c.end_line, c.text,
vec_distance_cosine(v.embedding, ?) AS dist
FROM chunks_vec v
JOIN chunks c ON c.id = v.id
WHERE c.model = ?
ORDER BY dist ASC
LIMIT ?仕組み:返されるdistはコサイン距離を表します。この値が小さいほど、類似度が高いことを意味します。この手法の利点は、計算処理をデータベースエンジン側で行わせることで、Node.jsプロセスの負荷を低く抑えられる点にあります。
2. フォールバック (安全なパス)
ユーザーの環境がネイティブのベクトル検索拡張機能をサポートしていない場合 (クロスプラットフォームのNode.jsモジュールでよく発生する問題です) でも、OpenClawはクラッシュしません。その代わりに、JavaScriptによる「総当たり」方式へと切り替わります。
- SQLiteから候補となるチャンクを読み込みます。
- JavaScriptのみ使用して、メモリ上でコサイン類似度を計算します。
- 類似度の高い順にソートし、上位K個を返します。
これにより、大規模なデータセットではパフォーマンスが低下するものの、メモリー機能そのものは動作し続けることが保証されます。
レジリエンス(回復性)のロジック
OpenClawはtry-catchパターンを使用して、sqlite-vec拡張機能が利用可能かどうかを検知します。拡張機能のロードに失敗したり、クエリがエラーを返したりした場合は、即座にメモリ上での「総当たり」計算へと移行します。
async function searchMemory(queryVector, limit = 5) {
try {
// 1. THE FAST PATH: Native Vector Search [cite: 58]
// Utilizes the 'sqlite-vec' extension for database-level cosine distance[cite: 59, 61].
return await db.all(`
SELECT c.text, vec_distance_cosine(v.embedding, ?) AS dist
FROM chunks_vec v
JOIN chunks c ON c.id = v.id
ORDER BY dist ASC LIMIT ?`, [queryVector, limit]); [cite: 63, 68, 69]
} catch (err) {
console.warn("sqlite-vec not found. Falling back to JS-based search."); [cite: 73]
// 2. THE SAFE PATH: Brute-Force JavaScript [cite: 72, 74]
// Load all candidates and compute similarity in the Node.js process[cite: 75, 76].
const allChunks = await db.all("SELECT id, text, embedding FROM chunks"); [cite: 75]
return allChunks
.map(chunk => ({
...chunk,
dist: cosineSimilarity(queryVector, JSON.parse(chunk.embedding)) // Pure JS calculation [cite: 53, 76]
}))
.sort((a, b) => a.dist - b.dist) // Sorting manually in memory [cite: 76]
.slice(0, limit); [cite: 76]
}
}3. ハイブリッド検索 (両方の長所を活用)
より精度の高い情報取得を実現するために、意味を理解するベクトル検索と、特定の語句を正確に一致させるキーワード検索を組み合わせています。
キーワード検索のクエリ:SQLite標準のFTS5モジュールと、ランキング関数であるBM25を使用しています。
-- Conceptual FTS Query
SELECT *, bm25(chunks_fts) as rank
FROM chunks_fts
WHERE chunks_fts MATCH 'OpenClaw AND Memory'
ORDER BY rank
次に、これらの結果をベクトル結果と重み付けスコアリング式を用いて統合します。
ユーザーの知識を偏りなく、バランスの取れた視点でエージェントに提供します。
まとめ
OpenClawのメモリーシステムは、アーキテクチャを適切なサイズに保つことの重要性を教えてくれます。
SQLiteを選択することで、開発チームは個人用ツールに不必要な分散システムの複雑さを持ち込むことを回避しました。その結果、運用の負担を負うことなく、ACID準拠、ポータビリティ、そして強力なクエリ言語を手に入れることができたのです。
データプライバシーを完全に確保し、個人ユーザー向けに瞬時の起動を実現するという点において、現在のこのタスクにはSQLiteこそが最適なツールです。しかし、「技術的な誠実さ」とは、いつ次のステップへ進むべきかを見極めることでもあります。マルチテナンシーや水平スケーリングが必要になり、拡張性の壁に突き当たったとき―そのとき、これまでのSQLの考え方を変える必要はありません。ただ、データベースを切り替えればよいのです。
とはいえ、アーキテクチャは進化するものです。この「メモリ」の概念を、数千のエージェントにサービスを提供するマルチテナントSaaSプラットフォームへとスケールさせる場合、「ローカルファイル」という制約がボトルネックとなります。その時点こそが、SQLiteからTiDBのような分散型SQLデータベースへと移行すべきタイミングです。それまで利用してきたSQLの作法は維持しつつ、必要とされるスケール性能を追加できるからです。
一方、ローカルで動作するエージェントにとっては、一つの.sqliteファイルがシンプルさと機能性の最も優れたバランスを提供してくれるのです。



TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。