
※このブログは2020年1月11日に公開された英語ブログ「How TiKV Reads and Writes」の拙訳です。
著者: Siddon Tang (Chief Engineer at PingCAP)
トランスクリエーター: Calvin Weng
この記事では、TiKVが読み取りオペレーションと書き込みオペレーションをどのように処理しているのかを詳しく説明します。さらに、TiKVが分散型データベースとして、書き込みリクエストに含まれるデータをどのように保存しているのか、また、整合性が保証された対応データをどのように読み出しているのかを掘り下げていきます。
読み進める前に
話を始める前に、このプロセスを完全に理解するための助けとなる、TiKVの最重要コンセプトをいくつか説明します。TiKVをすでに熟知している読者は、次のセクションにスキップしてもらっても結構です。
Raft
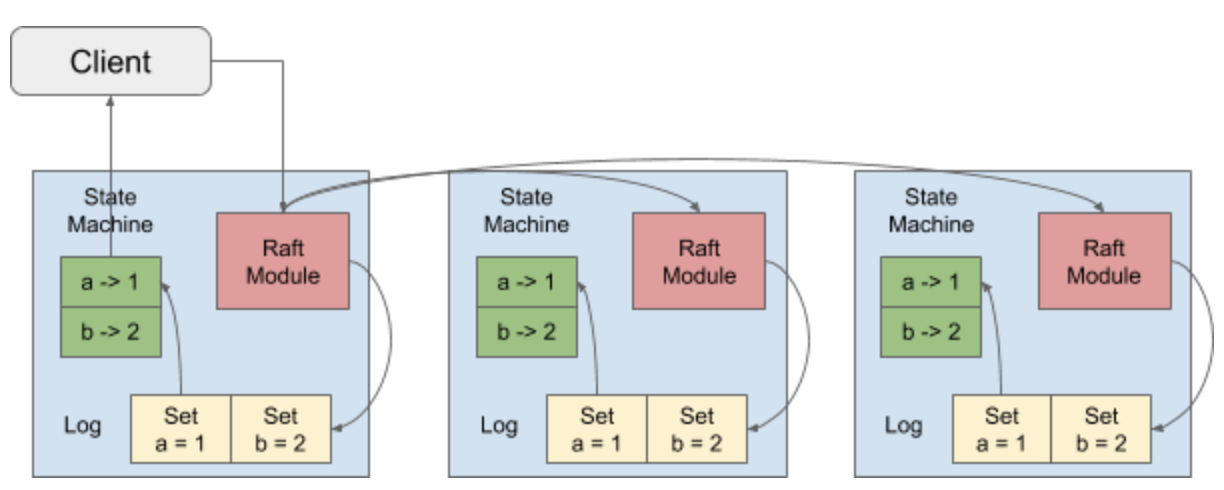
TiKVのRaftプロセス
TiKVでは、Raftコンセンサスアルゴリズムを使うことによって、データの安全性と整合性を確保しています。TiKVでは、デフォルトで3つの複製を利用しており、これらがRaft Groupを形成しています。
データの書き込みを行う場合、クライアントはRaft Leaderにリクエストを送信します。TiKVではこのプロセスをProposeと呼びます。Leaderは、このオペレーションをエントリーにエンコードしてから、独自のRaftログにそれを書き込みます。これをAppendと呼びます。
また、LeaderはRaftアルゴリズムによって、エントリーを他のFollowerにコピーします。この作業をReplicateと呼びます。Followerがエントリーを受信すると、Followerも同様にAppendオペレーションを実行します。その後Leaderに対し、Appendが成功したことを通知します。
Leaderは、エントリーが過半数のノードに追加されたことを確認すると、そのエントリーがCommitされたとみなします。次いで、Leaderは、そのエントリーのオペレーションをデコードして実行してから、ステートマシンに適用します。これをApplyと呼びます。
TiKVは、Lease Readという機能をサポートしています。これにより、ReadリクエストをLeaderに直接送信することができます。時間ベースのリースが期限切れとなっていないとLeaderが判断した場合は、LeaderはRaftプロセスを実行する必要なく、Readサービスを直接提供できます。リースが期限切れとなった場合は、LeaderはRaftプロセスを実行してリース期限を延長した後、Readサービスを提供します。
マルチRaft

マルチRaft
1つのRaft Groupが処理できるデータ量には限度があるため、データを複数のRaft Groupに分割します。それぞれのRaft Groupは1つのRegionに対応しています。分割は、レンジごとにスライスされる形で行われます。つまり、データのキーをバイト順にソートし、無制限のソートマップを作成し、それを連続したキーレンジのセグメントにスライスします。各キーレンジはRegionとして扱われます。Regionのレンジには、左包含・右排他モードが適用されます[start, end)。前のRegionのエンドキーは、次のRegionのスタートキーになります。
TiKVのRegionのサイズには、上限(しきい値)があります。サイズがこのしきい値を超過すると、そのRegionは2つのRegionに分割されます (例:[a, b) -> [a, ab) + [ab, b))。反対に、Region内のデータ量が非常に少ない場合は、そのRegionは隣接するRegionにマージされ、より大きなRegionが形成されます (例:[a, ab) + [ab, b) -> [a, b))。
Percolator
同一のRegionについては、Raftコンセンサスプロトコルによって、キーオペレーションの整合性を保証することができます。しかし、複数のRegionにあるデータを同時に操作する場合は、各オペレーションの整合性を確保するため、分散トランザクションが必要になります。
分散トランザクションの最も一般的な手法は、2フェーズコミット(2PC)です。TiKVは、Googleの- Percolatorに基づく2PC実装から着想を得ており、実用的最適化を行った分散トランザクションをサポートしています。説明のため、このメカニズムのポイントをいくつか取り上げてみます。
まず、Percolatorは、各トランザクションにグローバルタイムスタンプを割り当てるためのタイムスタンプオラクル(TSO)サービスを必要とします。このタイムスタンプはグローバルに一意であり、時間的に単調に増加します。いずれのトランザクションも、最初に開始タイムスタンプ (startTS) を取得し、トランザクションがコミットされると、コミットスタンプ (commitTS) を取得します。
Percolatorには、Lock、Data、Writeの3つのカラムファミリー(CF)があります。キーと値のペアが書き込まれると、このキーのロックはLock CFに配置され、実際の値はData CFに配置されます。書き込みが正常にコミットされると、対応するコミット情報がWrite CFに保存されます。
キーがData CFとWrite CFに保存されると、対応するタイムスタンプがキーに追加されます(Data CFの場合は— startTS、Write CFの場合はcommitTS)
例えばa = 1を書き込む必要があるとします。この場合はまず、startTS(例えば10)がTSOから取得されます。その後、以下のようにLock CFとData CFにデータが書き込まれると、PercolatorのステージはPreWriteに移ります。
注釈:
以下の操作例では、WはWrite、RはRead、DはDelete、SはSeekを示しています。
Lock CF: W a = lock
Data CF: W a_10 = value
PreWriteが正常に完了すると、2PCはCommitフェーズに入ります。まず、commitTS(例えば11)がTSOから取得され、書き込みは以下のように続きます。
Lock CF: D a
Write CF: W a_11 = 10
Commitフェーズが正常に完了すると、Data CFとWrite CFにキーと値のレコードが保存されます。一方、実際のデータはData CFに保存され、対応するstartTSはWrite CFに記録されます。
データの読み取りでは、startTS(例えば12)は、TSOから取得され、読み取りは以下のように処理されます。
Lock CF: R a
Write CF: S a_12-> a_11 = 10
Data CF: R a_10
Percolatorモデルでのデータの読み取り方法を以下に示します。
- Lock CFにロックがかかっているか確認します。ロックがかかっている場合は、読み込みは失敗します。ロックがかかっていなかった場合は、Write CFの最新のコミットバージョン(この場合は11)を探します。
- 対応するstartTS(この場合は10)を取得し、Data CF内でキーとstartTSを組み合わせ、対応するデータを読み取ります。
上記は、Percolatorの読み取りプロセスと書き込みプロセスの簡単な説明であり、実際の内容はもっと複雑です。
RocksDB
TiKVでは、基盤となるストレージエンジンとしてRocksDBを使用しています。TiKVの場合、いずれのデータも最終的に1つまたは複数のキーと値のペアに変換されてから、RocksDBに永続化されます。
各TiKVには、2つのRocksDBインスタンスが含まれています。そのうちの1つをRaft RocksDBと呼んでおり、Raftログを保存するために使用します。もう1つをKV RocksDBと呼んでおり、実際のデータを保存するために使用します。
各TiKVストアには、複数のRegionがあります。Raft RocksDBでは、キーのプレフィックスとしてRegion IDを使用します。これをRaft Log IDと組み合わせることで、Raftログを一意に特定することができます。例えば1と2のIDを持つ2つのRegionがあるとします。すると、Raftログは以下のようにRocksDBに保存されます。
1_1-> Log {a = 1}
1_2-> Log {a = 2}
...
1_N-> Log {a = N}
2_1-> Log {b = 2}
2_2-> Log {b = 3}
...
2_N-> Log {b = N}
レンジに基づいてキーをスライスするため、以下のようにキーを使って直接保存します。
a-> N
b-> N
2つのキー(aとb)が保存されますが、これらを識別するためのプレフィックスは使われません。
RocksDBはカラムファミリーをサポートしているため、Percolatorのカラムファミリーに直接対応することができます。TiKVでは、RocksDBのDefault CFを使用し、PercolatorのData CFに直接対応します。また、同じ名前のLock CFとWrite CFを使用します。
PD
各TiKVは、すべてのRegionの情報をPlacement Driver(PD)に報告します。したがって、PDはクラスタ全体のRegion情報を認識しています。これに基づき、Regionルーティングテーブルは以下のように形成されます。

TiKVでのRegionルーティング
あるキーのデータを操作する必要がある場合、クライアントはまず、そのキーが属するRegionがどれなのかをPDに問い合わせます。例えばキーaの場合、PDはそれがRegion1に属していることを認識しているため、関連情報をクライアントに返します。この関連情報には、Region1の複製はいくつあるのか、現在Leaderとなっているのはどのピアなのか、そのLeaderの複製があるのはどのTiKVなのかといった情報が含まれています。
クライアントは、必要なRegion情報をローカルにキャッシュし、その後のオペレーションを続行します。ただし、RegionのRaft Leaderが変更されたり、Regionが分割されたり、マージされたりする可能性はあります。この場合は、クライアントはキャッシュが無効であることを認識し、PDから最新の情報を再取得します。
PDは、グローバルタイミングサービスを備えています。Percolatorトランザクションモデルでは、トランザクションの開始ポイントとコミットポイントの両方でタイムスタンプが必要です。タイムスタンプは、現在の実装ではPDによって割り当てられます。
TiKVでの読み取りと書き込み
これまでの説明で、TiKVの基本を理解できたと思います。では、TiKVでの実際の読み取りと書き込み作業について説明します。TiKVは、データオペレーション用のAPIを2つ備えています。すなわち、RawKVとTransactional KV(TxnKV)です。このセクションでは、これらの2つのAPIを使って読み取り処理と書き込み処理を行う方法を説明します。
RawKV
RowKV APIは、ローレベルのKey-Value APIです。これにより、個々のキーと値のペアと直接インタラクションを行うことができます。アプリケーションが分散トランザクションやマルチバージョン同時実行制御(MVCC)のデータアクセスを必要としない場合、RowKVを使用します。
RawKVを使った書き込み

RawKVを使った書き込み
RawKV APIを使った一般的な書き込みオペレーション(例えばa = 1の書き込み)では、以下のステップを踏みます。
- クライアントはPDに対し、
aのRegionをリクエストする。 - PDはRegionに関連する情報(主に、Leaderが配置されているTiKVノードに関連する情報)を返す。
- クライアントは、Leaderが配置されているTiKVノードにコマンドを送信する。
- Leaderはリクエストを承認し、Raftプロセスを実行する。
- Leaderは
a = 1をKV RocksDBに適用し、書き込みが成功したことをクライアントに知らせる。
RawKVを使った読み込み

RawKVを使った読み込み
読み込み処理も、書き込みの場合と同様です。唯一の違いは、Leaderが読み込みを直接適用する際、Raftプロセスを実行する必要がないことです。
TxnKV
TxnKVは、前述したPercolatorに相当します。ハイレベルのKey-Value APIであり、ACIDセマンティクスを提供します。アプリケーションが分散トランザクションやMVCCを必要とする場合、TxnKVを利用します。
TxnKVを使った書き込み

TxnKVを使った書き込み
TxnKVの場合は、作業はずっと複雑になります。大部分のプロセスは、Percolatorのセクションで説明してあります。TiKVが最新のコミットをすぐにシークできるよう、以下のステップを踏みます。
- ビッグエンディアンでタイムスタンプを8バイト値に変換し、そのバイトをビットごとに反転させる。
- RocksDBに保存するため、反転したバイトをオリジナルキーに結合する。
このようにして、最新のコミットが先頭に保存されるとともに、シークの場所を直接特定できるようになります。もちろん、対応するTSも同じ方法でエンコードされ、処理されます。
例えば、あるキーに2つのコミットがあるとします。commitTSは10と12、startTSは9と11とします。すると、RocksDBのキーの順番は以下のようになります。
Write CF:
a_12-> 11
a_10-> 9
Data CF:
a_11-> data_11
a_9-> data_9
また、留意すべき点は、値が小さい場合、TiKVが直接その値をWrite CFに保存するため、読み取り時に必要となるのはRead CFのみであるということです。書き込みオペレーションの場合、プロセスは以下のようになります。
PreWrite:
Lock CF: W a-> Lock + Data
Commit:
Lock CF: R a-> Lock + 10 + Data
Lock CF: D a
Write CF: W a_11-> 10 + Data
TiKVでは、Commitフェーズ中にLock CFが読み取られてトランザクションの競合が判定されるため、Lock CFからデータを取得し、それをWrite CFに書き込むことができます。
TxnKVを使った読み取り

TxnKVを使った読み取り
TxnKVを使った書き込みプロセスの詳細については、Percolatorセクションを参照してください。
TiDBとTiKV間のSQLキーマッピング
TiKVは、分散KVストアです。企業は、TiKV上にさまざまな言語のデータベースを構築しています。こうした場合、TiKVはどのように利用されているのでしょうか。PingCAPの分散型リレーショナルデータベースであり、MySQLプロトコルを話すTiDBについて考えてみたいと思います。リレーショナルテーブルがキーと値にどのようにマッピングされているのか、疑問に思う人もいるかもしれません。では以下のテーブルを見てください。
CREATE TABLE t1 {
id BIGINT PRIMARY KEY,
name VARCHAR (1024),
age BIGINT,
content BLOB,
UNIQUE (name),
INDEX (age),
}
この例では、4つのフィールドを持つテーブルt1を作成します。IDをプライマリキー、nameを一意なインデックス、age を一意でないインデックスとします。
では、このテーブルのデータはどのようにTiKVに対応するのでしょうか。
TiDBでは、各テーブルには一意のIDがあります(例えば11)。また、各インデックスにも一意のIDがあります(例えばnameインデックスの場合は12、ageインデックスの場合は13)。プレフィックスにはtとiを用い、テーブルのデータとインデックスを区別します。上記のテーブルt1には、現在2行のデータがあり、これらを(1, "a", 10, "hello")と(2, "b", 12, "world")とします。以下に示すように、TiKVの各データ行にはそれぞれ異なる、対応するキーと値のペアがあります。
Primary Key
t_11_1-> (1, "a", 10, "hello")
t_11_2-> (2, "b", 12, "world")
Unique Name
i_12_a-> 1
i_12_b-> 2
Index Age
i_13_10_1-> nil
i_13_12_2-> nil
PKは一意であるため、t + Table ID + PKと記述することによって、データ行を表すことができます。この場合の値はこの行データとなります。一意のインデックスの場合は、i + Index ID + nameと記述することによって表すことができます。この場合の値は対応するPKとなります。2つの名前が同じ場合は、一意性制約は違反しています。一意のインデックスでクエリを実行する場合、TiKVはまず、対応するPKを特定し、次いでPKを介して対応するデータを見つけます。
通常のインデックスの場合は、一意性制約は要求されないので、i + Index ID + age + PKと記述します。この場合の値は空です。PKは一意となるはずなので、2行のデータに同一の年齢があっても、これらのデータは競合しません。通常のインデックスでクエリを実行する場合は、TiKVはi + Index ID + ageキー以上の最初のキーを持つデータをシークし、次いでプレフィックスが一致しているかどうか確認します。プレフィックスが一致すると、TiKVは対応するPKをデコードし、次いでデコードされたPKを介して対応する実際のデータを取得します。
TiDBでは、TiKVとのインタラクションを行う場合、キーの整合性を確保する必要があるため、TxnKVモードが使用されます。
結論
ここまで、TiKVでのデータの読み取りと書き込みのプロセスを簡単に説明しました。エラー処理やPercolatorのパフォーマンス最適化など、今回カバーできなかった事項もたくさんあります。詳細については、TiKVの説明書やTiKVの詳細をご参照ください。また、TiKVプロジェクトの開発に参加していただければ、より一層嬉しく思います!


TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。