

※このブログは2025年7月25日に公開された英語ブログ 「Exploring TiDB Observability: A Journey Through Real-World Case Studies」 の拙訳です。
日付パラメータや関数の違いだけでほぼ同一のSQL文が、結果こそ似ているものの、パフォーマンスが10倍や100倍も大きく異なるケースを経験したことはありませんか?
実際の運用では、まず”EXPLAIN”を使って実行計画の変化を確認するのが一般的です。
しかし、もし実行計画が変わっていなかったらどうでしょうか?その場合は?
そこで登場するのがEXPLAIN ANALYZEです。EXPLAIN ANALYZEは、単なる実行計画ではなく、各オペレーターの実際の実行時の挙動を明らかにしてくれます。
前回のブログでは、TiDBにおける未使用または非効率なインデックスを検出・削除し、パフォーマンスと安定性を向上させるための監視ツールについて紹介しました。 本ブログでは、実際の事例やよくある課題を交えながら、オペレーターの実行情報を活用してSQLパフォーマンスをより正確に分析・診断する方法について掘り下げていきます。
TiDBのオブザーバビリティ:オペレーター実行情報の概要
通常、オペレーターの実行情報を取得するには、EXPLAIN ANALYZEステートメントを使用します。EXPLAIN ANALYZEは、対象のSQL文を実際に実行し、その実行時の情報を取得して、実行計画と共に返します。記録される主な情報には以下が含まれます:actRows (実際に処理された行数)、execution info (実行時間などの詳細)、memory (メモリ使用量)、Disk (ディスクI/Oの使用状況)
| 属性名 | 意味 |
| actRows | オペレーターが出力した行数 |
| execution info | オペレーターの実行情報。timeはオペレーターの開始から終了までの総wall timeを示し、すべてのサブオペレーターの実行時間も含まれます。親オペレーターから複数回 (ループなどで) 呼び出される場合、timeはその累積時間を指します。 loopsは、現在のオペレーターが親オペレーターから呼び出された回数を示します。 |
| memory | オペレーターが使用したメモリ領域 |
| disk | オペレーターが使用したディスク領域 |
“execution info”の各オペレーターにおける詳細な解説については、TiDBの公式ドキュメントを参照してください。これらの指標は、開発者が多数のパフォーマンス問題を調査・解決する中で磨き上げてきたものであり、TiDBのSQLパフォーマンス診断を深く理解したい方にとって必読の内容です。
SQLのパフォーマンス問題は断続的に発生することもあり、その場合は EXPLAIN ANALYZEを直接使っての調査が難しくなることがあります。
そのようなときは、TiDB Dashboardのスローログクエリから、問題のあるSQLステートメントをすばやく特定し、詳細な実行情報を確認することが可能です。
TiDBのオブザーバビリティ事例集
ここからは、具体的な実例を通じて関連する問題を探っていきます。今回取り上げる例は以下の通りです:
- クエリのレイテンシージッターの調査
- オペレーターの並列実行の理解
- なぜMAX() は100msで終わったのに、MIN() は8秒かかったのか?
なお、以下で紹介する実行計画の多くは、本番環境から取得されたものであり、プライバシー保護のためにマスキングが施されています。
クエリのレイテンシージッター
クエリのレイテンシーのジッター (ばらつき) は、最も一般的なパフォーマンス問題のひとつです。スロークエリログから、パフォーマンスのばらつきを引き起こしている特定のSQLステートメントを特定できれば、さらにそのオペレーターの実行情報を分析することで、根本原因が明らかになり、具体的な最適化の手がかりを得られることがよくあります。
事例:
ある顧客環境におけるポイントクエリのレイテンシージッター (ばらつき) の問題を考えてみましょう。このクエリでは、遅延が断続的に発生し、2秒を超えることもありました。スロークエリログを使用して、問題のあるクエリのオペレーター実行メトリクスを特定しました:
mysql> explain analyze select * from t0 where col0 = 100 and col1 = 'A';
+---------------------+---------+---------+-----------+---------------------------------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+---------------+---------+------+
| id | estRows | actRows | task | access object | execution info | operator info | memory | disk |
+---------------------+---------+---------+-----------+---------------------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------+---------------+---------+------+
| Point_Get_1 | 1 | 1 | root | table:t0, index:uniq_col0_col1 | time:2.52s, loops:2, ResolveLock:{num_rpc:1, total_time:2.52s}, Get:{num_rpc:3, total_time:2.2ms}, txnNotFound_backoff:{num:12, total_time:2.51s}, tikv_wall_time: 322.8us, scan_detail: {total_process_keys: 2, total_process_keys_size: 825, total_keys: 9, get_snapshot_time: 18us, rocksdb: {delete_skipped_count: 3, key_skipped_count: 14, block: {cache_hit_count: 16}}} | N/A | N/A | N/A |
+---------------------+---------+---------+-----------+---------------------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------+---------------+---------+------+分析
まず最初に注目すべきは、このクエリがPoint_Get_1オペレーターのみで構成されており、execution infoに記録された実行時間は2.52秒であるという点です。これは、クエリ全体の実行時間が正確に記録されていることを意味します。
さらにexecution infoを詳しく確認すると、ResolveLockというエントリが含まれているのがわかります。この処理に合計2.52秒かかっており、クエリ時間のほぼすべてがロック解消処理に費やされたことを示しています。一方で、実際のGet操作にはわずか2.2ミリ秒しかかかっておらず、データアクセス自体はほとんど時間がかかっていないことが確認できます。
さらに、txnNotFound_backoffというエントリには、古いトランザクションによるリトライが発生していたことが記録されています。具体的には 12 回のリトライが発生し、合計で 2.51 秒を要しています (これはResolveLockの2.52 秒とほぼ一致しています)。
これらの情報から次のような仮説が立てられます:このポイントクエリは、古いトランザクションによって保持されたロックに遭遇し、そのロック解消処理中に高いレイテンシーが発生した可能性が高い。
ResolveLockのフェーズでは、システムが期限切れのロックを検出し、クリーンアップ処理を実施していたと考えられます。このロック解消のオーバーヘッドが、クエリのレイテンシーを大きく引き上げた要因です。
この仮説を検証するために、以下の画像のように監視データを照合することができます:
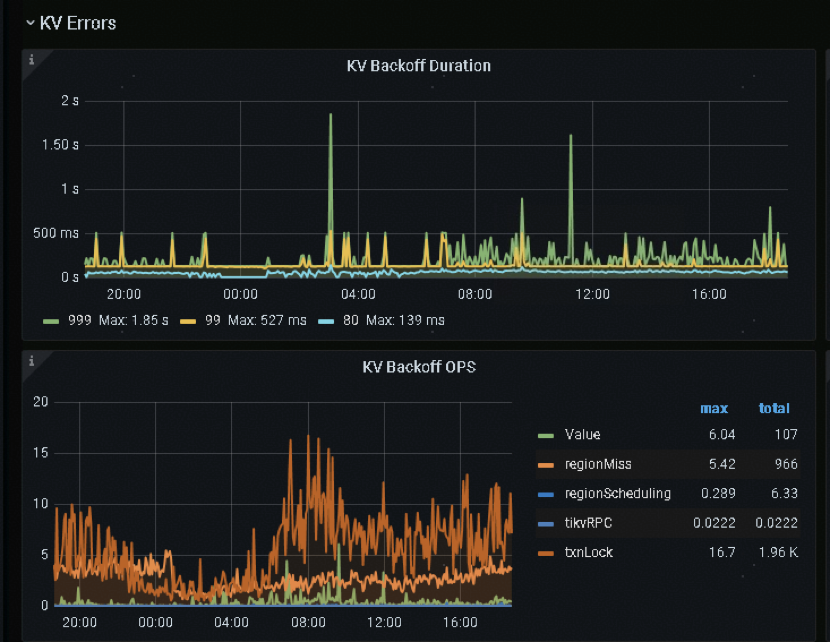
TiDBにおけるオペレーターの並列度
TiDBでは、システム変数を通じてオペレーターの実行並列性を調整し、最終的にSQLパフォーマンスをチューニングすることができます。 オペレーターの並列度は実行効率に大きく影響します。例えば、同じ数のコプロセッサタスク数であっても、並列度を5から10に上げることで、リソース使用量は増加しますが、パフォーマンスがほぼ2倍に向上することがあります。実行情報を活用することで、オペレーターの実際の並列度を把握でき、より詳細なパフォーマンス診断の基盤を作ることが可能になります。 それでは、実際の事例を見てみましょう。
事例:
システムは以下のように設定されていました:
tidb_executor_concurrency = 5tidb_distsql_scan_concurrency = 15
それでは、以下の実行計画において、cop_taskとtikv_taskの実際の実行並列度はどのようになっているでしょうか?
mysql> explain analyze select * from t0 where c like '2147%';
+-------------------------------+---------+---------+-----------+-------------------------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------------------------------------+---------+------+
| id | estRows | actRows | task | access object | execution info | operator info | memory | disk |
+-------------------------------+---------+---------+-----------+-------------------------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------------------------------------+---------+------+
| IndexLookUp_10 | 3.82 | 99 | root | | time:2.83ms, loops:2, index_task: {total_time: 733.8µs, fetch_handle: 727.9µs, build: 806ns, wait: 5.14µs}, table_task: {total_time: 1.96ms, num: 1, concurrency: 5}, next: {wait_index: 821µs, wait_table_lookup_build: 108.2µs, wait_table_lookup_resp: 1.85ms} | | 41.0 KB | N/A |
| ├─IndexRangeScan_8(Build) | 3.82 | 99 | cop[tikv] | table:t0, index:idx_c(c) | time:719.1µs, loops:3, cop_task: {num: 1, max: 650µs, proc_keys: 99, rpc_num: 1, rpc_time: 625.7µs, copr_cache_hit_ratio: 0.00, distsql_concurrency: 15}, tikv_task:{time:0s, loops:3}, scan_detail: {total_process_keys: 99, total_process_keys_size: 18810, total_keys: 100, get_snapshot_time: 102µs, rocksdb: {key_skipped_count: 99, block: {cache_hit_count: 3}}} | range:["2147","2148"), keep order:false | N/A | N/A |
| └─TableRowIDScan_9(Probe) | 3.82 | 99 | cop[tikv] | table:t0 | time:1.83ms, loops:2, cop_task: {num: 4, max: 736.9µs, min: 532.6µs, avg: 599µs, p95: 736.9µs, max_proc_keys: 44, p95_proc_keys: 44, rpc_num: 4, rpc_time: 2.32ms, copr_cache_hit_ratio: 0.00, distsql_concurrency: 15}, tikv_task:{proc max:0s, min:0s, avg: 0s, p80:0s, p95:0s, iters:5, tasks:4}, scan_detail: {total_process_keys: 99, total_process_keys_size: 22176, total_keys: 99, get_snapshot_time: 217.3µs, rocksdb: {block: {cache_hit_count: 201}}} | keep order:false | N/A | N/A |
+-------------------------------+---------+---------+-----------+-------------------------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------------------------------------+---------+------+
3 rows in set (0.00 sec)分析
この例を使って、実行情報におけるcop_taskおよびtikv_taskの項目と、実際のcopタスクの実行並列度との関係を説明します。
cop_taskとtikv_taskの違い
まず最初に明確にしておくべき重要な点として、実行情報 (execution info) におけるxxx_taskの各項目は、実行計画における 「task」 カラムと同義ではないということがあります。
たとえば、実行計画において 「task」 カラムのカテゴリは “root” や “cop [tikv]” などとなっており、これは各オペレーターがどのコンポーネント (TiDB、TiKV、TiFlashなど) 上で実行されるかを示しています。さらに、これはストレージエンジンとの通信プロトコルの種類 (Coprocessor、Batch Coprocessor、MPPなど) も表しています。
一方で、execution info内の各種taskは、異なる観点からオペレーターの実行情報を細分化して表現しており、性能ボトルネックの特定やクロスチェックを目的とした情報です。具体的には:
- ttikv_taskは、特定の TiKV オペレーターの全体的な実行情報を表します。
- cop_taskは、1つの RPC タスク全体の実行を表し、その中に複数の tikv_taskが含まれる可能性があります。 たとえば、あるcop_taskに tableScan + Selectionの2つのオペレーターが含まれている場合、それぞれに対応するtikv_task情報があり、個別の実行状況を記録します。
一方cop_taskは、それら 2つのオペレーターを含む RPC 要求全体の実行情報(実行時間など) をまとめて示すものです。
同様に、MPP クエリにおいては、execution info におけるtiflash_task項目が、特定の TiFlash オペレーターの全体的な実行情報を表します。
+------------------------------+-------------+----------+--------------+----------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------+-----------+---------+
| id | estRows | actRows | task | access object | execution info | operator info | memory | disk |
+------------------------------+-------------+----------+--------------+----------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------+-----------+---------+
| HashAgg_22 | 1.00 | 1 | root | | time:17ms, open:1.92ms, close:4.83µs, loops:2, RU:1832.08, partial_worker:{wall_time:15.055084ms, concurrency:5, task_num:1, tot_wait:15.017625ms, tot_exec:12.333µs, tot_time:75.203959ms, max:15.042667ms, p95:15.042667ms}, final_worker:{wall_time:15.079958ms, concurrency:5, task_num:5, tot_wait:1.414µs, tot_exec:41ns, tot_time:75.277708ms, max:15.060375ms, p95:15.060375ms} | funcs:count(Column#19)->Column#17 | 6.23 KB | 0 Bytes |
| └─TableReader_24 | 1.00 | 1 | root | | time:16.9ms, open:1.9ms, close:3.46µs, loops:2, cop_task: {num: 2, max: 0s, min: 0s, avg: 0s, p95: 0s, copr_cache_hit_ratio: 0.00} | MppVersion: 3, data:ExchangeSender_23 | 673 Bytes | N/A |
| └─ExchangeSender_23 | 1.00 | 1 | mpp[tiflash] | | tiflash_task:{time:13.1ms, loops:1, threads:1}, tiflash_network: {inner_zone_send_bytes: 24} | ExchangeType: PassThrough | N/A | N/A |
| └─HashAgg_9 | 1.00 | 1 | mpp[tiflash] | | tiflash_task:{time:13.1ms, loops:1, threads:1} | funcs:count(test.lineitem.L_RETURNFLAG)->Column#19 | N/A | N/A |
| └─TableFullScan_21 | 11997996.00 | 11997996 | mpp[tiflash] | table:lineitem | tiflash_task:{time:12.8ms, loops:193, threads:12}, tiflash_scan:{mvcc_input_rows:0, mvcc_input_bytes:0, mvcc_output_rows:0, local_regions:10, remote_regions:0, tot_learner_read:0ms, region_balance:{instance_num: 1, max/min: 10/10=1.000000}, delta_rows:0, delta_bytes:0, segments:20, stale_read_regions:0, tot_build_snapshot:0ms, tot_build_bitmap:0ms, tot_build_inputstream:15ms, min_local_stream:10ms, max_local_stream:11ms, dtfile:{data_scanned_rows:11997996, data_skipped_rows:0, mvcc_scanned_rows:0, mvcc_skipped_rows:0, lm_filter_scanned_rows:0, lm_filter_skipped_rows:0, tot_rs_index_check:3ms, tot_read:53ms}} | keep order:false | N/A | N/A |
+------------------------------+-------------+----------+--------------+----------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------+-----------+---------+Cop タスクの実行並列度
まず、実行計画を確認してみましょう。IndexLookUp_10は ルート オペレーターです。IndexLookUpオペレーターは主に2つのステップを実行します。1つ目は、インデックスを使って対象行の 行 ID を取得すること。2つ目は、その 行 ID に基づいて必要な列データを読み取ることです。IndexLookUp_10のexecution infoでは、index_taskとtable_taskの詳細がそれぞれ別々に表示されています。明らかに、index_taskはIndexRangeScan_8オペレーターに対応しており、table_taskはTableRowIDScan_9オペレーターに対応しています。
並列性の観点から見ると、index_taskには並列性の情報が表示されていないため、IndexRangeScan_8オペレーターの並列度はデフォルトで 1 であることを意味します。しかし、IndexRangeScan_8のcop_taskは15 (これは tidb_distsql_scan_concurrencyパラメータによって決まります) となっており、理論上は15のcopタスクを並列に実行してデータを読み取ることができることを意味します。
一方、table_taskの並列度は5 (tidb_executor_concurrency パラメータによって決まります) であり、最大で5つのTableRowIDScan_9オペレーターが同時に実行可能です。また、TableRowIDScan_9のcop_taskにおけるdistsql_concurrencyも15 (これもtidb_distsql_scan_concurrencyによって決まります) です。したがって、table_taskの最大並列読み取り能力は:5 × 15 = 75 のcopタスクとなります。
Max関数=> Min関数, 100ミリ秒 => 8秒
インデックス付きのカラムに対して最大値を取得するSQLクエリは、実行に約100ミリ秒しかかかりませんでした。しかし、最小値を取得するようにクエリを変更したところ、実行時間が8秒以上に跳ね上がりました。以下に、両ケースのEXPLAIN ANALYZEの出力を示します:
mysql> explain analyze select max(time_a) from t0 limit 1;
+--------------------------------+---------+---------+-----------+----------------------------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------+-----------+------+
| id | estRows | actRows | task | access object | execution info | operator info | memory | disk |
+--------------------------------+---------+---------+-----------+----------------------------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------+-----------+------+
| Limit_14 | 1.00. | 1 | root | | time:2.328901ms, loops:2 | offset:0, count:1 | N/A | N/A |
| └─StreamAgg_19 | 1.00 | 1 | root | | time:2.328897ms, loops:1 | funcs:max(t0.time_a)->Column#18 | 128 Bytes | N/A |
| └─Limit_39 | 1.00 | 1 | root | | time:2.324137ms, loops:2 | offset:0, count:1 | N/A | N/A |
| └─IndexReader_45 | 1.00 | 1 | root | | time:2.322215ms, loops:1, cop_task: {num: 1, max:2.231389ms, proc_keys: 32, rpc_num: 1, rpc_time: 2.221023ms, copr_cache_hit_ratio: 0.00} | index:Limit_26 | 461 Bytes | N/A |
| └─Limit_44 | 1.00 | 1 | cop[tikv] | | time:0ns, loops:0, tikv_task:{time:2ms, loops:1} | offset:0, count:1 | N/A | N/A |
| └─IndexFullScan_31 | 1.00 | 32 | cop[tikv] | table:t0, index:time_a(time_a) | time:0ns, loops:0, tikv_task:{time:2ms, loops:1} | keep order:true, desc | N/A | N/A |
+------------------------------+---------+---------+-----------+----------------------------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------+-----------+------+
6 rows in set (0.12 sec)
mysql> explain analyze select min(time_a) from t0 limit 1;
+--------------------------------+---------+---------+-----------+----------------------------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------+-----------------+------+
| id | estRows | actRows | task | access object | execution info | operator info | memory | disk |
+--------------------------------+---------+---------+-----------+----------------------------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------+-----------------+------+
| Limit_14 | 1.00 | 1 | root | | time:8.263857153s, loops:2 | offset:0, count:1 | N/A | N/A |
| └─StreamAgg_19 | 1.00 | 1 | root | | time:8.26385598s, loops:1 | funcs:min(t0.time_a)->Column#18 | 128 Bytes | N/A |
| └─Limit_39 | 1.00 | 1 | root | | time:8.263848289s, loops:2 | offset:0, count:1 | N/A | N/A |
| └─IndexReader_45 | 1.00 | 1 | root | | time:8.26384652s, loops:1, cop_task: {num: 175, max: 1.955114915s, min: 737.989μs, avg: 603.631575ms, p95: 1.161411687s, max_proc_keys: 480000, p95_proc_keys: 480000, tot_proc: 1m44.809s, tot_wait: 361ms, rpc_num: 175, rpc_time: 1m45.632904647s, copr_cache_hit_ratio: 0.00} | index:Limit_44 | 6.6025390625 KB | N/A |
| └─Limit_44 | 1.00 | 1 | cop[tikv] | | time:0ns, loops:0, tikv_task:{proc max:1.955s, min:0s, p80:784ms, p95:1.118s, iters:175, tasks:175} | offset:0, count:1 | N/A | N/A |
| └─IndexFullScan_31 | 1.00 | 32 | cop[tikv] | table:t0, index:time_a(time_a) | time:0ns, loops:0, tikv_task:{proc max:1.955s, min:0s, p80:784ms, p95:1.118s, iters:175, tasks:175} | keep order:true | N/A | N/A |
+--------------------------------+---------+---------+-----------+----------------------------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------+-----------------+------+
6 rows in set (8.38 sec)分析
パフォーマンス診断のためにオペレーターの実行情報を使用する際は、通常、まず各オペレーター自身の実行時間 (他のオペレーターからのデータ待機時間を除く) を上から順に確認し、全体のクエリ性能に最も影響を与えているオペレーターを特定します。以下に、オペレーターの実行時間の算出方法を示します。.
モナドオペレーターの実行時間
以下は、オペレーターの種類ごとの実行時間の算出方法です:
1.「root」 型のオペレーター
オペレーター自身の処理時間は、オペレーターの総実行時間からサブオペレーターの実行時間を差し引くことで直接求めることができます。
2. 「cop [tikv]」 型のオペレーター
実行情報にはtikv_taskの統計が含まれています。オペレーターのデータ待機時間を含む実行時間は、以下の式で推定できます:推定実行時間 = 平均実行時間 × task数 / 並列度。この時間からサブオペレーターの実行時間を差し引くことで、当該オペレーターの実際の処理時間を求めることができます。
3. 「mpp [tiflash]」、「cop [tiflash]」、「batchcop [tiflash]」 型のオペレーター
実行情報にはtiflash_taskの統計が含まれています。通常、オペレーターの処理時間は、proc maxからサブオペレーターのproc maxを差し引くことで求められます。これは、同一クエリにおけるすべてのTiFlashタスクが基本的に同時に実行を開始するためです。
補足:ExchangeSenderオペレーターの実行時間には、上位のExchangeReceiverオペレーターがデータを受信するまでの時間も含まれます。そのため、上位のExchangeReceiverがメモリ上のデータを読み取る時間よりも長くなることがよくあります。
複数オペレーターの実行時間
複合オペレーターで複数のサブオペレーターを持つ場合、実行情報には通常、それぞれのサブオペレーターの実行情報が詳細に記載されています。例えば、IndexLookUpオペレーターの実行情報には、index_taskとtable_taskの実行詳細が明示的に含まれています。これらのサブオペレーターの実行情報を分析することで、どのサブオペレーターが全体のパフォーマンスにより大きな影響を与えているかを正確に特定し、より的確な最適化が可能になります。
この例では、IndexReader_45がパフォーマンスに最も大きな影響を与えている主要なオペレーターであることがわかります。実行情報を比較すると、copタスクの数に大きな差があることがわかります。「max」 シナリオではcopタスクが1つしかないのに対し、「min」 シナリオでは175個のcopタスクがあります。同時に、proc_keysの数も32から480,000に増加しています。
「operator info」 列のタグから判断すると、「max」 シナリオの読み取り順序は降順 (keep order, desc)、つまり大きい値から小さい値へ読み取っているのに対し、「min」 シナリオはデフォルトの昇順 (keep order) となっています。オプティマイザーは集約関数の種類に応じてインデックスの読み取り順序を最適化しており、「max」 シナリオでは降順読み取りを、「min」 シナリオでは昇順読み取りを使用しています。この最適化戦略の狙いは、条件を満たす最初のデータをできるだけ早く見つけることにあります。
しかし「min」 シナリオでは、最小のキー付近に削除済みでまだ回収されていない大量のキーが存在します。そのため、最初の有効なデータが見つかるまでの読み取り処理中に大量の不要なデータをスキャンせざるを得ず、これが大きなパフォーマンスオーバーヘッドを引き起こしています。
TiDBのオブザーバビリティ:今後の展望
TiDB 9.0 Beta 1では、オペレーターの実行情報をさらに強化し、システムの観測性を向上させます。主な改善点は以下の通りです。
- より正確なパフォーマンスの把握:初期化 (open) および終了処理 (close) の時間を含めることで、オペレーターの計測精度が向上します。従来は実行時間のメトリクスが実際の稼働時間を過小評価することがあり、パフォーマンスのボトルネック特定が難しい場合がありました。今回の改善により、開始から終了までの実際の経過時間 (ウォールクロック時間) を反映し、DBAはクエリ実行中の実際に費やされた時間をより正確に把握できるようになります。
なぜ重要か:
遅いオペレーターを特定し、実行が遅いのかセットアップ・終了処理が遅いのかをより正確に区別できるため、チューニング時の誤った仮定を減らせます。 - 並列実行時の時間計測の明確化:従来、オペレーターが複数の並列実行を持つ場合、累積ウォールタイムが誤解を招くことがありました。サブオペレーターの方が親オペレーターより遅く見えるケースもありました。この改善では、total_time、total_open、total_closeを導入し、並列タスク全体の累積時間を個別に報告することで、時間配分の内訳をより明確にします。
なぜ重要か:
実際のボトルネックと並列実行の影響による誤差を区別できるため、パフォーマンス問題の根本原因分析が容易になります。 - TiFlash特有の遅延診断の向上:TiFlashの実行情報に、minTSO_wait、pipeline_breaker_wait、pipeline_queue_waitといった新しいレイテンシメトリクスを追加。これらはMPPタスクのスケジューリングやパイプライン実行中の隠れた待機時間を明らかにします。
なぜ重要か:
実際のボトルネックと並列実行による遅延を区別でき、パフォーマンス問題の根本原因を特定しやすくなります。
これらの改善により、TiDBはより包括的かつ正確な実行情報を提供し、クエリパフォーマンスの診断と最適化を支援します。
TiDBの観測性に関してご質問がある場合は、 Twitter、 LinkedIn、 または Slack チャンネルでお気軽にお問い合わせください。



TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。