
Author: Wu Qiang (Platform Engineer at PingCAP)
Editors: Calvin Weng, Tom Dewan
Data build tool (dbt) is a popular open-source data transformation tool that enables analytics engineers to transform data in their warehouses through SQL statements. The TiDB community recently released the dbt-tidb adapter to make TiDB, a distributed SQL database to work with dbt. Through the dbt-tidb plug-in, analytics engineers working with TiDB can directly create forms and match data through SQL without having to think about the process of creating tables or views. They can also use Jinja, a dbt template language for writing SQL, test, package management, and other functions, which greatly improves efficiency.
In this tutorial, I will show you how to use dbt with TiDB. Before you try any of the steps below, make sure the following items are installed:
- TiDB 5.3 or later
- dbt 1.01 or later
- dbt-tidb 1.0.0
Installation
There are several ways you can install dbt and dbt-tidb, In this tutorial, we will use pypi. When you install dbt-tidb, dbt is installed as a dependency. So you only need one command to install both:
$ pip install dbt-tidbYou can also install dbt separately. Please refer to How to install dbt in the dbt documentation.
Creating the project: jaffle shop
dbt-lab provides a project, jaffle_shop, to demonstrate dbt’s functionality. You can get the project directly from GitHub:
$ git clone https://github.com/dbt-labs/jaffle_shop$ cd jaffle_shop
All files in the jaffle_shop project directory are structured as follows.
ubuntu@ubuntu:~/jaffle_shop$ tree.├── dbt_project.yml├── etc│ ├── dbdiagram_definition.txt│ └── jaffle_shop_erd.png├── LICENSE├── models│ ├── customers.sql│ ├── docs.md│ ├── orders.sql│ ├── overview.md│ ├── schema.yml│ └── staging│ ├── schema.yml│ ├── stg_customers.sql│ ├── stg_orders.sql│ └── stg_payments.sql├── README.md└── seeds├── raw_customers.csv├── raw_orders.csv└── raw_payments.csv
- dbt_project.yml is the dbt project configuration file, which holds the project name and database configuration file information.
- The models directory contains the project’s SQL models and table schemas. Note that the data analyst at your company writes this section. To learn more about models, see dbt Docs.
- The seed directory stores CSV files that are dumped from database export tools. For example, TiDB can export the table data into CSV files through Dumpling. In the jaffle shop project, these CSV files are used as raw data to be processed.
Configuring the project
To configure the project:
- Complete the global configuration. In the user directory, edit the default global profile,
~/.dbt/profiles.ymlto configure the connection with TiDB:$ vi ~/.dbt/profiles.ymljaffle_shop_tidb: # project nametarget: dev # targetoutputs:dev:type: tidb # adapter typeserver: 127.0.0.1port: 4000schema: analytics # database nameusername: rootpassword: "" - Complete the project configuration.
In the jaffle_shop project directory, enter the project configuration filedbt_project.ymland change the profile field tojaffle_shop_tidb. This configuration allows the project to query from the database as specified in the~/.dbt/profiles.ymlfile.$ cat dbt_project.ymlname: 'jaffle_shop'config-version: 2version: '0.1'profile: 'jaffle_shop_tidb' # note the modification heremodel-paths: ["models"] # model pathseed-paths: ["seeds"] # seed pathtest-paths: ["tests"]analysis-paths: ["analysis"]macro-paths: ["macros"]target-path: "target"clean-targets:- "target"- "dbt_modules"- "logs"require-dbt-version: [">=1.0.0", "<2.0.0"]models:jaffle_shop:materialized: table # *.sql which in models/ would be materialized to tablestaging:materialized: view # *.sql which in models/staging/ would bt materialized to view - Verify the configuration.
Run the following command to check whether the database and project configuration are correct:$ dbt debug
Loading CSV files
Now that you have successfully created and configured the project, it’s time to load the CSV data and materialize the CSV as a table in the target database. Note that this step is not generally required for a dbt project because the data items for processing are already in the database.
- Load the CSV files by running the following command:
$ dbt seedThis displays the following:
Running with dbt=1.0.1Partial parse save file not found. Starting full parse.Found 5 models, 20 tests, 0 snapshots, 0 analyses, 172 macros, 0 operations, 3 seed files, 0 sources, 0 exposures, 0 metricsConcurrency: 1 threads (target='dev')1 of 3 START seed file analytics.raw_customers.................................. [RUN]1 of 3 OK loaded seed file analytics.raw_customers.............................. [INSERT 100 in 0.19s]2 of 3 START seed file analytics.raw_orders..................................... [RUN]2 of 3 OK loaded seed file analytics.raw_orders................................. [INSERT 99 in 0.14s]3 of 3 START seed file analytics.raw_payments................................... [RUN]3 of 3 OK loaded seed file analytics.raw_payments............................... [INSERT 113 in 0.24s]As you can see in the results, the seed file was started and loaded into three tables:
analytics.raw_customers,analytics.raw_orders, andanalytics.raw_payments. -
Verify the results in TiDB. The show databases command lists the new analytics database that dbt created. The show tables command indicates that there are three tables in the analytics database, corresponding to the ones we created above.
mysql> show databases;+--------------------+| Database |+--------------------+| INFORMATION_SCHEMA || METRICS_SCHEMA || PERFORMANCE_SCHEMA || analytics || mysql || test |+--------------------+6 rows in set (0.00 sec)mysql> show tables;+---------------------+| Tables_in_analytics |+---------------------+| raw_customers || raw_orders || raw_payments |+---------------------+3 rows in set (0.00 sec)
Running the dbt project
Now you are ready to run the configured projects and finish the data transformation.
- Run the dbt project to finish the data transformation:
$ dbt run
The result shows three views (Running with dbt=1.0.1Unable to do partial parsing because profile has changedUnable to do partial parsing because a project dependency has been addedFound 5 models, 20 tests, 0 snapshots, 0 analyses, 172 macros, 0 operations, 3 seed files, 0 sources, 0 exposures, 0 metricsConcurrency: 1 threads (target='dev')1 of 5 START view model analytics.stg_customers................................. [RUN]1 of 5 OK created view model analytics.stg_customers............................ [SUCCESS 0 in 0.12s]2 of 5 START view model analytics.stg_orders.................................... [RUN]2 of 5 OK created view model analytics.stg_orders............................... [SUCCESS 0 in 0.08s]3 of 5 START view model analytics.stg_payments.................................. [RUN]3 of 5 OK created view model analytics.stg_payments............................. [SUCCESS 0 in 0.07s]4 of 5 START table model analytics.customers.................................... [RUN]4 of 5 OK created table model analytics.customers............................... [SUCCESS 0 in 0.16s]5 of 5 START table model analytics.orders....................................... [RUN]5 of 5 OK created table model analytics.orders.................................. [SUCCESS 0 in 0.12s]analytics.stg_customers,analytics.stg_orders, andanalytics.stg_payments) and two tables (analytics.customersandanalytics.orders) were created successfully. - Go to the TiDB database to verify that the operation is successful.
The output shows that five more tables or views have been added, and the data in the tables or views has been transformed. Note that only part of the data from the customer table is shown here.mysql> show tables;+---------------------+| Tables_in_analytics |+---------------------+| customers || orders || raw_customers || raw_orders || raw_payments || stg_customers || stg_orders. || stg_payments |+---------------------+8 rows in set (0.00 sec)mysql> select * from customers;+-------------+------------+-----------+-------------+-------------------+------------------+-------------------------+| customer_id | first_name | last_name | first_order | most_recent_order | number_of_orders | customer_lifetime_value |+-------------+------------+-----------+-------------+-------------------+------------------+-------------------------+| 1 | Michael | P. | 2018-01-01 | 2018-02-10 | 2 | 33.0000 || 2 | Shawn | M. | 2018-01-11 | 2018-01-11 | 1 | 23.0000 || 3 | Kathleen | P. | 2018-01-02 | 2018-03-11 | 3 | 65.0000 || 4 | Jimmy | C. | NULL | NULL | NULL | NULL || 5 | Katherine | R. | NULL | NULL | NULL | NULL || 6 | Sarah | R. | 2018-02-19 | 2018-02-19 | 1 | 8.0000 || 7 | Martin | M. | 2018-01-14 | 2018-01-14 | 1 | 26.0000 || 8 | Frank | R. | 2018-01-29 | 2018-03-12 | 2 | 45.0000 |
Generating visual documents
dbt lets you generate visual documents that display the overall structure of the project and describe all the tables and views. To generate visual documents:
- Generate the document:
$ dbt docs generate - Start the server:
$ dbt docs serveRunning with dbt=1.0.1Serving docs at 0.0.0.0:8080 -
To access the document view from your browser, navigate to http://localhost:8080.

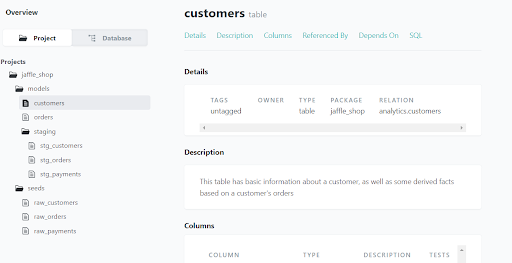
Conclusion
Currently, TiDB supports dbt in TiDB 4.0 and later versions. Earlier versions of TiDB may run into issues when working with dbt. For details, visit the tidb-dbt project on GitHub. To get the most out of dbt, we recommend that you run TiDB 5.3 or later. These versions support all of dbt’s functions.
If you run into issues, feel free to join our community on Slack or file an issue on our repository.


TiDB Cloud Dedicated
TiDB Cloudのエンタープライズ版。
専用VPC上に構築された専有DBaaSでAWSとGoogle Cloudで利用可能。
TiDB Cloud Starter
TiDB Cloudのライト版。
TiDBの機能をフルマネージド環境で使用でき無料かつお客様の裁量で利用開始。